Performances de base de données Oracle sur Azure NetApp Files plusieurs volumes
La migration de bases de données Exadata hautement performantes vers le cloud devient de plus en plus impératif pour les clients Microsoft. Les suites de logiciel de chaîne logistique mettent la barre haut en raison des demandes intenses d’E/S de stockage avec une charge de travail mixte de lecture et d’écriture pilotée par un seul nœud de calcul. L’infrastructure Azure combinée à Azure NetApp Files est en mesure de répondre aux besoins de cette charge de travail hautement exigeante. Cet article présente un exemple de la façon dont cette demande a été satisfaite pour un client et comment Azure peut répondre aux demandes de vos charges de travail Oracle critiques.
Performances Oracle à l’échelle de l’entreprise
Lorsque vous explorez les limites supérieures des performances, il est important de remarquer et de réduire toutes les contraintes qui pourraient faussement biaiser les résultats. Par exemple, si l’intention est de prouver les fonctionnalités de performances d’un système de stockage, le client doit idéalement être configuré afin que le processeur ne devienne pas un facteur d’atténuation avant que les limites de performances de stockage ne soient atteintes. À cette fin, les tests ont commencé avec le type d’instance E104ids_v5, car cette machine virtuelle est équipée non seulement d’une interface réseau de 100 Gbits/s, mais avec une limite de sortie aussi importante (100 Gbits/s).
Le test s’est produit en deux phases :
- La première phase s’est concentrée sur le test à l’aide de l’outil SLOB2 (Silly Little Oracle Benchmark) standard de Kevin Closson - version 2.5.4. L’objectif étant de piloter autant d’E/S Oracle que possible d’une machine virtuelle vers plusieurs volumes Azure NetApp Files, puis de monter en charge à l’aide d’autres bases de données pour illustrer la mise à l’échelle linéaire.
- Après avoir testé les limites de mise à l’échelle, nos tests ont pivoté vers les E96ds_v5 moins coûteux, mais presque aussi capables pour une phase de test client à l’aide d’une véritable charge de travail d’application Chaîne logistique et de données réelles.
Performances de montée en puissance SLOB2
Les graphiques suivants capturent le profil de performances d’une machine virtuelle Azure E104ids_v5 unique exécutant une base de données Oracle 19c unique sur huit volumes Azure NetApp Files avec huit points de terminaison de stockage. Les volumes sont répartis entre trois groupes de disques ASM : données, journaux et archive. Cinq volumes ont été alloués au groupe de disques de données, deux volumes au groupe de disques de journal et un volume au groupe de disques d’archivage. Tous les résultats capturés dans cet article ont été collectés à l’aide de régions Azure de production et de services Azure de production actifs.
Pour déployer Oracle sur des machines virtuelles Azure à l’aide de plusieurs volumes Azure NetApp Files sur plusieurs points de terminaison de stockage, utilisez groupe de volumes d’applications pour Oracle.
Architecture d'hôte unique
Le diagramme suivant illustre l’architecture sur laquelle les tests ont été effectués ; notez que la base de données Oracle est répartie sur plusieurs volumes et points de terminaison Azure NetApp Files.

E/S de stockage d’hôte unique
Le diagramme suivant montre une charge de travail sélectionnée aléatoirement à 100 % avec un taux d’accès à la mémoire tampon de base de données d’environ 8 %. SLOB2 a pu piloter environ 850 000 requêtes d’E/S par seconde tout en conservant une latence d’événement de lecture séquentielle de fichier de base de données à la sous-milliseconde. Avec une taille de bloc de base de données de 8 Ko qui représente environ 6 800 Mio/s de débit de stockage.

Débit d’un hôte unique
Le diagramme suivant montre que, pour les charges de travail d’E/S séquentielles gourmandes en bande passante, telles que les analyses de tables complètes ou les activités RMAN, Azure NetApp Files peut fournir les fonctionnalités de bande passante complètes de la machine virtuelle E104ids_v5 elle-même.

Remarque
Comme l’instance de calcul est au maximum théorique de sa bande passante, l’ajout d’une concurrence d’application supplémentaire entraîne uniquement une latence côté client accrue. Ainsi, les charges de travail SLOB2 dépassent la période d’achèvement ciblée, ce qui limite le nombre de threads à six.
Performances de montée en charge SLOB2
Les graphiques suivants capturent le profil de performances de trois machines virtuelles Azure E104ids_v5 chacune exécutant une base de données Oracle 19c unique et chacune avec son propre ensemble de volumes Azure NetApp Files et une disposition de groupe de disques ASM identique, comme décrit dans la section Montée en puissance des performances. Les graphiques montrent qu’avec Azure NetApp Files multi-volume/multi-point de terminaison, les performances sont facilement mises à l’échelle avec cohérence et prévisibilité.
Architecture d'hôte multiple
Le diagramme suivant illustre l’architecture sur laquelle les tests ont été effectués ; notez que les trois bases de données Oracle sont réparties sur plusieurs volumes et points de terminaison Azure NetApp Files. Les points de terminaison peuvent être dédiés à un seul hôte, comme indiqué avec Oracle VM 1 ou partagés entre des hôtes, comme indiqué avec Oracle VM2 et Oracle VM 3.

