Résilience de la découverte de services (préversion)
Avec la résilience d’Azure Container Apps, vous pouvez empêcher, détecter et récupérer de manière proactive des échecs de demande de service à l’aide de stratégies de résilience simples. Dans cet article, vous allez apprendre à configurer des stratégies de résilience Azure Container Apps lors du lancement de requêtes à l’aide de la découverte du service Azure Container Apps.
Remarque
Actuellement, les stratégies de résilience ne peuvent pas être appliquées aux requêtes effectuées à l’aide de l’API d’appel de service Dapr.
Les stratégies sont en vigueur pour chaque requête adressée à une application conteneur. Vous pouvez adapter des stratégies à l’application conteneur acceptant des demandes avec des configurations telles que :
- Nombre de nouvelles tentatives
- Durée de nouvelle tentative et de délai d’expiration
- Nouvelles tentatives de correspondances
- Erreurs consécutives du disjoncteur et autres
La capture d’écran suivante montre comment une application utilise une stratégie de nouvelle tentative pour tenter de récupérer à partir de requêtes ayant échoué.
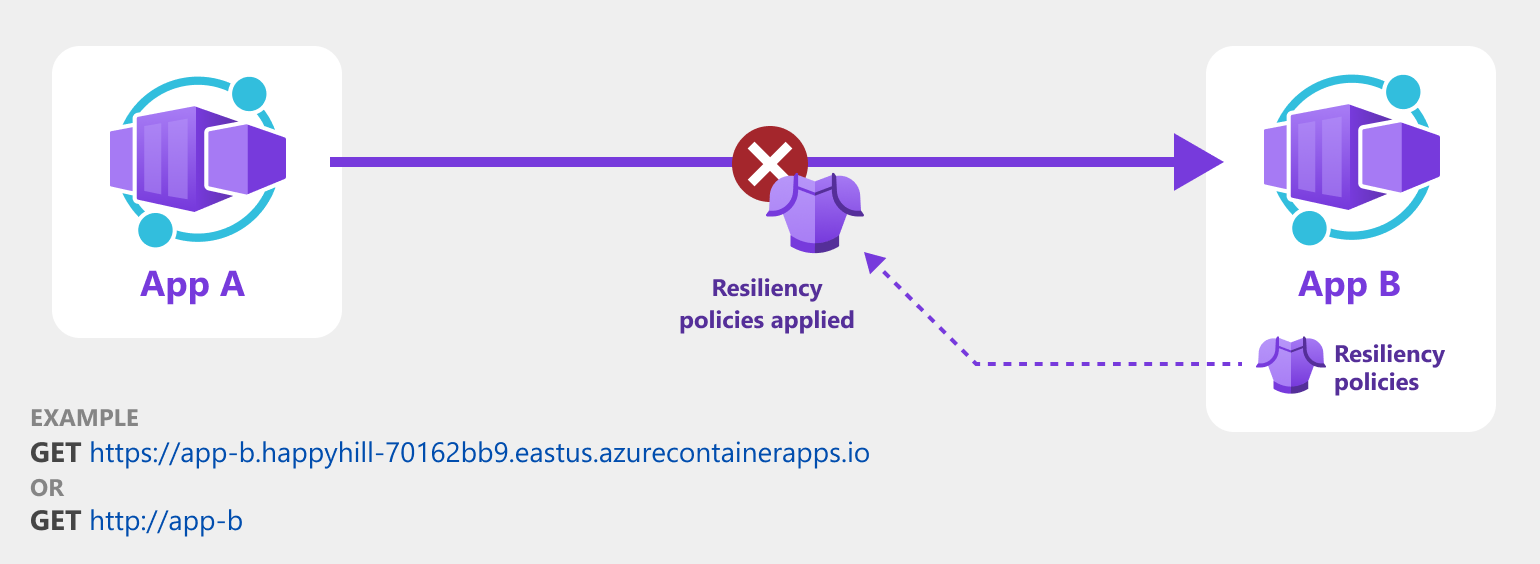
Stratégies de résilience prises en charge
Configurer des stratégies de résilience
Que vous configuriez des stratégies de résilience à l’aide de Bicep, de l’interface CLI ou du portail Azure, vous ne pouvez appliquer qu’une seule stratégie par application conteneur.
