Stratégies de récupération d’urgence pour les applications utilisant les pools élastiques Azure SQL Database
S’applique à : ![]() Azure SQL Database
Azure SQL Database
Azure SQL Database offre un certain nombre de fonctionnalités pour assurer la continuité des activités de votre application en cas d’incidents catastrophiques. Les pools élastiques et les bases de données uniques prennent en charge le même type de fonctionnalités de reprise d’activité après sinistre. Cet article décrit plusieurs stratégies de récupération d’urgence pour des pools élastiques qui tirent parti de ces fonctionnalités de continuité des activités Azure SQL Database.
Cet article utilise le modèle d’application d’éditeur de logiciels indépendant (ISV) SaaS canonique suivant :
Une application web basée dans le cloud moderne configure une base de données pour chaque utilisateur final. L’éditeur de logiciels indépendant a de nombreux clients et utilise donc de nombreuses bases de données, appelées bases de données client. Comme les bases de données client ont généralement des modèles d’activité non prévisibles, l’ISV utilise un pool élastique afin de pouvoir prévoir à long terme les coûts des bases de données. Le pool élastique simplifie également la gestion des performances lors des pics d’activité de l’utilisateur. Outre les bases de données de locataire, l’application utilise plusieurs bases de données pour gérer les profils utilisateur et la sécurité, collecter les modèles d’utilisation, etc. La disponibilité des locataires individuels n’affecte pas la disponibilité de l’application dans son ensemble. Toutefois, la disponibilité et les performances des bases de données de gestion sont critiques pour le bon fonctionnement de l’application. Ainsi, si les bases de données de gestion sont hors connexion, l’application l’est également.
Cet article aborde les stratégies de récupération d’urgence applicables à des scénarios allant des applications de start-ups soucieuses des coûts aux applications présentant des exigences de disponibilité strictes.
Notes
Si vous utilisez des bases de données et des pools élastiques Premium ou Critique pour l’entreprise, vous pouvez les rendre résistants aux pannes régionales en les transformant en configuration de déploiement redondante dans une zone. Consultez Bases de données redondantes interzone.
Scénario 1 Start-up soucieuse des coûts
Ma jeune entreprise a un budget très serré. Je souhaite simplifier le déploiement et la gestion de l’application et peux avoir un contrat SLA limité pour chacun de mes clients. Mais je veux être sûr que l’application ne sera jamais hors connexion.
Pour répondre au besoin de simplicité, déployez toutes les bases de données client dans un pool élastique de la région Azure de votre choix et déployez les bases de données de gestion en tant que bases de données uniques géorépliquées. Pour la récupération d’urgence des locataires, utilisez la fonctionnalité de géo-restauration qui ne vous coûtera pas un centime. Pour garantir la disponibilité des bases de données de gestion, géorépliquez-les dans une autre région avec un groupe de basculement (étape 1). Dans ce scénario, le coût de la configuration de récupération d’urgence est égal au coût total des bases de données secondaires. Cette configuration est illustrée dans le schéma suivant.
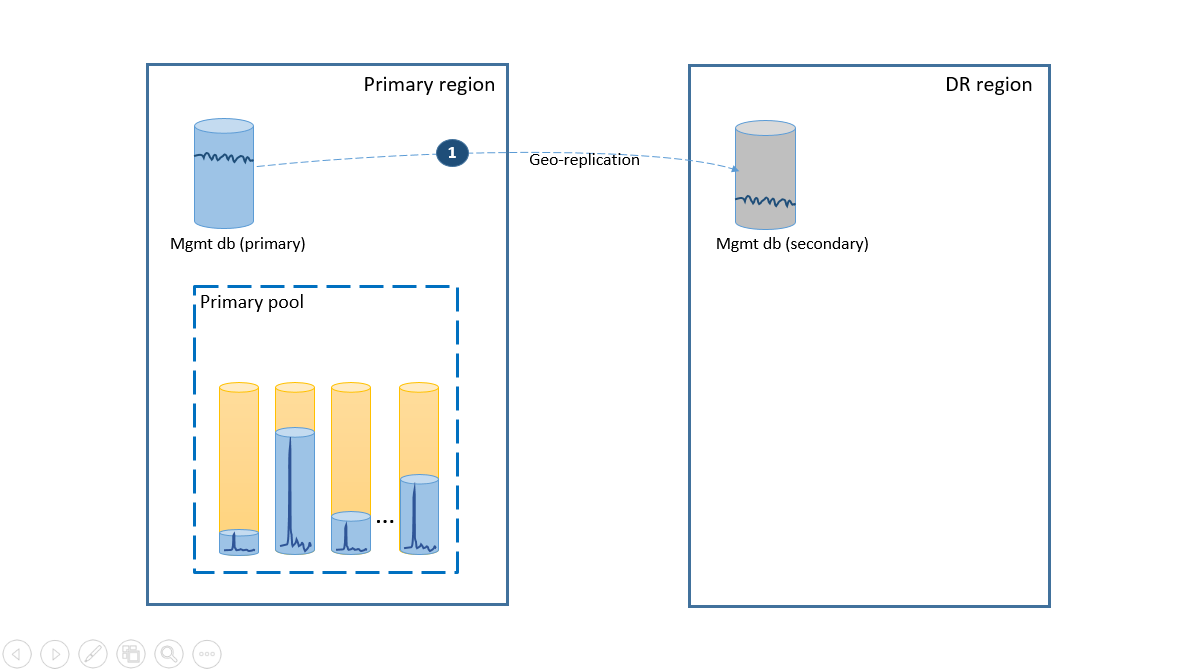
En cas de panne dans la région primaire, les étapes de récupération à suivre pour remettre votre application en ligne sont illustrées dans le schéma suivant.
