Provisionner l’analytique à l’échelle du cloud
Processus de déploiement de la zone d’atterrissage de gestion des données
L’équipe d’exploitation de la plateforme de données est responsable du déploiement d’une zone d’atterrissage de gestion des données. La zone d’atterrissage de gestion des données doit avoir son propre référentiel géré par l’équipe d’exploitation de la plateforme de données.
Attention
Créez et déployez une zone d’atterrissage de gestion des données avant le déploiement de toute zone d’atterrissage de données.
Processus de déploiement de la zone d’atterrissage des données
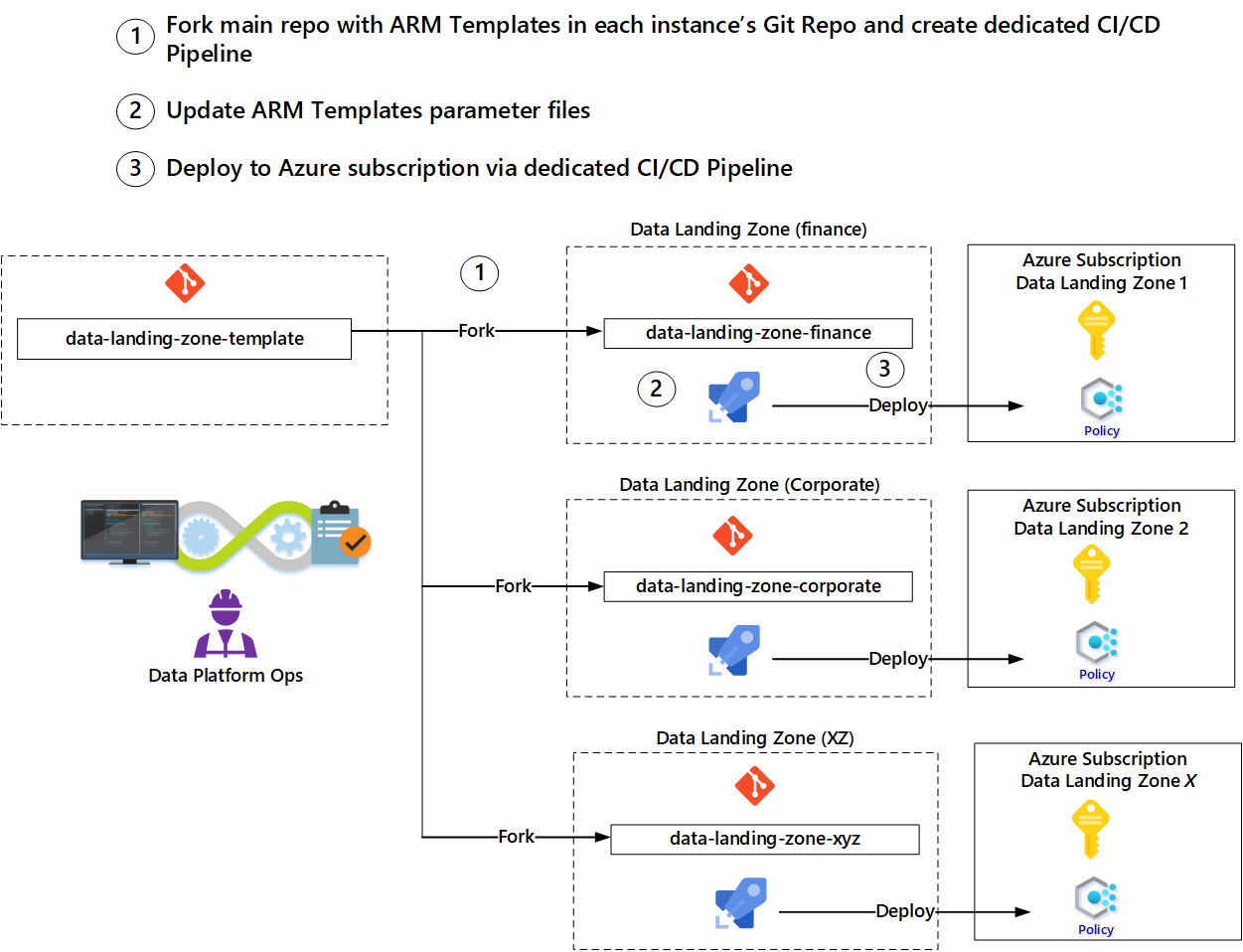
Les équipes peuvent utiliser les modèles fournis par l’équipe d’exploitation de la plateforme de données pour éviter de commencer à partir de zéro pour chaque ressource. Nous vous recommandons d’utiliser un modèle de duplication pour automatiser le déploiement d’une nouvelle zone d’atterrissage.