Lorsque vous appliquez une stratégie à une application conteneur, les règles sont appliquées à toutes les demandes adressées à cette application conteneur, pas aux demandes effectuées à partir de cette application conteneur. Par exemple, une stratégie de nouvelle tentative est appliquée à une application conteneur nommée App B. Toutes les demandes entrantes adressées à l’application B réessayent automatiquement en cas d’échec. Toutefois, les demandes sortantes envoyées par l’application B ne sont pas garanties de réessayer en cas d’échec.
L’exemple de résilience suivant illustre toutes les configurations disponibles.
resource myPolicyDoc 'Microsoft.App/containerApps/resiliencyPolicies@2023-11-02-preview' = {
name: 'my-app-resiliency-policies'
parent: '${appName}'
properties: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
connectionTimeoutInSeconds: 5
}
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
matches: {
headers: [
{
header: 'x-ms-retriable'
match: {
exactMatch: 'true'
}
}
]
httpStatusCodes: [
502
503
]
errors: [
'retriable-status-codes'
'5xx'
'reset'
'connect-failure'
'retriable-4xx'
]
}
}
tcpRetryPolicy: {
maxConnectAttempts: 3
}
circuitBreakerPolicy: {
consecutiveErrors: 5
intervalInSeconds: 10
maxEjectionPercent: 50
}
tcpConnectionPool: {
maxConnections: 100
}
httpConnectionPool: {
http1MaxPendingRequests: 1024
http2MaxRequests: 1024
}
}
}
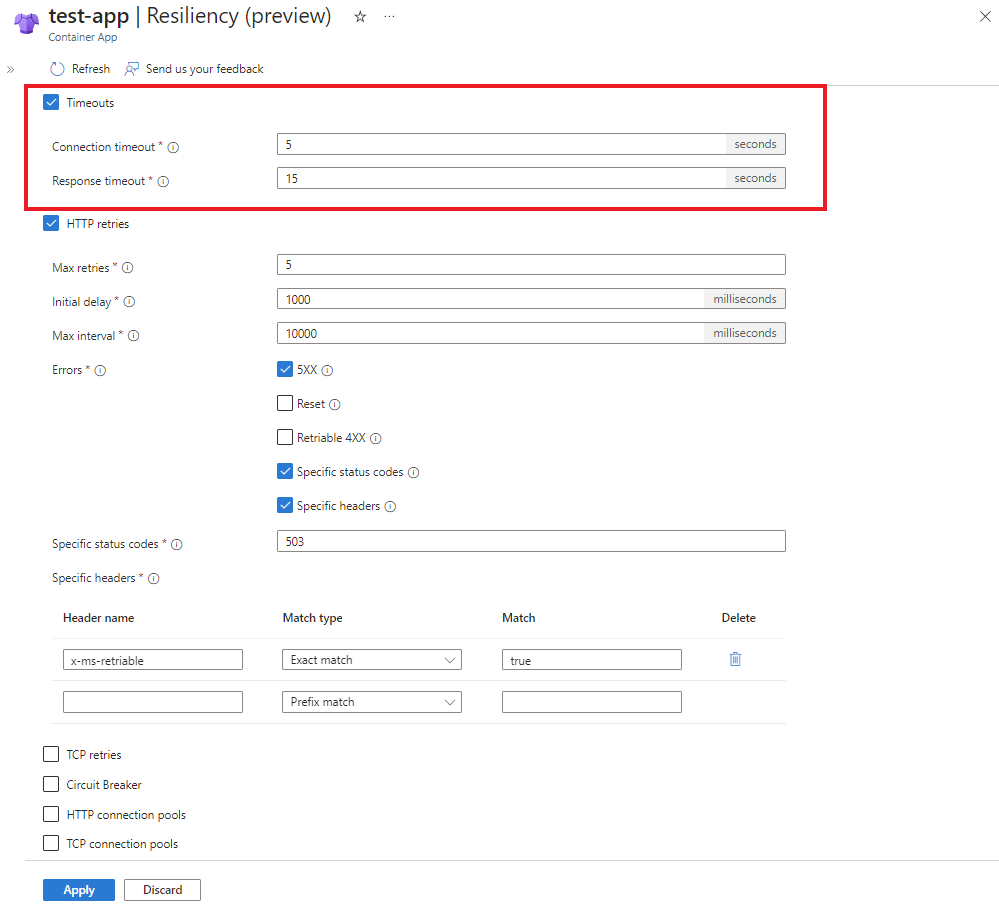

Spécifications de stratégie
Délais d'attente
Les délais d’expiration sont utilisés pour arrêter rapidement les opérations de longue durée. La stratégie de délai d’expiration inclut les propriétés suivantes.
