Accélérer l’analytique en temps réel du Big Data au moyen du connecteur Spark
S’applique à : ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Notes
Depuis septembre 2020, ce connecteur n’est plus activement géré. Toutefois, le connecteur Apache Spark pour SQL Server et Azure SQL est désormais disponible, avec une prise en charge des liaisons Python et R, une interface plus facile à utiliser pour l’insertion en bloc de données, et de nombreuses autres améliorations. Nous vous encourageons vivement à évaluer et à utiliser ce nouveau connecteur au lieu de celui-ci. Les informations relatives à l’ancien connecteur (cette page) sont conservées uniquement à des fins d’archivage.
Le connecteur Spark permet aux bases de données dans Azure SQL Database, Azure SQL Managed Instance et SQL Server de jouer le rôle de source de données d’entrée ou de récepteur de données de sortie pour les travaux Spark. Il vous permet d’utiliser des données transactionnelles en temps réel dans l’analytique du Big Data et de conserver les résultats pour des requêtes ad hoc ou des rapports. Par rapport au connecteur JDBC intégré, ce connecteur offre la possibilité d’insérer des données en bloc dans votre base de données. Il peut donner de meilleurs résultats que l’insertion ligne par ligne et atteindre des performances entre 10 et 20 fois plus rapides. Le connecteur Spark prend en charge l’authentification avec Microsoft Entra ID (anciennement Azure Active Directory) pour se connecter à Azure SQL Database et Azure SQL Managed Instance, ce qui vous permet de connecter votre base de données à partir d’Azure Databricks à l’aide de votre compte Microsoft Entra. Il fournit des interfaces similaires à celles du connecteur JDBC intégré. Effectuer la migration de vos travaux Spark existants pour utiliser ce nouveau connecteur est très simple.
Remarque
Microsoft Entra ID était précédemment connu sous le nom d’Azure Active Directory (Azure AD).
Télécharger et créer un connecteur Spark
Le référentiel GitHub de l’ancien connecteur, précédemment lié à partir de cette page, n’est pas activement géré. À la place, nous vous encourageons vivement à évaluer et à utiliser ce nouveau connecteur.
Versions officielles prises en charge
| Composant | Version |
|---|---|
| Apache Spark | 2.0.2 ou version ultérieure |
| Scala | 2.10 ou version ultérieure |
| Pilote Microsoft JDBC pour SQL Server | 6.2 ou version ultérieure |
| Microsoft SQL Server | SQL Server 2008 ou version ultérieure |
| Azure SQL Database | Prise en charge |
| Azure SQL Managed Instance | Prise en charge |
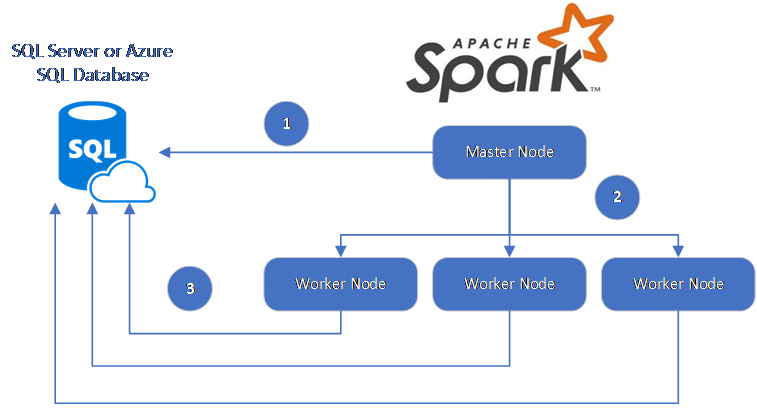
Le connecteur Spark utilise le Pilote JDBC Microsoft pour SQL Server afin de déplacer des données entre les nœuds Worker Spark et les bases de données :
Le flux de données est le suivant :
- Le nœud principal Spark se connecte à des bases de données dans SQL Database ou SQL Server et charge les données à partir d’une table spécifique ou à l’aide d’une requête SQL spécifique.
- Le nœud principal Spark distribue les données aux nœuds de rôle de travail à des fins de transformation.
- Le nœud Worker se connecte aux bases de données qui se connectent à SQL Database ou SQL Server et écrit les données dans la base de données. L’utilisateur peut choisir d’utiliser l’insertion ligne par ligne ou l’insertion en bloc.
Le diagramme suivant illustre le flux de données.
Générer un connecteur Spark
Actuellement, le projet de connecteur utilise maven. Pour créer le connecteur sans dépendances, vous pouvez exécuter :
- Un package propre mvn
- Les dernières versions du fichier JAR téléchargées à partir du dossier release
- Inclure le JAR Spark SQL Database
Se connecter et lire des données à l’aide du connecteur Spark
Vous pouvez vous connecter à des bases de données dans SQL Database et SQL Server à partir d’un travail Spark pour lire ou écrire des données. Vous pouvez également exécuter une requête DML ou DDL dans des bases de données dans SQL Database et SQL Server.
Lire des données à partir d’Azure SQL et SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Lecture de données à partir d’Azure SQL et SQL Server avec une requête SQL spécifiée
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Écrire des données dans Azure SQL et SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Acquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Exécuter une requête DML ou DDL dans Azure SQL et SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Se connecter depuis Spark à l’aide de l’authentification Microsoft Entra
Vous pouvez vous connecter à SQL Database et SQL Managed Instance à l’aide de l’authentification Microsoft Entra. Utilisez l’authentification Microsoft Entra pour gérer de manière centralisée les identités des utilisateurs de base de données et comme alternative à l’authentification SQL.
Connexion à l’aide du mode d’authentification ActiveDirectoryPassword
Configuration requise
Si vous utilisez le mode d’authentification ActiveDirectoryPassword, vous devez télécharger microsoft-authentication-library-for-java et ses dépendances, puis les inclure dans le chemin de build Java.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Connexion à l’aide d’un jeton d’accès
Configuration requise
Si vous utilisez le mode d’authentification par jeton d’accès, vous devez télécharger microsoft-authentication-library-for-java et ses dépendances, puis les inclure dans le chemin de build Java.
Consultez Utiliser l’authentification Microsoft Entra pour savoir comment obtenir un jeton d’accès à votre base de données dans Azure SQL Database ou Azure SQL Managed Instance.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Écrire des données à l’aide de l’insertion en bloc
Le connecteur JDBC traditionnel écrit des données dans votre base de données en utilisant l’insertion ligne par ligne. Vous pouvez utiliser le connecteur Spark pour écrire des données dans Azure SQL et SQL Server en utilisant l’insertion en bloc. Ce connecteur améliore considérablement les performances d’écriture lors du chargement de grands jeux de données ou de données dans des tables où un index columnstore est utilisé.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Étapes suivantes
Si ce n’est déjà fait, téléchargez le connecteur Spark depuis le référentiel GitHub azure-sqldb-spark et parcourez les ressources supplémentaires qui s’y trouvent :
Vous pouvez également consulter Apache Spark SQL, DataFrames, and Datasets Guide (Guide sur Apache Spark SQL, les tableaux de données et les jeux de données) et la documentation Azure Databricks.