E/S de stockage d’hôte multiple
Le diagramme suivant montre une charge de travail sélectionnée aléatoirement à 100 % avec un taux d’accès à la mémoire tampon de base de données d’environ 8 %. SLOB2 a pu piloter environ 850 000 demandes d’E/S par seconde sur les trois hôtes individuellement. SLOB2 a pu effectuer cette opération tout en s’exécutant en parallèle à un total collectif d’environ 2 500 000 requêtes d’E/S par seconde, chaque hôte conservant toujours une latence d’événement de lecture séquentielle du fichier de base de données à la sous-milliseconde. Avec une taille de bloc de base de données de 8 Ko, cela représente environ 20 000 Mio/s entre les trois hôtes.

Débit d’un hôte multiple
Le diagramme suivant montre que, pour les charges de travail séquentielles, Azure NetApp Files peut toujours fournir les fonctionnalités de bande passante complètes de la machine virtuelle E104ids_v5 elle-même, alors même qu’elle monte en charge. SLOB2 a pu générer des E/S totalisant plus de 30 000 Mio/s sur les trois hôtes tout en s’exécutant en parallèle.

Performances réelles
Une fois les limites de mise à l’échelle testées avec SLOB2, les tests ont été effectués avec une suite d’applications de chaîne logistique réelle par rapport à Oracle sur Azure NetApp files avec d’excellents résultats. Les données suivantes du rapport de référentiel de charge de travail automatique (AWR) Oracle sont un aperçu de la façon dont un travail critique spécifique a été effectué.
Cette base de données a des E/S supplémentaires importantes en plus de la charge de travail de l’application en raison de l’activation du flashback et d’une taille de bloc de base de données de 16 000. Dans la section profil d’E/S du rapport AWR, il est évident qu’il existe un ratio important d’écritures par rapport aux lectures.
| - | Lecture et écriture par seconde | Lecture par seconde | Écriture par seconde |
|---|---|---|---|
| Total (Mo) | 4 988,1 | 1 395,2 | 3 592,9 |
Malgré l’événement d’attente de lecture séquentielle du fichier de base de données affichant une latence plus élevée à 2,2 ms que dans le test SLOB2, ce client a constaté une réduction de quinze minutes du temps d’exécution du travail provenant d’une base de données RAC sur Exadata vers une base de données d’instance unique dans Azure.
Contraintes de ressources Azure
Tous les systèmes finissent par atteindre des contraintes de ressources, traditionnellement appelées points d’étranglement. Les charges de travail de base de données, particulièrement exigeantes, telles que les suites d’applications de chaîne logistique, sont des entités gourmandes en ressources. La recherche de ces contraintes de ressources et leur utilisation est essentielle pour tout déploiement réussi. Cette section éclaire différentes contraintes que vous pouvez vous attendre à rencontrer dans un tel environnement et comment les surmonter. Dans chaque sous-section, vous apprendrez les meilleures pratiques et leur justification.
Machines virtuelles
Cette section détaille les critères à prendre en compte lors de la sélection de machines virtuelles pour des performances optimales et la justification des sélections effectuées pour les tests. Azure NetApp Files est un service NAS (Network Attached Storage), par conséquent, le dimensionnement de bande passante réseau approprié est essentiel pour obtenir des performances optimales.
Circuits microprogammés
Le premier sujet d’intérêt est la sélection de circuits microprogammés. Assurez-vous que la référence SKU de machine virtuelle que vous sélectionnez est basée sur un seul circuit microprogammé pour des raisons de cohérence. La variante Intel de machines virtuelles E_v5 s’exécute sur une troisième configuration Intel Xeon Platinum 8370C (Ice Lake). Toutes les machines virtuelles de cette famille sont équipées d’une seule interface réseau de 100 Gbits/s. En revanche, la série E_v3, mentionnée comme exemple, repose sur quatre circuits microprogrammés distincts, avec différentes bande passantes réseau physiques. Les quatre circuits microprogrammés utilisés dans la famille E_v3 (Broadwell, Skylake, Cascade Lake, Haswell) ont des vitesses de processeur différentes, ce qui affecte les caractéristiques de performances de la machine.
Lisez la documentation Azure Compute attentivement en prêtant attention aux options de circuit microprogrammé. Reportez-vous également aux Meilleures pratiques de références SKU de machine virtuelle Azure pour Azure NetApp Files. La sélection d’une machine virtuelle avec un seul circuit microprogrammé est préférable pour une meilleure cohérence.
Bande passante réseau disponible
Il est important de comprendre la différence entre la bande passante disponible de l’interface réseau de la machine virtuelle et la bande passante mesurée appliquée à la même bande passante. Lorsque la Documentation Azure Compute évoque les limites de bande passante réseau, ces limites sont appliquées uniquement à la sortie (écriture). Le trafic d’entrée (lecture) n’est pas mesuré et, par conséquent, est limité uniquement par la bande passante physique de la carte d’interface réseau (NIC) elle-même. La bande passante réseau de la plupart des machines virtuelles dépasse la limite de sortie appliquée à l’ordinateur.
Comme les volumes Azure NetApp Files sont attachés au réseau, la limite de sortie peut être comprise comme étant appliquée aux écritures spécifiquement tandis que l’entrée est définie comme des lectures et des charges de travail de type lecture. Bien que la limite de sortie de la plupart des machines soit supérieure à la bande passante réseau de la carte réseau, ce n’est pas la même chose pour les E104_v5 utilisées lors du test pour cet article. L’E104_v5 a également une carte réseau de 100 Gbits/s avec la limite de sortie définie à 100 Gbits/s. Par comparaison, l’E96_v5, avec sa carte réseau de 100 Gbits/s a une limite de sortie de 35 Gbits/s avec entrée non limitée à 100 Gbits/s. À mesure que les machines virtuelles diminuent de taille, les limites de sortie diminuent, mais elles restent libres des limites imposées logiquement.