properties: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
connectionTimeoutInSeconds: 5
}
}
| Métadonnées | Requis | Description | Exemple |
|---|---|---|---|
responseTimeoutInSeconds |
Oui | Délai d’attente d’une réponse de l’application conteneur. | 15 |
connectionTimeoutInSeconds |
Oui | Délai d’expiration pour établir une connexion à l’application conteneur. | 5 |
Nouvelles tentatives
Définissez un tcpRetryPolicy ou une stratégie httpRetryPolicy pour les opérations ayant échoué. La stratégie de nouvelle tentative inclut les configurations suivantes.
httpRetryPolicy
properties: {
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
matches: {
headers: [
{
header: 'x-ms-retriable'
match: {
exactMatch: 'true'
}
}
]
httpStatusCodes: [
502
503
]
errors: [
'retriable-headers'
'retriable-status-codes'
]
}
}
}
| Métadonnées | Requis | Description | Exemple |
|---|---|---|---|
maxRetries |
Oui | Nombre maximal de nouvelles tentatives à exécuter pour une requête http ayant échoué. | 5 |
retryBackOff |
Oui | Surveillez les demandes et arrêtez tout le trafic vers le service concerné lorsque les critères de délai d’expiration et de nouvelle tentative sont satisfaits. | N/A |
retryBackOff.initialDelayInMilliseconds |
Oui | Délai entre la première erreur et la première nouvelle tentative. | 1000 |
retryBackOff.maxIntervalInMilliseconds |
Oui | Délai maximal entre les nouvelles tentatives. | 10000 |
matches |
Oui | Définissez les valeurs de correspondance à limiter lorsque l’application doit tenter une nouvelle tentative. | headers, httpStatusCodes, errors |
matches.headers |
Y* | Réessayez lorsque la réponse d’erreur inclut un en-tête spécifique. *Les en-têtes ne sont obligatoires que si vous spécifiez la propriété d’erreur retriable-headers. En savoir plus sur les correspondances d’en-tête disponibles. |
X-Content-Type |
matches.httpStatusCodes |
Y* | Réessayez lorsque la réponse retourne un code d’état spécifique. *Les codes d’état ne sont obligatoires que si vous spécifiez la propriété d’erreur retriable-status-codes. |
502, 503 |
matches.errors |
Oui | Réessayez uniquement lorsque l’application retourne une erreur spécifique. En savoir plus sur les erreurs disponibles. | connect-failure, reset |
Correspondances d’en-tête
Si vous avez spécifié l’erreur retriable-headers, vous pouvez utiliser les propriétés de correspondance d’en-tête suivantes pour réessayer lorsque la réponse inclut un en-tête spécifique.
matches: {
headers: [
{
header: 'x-ms-retriable'
match: {
exactMatch: 'true'
}
}
]
}
| Métadonnées | Description |
|---|---|
prefixMatch |
Les nouvelles tentatives sont effectuées en fonction du préfixe de la valeur d’en-tête. |
exactMatch |
Les nouvelles tentatives sont effectuées en fonction d’une correspondance exacte de la valeur d’en-tête. |
suffixMatch |
Les nouvelles tentatives sont effectuées en fonction du suffixe de la valeur d’en-tête. |
regexMatch |
Les nouvelles tentatives sont effectuées en fonction d’une règle d’expression régulière où la valeur d’en-tête doit correspondre au modèle regex. |
Erreurs
Vous pouvez effectuer des nouvelles tentatives sur l’une des erreurs suivantes :
matches: {
errors: [
'retriable-headers'
'retriable-status-codes'
'5xx'
'reset'
'connect-failure'
'retriable-4xx'
]
}
| Métadonnées | Description |
|---|---|
retriable-headers |
En-têtes de réponse HTTP qui déclenchent une nouvelle tentative. Une nouvelle tentative est effectuée si l’un des en-têtes correspond aux en-têtes de réponse. Obligatoire si vous souhaitez réessayer sur les en-têtes correspondants. |
retriable-status-codes |
Codes d’état HTTP qui doivent déclencher des nouvelles tentatives. Obligatoire si vous souhaitez réessayer sur les codes d’état correspondants. |
5xx |
Réessayez si le serveur répond avec des codes de réponse 5xx. |
reset |
Réessayez si le serveur ne répond pas. |
connect-failure |
Réessayez si une requête a échoué en raison d’une connexion défectueuse avec l’application conteneur. |
retriable-4xx |
Réessayez si l’application conteneur répond avec un code de réponse de 400 séries, comme 409. |
tcpRetryPolicy
properties: {
tcpRetryPolicy: {
maxConnectAttempts: 3
}
}
| Métadonnées | Requis | Description | Exemple |
|---|---|---|---|
maxConnectAttempts |
Oui | Définissez les tentatives de connexion maximales (maxConnectionAttempts) pour réessayer sur les connexions ayant échoué. |
3 |
Disjoncteurs
Les stratégies de disjoncteur spécifient si un réplica d’application conteneur est temporairement supprimé du pool d’équilibrage de charge, en fonction de déclencheurs tels que le nombre d’erreurs consécutives.