Par exemple, une équipe des opérations de zone d’atterrissage de données demande une nouvelle zone d’atterrissage de données à l’aide d’un outil de gestion informatique ou de Power Apps. Après l’approbation de la demande, démarrez le workflow suivant à l’aide des paramètres de la demande :
- Déployez un nouvel abonnement pour la nouvelle zone d’atterrissage des données.
- Dupliquez la branche primaire du modèle de zone d’atterrissage des données pour créer un nouveau référentiel.
- Créez une connexion au service dans le nouveau référentiel.
- Mettez à jour les paramètres dans le nouveau référentiel en fonction des paramètres de la demande.
- Créez un pipeline de déploiement pour déployer les services, déclenchés par l’archivage des paramètres mis à jour.
- Informez l’équipe d’exploitation de la zone d’atterrissage des données que la nouvelle zone d’atterrissage est disponible.
L’équipe d’exploitation de la zone d’atterrissage des données peut à présent modifier ou ajouter des modèles Azure Resource Manager.
Ce workflow peut être automatisé à l’aide de plusieurs ensembles de services sur la plateforme Azure. Gérez certaines étapes, telles que le changement de nom des paramètres dans les fichiers de paramètres, à l’aide de pipelines CI/CD. D’autres étapes peuvent être exécutées à l’aide d’autres outils d’orchestration de workflow, tels que Logic Apps.
Le modèle de duplication permet aux équipes de mettre à jour leurs modèles à partir des modèles originaux utilisés pour les dupliquer. En outre, si des améliorations ou de nouvelles fonctionnalités sont implémentées dans les référentiels de modèles, les équipes d’exploitation peuvent les intégrer dans leur duplication.
Adoptez les meilleures pratiques pour les référentiels, par exemple :
- Sécurisez la branche primaire.
- Utilisez des branches pour les modifications, les mises à jour et les améliorations.
- Définissez les propriétaires du code qui approuvent les demandes de tirage avant de fusionner les modifications dans la branche primaire.
- Validez les branches par le biais de tests automatisés.
- Limitez le nombre d’actions et de personnes au sein de l’équipe, par exemple qui peut déclencher des pipelines de build et de mise en production.
Conseil
Coordonnez les activités entre les équipes pour vous assurer que les améliorations ou les nouvelles fonctionnalités des modèles d’origine sont répliquées dans toutes les instances de zones d’atterrissage des données. Les équipes d’exploitation peuvent extraire les modifications de modèle d’origine dans leur duplication.