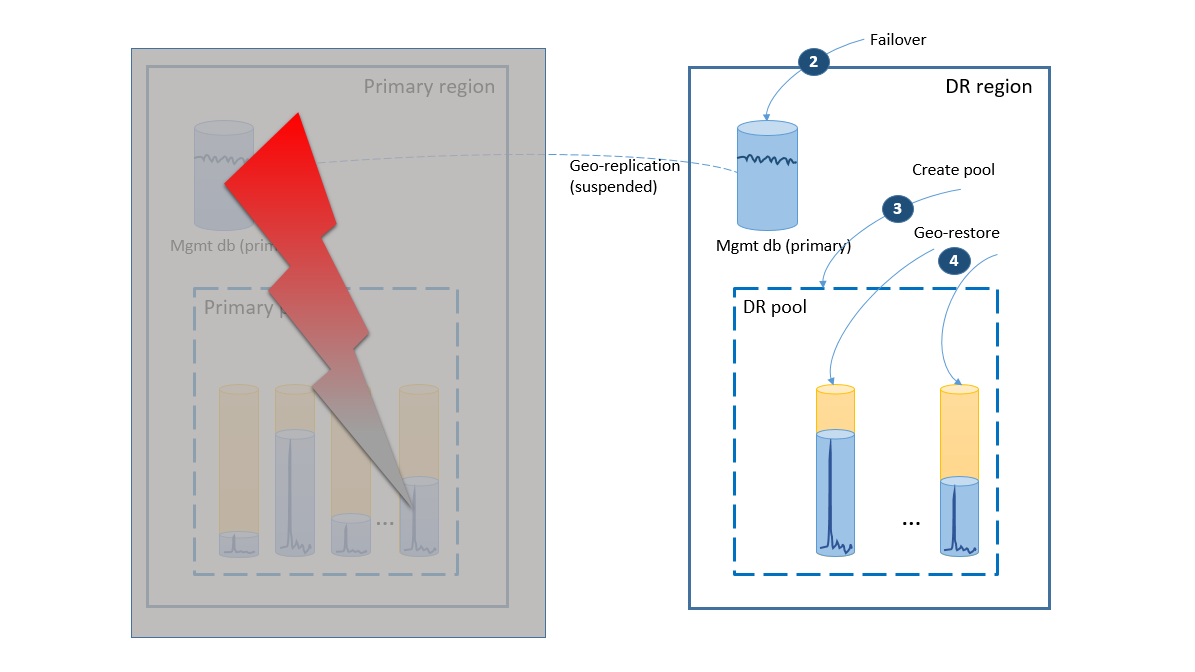
- Le groupe de basculement lance le basculement automatique de la base de données de gestion vers la région de récupération d’urgence. L’application est reconnectée automatiquement aux nouveaux comptes principaux et à tous les nouveaux comptes. De même, les nouvelles bases de données client sont créées dans la région de récupération d’urgence. Les données des clients existants sont temporairement indisponibles.
- Créez le pool élastique en utilisant la même configuration que celle du pool d’origine (2).
- Utilisez la géo-restauration pour créer des copies des bases de données client (3). Vous pouvez envisager de déclencher les restaurations individuelles via les connexions de l’utilisateur final ou d’utiliser d’autres schémas de priorité spécifiques à l’application.
À ce stade, votre application est à nouveau en ligne dans la région de récupération d’urgence, mais certains clients accèdent moins rapidement à leurs données.
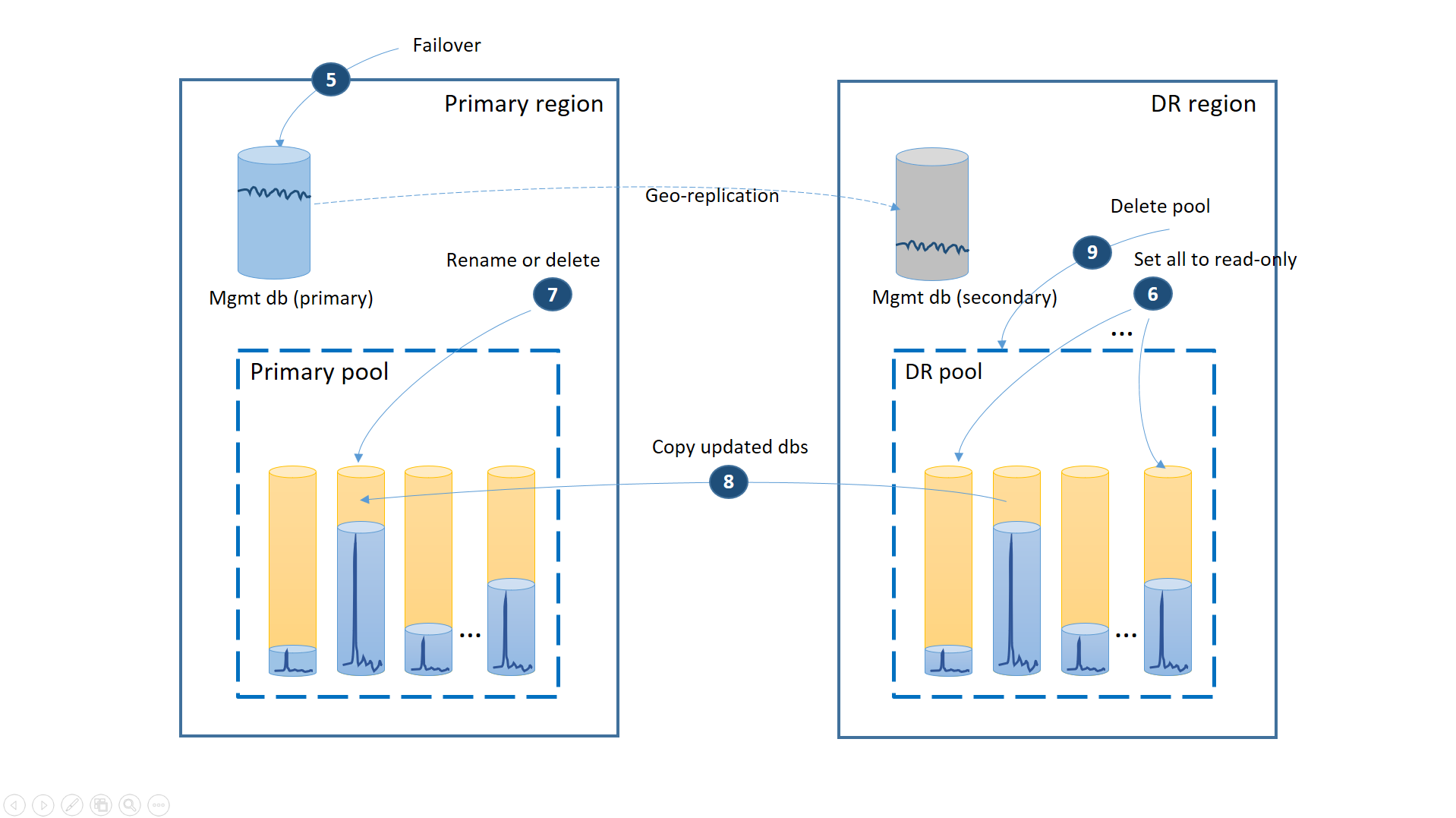
Si la panne est temporaire, il est possible que la région primaire soit restaurée par Azure avant que toutes les restaurations de base de données soient terminées dans la région de récupération d’urgence. Dans ce cas, orchestrez le déplacement de l’application dans la région primaire. Les étapes du processus sont illustrées dans le schéma suivant.
- Annulez toutes les requêtes de géo-restauration en attente.