Les limites de sortie sont à l’échelle de la machine virtuelle et à ce titre, elles sont appliquées à toutes les charges de travail basées sur le réseau. Lors de l’utilisation d’Oracle Data Guard, toutes les écritures sont doublées pour archiver les journaux et doivent être prises en compte pour limiter la sortie. Cela est également vrai pour le journal d’archivage avec multi-destination et RMAN, s’il est utilisé. Lors de la sélection de machines virtuelles, familiarisez-vous avec ces outils en ligne de commande comme ethtool, qui exposent la configuration de la carte réseau, car Azure ne documente pas les configurations d’interface réseau.
Accès concurrentiel au réseau
Les machines virtuelles Azure et les volumes Azure NetApp Files sont équipés de quantités spécifiques de bande passante. Comme indiqué précédemment, tant qu’une machine virtuelle dispose d’un espace principal de processeur suffisant, une charge de travail peut en théorie consommer la bande passante mise à la disposition de celle-ci, qui se trouve dans les limites de la carte réseau et ou de la limite de sortie appliquée. Toutefois, dans la pratique, la quantité de débit réalisable est fondée sur l’accès concurrentiel de la charge de travail au niveau du réseau, c’est-à-dire le nombre de flux réseau et de points de terminaison réseau.
Lisez la section sur les Limites de flux réseau du document de bande passante réseau de machine virtuelle pour améliorer votre compréhension du sujet. Ce qu’il faut retenir c’est que plus il y a de flux réseau reliant le client au stockage, plus les performances potentielles sont élevées.
Oracle prend en charge deux clients NFS distincts, Kernel NFS et Direct NFS (dNFS). Jusqu’à récemment, Kernel NFS prenait en charge un flux réseau unique entre deux points de terminaison (calcul - stockage). Direct NFS, le plus performant des deux, prend en charge un nombre variable de flux réseau, les tests ont montré des centaines de connexions uniques par point de terminaison, qui augmentent ou diminuent en fonction des demandes de charge. En raison de la mise à l’échelle des flux réseau entre deux points de terminaison, Direct NFS est largement préféré à Kernel NFS noyau et, par conséquent, la configuration recommandée. Le groupe de produits Azure NetApp Files ne recommande pas l’utilisation de Kernel NFS avec les charges de travail Oracle. Pour plus d’informations, reportez-vous aux Avantages de l’utilisation d’Azure NetApp Files avec Oracle Database.
Concurrence d’exécution
Utiliser NFS direct, un seul circuit microprogrammé pour la cohérence et comprendre des contraintes de bande passante réseau présentent des limites. Au final, l’application génère des performances. Les preuves de concept utilisant SLOB2 et les preuves de concept utilisant une suite d’applications de chaîne logistique réelle sur des données client réelles ont été en mesure de générer des quantités significatives de débit uniquement parce que les applications étaient exécutées à des niveaux élevés de concurrence ; la première option utilisant un nombre important de threads par schéma et la deuxième utilisant plusieurs connexions à partir de plusieurs serveurs d’applications. En bref, la concurrence stimule la charge de travail, la faible concurrence-faible débit, la concurrence élevée-débit élevé tant que l’infrastructure est en place pour prendre en charge ceci.
Mise en réseau accélérée
Une mise en réseau accélérée permet d’opérer une virtualisation d’E/S d’une racine unique (SR-IOV) sur une machine virtuelle, ce qui améliore considérablement les performances de mise en réseau. Cette voie hautement performante court-circuite l’hôte à partir du chemin d’accès aux données, ce qui réduit la latence, l’instabilité et l’utilisation du processeur pour les charges de travail réseau les plus exigeantes sur les types de machines virtuelles pris en charge. Lors du déploiement de machines virtuelles via des utilitaires de gestion de configuration tels que terraform ou ligne de commande, sachez que la mise en réseau accélérée n’est pas activée par défaut. Pour des performances optimales, activez la mise en réseau accélérée. Notez que la mise en réseau accélérée est activée ou désactivée sur une interface réseau par interface réseau. La fonctionnalité de mise en réseau accélérée est une fonctionnalité qui peut être activée ou désactivée dynamiquement.
Remarque
Cet article contient des références au terme SLAVE, un terme que Microsoft n’utilise plus. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
Une approche faisant autorité pour s’assurer que la mise en réseau accélérée est activée pour une carte réseau consiste à passer par le terminal Linux. Si la mise en réseau accélérée est activée pour une carte réseau, une deuxième carte réseau virtuelle est présente et associée à la première carte réseau. Cette deuxième carte réseau est configurée par le système avec l’indicateur SLAVE activé. Si aucune carte réseau n’est présente avec l’indicateur SLAVE, la mise en réseau accélérée n’est pas activée pour cette interface.
Dans le scénario où plusieurs cartes réseau sont configurées, vous devez déterminer quelle interface SLAVE est associée à la carte réseau utilisée pour monter le volume NFS. L’ajout de cartes d’interface réseau à la machine virtuelle n’a aucun effet sur les performances.
