Processus de gouvernance des données
Il existe quatre catégories de processus de gouvernance des données.
| Catégorie de processus | Processus |
|---|---|
| processus de découverte de données, pour comprendre le paysage des données | Un processus de découverte, de cartographie et de catalogage des données et des entités de données Processus de découverte de profilage des données pour déterminer la qualité des données Un processus de classification des données sensibles et de gouvernance Processus de découverte de la maintenance des données pour l’analyse CRUD, par exemple à partir de fichiers journaux, pour comprendre l’utilisation et la maintenance des données telles que les données de référence dans l’entreprise |
| processus de définition de gouvernance des données | Créer et gérer un vocabulaire métier courant dans un glossaire métier définissent des entités de données, notamment des données de référence, des noms d’attributs de données, des règles d’intégrité des données et des formats valides Définir des données de référence pour normaliser les ensembles de code dans l’entreprise Définir des schémas de classification de gouvernance des données pour étiqueter les données afin de déterminer comment les régir Définir des stratégies et des règles de gouvernance des données pour régir les cycles de vie des entités de données et des documents Définir les métriques de réussite et le seuil |
| processus de gouvernance des données et de mise en œuvre des règles | Processus permettant d’automatiser l’application et l’application des stratégies et règles de gouvernance des données Processus permettant d’appliquer et de faire respecter manuellement des stratégies et des règles Processus de gouvernance des données pilotés par les événements, à la demande et pilotés par l’heure publiés en tant que services pouvant être appelés pour régir : Ingestion des données : catalogage, classification, attribution de propriétaire et stockage Qualité des données Sécurité de l’accès aux données Confidentialité des données Utilisation des données, par exemple, y compris le partage et pour garantir que les données sous licence sont utilisées uniquement à des fins approuvées Maintenance des données, telles que les données de référence Rétention des données Données de référence et synchronisation des données de référence |
| processus de supervision | Surveiller et auditer l’activité d’utilisation des données, la qualité des données, la sécurité de l’accès aux données, la confidentialité des données, la maintenance des données et la rétention des données Surveiller la détection et la résolution des violations de règle de stratégie |
Le vocabulaire métier commun doit être défini dans un glossaire métier au sein d’un catalogue de données.
Les groupes de travail de gouvernance des données planifient et développent la définition des données et l’amélioration de domaines de données spécifiques (par exemple, le client ou le fournisseur) ; mettre à jour le tableau de contrôle de gouvernance des données en cours ; et gérer la gestion de la gestion au sein de l’entreprise pour un domaine spécifique. Chaque groupe de travail doit prendre la responsabilité de définir une entité de données ou une zone de sujet de données spécifique, telle que plusieurs entités associées. Plusieurs entités de données du vocabulaire, ainsi que les stratégies et les règles, peuvent ensuite être travaillées en parallèle. Pour plus d’informations, consultez rôles et responsabilités de gouvernance des données
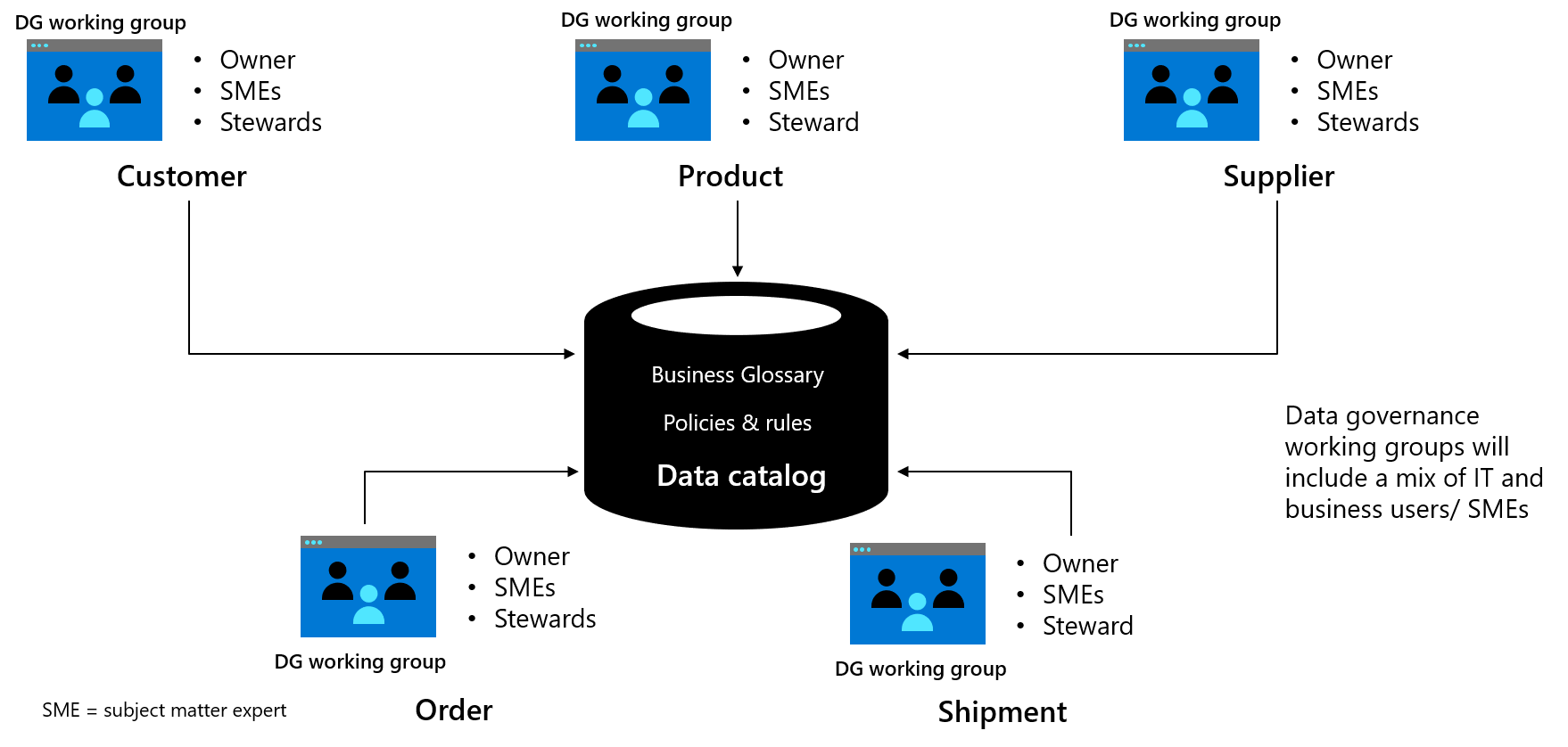 Figure 1 : Exemple de groupe de travail de gouvernance des données
Figure 1 : Exemple de groupe de travail de gouvernance des données
L’intégration du glossaire métier catalogue à d’autres technologies est ensuite nécessaire pour obtenir des noms de données communs cohérents dans toutes les technologies. Voici quelques exemples d’autres technologies à intégrer :
- Outils d'extraction, transformation et chargement (ETL)
- Outils de modélisation des données
- Outils décisionnels, systèmes de gestion des bases de données
- Gestion des données de référence
- Outils de virtualisation des données
- Outils de développement logiciel