- Basculez les bases de données de gestion vers la région primaire (5). Après la récupération de la région, les anciennes bases de données primaires sont automatiquement devenues des bases de données secondaires. Les rôles sont à nouveau permutés.
- Changez la chaîne de connexion de l’application pour la rediriger vers la région primaire. Désormais, tous les nouveaux comptes et bases de données client sont créés dans la région primaire. Les données de certains clients existants sont temporairement indisponibles.
- Définissez toutes les bases de données du pool de récupération d’urgence en lecture seule pour vous assurer qu’elles ne pourront pas être modifiées dans la région de récupération d’urgence (6).
- Pour chaque base de données du pool de récupération d’urgence qui a été modifiée depuis la récupération, renommez ou supprimez la base de données correspondante dans le pool principal (7).
- Copiez les bases de données mises à jour du pool de récupération d’urgence vers le pool principal (8).
- Supprimez le pool de récupération d’urgence (9).
À ce stade, votre application est en ligne dans la région primaire avec toutes les bases de données client disponibles dans le pool principal.
Avantage
L’avantage majeur de cette stratégie est le faible coût de redondance des couches de données. Azure SQL Database sauvegarde automatiquement des bases de données sans réécriture des applications et gratuitement. Des frais s’appliquent uniquement lorsque les bases de données sont restaurées.
Compromis
Le compromis consiste à la récupération complète de toutes les bases de données abonné qui prend beaucoup de temps. La durée de l’opération dépend du nombre total de restaurations que vous lancez dans la région de récupération d’urgence et de la taille globale des bases de données client. Même si vous donnez la priorité à la restauration de certains clients, vous composez tout de même avec toutes les autres restaurations lancées dans la même région, car le service limite la bande passante pour minimiser l’impact global sur les bases de données des clients existants. En outre, la récupération des bases de données client ne peut pas démarrer tant que le nouveau pool élastique n’a pas été créé dans la région de récupération d’urgence.
Scénario 2 Application arrivée à maturité avec un service sur plusieurs niveaux
Je propose une application SaaS mature avec plusieurs offres de service et différents contrats SLA pour les clients qui utilisent une version d’évaluation gratuite ou une version payante. Pour les clients utilisant une version d’évaluation, je dois réduire les coûts autant que possible. Les interruptions de service sont acceptables pour les clients utilisant une version d’évaluation, mais je souhaite les éviter au maximum. Pour les clients utilisant une version payante, les interruptions de service ne sont pas acceptables (risque de perte du client). Je veux donc m’assurer que les clients qui utilisent une version payante ont accès à leurs données à tout moment.
Dans ce scénario, séparez les clients utilisant une version d’évaluation des clients utilisant une version payante en les plaçant dans des pools élastiques distincts. Les clients utilisant une version d’évaluation ont un nombre inférieur d’eDTU ou de vCore par client et un contrat SLA moins élevé avec un temps de récupération plus long. Les clients utilisant une version payante se trouvent dans un pool avec un nombre d’eDTU ou de vCore par client plus élevé et un contrat SLA plus élevé. Pour limiter au maximum le temps de récupération, les bases de données client des clients utilisant une version payante sont géorépliquées. Cette configuration est illustrée dans le schéma suivant.
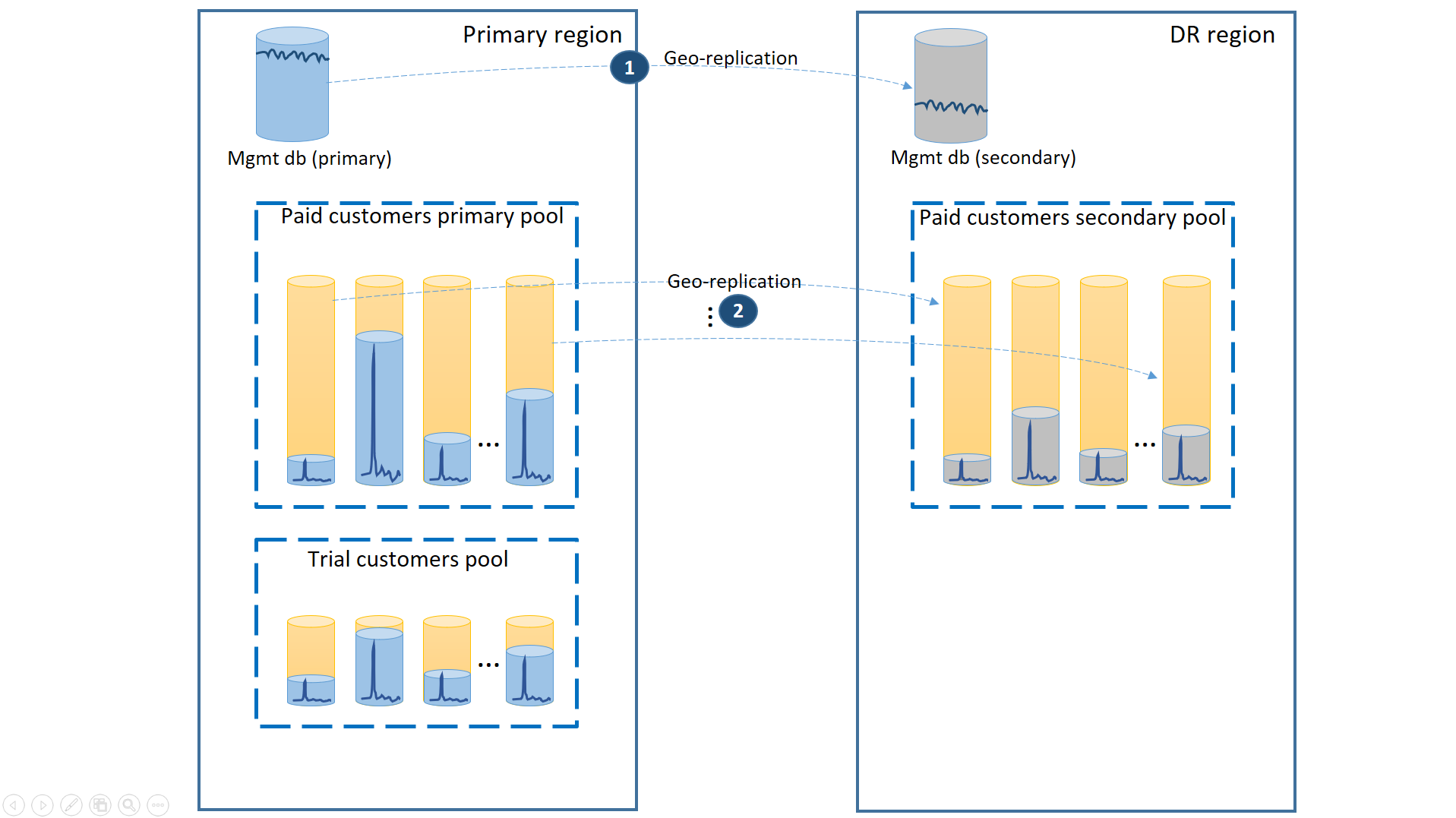
Comme dans le premier scénario, les bases de données de gestion sont assez actives, d’où l’importance d’utiliser une base de données géorépliquée unique (1). Cela garantit la prévisibilité des résultats concernant les nouveaux abonnements de client, les mises à jour de profil et les autres opérations de gestion. La région qui héberge les bases de données de gestion primaires est la région primaire. La région qui héberge les bases de données de gestion secondaires est la région de récupération d’urgence.