properties: {
circuitBreakerPolicy: {
consecutiveErrors: 5
intervalInSeconds: 10
maxEjectionPercent: 50
}
}
| Métadonnées | Requis | Description | Exemple |
|---|---|---|---|
consecutiveErrors |
Oui | Nombre consécutif d’erreurs avant qu’un réplica d’application conteneur ne soit temporairement supprimé de l’équilibrage de charge. | 5 |
intervalInSeconds |
Oui | Durée donnée pour déterminer si un réplica est supprimé ou restauré du pool d’équilibrage de charge. | 10 |
maxEjectionPercent |
Oui | Pourcentage maximal de réplicas d’application conteneur défaillants à éjecter de l’équilibrage de charge. Supprime au moins un hôte, quelle que soit la valeur. | 50 |
Pools de connexions
Le regroupement de connexions d’Azure Container App gère un pool de connexions établies et réutilisables aux applications conteneur. Ce pool de connexions réduit la surcharge liée à la création et à la suppression de connexions individuelles pour chaque requête.
Les pools de connexions vous permettent de spécifier le nombre maximal de demandes ou de connexions autorisées pour un service. Ces limites contrôlent le nombre total de connexions simultanées pour chaque service. Lorsque cette limite est atteinte, les nouvelles connexions ne sont pas établies pour ce service tant que les connexions existantes ne sont pas libérées ou fermées. Ce processus de gestion des connexions empêche les ressources d’être submergées par les requêtes et gère une gestion efficace des connexions.