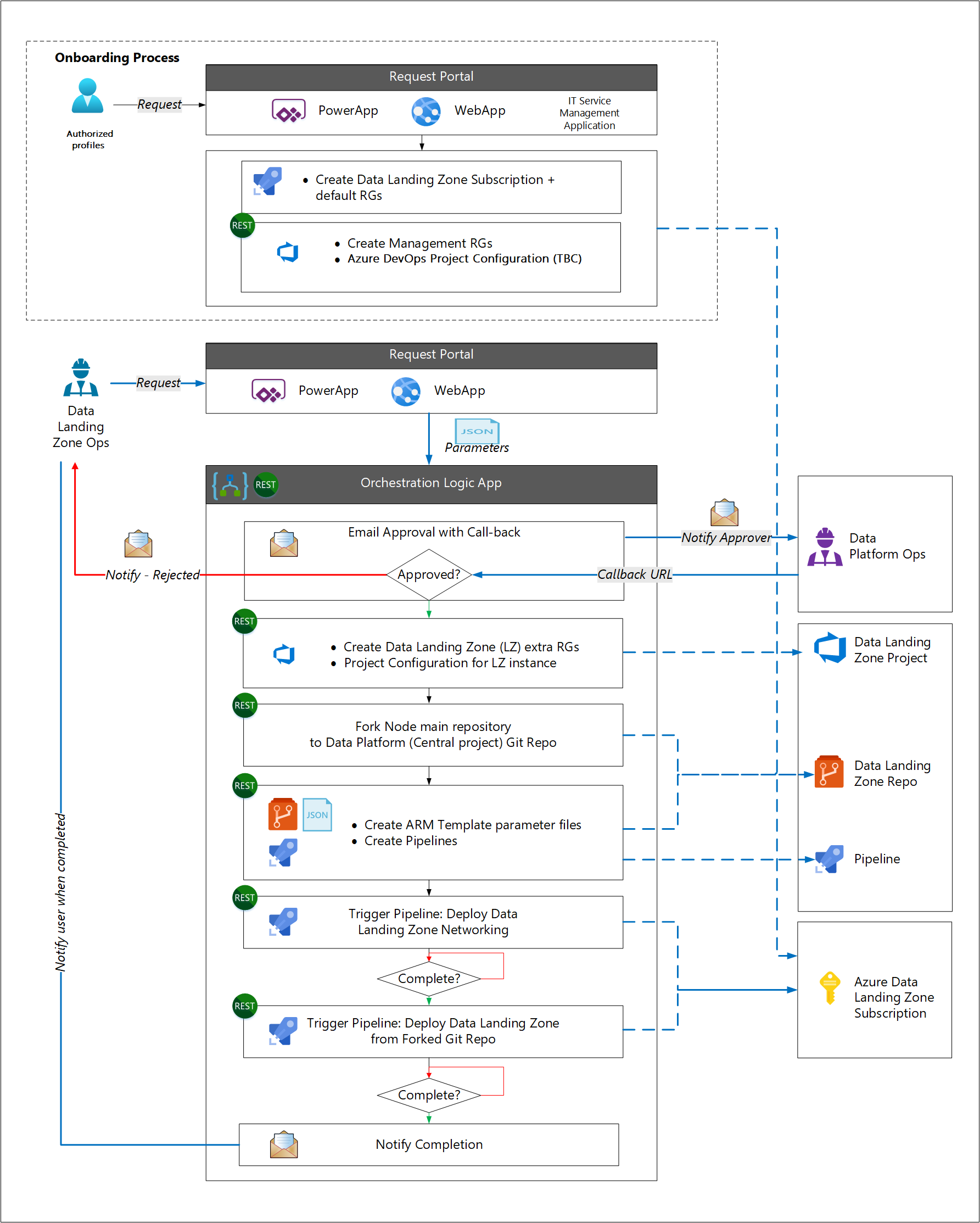
Le processus d’intégration est distinct du processus de déploiement de la zone d’atterrissage des données. Cette séparation repose sur l’hypothèse que la plupart des organisations disposent d’un processus de déploiement d’abonnement Azure standard dans le cadre de leur modèle d’exploitation cloud. Le processus d’intégration déploie des composants d’entreprise standard (par exemple un outil de gestion des services informatiques tiers). Les composants propres à la zone d’atterrissage des données sont déployés à l’étape suivante.
Aucune API Git n’est disponible pour cloner/mettre à jour/valider/transmettre la solution d’automatisation proposée. Notre approche consiste donc à utiliser un compte Azure Automation contenant des runbooks PowerShell qui :
- Configurent une zone d’atterrissage des données.
- Dupliquent le référentiel principal vers un référentiel Git de plateforme de données
- Configurent les configurations de sous-réseau pour la zone d’atterrissage des données.
- Configurer Microsoft Entra ID
Les runbooks utilisent les fonctions Git du module PowerShell GitAutomation pour l’utilisation des référentiels Git. En installant ce module à l’intérieur d’un compte Azure Automation, les utilisateurs peuvent effectuer des opérations de création, de clonage, de requête, de transmission push, d’extraction et de validation dans des référentiels Git. L’image suivante montre le module GitAutomation installé dans un compte Azure Automation :

Utilisez la fonction Copy-GitRepository du module GitAutomation pour cloner le dépôt Git principal à partir de l’URL spécifiée par URL vers le chemin Git de la plateforme de données spécifié par DestinationPath.