Les bases de données client du locataire utilisant une version payante ont des bases de données actives dans le pool payant configuré dans la région primaire. Configurez un pool secondaire portant le même nom dans la région de récupération d’urgence. Chaque base de données client est géorépliquée dans le pool secondaire (2). Cela permet une récupération rapide de toutes les bases de données client à l’aide de la fonctionnalité de basculement.
En cas de panne dans la région primaire, les étapes de récupération à suivre pour remettre votre application en ligne sont illustrées dans le schéma suivant :
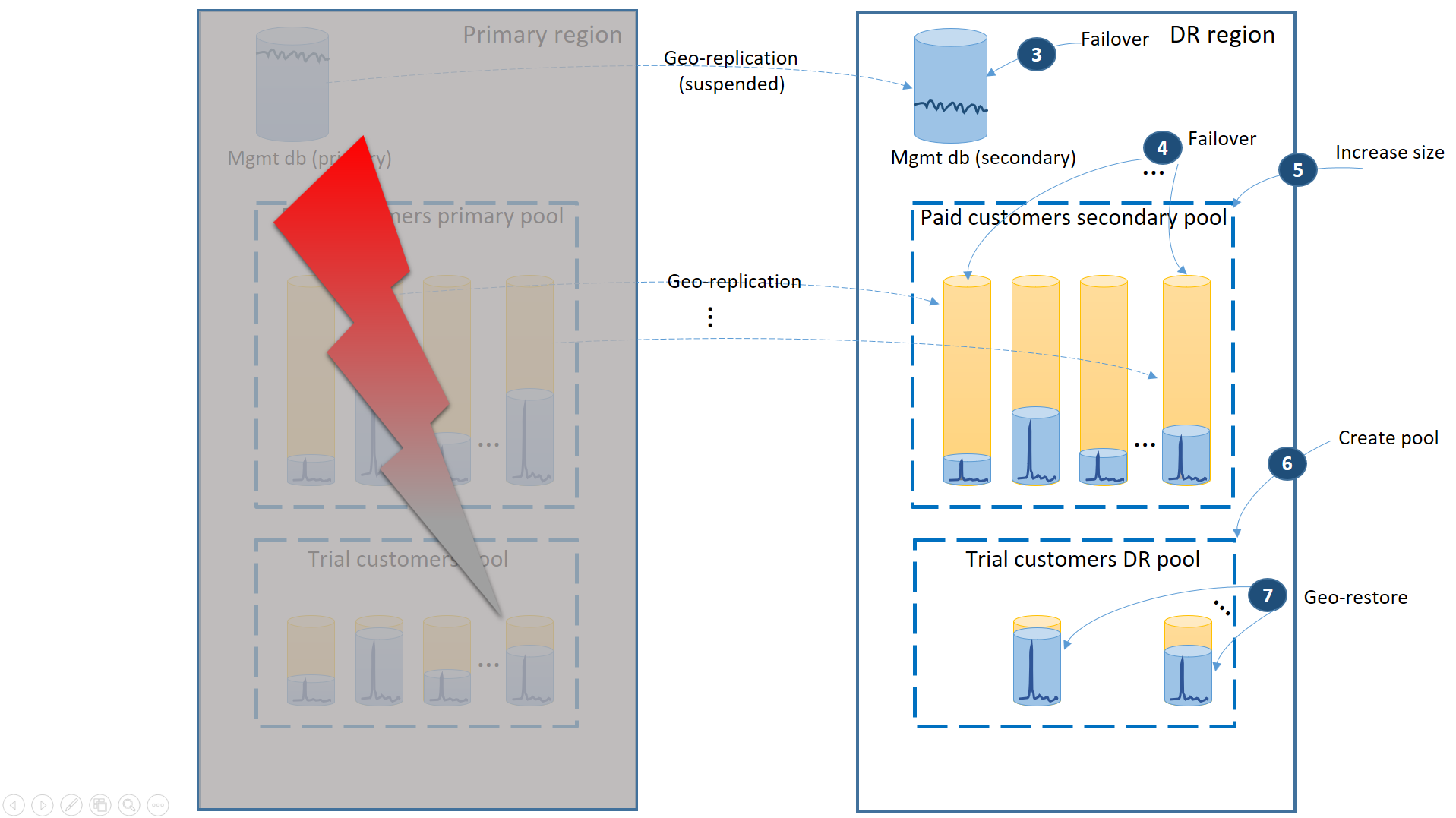
- Basculez immédiatement les bases de données de gestion vers la région de récupération d’urgence (3).
- Modifiez la chaîne de connexion de l’application pour qu’elle pointe vers la région de récupération d’urgence. Tous les nouveaux comptes et bases de données client sont désormais créés dans la région de récupération d’urgence. Les données des clients existants utilisant une version d’évaluation sont temporairement indisponibles.
- Basculez les bases de données client des clients utilisant une version payante vers le pool de la région de récupération d’urgence afin de restaurer immédiatement leur disponibilité (4). Le basculement étant un processus de modification rapide au niveau des métadonnées, envisagez de l’optimiser en permettant le déclenchement à la demande des basculements individuels via les connexions de l’utilisateur final.
- Si le nombre d’eDTU de votre pool secondaire ou la valeur de vCore était inférieur à celui de votre pool principal car les bases de données secondaires n’avaient besoin que d’une capacité limitée pour traiter les journaux d’activité des modifications en tant que bases de données secondaires, augmentez immédiatement la capacité du pool pour prendre en charge la charge de travail globale de tous les clients (5).
- Créez le nouveau pool élastique avec le même nom et la même configuration dans la région de récupération d’urgence pour les bases de données des clients utilisant une version d’évaluation (6).
- Une fois le pool créé pour les clients utilisant une version d’évaluation, utilisez la géo-restauration pour restaurer chaque base de données de locataire en version d’évaluation dans le nouveau pool (7). Envisagez de déclencher les restaurations individuelles via les connexions de l’utilisateur final ou d’utiliser d’autres schémas de priorité spécifiques à l’application.