Utilisez le processus suivant pour identifier le mappage entre l’interface réseau configurée et son interface virtuelle associée. Ce processus valide que la mise en réseau accélérée est activée pour une carte réseau spécifique sur votre ordinateur Linux et affiche la vitesse d’entrée physique que la carte réseau peut atteindre.
- Exécutez la commande
ip a: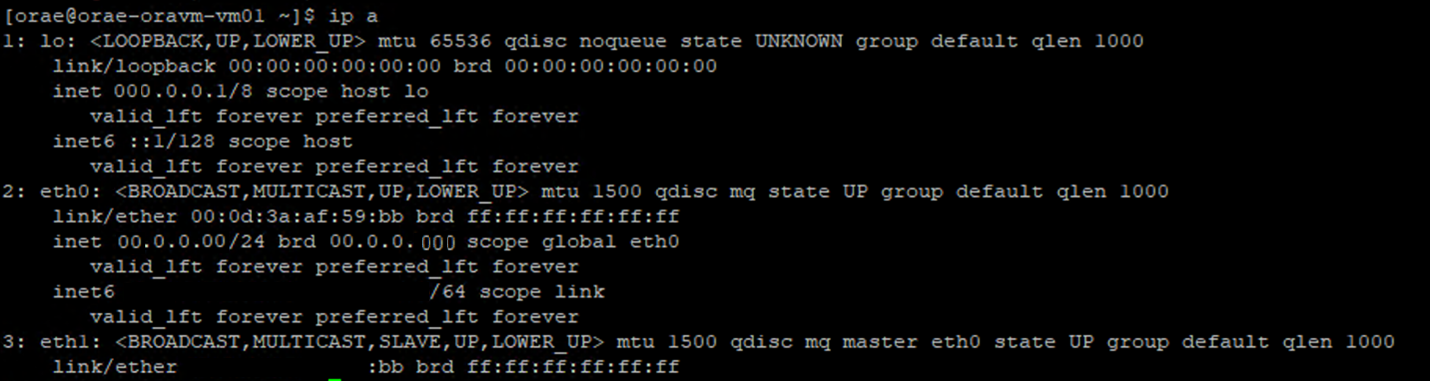
- Listez le répertoire
/sys/class/net/de l’ID de carte réseau que vous vérifiez (eth0dans l’exemple) etgreppour le mot inférieur :ls /sys/class/net/eth0 | grep lower lower_eth1 - Exécutez la commande
ethtoolsur l’appareil Ethernet identifié comme appareil inférieur à l’étape précédente.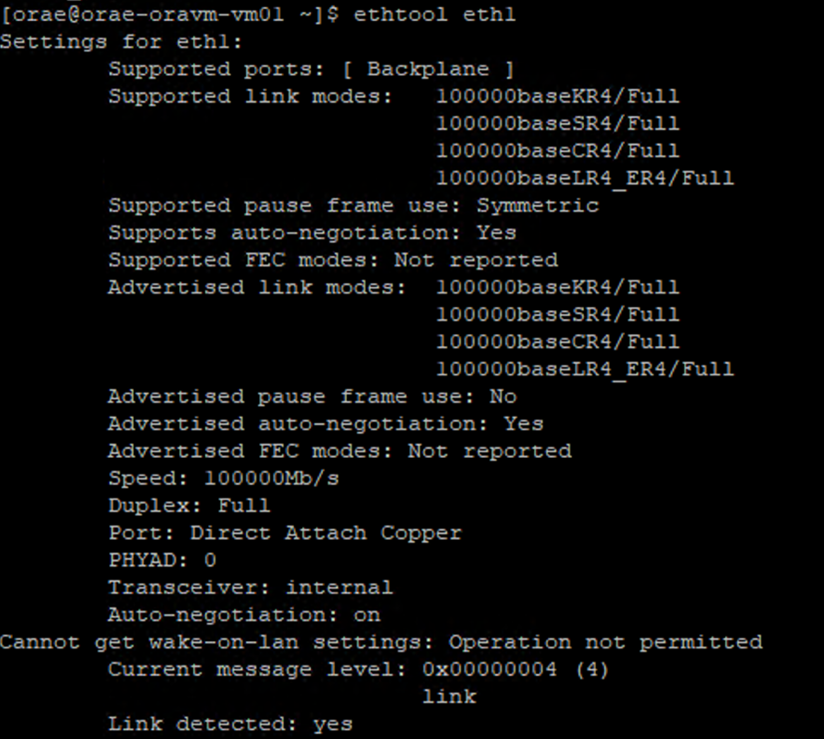
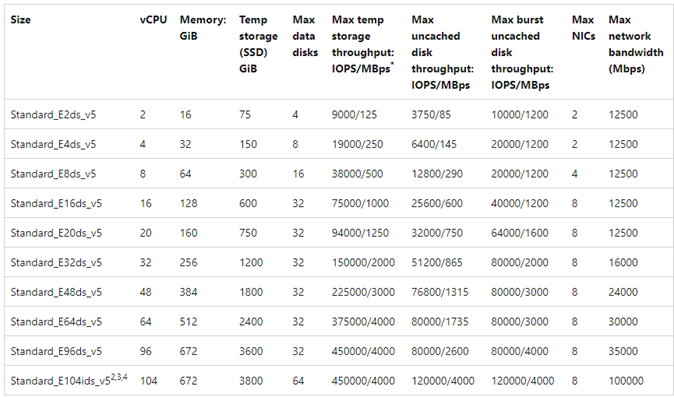
Machine virtuelle Azure : Limites de bande passante réseau vs disque
Un niveau d’expertise est requis lors de la lecture de la documentation sur les limites de performances des machines virtuelles Azure. Soyez attentif aux points suivants :
- Le débit de stockage temporaire et les numéros d’IOPS font référence aux fonctionnalités de performances du stockage éphémère sur boîte directement attaché à la machine virtuelle.