Une bonne pratique pour créer un vocabulaire métier commun consiste à développer un modèle de concept de données. Ce modèle utilise une approche de haut en bas pour identifier les concepts de données qui peuvent être utilisés en tant qu’entités de données dans un vocabulaire métier commun. Différents groupes de travail de gouvernance des données peuvent ensuite être affectés à chaque concept de données (entité) ou à un groupe de concepts de données connexes (domaine d’objet). Ces groupes de travail sont chargés de gérer différentes entités de données dans le paysage.
Lors de la création d’un vocabulaire métier commun, vous pouvez utiliser des logiciels de catalogue de données pour découvrir automatiquement les données qui existent dans plusieurs magasins de données. Ce logiciel permet d’identifier tous les attributs associés à des entités de données spécifiques, qui est une approche ascendante.
Plusieurs groupes de travail peuvent créer rapidement un vocabulaire métier commun en combinant l’approche descendante d’un modèle de concept de données avec l’approche ascendante de la découverte automatisée des données.
L’utilisation d’un catalogue de données pour la découverte automatisée des données permet de mapper des données disparates à un vocabulaire commun. Le catalogue de données peut vous aider à comprendre où se trouvent les données de chaque entité de données particulière dans le glossaire métier dans l’entreprise.
Stratégies et règles pour régir les données à différents points du cycle de vie
Les stratégies de gouvernance des données décrivent un ensemble de règles pour contrôler l’intégrité, la qualité, la sécurité d’accès, la confidentialité et la rétention des données. Il existe différents types de stratégie qui incluent :
- Stratégies d’intégrité des données, telles que les valeurs valides, l’intégrité référentielle.
- Stratégies de qualité des données avec normalisation des données, nettoyage et règles de correspondance.
- Stratégies de protection des données avec des règles de sécurité d’accès et de confidentialité des données.
- Stratégies de rétention des données pour gérer le cycle de vie avec des règles de rétention, d’archivage et de sauvegarde. Plusieurs versions d’une stratégie peuvent être nécessaires pour régir les mêmes données entre différentes juridictions juridiques.
Le schéma de classification de confidentialité des données a cinq niveaux de classification :
- Public
- Utilisation interne uniquement
- Confidentiel
- Données personnelles sensibles
- Restreint
Régir les données en combinant ce schéma de classification avec des stratégies et des règles. Utilisez chacun des cinq niveaux pour étiqueter des données, telles que des données personnelles sensibles. En créant des règles pour les données personnelles sensibles et en attachant ces règles à une stratégie, vous créez une stratégie pour les données personnelles sensibles. Vous pouvez attacher la stratégie à l’étiquette de données personnelles sensibles, puis attacher l’étiquette de données personnelles sensibles aux données. De cette façon, toutes les données étiquetées comme des données personnelles sensibles sont soumises aux mêmes stratégies et règles. Ce processus est connu sous le nom de gestion de la stratégie basée sur les étiquettes. Il est flexible, car une règle individuelle ou une stratégie peut être modifiée indépendamment. Toutes les données étiquetées sensibles sont régies par les nouvelles règles. De même, une étiquette de données personnelles sensible peut être détachée des données et une étiquette confidentielle utilisée à la place. Dans ce cas, les données deviennent régies instantanément par un nouvel ensemble de stratégies et de règles associées à l’étiquette confidentielle.
Après avoir défini des stratégies et des règles dans un catalogue de données pour chaque classe d’un schéma de classification de gouvernance des données, elles peuvent être transmises à d’autres technologies à partir d’un catalogue de données, via des API, pour qu’elles s’appliquent. Au lieu de cela, une plateforme de gestion des données commune qui peut se connecter à plusieurs magasins de données peut potentiellement les appliquer.
Il doit ensuite être possible de surveiller la qualité des données, la confidentialité, la sécurité d’accès, l’utilisation, la maintenance et la rétention d’entités de données spécifiques tout au long de leur cycle de vie.