httpConnectionPool
properties: {
httpConnectionPool: {
http1MaxPendingRequests: 1024
http2MaxRequests: 1024
}
}
| Métadonnées | Requis | Description | Exemple |
|---|---|---|---|
http1MaxPendingRequests |
Oui | Utilisé pour les requêtes http1. Nombre maximal de connexions ouvertes à une application conteneur. |
1024 |
http2MaxRequests |
Oui | Utilisé pour les requêtes http2. Nombre maximal de requêtes simultanées adressées à une application conteneur. |
1024 |
tcpConnectionPool
properties: {
tcpConnectionPool: {
maxConnections: 100
}
}
| Métadonnées | Requis | Description | Exemple |
|---|---|---|---|
maxConnections |
Oui | Nombre maximal de connexions simultanées à une application conteneur. | 100 |
Observabilité de résilience
Vous pouvez effectuer une observabilité de résilience via les métriques et les journaux système de votre application conteneur.
Journaux de résilience
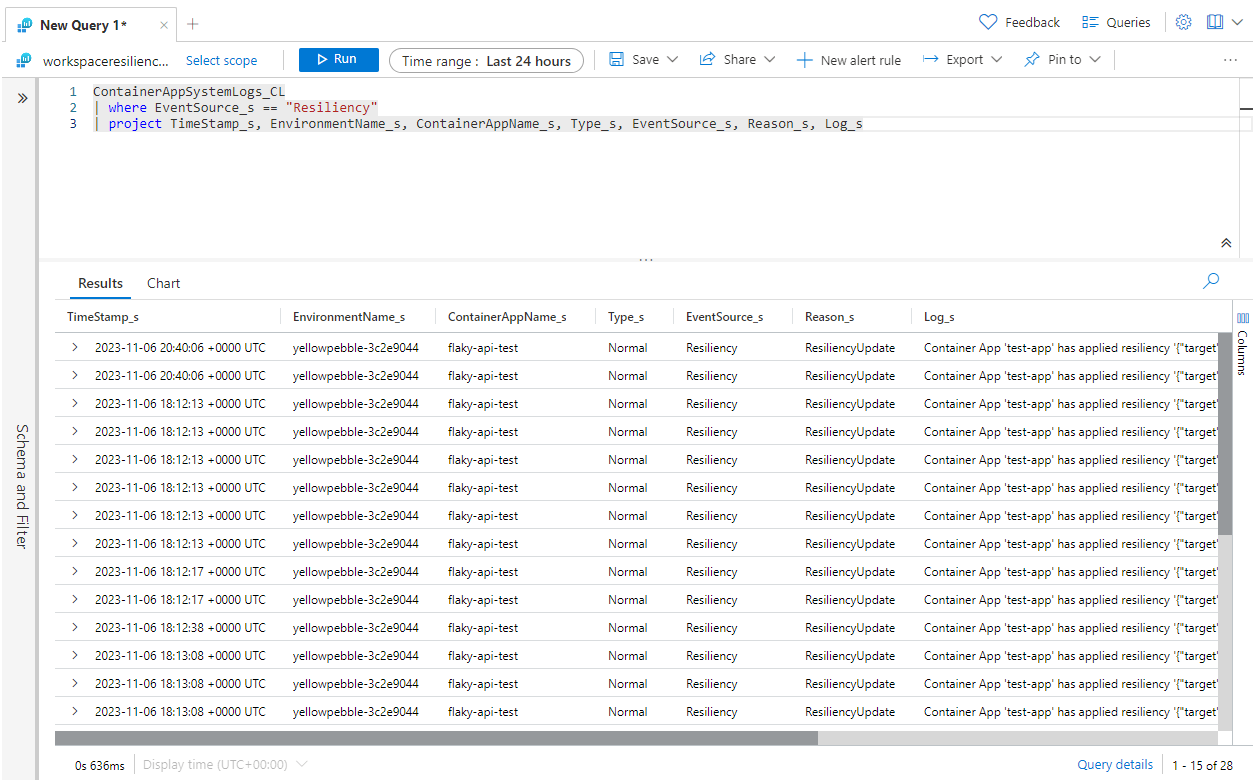
Dans la section Analyse de votre application conteneur, sélectionnez Journaux d’activité.
Dans le volet Journaux, écrivez et exécutez une requête pour rechercher la résilience via les journaux de votre système d’application conteneur. Par exemple, exécutez une requête similaire à ce qui suit pour rechercher des événements de résilience et afficher leur :
