Analytique et décisionnel (BI) sur vos données Azure Cosmos DB
Azure Cosmos DB offre différentes options pour permettre une analytique à grande échelle et des rapports BI sur vos données opérationnelles.
Pour obtenir des insights significatifs sur vos données Azure Cosmos DB, vous devrez peut-être interroger plusieurs partitions, collections ou bases de données. Dans certains cas, vous pouvez combiner ces données avec d’autres sources de données de votre organisation, telles qu’Azure SQL Database, Azure Data Lake Storage Gen2, etc. Vous pouvez également utiliser dans vos requêtes des fonctions d'agrégation telles que la somme, le décompte, etc. Ces requêtes nécessitent une grande puissance de calcul, ce qui consomme probablement plus d'unités de requête (UR) et, par conséquent, ces requêtes peuvent potentiellement affecter les performances de votre charge de travail critique.
Pour isoler les charges de travail transactionnelles de l'impact sur les performances des requêtes analytiques complexes, les données des bases de données sont ingérées chaque nuit vers un emplacement central à l'aide de pipelines ETL (Extract-Transform-Load) complexes. Ces analyses basées sur ETL sont complexes, coûteuses avec des insights différés sur les données métier.
Azure Cosmos DB répond à ces défis en proposant des offres d'analytique zéro ETL rentables.
Analytique zéro ETL en quasi-temps réel sur Azure Cosmos DB
Azure Cosmos DB offre une analytique zéro ETL, en quasi-temps réel sur vos données, sans affecter les performances de vos charges de travail transactionnelles ou unités de requête (UR). Ces offres suppriment la nécessité de pipelines ETL complexes, ce qui rend vos données Azure Cosmos DB accessibles en toute transparence aux moteurs d’analyse. En réduisant le temps de latence des informations, vous pouvez améliorer l'expérience de vos clients et réagir plus rapidement aux changements des conditions du marché ou de l'environnement commercial. Voici quelques exemples de scénarios que vous pouvez réaliser avec des insights rapides sur vos données.
Vous pouvez activer l’analytique zéro ETL et la création de rapports BI sur Azure Cosmos DB à l’aide des options suivantes :
- Mise en miroir de vos données dans Microsoft Fabric
- Activation d’Azure Synapse Link pour accéder aux données à partir d’Azure Synapse Analytics
Option 1 : Mise en miroir de vos données Azure Cosmos DB dans Microsoft Fabric
La mise en miroir vous permet d’intégrer en toute transparence vos données de base de données Azure Cosmos DB dans Microsoft Fabric. Avec zéro ETL, vous pouvez obtenir rapidement des insights métier enrichis sur vos données Azure Cosmos DB à l’aide des fonctionnalités intégrées d’analytique, de BI et d’IA de Fabric.
Vos données opérationnelles Cosmos DB sont répliquées de manière incrémentielle dans Fabric OneLake en quasi-temps réel. Les données dans OneLake sont stockées au format Delta Parquet open source et mises à la disposition de tous les moteurs analytiques dans Fabric. Avec l’accès ouvert, vous pouvez les utiliser avec différents services Azure tels qu’Azure Databricks, Azure HDInsight, etc. OneLake permet également d’unifier votre patrimoine de données pour vos besoins analytiques. Les données mises en miroir peuvent être jointes à d’autres données dans OneLake, telles que Lakehouses, Warehouses ou raccourcis. Vous pouvez également joindre des données Azure Cosmos DB à d’autres sources de base de données mises en miroir telles qu’Azure SQL Database, Snowflake. Vous pouvez interroger des collections ou des bases de données Azure Cosmos DB mises en miroir dans OneLake.