À ce stade, votre application est à nouveau en ligne dans la région de récupération d’urgence. Tous les clients utilisant une version payante ont accès à leurs données à tout moment, tandis que les clients utilisant une version d’évaluation accèdent moins rapidement à leurs données.
Lorsque la région primaire est restaurée par Azure après que vous ayez restauré l’application dans la région de récupération d’urgence, vous pouvez continuer à exécuter l’application dans cette région ou restaurer l’application dans la région primaire. Si la région primaire est restaurée avant la fin du processus de basculement, envisagez de restaurer immédiatement l’application. Les étapes du processus de restauration sont illustrées dans le schéma suivant :
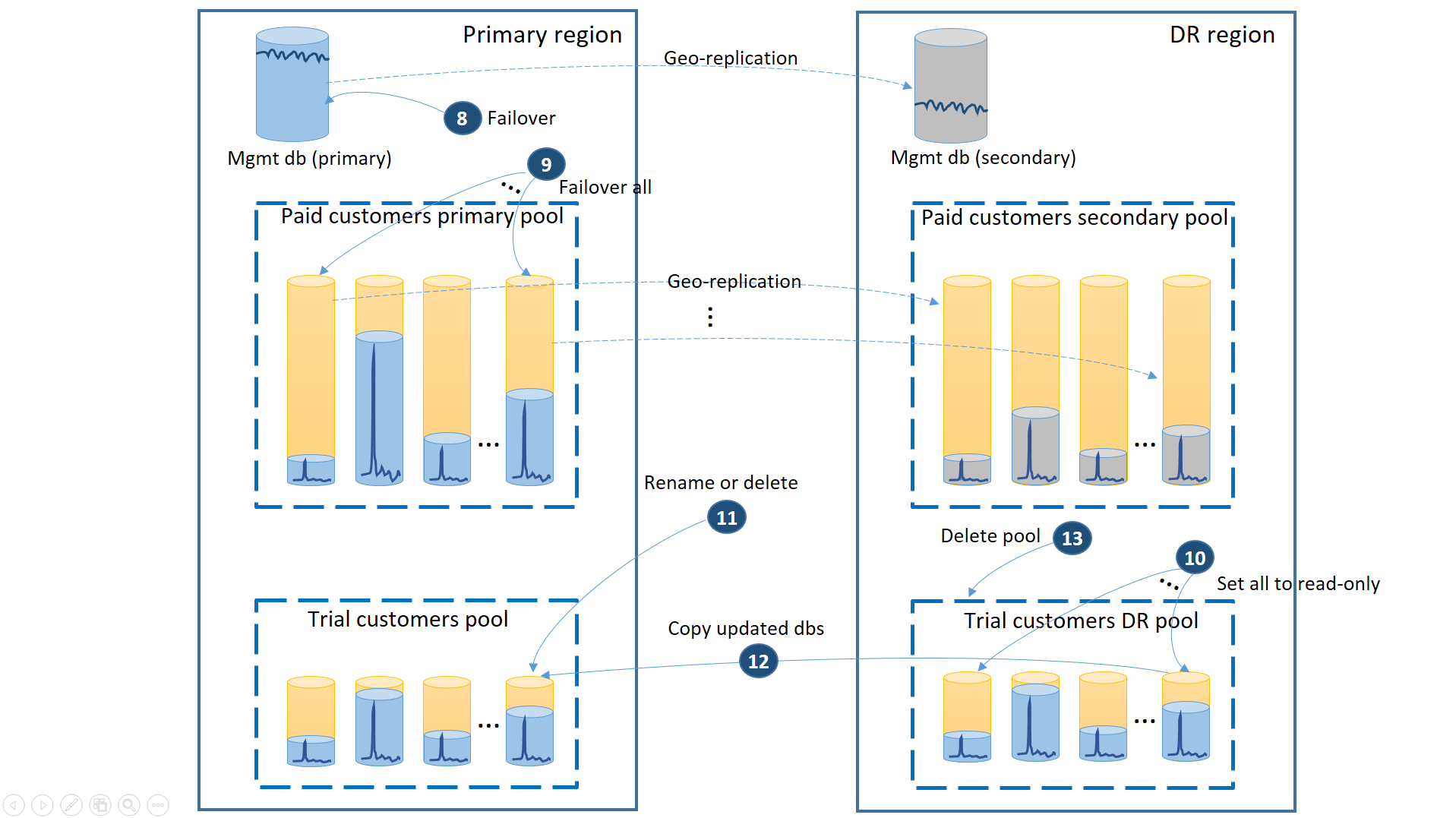
- Annulez toutes les requêtes de géo-restauration en attente.
- Basculez les bases de données de gestion (8). Après la récupération de la région, l’ancienne base de données primaire est automatiquement devenue une base de données secondaire. Celles-ci redeviennent désormais les bases de données primaires.
- Basculez les bases de données client des clients utilisant une version payante (9). De la même manière, après la récupération de la région, les anciennes bases de données primaires sont automatiquement devenues des bases de données secondaires. Celles-ci redeviennent désormais les bases de données primaires.
- Définissez les bases de données d’évaluation restaurées qui ont été modifiées dans la région de récupération d’urgence en lecture seule (10).
- Pour chaque base de données du pool de récupération d’urgence des clients utilisant une version d’évaluation qui a été modifiée depuis la restauration, renommez ou supprimez la base de données correspondante dans le pool principal de ces clients (11).
- Copiez les bases de données mises à jour du pool de récupération d’urgence vers le pool principal (12).
- Supprimez le pool de récupération d’urgence (13).
Notes
L’opération de basculement est asynchrone. Pour réduire le temps de récupération, il est important que vous exécutiez la commande de basculement des bases de données client pour des lots d’au moins 20 bases de données.
Avantage
L’avantage majeur de cette stratégie est qu’elle fournit le contrat de niveau de service le plus élevé pour les clients utilisant une version payante. Elle garantit également le déblocage des nouvelles bases de données en version d’évaluation dès que le pool de récupération d’urgence des bases de données en version d’évaluation est créé.
Compromis
Le compromis consiste à l’augmentation du coût total des bases de données abonné par la configuration en ajoutant le coût du pool de récupération d’urgence secondaire pour les clients utilisant une version payante. De plus, si le pool secondaire est de taille différente, les clients qui utilisent une version payante constatent une baisse des performances après le basculement, jusqu’à la fin du processus de mise à niveau du pool dans la région de récupération d’urgence.