Cette approche du déploiement de la zone d’atterrissage des données est flexible, tout en veillant à ce que les actions soient conformes aux exigences de l’organisation. La gestion de cycle de vie est activée par l’application de nouvelles fonctionnalités ou optimisations à partir des modèles d’origine.
Processus de déploiement d’application de données
Une fois qu’une zone d’atterrissage des données a été créée, l’intégration peut démarrer pour les équipes d’applications de données. Les équipes d’exploitation de la plateforme de données ou de la zone d’atterrissage des données accordent l’approbation du déploiement.
Le déploiement s’effectue directement à l’aide des outils DevOps ou il est appelé via des pipelines/workflows exposés en tant qu’API. Comme pour la zone d’atterrissage des données, le déploiement commence par la duplication du référentiel d’application de données d’origine.
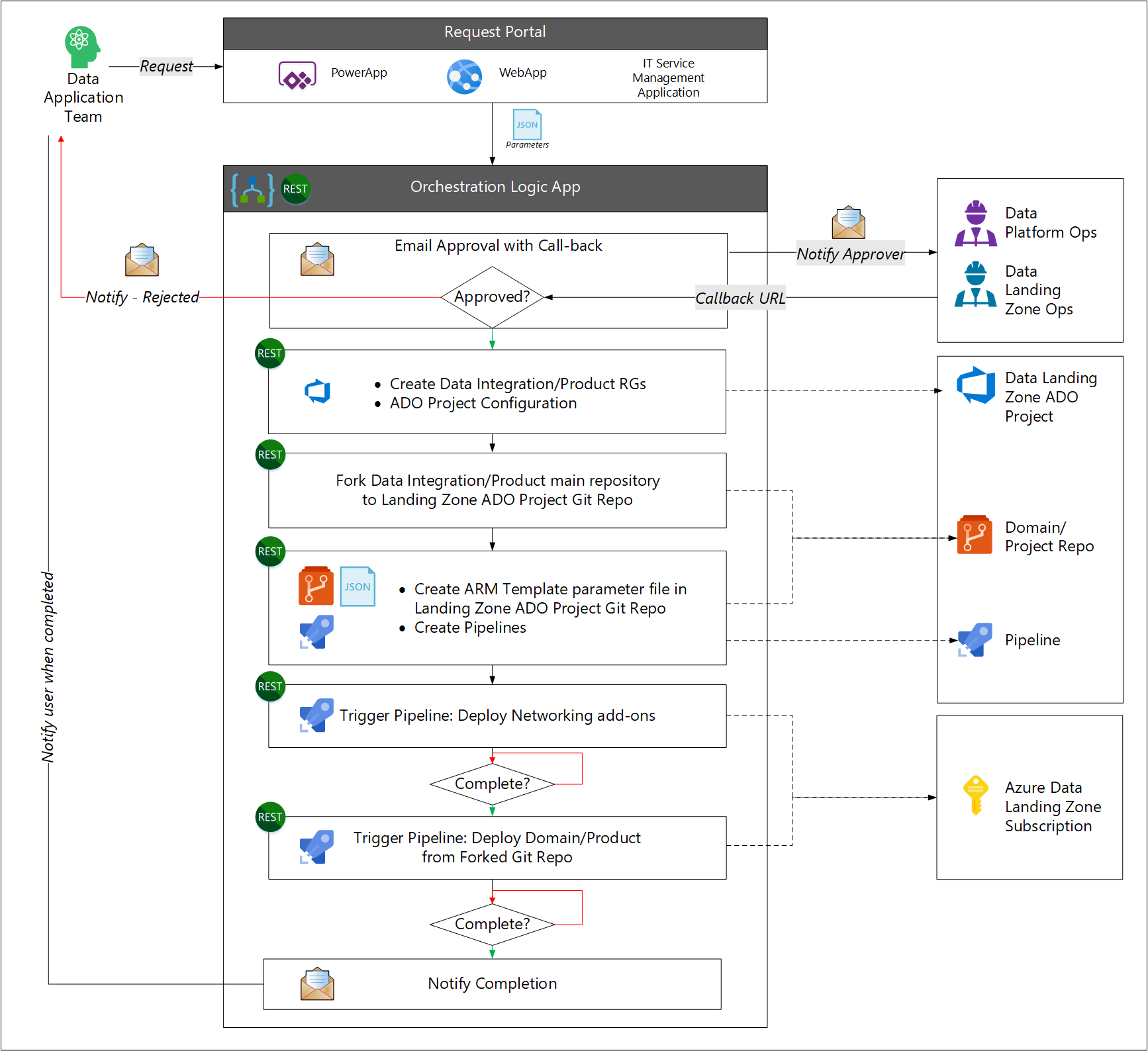
- L’utilisateur effectue une demande de nouveaux services d’application de données.