- Le débit de disque non mis en cache et les numéros d’E/S font spécifiquement référence à Azure Disk (Premium, Premium v2 et Ultra) et n’ont aucune incidence sur le stockage attaché au réseau tel qu’Azure NetApp Files.
- L’attachement de cartes réseau supplémentaires à la machine virtuelle n’a aucun impact sur les limites de performances ou les fonctionnalités de performances de la machine virtuelle (documentées et éprouvées).
- La bande passante réseau maximale fait référence aux limites de sortie (autrement dit, les écritures quand Azure NetApp Files est impliqué) appliquées à la bande passante réseau de la machine virtuelle. Aucune limite d’entrée (autrement dit, les lectures quand Azure NetApp Files est impliqué) n’est appliquée. Avec suffisamment de processeur, suffisamment de concurrence réseau et suffisamment de points de terminaison enrichis, une machine virtuelle peut théoriquement conduire le trafic d’entrée aux limites de la carte réseau. Comme mentionné dans la section Bande passante réseau disponible, utilisez des outils tels que
ethtoolpour voir la bande passante de la carte réseau.
Un exemple de graphique est affiché pour référence :
Azure NetApp Files
Le service de stockage Azure premier niveau Azure NetApp Files fournit une solution de stockage entièrement managée hautement disponible capable de prendre en charge les charges de travail Oracle exigeantes, présentées précédemment.
Étant donné que les limites des performances de stockage de montée en puissance dans une base de données Oracle sont bien comprises, cet article se concentre intentionnellement sur les performances du stockage avec montée en puissance parallèle. La montée en puissance des performances de stockage implique d’accorder à une instance Oracle unique l’accès à de nombreux volumes Azure NetApp Files où ces volumes sont distribués sur plusieurs points de terminaison de stockage.
En mettant à l’échelle une charge de travail de base de données sur plusieurs volumes de cette façon, les performances de la base de données ne sont pas associées à des limites supérieures de volume et de point de terminaison. Avec le stockage qui n’impose plus de limitations de performances, l’architecture de machine virtuelle (processeur, carte réseau et limites de sortie de machine virtuelle) devient le point d’étranglement auquel il faut faire face. Comme indiqué dans la section Machine virtuelle, la sélection des instances E104ids_v5 et E96ds_v5 a été prises en compte.
Qu’une base de données soit placée sur un volume de grande capacité unique ou répartie sur plusieurs volumes plus petits, le coût financier total est le même. L’avantage de distribuer des E/S sur plusieurs volumes et points de terminaison contrairement à un seul volume et point de terminaison est l’évitement des limites de bande passante ; ainsi, vous utilisez entièrement ce que vous payez.
Important
Pour déployer à l’aide d’Azure NetApp Files dans une configuration multiple volume:multiple endpoint, contactez votre spécialiste Azure NetApp Files ou votre architecte de solution cloud pour obtenir de l’aide.
Base de données
La version 19c de la base de données Oracle est la version actuelle d’Oracle à long terme et celle utilisée pour produire tous les résultats des tests abordés dans ce document.
Pour des performances optimales, tous les volumes de base de données ont été montés à l’aide de Direct NFS, Kernel NFS n’est pas recommandé en raison des contraintes de performances. Pour obtenir une comparaison des performances entre les deux clients, reportez-vous à performances de base de données Oracle sur des volumes uniques Azure NetApp Files. Notez que toutes les correctifs dNFS pertinents (ID de support Oracle 1495104) ont été appliqués, comme les meilleures pratiques décrites dans le rapport Bases de données Oracle sur Microsoft Azure en utilisant Azure NetApp Files.
Bien qu’Oracle et Azure NetApp Files prennent en charge NFSv3 et NFSv4.1, étant donné que NFSv3 est le protocole plus mature, il est généralement considéré comme ayant la plus grande stabilité et c’est l’option la plus fiable pour les environnements qui sont très sensibles aux perturbations. Le test décrit dans cet article a été réalisé sur NFSv3.
Important
Certains des correctifs recommandés qu’Oracle documente dans l’ID de support 1495104 sont essentiels pour maintenir l’intégrité des données lors de l’utilisation de dNFS. L’application de ces correctifs est fortement recommandée pour les environnements de production.
La gestion automatique du stockage (ASM) est prise en charge pour les volumes NFS. Bien qu’elle soit généralement associée au stockage basé sur des blocs où ASM remplace la gestion des volumes logiques (LVM) et le système de fichiers, ASM joue un rôle précieux dans les scénarios NFS à plusieurs volumes et est digne de considération. Un des avantages d’ASM, à savoir l’ajout dynamique en ligne et le rééquilibrage sur les nouveaux volumes et points de terminaison NFS ajoutés, simplifie la gestion permettant l’expansion des performances et de la capacité à volonté. Bien que l’ASM n’augmente pas en soi les performances d’une base de données, son utilisation évite les fichiers chauds et la nécessité de gérer manuellement la distribution de fichiers, un avantage évident.