Scénario 3 Application dispersée géographiquement avec un service sur plusieurs niveaux
Je propose une application SaaS mature avec des offres de service sur plusieurs niveaux. Je souhaite offrir un contrat SLA très agressif à mes clients qui utilisent la version payante et réduire l’impact d’une éventuelle panne car je sais que même une brève interruption de service peut rendre mes clients mécontents. Il est essentiel que les clients utilisant la version payante puissent accéder à leurs données à tout moment. Les versions d’évaluation sont gratuites et n’incluent aucun contrat SLA.
Dans ce scénario, vous devez configurer trois pools élastiques distincts. Configurez deux pools de taille égale avec un nombre élevé d’eDTU ou de vCore par base de données dans deux régions différentes pour accueillir les bases de données client des clients utilisant la version payante. Le troisième pool, qui accueille les bases de données client des clients utilisant la version d’évaluation, peut avoir un nombre moins élevé d’eDTU ou de vCore par base de données et être configuré dans l’une des deux régions.
Pour limiter au maximum le temps de récupération en cas de panne, les bases de données client des clients utilisant la version payante sont géorépliquées avec 50 % des bases de données primaires dans chacune des deux régions. De même, chaque région a 50 % des bases de données secondaires. Ainsi, si une région est hors connexion, seule la moitié des bases de données des clients utilisant la version payante est affectée et devra être basculée. Les autres bases de données ne sont pas affectées. Cette configuration est illustrée dans le schéma suivant :
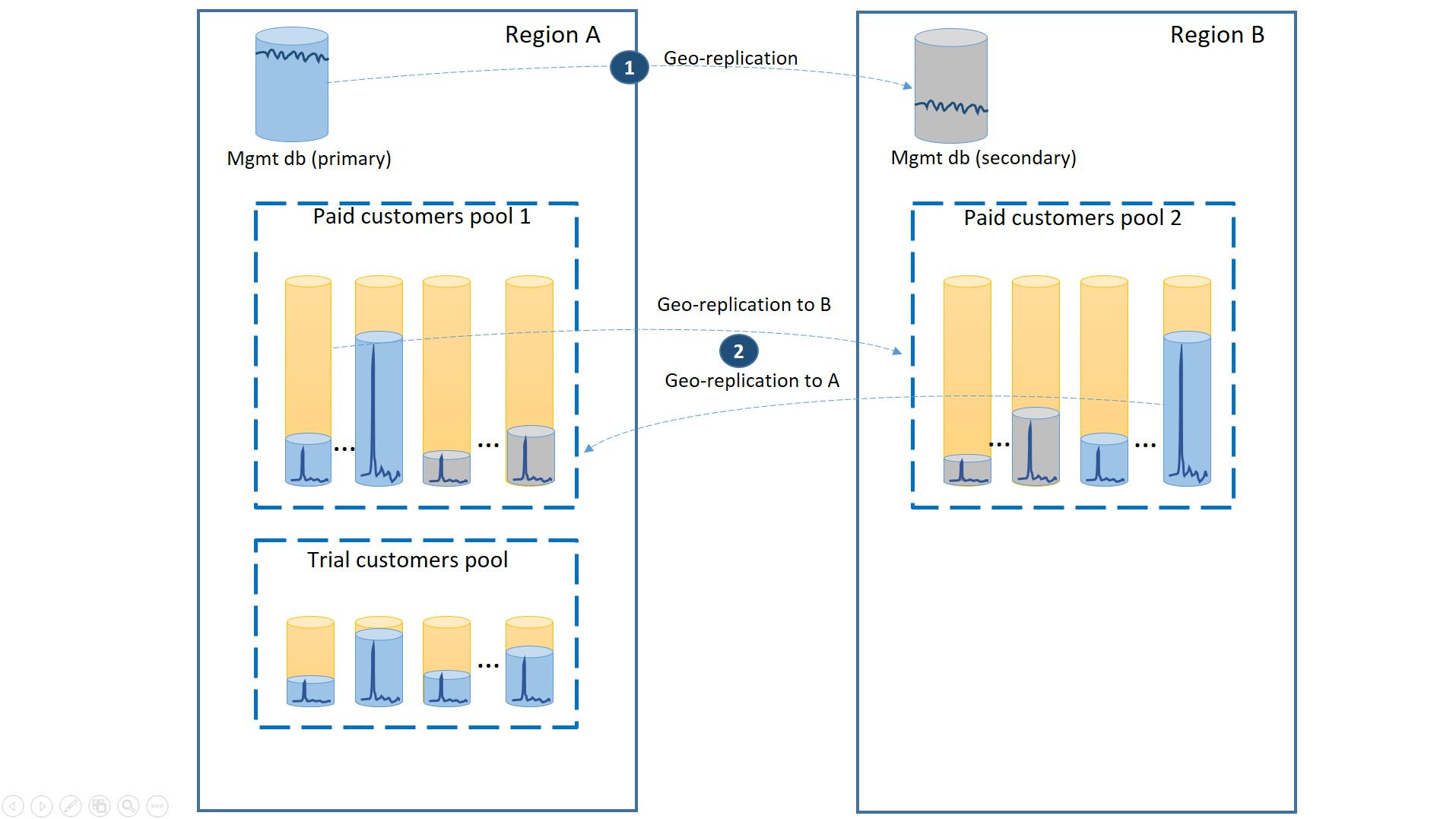
Comme dans les scénarios précédents, les bases de données de gestion sont assez actives. Il est donc essentiel de les configurer en tant que bases de données uniques géorépliquées (1). Cela garantit la prévisibilité des résultats concernant les nouveaux abonnements de client, les mises à jour de profil et les autres opérations de gestion. La région A est la région primaire pour les bases de données de gestion et la région B est utilisée pour la récupération des bases de données de gestion.
Les bases de données locataire des clients utilisant la version payante sont également géorépliquées, mais les bases de données primaires et secondaires sont réparties dans les régions A et B (2). Ainsi, les bases de données client primaires affectées par la panne peuvent basculer vers l’autre région et être à nouveau accessibles. L’autre moitié des bases de données client n’est pas du tout affectée.
Le schéma suivant illustre les étapes de récupération à suivre en cas de panne dans la région A.