Avec la mise en miroir dans Fabric, vous n’avez pas besoin de regrouper différents services à partir de plusieurs fournisseurs. Au lieu de cela, vous pouvez profiter d’un produit hautement intégré, de bout en bout et facile à utiliser qui est conçu pour simplifier vos besoins d’analyse. Vous pouvez utiliser T-SQL pour exécuter des requêtes d'agrégation complexes et Spark pour l'exploration de données. Vous pouvez accéder en toute transparence aux données des notebooks, utiliser la science des données pour créer des modèles Machine Learning et créer des rapports Power BI à l’aide de Direct Lake optimisé par une intégration riche de Copilot.
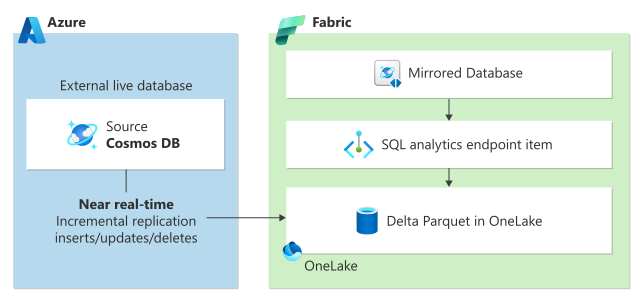
Si vous souhaitez effectuer une analyse de vos données opérationnelles dans Azure Cosmos DB, la mise en miroir fournit :
- Analytique zéro ETL rentable en quasi-temps réel sur les données Azure Cosmos DB, sans impact sur votre consommation d'unités de requête (UR)
- Facilité d’apport de données entre différentes sources dans Fabric OneLake.
- Amélioration des performances des requêtes du moteur SQL traitant les tables delta, avec des optimisations V-Order
- Amélioration du temps de démarrage à froid pour le moteur Spark avec une intégration approfondie avec ML/notebooks
- Intégration en un clic à Power BI avec Direct Lake et Copilot
- Intégration d’applications plus riche pour accéder aux requêtes et aux vues avec GraphQL
- Accès ouvert vers et depuis d'autres services tels que Azure Databricks
Pour bien démarrer avec la mise en miroir, consultez « Bien démarrer avec le didacticiel sur la mise en miroir ».
Option 2 : Azure Synapse Link pour accéder aux données à partir d’Azure Synapse Analytics
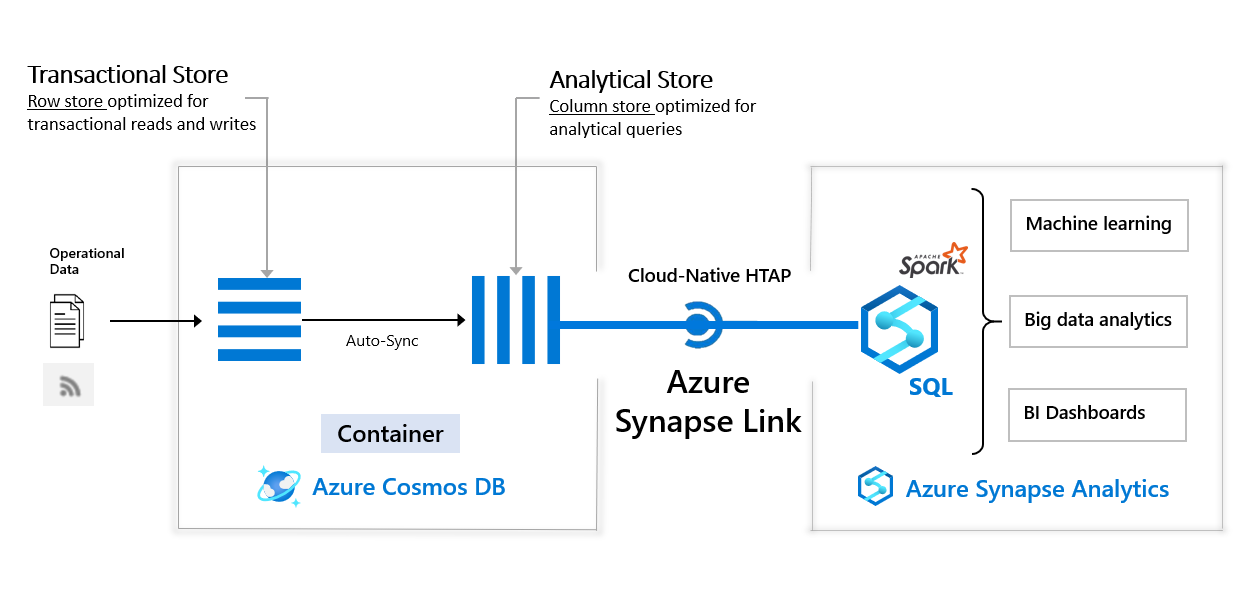
Azure Synapse Link pour Azure Cosmos DB crée une intégration étroite entre Azure Cosmos DB et Azure Synapse Analytics, activant l’analytique zéro ETL en quasi-temps réel sur vos données opérationnelles. Les données transactionnelles sont synchronisées de manière transparente avec le magasin analytique, qui stocke les données dans un format en colonnes optimisé pour l'analyse.