Une configuration ASM sur dNFS a été utilisée pour produire tous les résultats de test abordés dans cet article. Le diagramme suivant illustre la disposition du fichier ASM dans les volumes Azure NetApp Files et l’allocation de fichiers aux groupes de disques ASM.

Il y a certaines limitations liées à l’utilisation d’ASM sur les volumes montés NFS Azure NetApp Files lorsqu’il s’agit de captures instantanées de stockage qui peuvent être surmontés grâce à certaines considérations architecturales. Pour un examen approfondi de ces considérations, contactez votre spécialiste Azure NetApp Files ou votre architecte de solutions cloud.
Outils de test synthétiques et paramétrables
Cette section décrit l’architecture de test, les paramétrables et les détails de configuration de manière explicite. Alors que la section précédente est axée sur les raisons pour lesquelles les décisions de configuration sont prises, cette section se concentre spécifiquement sur le « quoi » des décisions de configuration.
Déploiement automatisé
- Les machines virtuelles de base de données sont déployées à l’aide de scripts bash disponibles sur gitHub.
- La disposition et l’allocation de plusieurs volumes et points de terminaison Azure NetApp Files sont effectuées manuellement. Vous devez travailler avec votre spécialiste Azure NetApp Files ou votre architecte de solution cloud pour obtenir de l’aide.
- L’installation de grille, la configuration ASM, la création et la configuration de la base de données et l’environnement SLOB2 sur chaque ordinateur sont configurés à l’aide d’Ansible pour la cohérence.
- Les exécutions de test SLOB2 parallèles sur plusieurs hôtes sont également effectuées à l’aide d’Ansible pour la cohérence et l’exécution simultanée.
Configuration des machines virtuelles
| Configuration | Valeur |
|---|---|
| Région Azure | Europe Ouest |
| Référence de la machine virtuelle | E104ids_v5 |
| Nombre de cartes réseau | 1 REMARQUE : l’ajout de cartes réseau virtuelles n’a aucun effet sur le nombre de systèmes |
| Bande passante réseau de sortie maximale (Mbits/s) | 100 000 |
| Stockage temporaire (SSD) en Gio | 3800 |
Configuration système
Tous les paramètres de configuration système requis par Oracle pour la version 19c ont été implémentés conformément à la documentation Oracle.
Les paramètres suivants ont été ajoutés au fichier système /etc/sysctl.conf Linux :
sunrpc.max_tcp_slot_table_entries: 128sunrpc.tcp_slot_table_entries = 128
Azure NetApp Files
Tous les volumes Azure NetApp Files ont été montés avec les options de montage NFS suivantes.
nfs rw,hard,rsize=262144,wsize=262144,sec=sys,vers=3,tcp
Paramètres de base de données
| Paramètres | Valeur |
|---|---|
db_cache_size |
2g |
large_pool_size |
2g |
pga_aggregate_target |
3g |
pga_aggregate_limit |
3g |
sga_target |
25g |
shared_io_pool_size |
500m |
shared_pool_size |
5g |
db_files |
500 |
filesystemio_options |
SETALL |
job_queue_processes |
0 |
db_flash_cache_size |
0 |
_cursor_obsolete_threshold |
130 |
_db_block_prefetch_limit |
0 |
_db_block_prefetch_quota |
0 |
_db_file_noncontig_mblock_read_count |
0 |
Configuration SLOB2
Toutes les générations de charges de travail pour les tests ont été effectuées à l’aide de l’outil SLOB2 version 2.5.4.
Quatorze schémas SLOB2 ont été chargés dans un espace disque Oracle standard et exécutés par rapport aux paramètres du fichier de configuration slob répertoriés, mettez le jeu de données SLOB2 à 7 Tio. Les paramètres suivants reflètent une exécution de lecture aléatoire pour SLOB2. Le paramètre de configuration SCAN_PCT=0 a été remplacé par SCAN_PCT=100 lors du test séquentiel.
UPDATE_PCT=0SCAN_PCT=0RUN_TIME=600SCALE=450GSCAN_TABLE_SZ=50GWORK_UNIT=32REDO_STRESS=LITETHREADS_PER_SCHEMA=1DATABASE_STATISTICS_TYPE=awr
Pour les tests de lecture aléatoires, neuf exécutions SLOB2 ont été effectuées. Le nombre de threads a été augmenté de six avec chaque itération de test à partir de un.
Pour les tests séquentiels, sept exécutions SLOB2 ont été effectuées. Le nombre de threads a été augmenté de deux avec chaque itération de test à partir de un. Le nombre de threads a été limité à six en raison de l’atteinte des limites maximales de bande passante réseau.
Métriques AWR
Toutes les métriques de performances ont été signalées via le référentiel de charge de travail automatique Oracle (AWR). Voici les métriques présentées dans les résultats :
- Débit : somme du débit de lecture moyen et du débit d’écriture de la section Profil de charge AWR
- Demandes d’E/S de lecture moyennes à partir de la section Profil de charge AWR
- Durée d’attente moyenne des événements de lecture séquentielle du fichier de base de données à partir de la section Événements d’attente de premier plan AWR
Migration à partir de systèmes spécialement conçus vers le cloud
Oracle Exadata est un système conçu : une combinaison de matériel et de logiciel, qui est considérée comme la solution la plus optimisée pour l’exécution des charges de travail Oracle. Bien que le cloud présente des avantages significatifs dans le schéma global du monde technique, ces systèmes spécialisés peuvent sembler incroyablement attrayants pour ceux qui ont lu et vu les optimisations qu’Oracle a créées autour de leurs charges de travail spécifiques.