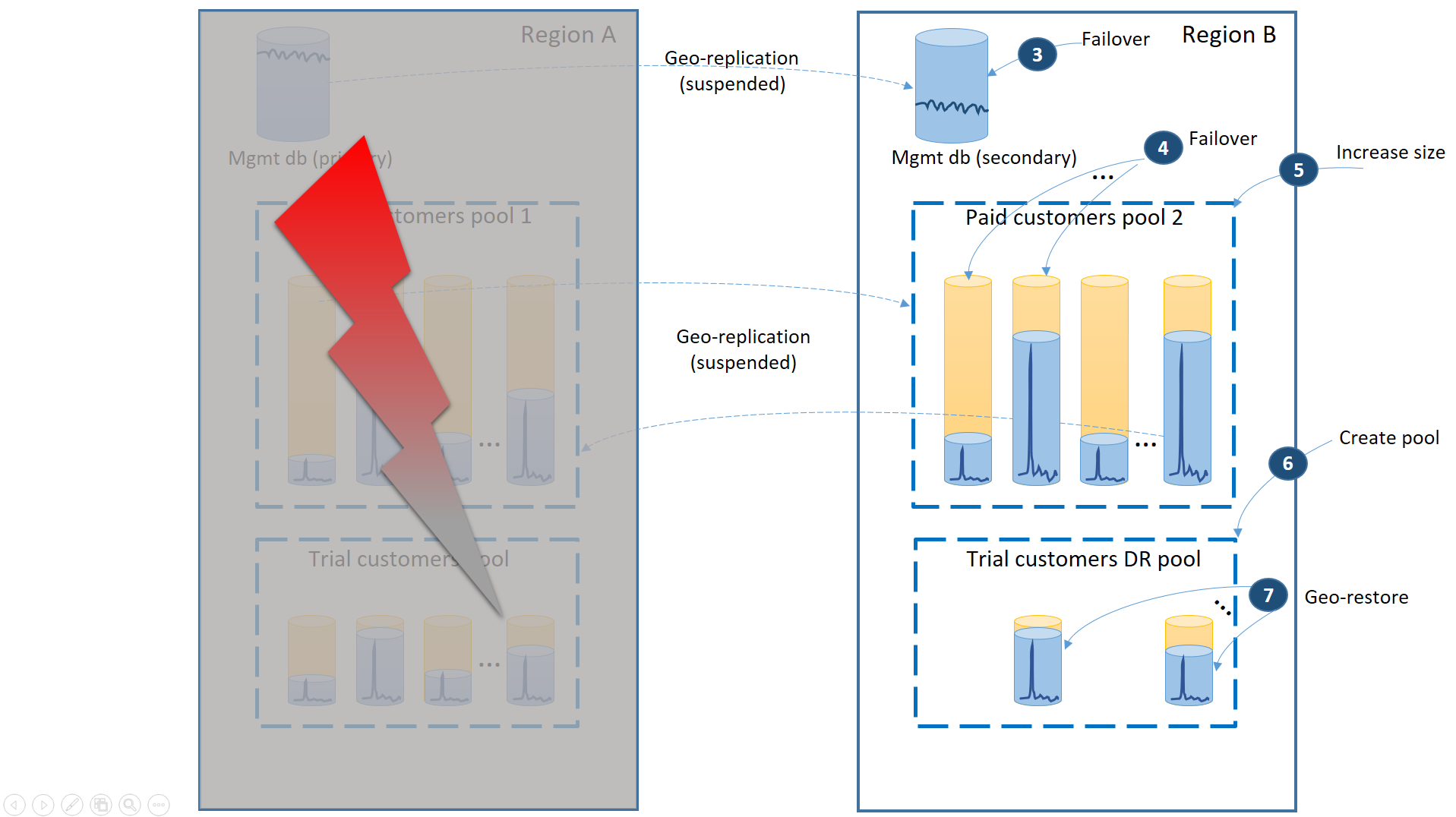
- Basculez immédiatement les bases de données de gestion vers la région B (3).
- Modifiez la chaîne de connexion de l’application pour qu’elle pointe vers les bases de données de gestion dans la région B. Modifiez les bases de données de gestion pour vous assurer que les nouveaux comptes et bases de données de locataire sont créés dans la région B et que les bases de données de locataire existantes s’y trouvent également. Les données des clients existants utilisant une version d’évaluation sont temporairement indisponibles.
- Basculez les bases de données client des clients utilisant une version payante vers le pool 2 de la région B afin de restaurer immédiatement leur disponibilité (4). Le basculement étant un processus de modification rapide au niveau des métadonnées, vous pouvez envisager de l’optimiser en permettant le déclenchement à la demande des basculements individuels via les connexions de l’utilisateur final.
- Comme le pool 2 ne contient désormais que les bases de données primaires, la charge de travail totale du pool augmente. Vous pouvez donc immédiatement augmenter son nombre d’eDTU (5) ou de vCore.
- Créez le nouveau pool élastique avec le même nom et la même configuration dans la région B pour les bases de données des clients utilisant une version d’évaluation (6).
- Une fois le pool créé, utilisez la géo-restauration pour restaurer chaque base de données client en version d’évaluation dans le pool (7). Vous pouvez envisager de déclencher les restaurations individuelles via les connexions de l’utilisateur final ou d’utiliser d’autres schémas de priorité spécifiques à l’application.
Remarque
L’opération de basculement est asynchrone. Pour réduire le temps de récupération, il est important que vous exécutiez la commande de basculement des bases de données client pour des lots d’au moins 20 bases de données.
À ce stade, votre application est à nouveau en ligne dans la région B. Tous les clients utilisant une version payante ont accès à leurs données à tout moment, tandis que les clients utilisant une version d’évaluation accèdent moins rapidement à leurs données.
Après la récupération de la région A, vous devez décider si vous souhaitez utiliser la région B pour les clients utilisant la version d’évaluation ou restaurer les bases de données dans le pool des clients d’évaluation de la région A. Pour prendre votre décision, vous pouvez par exemple tenir compte du pourcentage de bases de données client en version d’évaluation qui ont été modifiées depuis la récupération. Quelle que soit cette décision, vous devez répartir à nouveau les clients payants entre les deux pools. Le diagramme suivant illustre le processus lorsque les bases de données concernant les clients non payants rebasculent vers la région A.