- Horodatage
- Nom de l’environnement
- Nom de l’application conteneur
- Type de résilience et raison
- Messages des journaux
ContainerAppSystemLogs_CL
| where EventSource_s == "Resiliency"
| project TimeStamp_s, EnvironmentName_s, ContainerAppName_s, Type_s, EventSource_s, Reason_s, Log_s
Cliquez sur Exécuter pour exécuter la requête et afficher les résultats.
Métriques de résilience
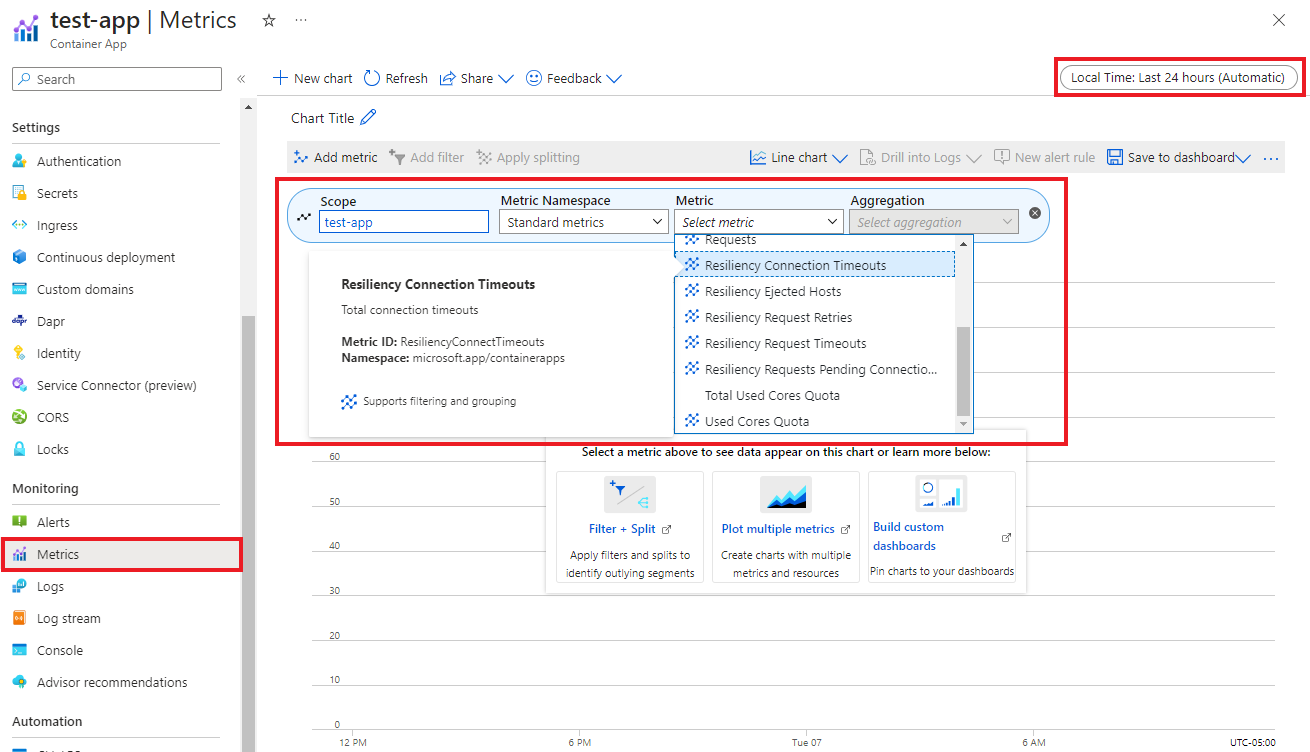
Dans le menu Analyse de votre application conteneur, sélectionnez Métriques. Dans le volet Métriques, sélectionnez les filtres suivants :
- Étendue au nom de votre application conteneur.
- L’espace de noms de métriquesMétriques Standard.
- Métriques de résilience dans le menu déroulant.
- Comment vous souhaitez que les données agrégées dans les résultats (par moyenne, par maximum, etc.).
- Durée (30 dernières minutes, dernières 24 heures, etc.).
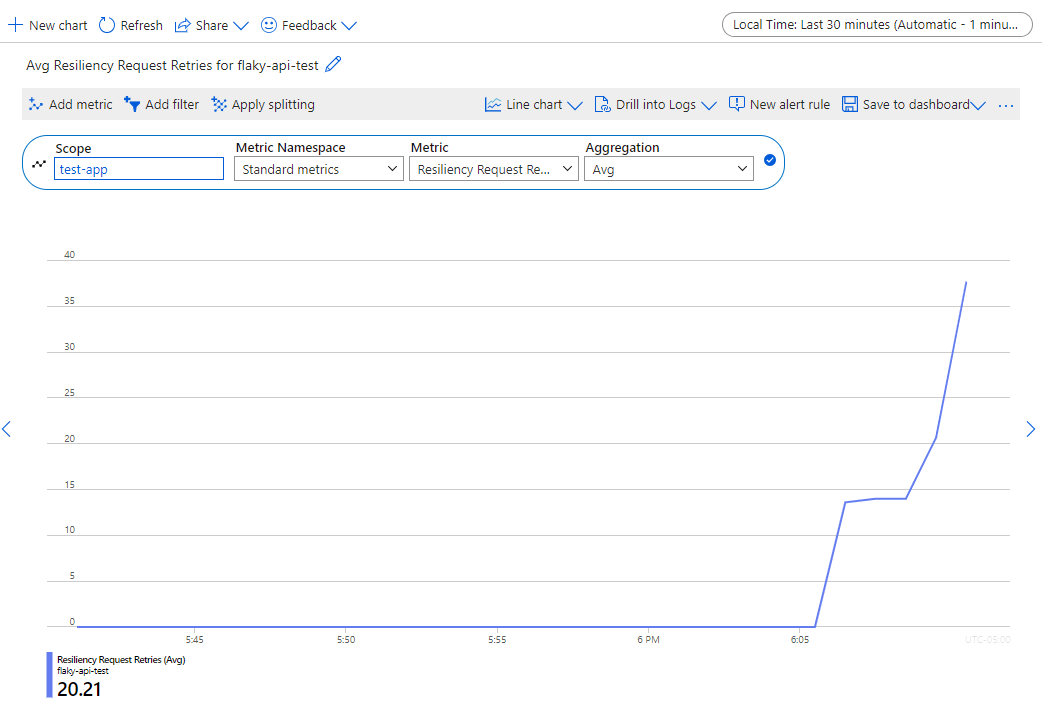
Par exemple, si vous définissez la métrique Nouvelles tentatives de demande de résiliencedans l’étendue test-app avec agrégation moyenne pour effectuer une recherche dans un délai de 30 minutes, les résultats ressemblent à ce qui suit :
Contenu connexe
Découvrez comment fonctionne la résilience pour composants Dapr dans Azure Container Apps.