Quand il s’agit d’exécuter Oracle sur Exadata, voici quelques raisons courantes pour lesquelles Exadata est choisi :
- 1-2 charges de travail d’E/S élevées qui conviennent bien aux fonctionnalités Exadata et, étant donné que ces charges de travail nécessitent des fonctionnalités d’ingénierie Exadata importantes, le reste des bases de données exécutées avec ont été consolidées selon Exadata.
- Les charges de travail OLTP complexes ou difficiles qui nécessitent RAC pour la mise à l’échelle et sont difficiles à concevoir avec du matériel protégé sans connaissance approfondie de l’optimisation d’Oracle ou peuvent être une dette technique impossible à optimiser.
- Exadata existant sous-utilisé avec différentes charges de travail : cela existe soit en raison des migrations précédentes, de la fin de vie sur un Exadata précédent, soit en raison d’un souhait de travailler/tester un Exadata en interne.
Il est essentiel que toute migration à partir d’un système Exadata soit comprise du point de vue des charges de travail et de la complexité de la migration. En outre, il est essentiel de comprendre la raison de l’achat d’Exadata du point de vue de l’état. Les compétences Exadata et RAC sont plus demandées et peuvent avoir conduit à un achat par les parties prenantes techniques.
Important
Peu importe le scénario, ce qu’il faut retenir pour toute charge de travail de base de données provenant d’un Exadata, plus les fonctionnalités protégées d’Exadata sont utilisées, plus la migration et la planification sont complexes. Les environnements qui n’utilisent pas fortement les fonctionnalités protégées d’Exadata ont des opportunités pour un processus de migration et de planification plus simple.
Il existe plusieurs outils qui peuvent être utilisés pour évaluer ces opportunités de charge de travail :
- Le référentiel de charge de travail automatique (AWR) :
- Toutes les bases de données Exadata ont une licence leur permettant d’utiliser des rapports AWR et des fonctionnalités de performances et de diagnostic connectées.
- Est toujours activé et collecte des données qui peuvent être utilisées pour afficher les informations de charge de travail historiques et évaluer l’utilisation. Les valeurs de pointe peuvent évaluer l’utilisation élevée sur le système.
- Les rapports AWR de fenêtre plus volumineuse peuvent évaluer la charge de travail globale, en fournissant des informations précieuses sur l’utilisation des fonctionnalités et sur la façon de migrer la charge de travail vers des données non Exadata efficacement. En revanche, les rapports AWR de pointe conviennent le mieux à l’optimisation des performances et la résolution des problèmes.
- Le rapport AWR global (RAC-Aware) pour Exadata inclut également une section spécifique à Exadata, qui explore l’utilisation spécifique des fonctionnalités Exadata et fournit un aperçu précieux du cache flash d’informations, de la journalisation flash, des E/S et d’autres utilisations des fonctionnalités par base de données et nœud de cellule.
Découplage à partir d’Exadata
Lors de l’identification des charges de travail Oracle Exadata à migrer vers le cloud, tenez compte des questions et des points de données suivants :
- La charge de travail consomme-t-elle plusieurs fonctionnalités Exadata, en dehors des avantages matériels ?
- Analyses intelligentes
- Index de stockage
- Cache flash
- Journalisation flash
- Compression en colonnes hybride
- La charge de travail utilise-t-elle le déchargement Exadata efficacement ? Dans les événements de premier plan de temps les plus fréquents, quel est le ratio (plus de 10 % du temps de base de données) de la charge de travail en utilisant :
- Analyse de table intelligente de cellule (optimale)
- Lecture physique multibloc de cellule (moins optimale)
- Lecture physique d’un bloc de cellule (moins optimale)
- Compression en colonnes hybrides (HCC/EHCC) : qu’est sont les ratios compressés vs les ratios non compressés :
- La base de données dépense-t-elle plus de 10 % du temps de la base de données pour compresser et décompresser les données ?
- Examinez les gains de performances des prédicats à l’aide de la compression dans les requêtes : la valeur est-elle acquise par rapport à la quantité enregistrée avec la compression ?
- E/S physique de cellule : inspectez les économies obtenues de :
- la quantité dirigée vers le nœud de base de données pour équilibrer le processeur.
- l’identification du nombre d’octets retournés par l’analyse intelligente. Ces valeurs peuvent être soustraites en E/S pour le pourcentage de lectures physiques de bloc de cellule une fois qu’elles migrent hors d’Exadata.
- Notez le nombre de lectures logiques à partir du cache. Déterminez si le cache flash sera requis dans une solution IaaS cloud pour la charge de travail.
- Comparez les octets physiques de lecture et d’écriture au total effectué dans le cache. La mémoire peut-elle être élevée pour éliminer les exigences de lecture physique (souvent le SGA est réduit pour forcer le déchargement pour Exadata) ?
- Dans Statistiques système, identifiez quels objets sont affectés par quelle statistique. Si vous réglez SQL, l’indexation, le partitionnement ou tout autre réglage physique peut optimiser considérablement la charge de travail.