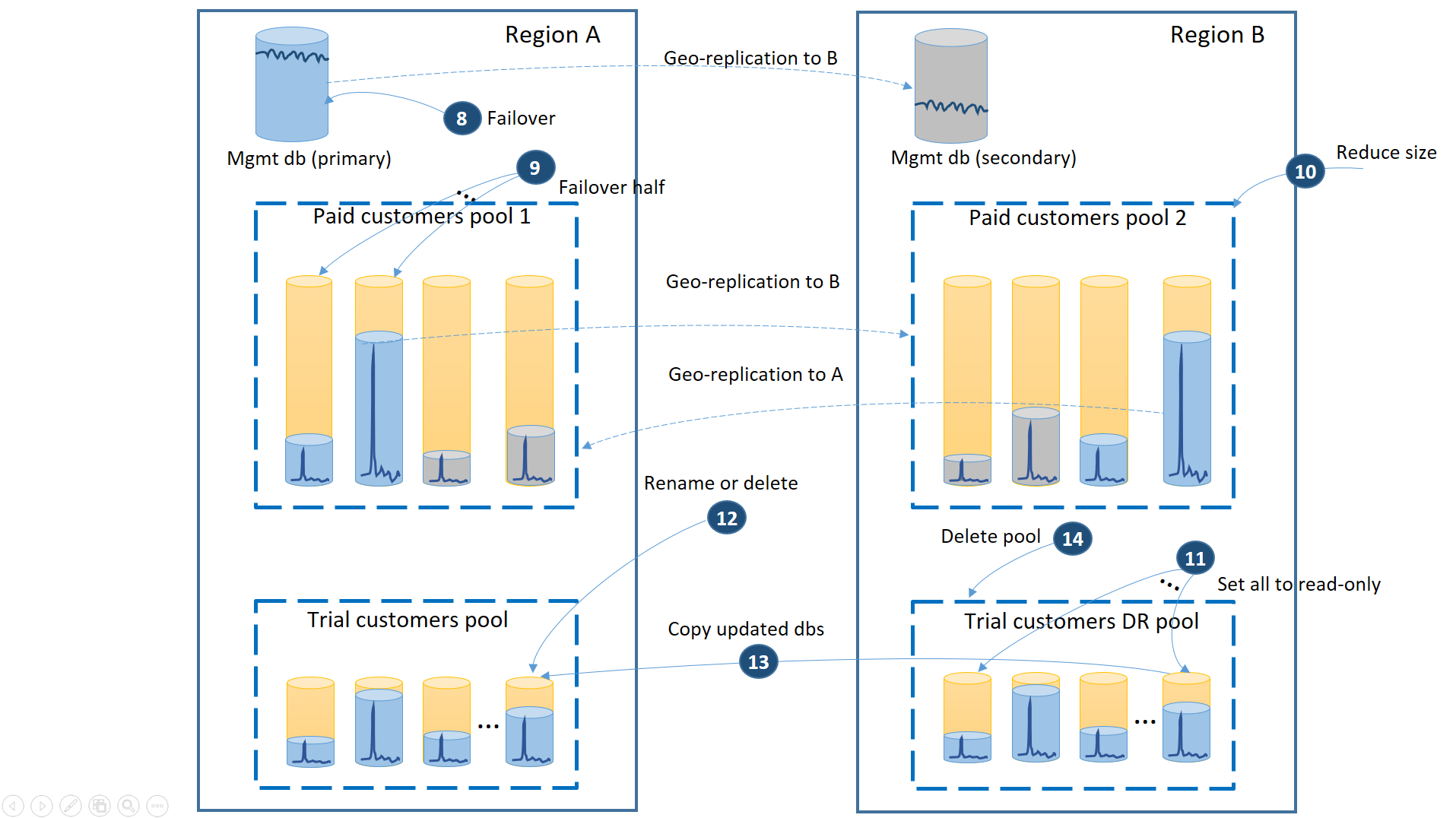
- Annulez toutes les requêtes de géo-restauration en attente pour le pool de récupération d’urgence des bases de données en version d’évaluation.
- Basculez la base de données de gestion (8). Après la récupération de la région, l’ancienne base de données primaire est automatiquement devenue une base de données secondaire. Celles-ci redeviennent désormais les bases de données primaires.
- Choisissez les bases de données client des clients utilisant la version payante qui seront restaurées dans le pool 1 et initiez le basculement vers les bases de données secondaires (9). Après la récupération de la région, toutes les bases de données du pool 1 sont automatiquement devenues des bases de données secondaires. Désormais, 50 % d’entre elles redeviennent des bases de données primaires.
- Réduisez la taille du pool 2 en rétablissant le nombre d’eDTU d’origine (10) ou le nombre de vCore.
- Définissez toutes les bases de données d’évaluation restaurées de la région B en lecture seule (11).
- Pour chaque base de données du pool de récupération d’urgence des versions d’évaluation qui a été modifiée depuis la récupération, renommez ou supprimez la base de données correspondante dans le pool principal des versions d’évaluation (12).
- Copiez les bases de données mises à jour du pool de récupération d’urgence vers le pool principal (13).
- Supprimez le pool de récupération d’urgence (14).
Avantage
Cette stratégie a plusieurs avantages :
- Elle offre le contrat SLA le plus agressif pour les clients utilisant la version payante de l’application, car elle protège au moins 50 % des bases de données client en cas de panne.
- Elle garantit le déblocage des nouvelles bases de données en version d’évaluation dès que le pool de récupération d’urgence des bases de données en version d’évaluation est créé lors de la récupération.
- Elle permet une utilisation plus efficace de la capacité du pool, car 50 % des bases de données secondaires des pools 1 et 2 sont systématiquement moins actives que les bases de données primaires.
Compromis
Les principaux compromis sont les suivants :
- Les opérations CRUD exécutées sur les bases de données de gestion ont une latence plus faible pour les utilisateurs finaux connectés à la région A que pour ceux connectés à la région B, car elles sont exécutées au niveau des bases de données de gestion primaires.
- Cette stratégie requiert une conception plus complexe des bases de données de gestion. Par exemple, chaque enregistrement client a une balise d’emplacement qui doit être modifiée pendant le basculement et la restauration.
- Les clients qui utilisent la version payante de l’application peuvent constater une baisse des performances jusqu’à la fin du processus de mise à niveau du pool dans la région B.
Résumé
Cet article aborde les différentes stratégies de récupération d’urgence pour la couche de base de données utilisée par une application SaaS de fournisseur de logiciel indépendant (ISV) à architecture mutualisée. La stratégie choisie repose sur les besoins de l’application, tels que le modèle commercial, le contrat SLA que vous souhaitez offrir à vos clients, les contraintes budgétaires, etc. Nous vous détaillons les avantages et les inconvénients de chaque stratégie afin de vous aider à prendre une décision éclairée. De plus, votre propre application inclut probablement d’autres composants Azure. Vérifiez donc les recommandations associées en termes de continuité des activités et orchestrez la récupération de la couche de base de données avec ces composants. Pour en savoir plus sur la gestion de la récupération des applications de base de données dans Azure, consultez Conception de services hautement disponibles à l’aide d’Azure SQL Database.
Étapes suivantes
- Pour en savoir plus sur les sauvegardes automatisées Azure SQL Database, consultez Sauvegardes automatisées Azure SQL Database.
- Pour une vue d’ensemble de la continuité des activités et des scénarios, consultez Vue d’ensemble de la continuité des activités.
- Pour en savoir plus sur l’utilisation des sauvegardes automatisées pour la récupération, consultez Restaurer une base de données à partir des sauvegardes initiées par le service.
- Pour plus d’informations sur les options de récupération plus rapides, consultez Géoréplication active et groupes de basculement.
- Pour en savoir plus sur l’utilisation des sauvegardes automatisées pour l’archivage, consultez Copie de base de données.