- Le processus de workflow demande l’approbation de l’équipe d’exploitation de la plateforme de données ou de la zone d’atterrissage des données.
- Le workflow appelle l’API Gestion des services informatiques pour créer les groupes de ressources nécessaire et créer une connexion au service Azure DevOps. Le workflow affecte une équipe au projet Azure DevOps.
- Le flux de travail duplique le référentiel d’origine d’application de données d’origine pour créer le projet de destination Azure DevOps.
- Le workflow crée un fichier de paramètres de modèle Azure Resource Manager et des pipelines.
- Le flux de travail démarre ensuite un pipeline Azure pour créer les exigences de mise en réseau et un autre pipeline Azure pour déployer les services d’application de données.
- Le workflow avertit l’utilisateur de son achèvement.
Conseil
Si vous débutez dans le domaine du DataOps, consultez le labo pratique DataOps pour l’entrepôt de données moderne dans le Centre des architectures Azure. Le scénario du labo décrit la façon dont un bureau d’urbanisme fictif peut utiliser cette solution de déploiement. La solution de déploiement fournit un pipeline de données de bout en bout qui suit le modèle architectural moderne d’entrepôt de données ainsi que les processus DevOps et DataOps correspondants pour permettre l’utilisation du parking et la prise de décisions métier éclairées.
Récapitulatif
Les modèles ci-dessus assurent le contrôle, l’agilité, le libre-service et la gestion du cycle de vie des stratégies.
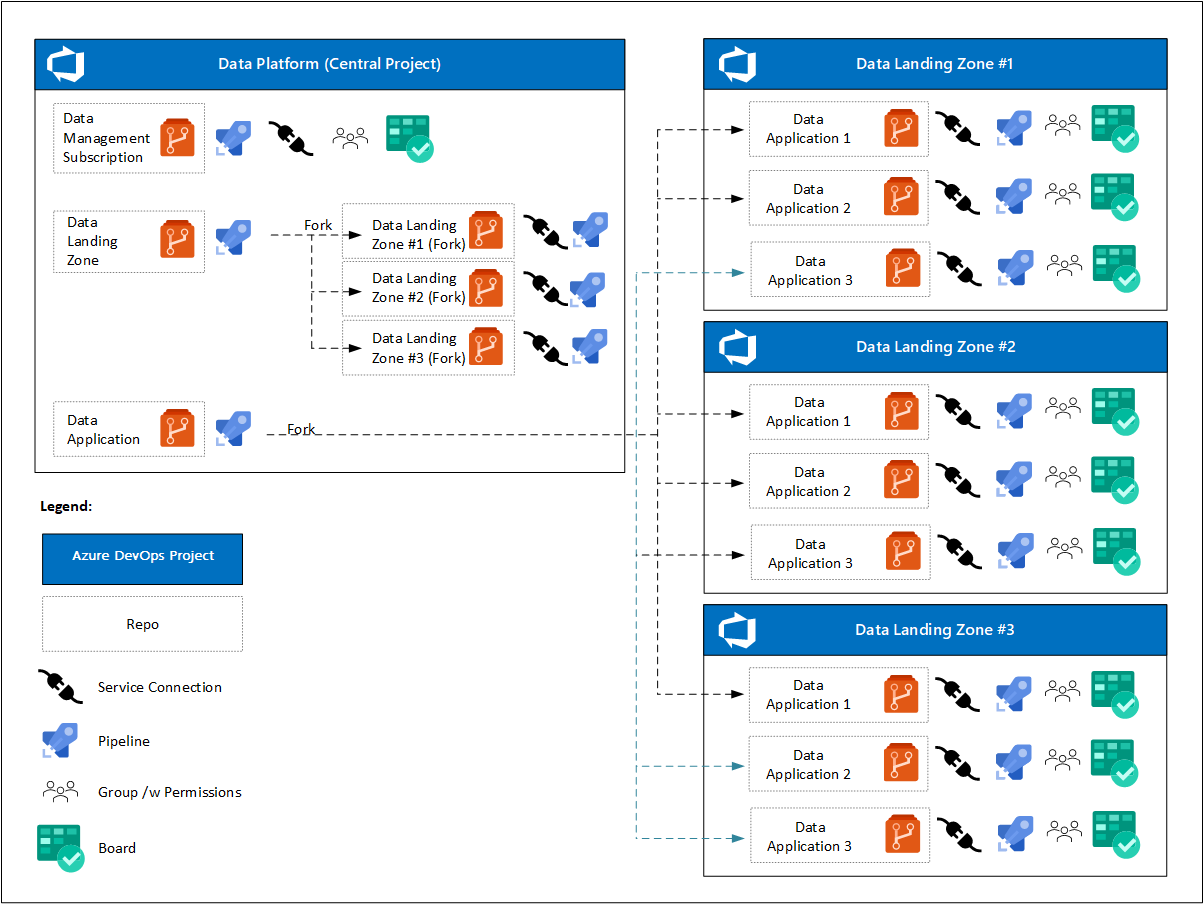
Au début du projet, la plateforme de données a un seul projet Azure DevOps avec une ou plusieurs instances Azure Boards. Les équipes DevOps individuelles se concentrent sur :
- Un référentiel pour la zone d’atterrissage de gestion des données, les pipelines et une connexion de service à l’environnement cloud.
- Un référentiel de modèles pour la zone d’atterrissage des données, des pipelines pour déployer une instance de zone d’atterrissage des données et des connexions de service à des environnements cloud.