- Inspectez les Paramètres d’initialisation pour les paramètres de soulignement (_) ou déconseillés, qui doivent être justifiés en raison de l’impact au niveau de la base de données qu’ils peuvent entraîner sur les performances.
Configuration du serveur Exadata
Dans Oracle version 12.2 et ultérieure, un ajout spécifique à Exadata sera inclus dans le rapport global AWR. Ce rapport contient des sections qui fournissent une valeur exceptionnelle vers une migration à partir d’Exadata.
Détails de la version et du système Exadata
Détails des alertes de nœud de cellule
Disques non en ligne Exadata
Données hors norme pour toutes les statistiques de système d’exploitation Exadata
Jaune/Rose : préoccupant. Exadata ne s’exécute pas de manière optimale.
Rouge : les performances Exadata sont significativement affectées.
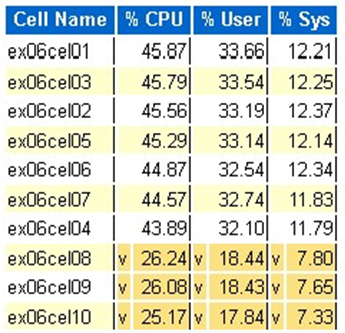
Statistique du processeur du système d’exploitation Exadata : cellules supérieures
- Ces statistiques sont collectées par le système d’exploitation sur les cellules et ne sont pas limitées à cette base de données ou à ces instances
- Un
vet un arrière-plan jaune foncé indiquent une valeur hors norme en dessous de la plage basse - Un
^et un arrière-plan jaune clair indiquent une valeur hors norme au-dessus de la plage élevée - Les cellules supérieures par pourcentage de processeur sont affichées et sont dans l’ordre décroissant du pourcentage de processeur
- Moyenne : 39,34 % processeur, 28,57 % utilisateur, 10,77 % sys
Lectures de blocs physiques à cellule unique
Utilisation du cache flash
E/S temporaire
Efficacité du cache en colonnes
Débit supérieur de la base de données par E/S
Bien que les évaluations de dimensionnement puissent être effectuées, il existe des questions sur les moyennes et les pics simulés intégrés à ces valeurs pour les charges de travail volumineuses. Cette section, trouvée à la fin d’un rapport AWR, est extrêmement utile, car elle montre à la fois l’utilisation moyenne du flash et du disque des 10 principales bases de données sur Exadata. Beaucoup pourraient vouloir dimensionner des bases de données pour obtenir des performances maximales dans le cloud, mais cela n’est pas judicieux pour la plupart des déploiements (plus de 95 % se trouve dans la plage moyenne, avec un pic simulé calculé dont la plage moyenne est supérieure à 98 %). Il est important de payer ce qui est nécessaire, même pour les charges de travail à la demande d’Oracle les plus élevées et inspecter les Bases de données principales par débit d’E/S peut être instructif pour comprendre les besoins en ressources de la base de données.
Taille appropriée d’Oracle en utilisant l’AWR sur Exadata
Lors de l’exécution de la planification de la capacité pour les systèmes locaux, il est naturel d’avoir une surcharge importante intégrée au matériel. Le matériel sur-provisionné doit servir la charge de travail Oracle pendant plusieurs années, quelle que soit la charge de travail ajoutée en raison de la croissance des données, des modifications de code ou des mises à niveau.
L’un des avantages du cloud est la mise à l’échelle des ressources dans un hôte de machine virtuelle et le fait que le stockage puisse être réalisé au fur et à mesure de l’augmentation des demandes. Cela permet de réduire les coûts cloud et les coûts de licence associés à l’utilisation du processeur (pertinents avec Oracle).
Le redimensionnement approprié implique la suppression du matériel de la migration classique du lift-and-shift et l’utilisation des informations de charge de travail fournies par le référentiel de charge de travail automatique (AWR) d’Oracle pour lever et déplacer la charge de travail vers le calcul et le stockage, spécialement conçus pour la prendre en charge dans le cloud sélectionné par le client. Le processus de dimensionnement approprié garantit que l’architecture supprime à l’avenir la dette technique de l’infrastructure, la redondance de l’architecture qui se produirait si la duplication du système local a été répliquée sur le cloud et implémente les services cloud dans la mesure du possible.
Les experts techniques de Microsoft Oracle ont estimé que plus de 80 % des bases de données Oracle sont sur-provisionnées et qu’elles bénéficient des mêmes coûts ou économies en accédant au cloud si elles prennent le temps de redimensionner de manière appropriée la charge de travail de base de données Oracle avant de migrer vers le cloud. Cette évaluation nécessite que les spécialistes de la base de données de l’équipe changent d’état d’esprit sur la façon dont ils peuvent avoir effectué la planification de la capacité par le passé, mais cela vaut la peine d’investir dans le cloud et la stratégie cloud de l’entreprise.
Étapes suivantes
- Exécuter vos charges de travail Oracle les plus exigeantes dans Azure sans sacrifier les performances ou la scalabilité
- Architectures de solution avec Azure NetApp Files - Oracle
- Concevoir et implémenter une base de données Oracle dans Azure
- Outil d’estimation pour dimensionner des charges de travail Oracle sur des machines virtuelles IaaS Azure
- Architectures de référence pour Oracle Database Enterprise Edition sur Azure
- Comprendre les groupes de volumes d’application Azure NetApp Files pour SAP HANA