Azure Synapse Analytics peut accéder à ces données dans le magasin analytique, sans déplacement supplémentaire, à l’aide d’Azure Synapse Link. Les analystes d’entreprise, les ingénieurs de données et les scientifiques de données peuvent désormais utiliser Synapse Spark ou Synapse SQL de façon interchangeable pour exécuter des pipelines décisionnels, analytiques et de machine learning en quasi-temps réel.
L’illustration suivante représente l’intégration d’Azure Synapse Link dans Azure Cosmos DB et Azure Synapse Analytics :
Important
La mise en miroir dans Microsoft Fabric est désormais disponible en préversion pour l’API NoSql. Cette fonctionnalité permet de bénéficier de toutes les capacités d’Azure Synapse Link avec de meilleures performances analytiques, la possibilité d’unifier votre patrimoine de données avec Fabric OneLake et d’ouvrir l’accès à vos données dans OneLake avec le format Delta Parquet. Si vous envisagez d’utiliser Azure Synapse Link, nous vous recommandons d’essayer la mise en miroir pour évaluer la compatibilité globale avec votre organisation. Pour commencer la mise en miroir, cliquez ici.
Pour bien démarrer avec Azure Synapse Link, consultez « Bien démarrer avec Azure Synapse Link ».
Analytique en temps réel et BI sur Azure Cosmos DB : autres options
Il existe quelques autres options pour activer l’analytique en temps réel sur les données Azure Cosmos DB :
- Utilisation du flux de modification
- Utilisation du connecteur Spark directement sur Azure Cosmos DB
- Utilisation du connecteur Power BI directement sur Azure Cosmos DB
Bien que ces options soient incluses par souci d'exhaustivité et qu'elles fonctionnent bien avec des requêtes en temps réel sur une seule partition, ces méthodes posent les problèmes suivants pour les requêtes analytiques :
Impact sur les performances de votre charge de travail :
Les requêtes analytiques ont tendance à être complexes et consomment une capacité de calcul importante. Lorsque ces requêtes sont exécutées directement sur vos données Azure Cosmos DB, vous pouvez constater une dégradation des performances de vos requêtes transactionnelles.
Impact sur les coûts :
Lorsque les requêtes analytiques sont exécutées directement sur votre base de données ou vos collections, elles augmentent le besoin d’unités de requête allouées, car les requêtes analytiques ont tendance à être complexes et nécessitent davantage de puissance de calcul. Une utilisation accrue des UR entraîne probablement un impact significatif sur les coûts au fil du temps, si vous exécutez des requêtes d’agrégation.
Au lieu de ces options, nous vous recommandons d'utiliser la mise en miroir dans Microsoft Fabric ou Azure Synapse Link, qui fournissent une analytique zéro ETL, sans affecter les performances des charges de travail transactionnelles ou les unités de requête.