- Un référentiel de modèles pour les services de produits de données, des pipelines pour déployer une instance de produit de données et des connexions de service à des environnements cloud. Ces connexions sont dupliquées à partir de la zone d’atterrissage des données Azure DevOps Projects.
Une fois que les zones d’atterrissage des données ont été déployées, l’analytique à l’échelle du cloud présente les exigences suivantes :
- Chaque zone d’atterrissage de données a son propre projet Azure DevOps avec une ou plusieurs instances Azure Boards.
- Pour chaque application de données, la fourche de projet Azure DevOps de zone d’atterrissage des données est créée après approbation de la demande.
- Chaque application de données inclut :
- Une connexion à un service.
- Un pipeline inscrit.
- Une équipe DevOps ayant accès à son tableau et son référentiel Azure.
- Un autre jeu de stratégies pour le référentiel dupliqué.
Pour contrôler le déploiement des application de données, procédez comme suit :
- L’équipe d’exploitation de la zone d’atterrissage des données détient et sécurise la branche principale du référentiel.
- Seule la branche principale est utilisée pour le déploiement dans des environnements de test et de production.
- Les branches de fonctionnalités peuvent être déployées dans des environnements de développement.
- Les branches de fonctionnalités sont détenues par les équipes DataOps. Elles sont utilisées pour tester les fonctionnalités nouvelles ou modifiées.
- Les équipes DataOps peuvent fusionner des branches de fonctionnalités dans d’autres branches de fonctionnalités sans approbation.
- Les équipes DataOps créent une demande de tirage pour fusionner les branches de fonctionnalités dans la branche primaire, et l’équipe d’exploitation de la zone d’atterrissage des données fournit l’approbation.
- Les nouvelles fonctionnalités ou améliorations apportées aux modèles d’origine sont fusionnées dans le référentiel dupliqué pour les maintenir à jour.