Basculement et mise à jour corrective pour Azure Managed Redis (préversion)
Pour générer des applications clientes résilientes et réussies, il est essentiel de comprendre ce qu’est un basculement dans le service Azure Managed Redis (préversion). Un basculement peut faire partie des opérations de gestion planifiées, ou il peut être dû à des défaillances matérielles ou réseau non planifiées. Le basculement du cache de correctifs est particulièrement utilisé lorsque le service de gestion corrige les fichiers binaires Azure Managed Redis.
Dans cet article, vous trouverez les informations suivantes :
- Qu’est-ce qu’un basculement ?
- Comment le basculement se produit lors d’une mise à jour corrective.
- Comment créer une application cliente résiliente.
Qu’est-ce qu’un basculement ?
Commençons par un aperçu du basculement pour Azure Managed Redis.
Un rapide résumé de l’architecture du cache
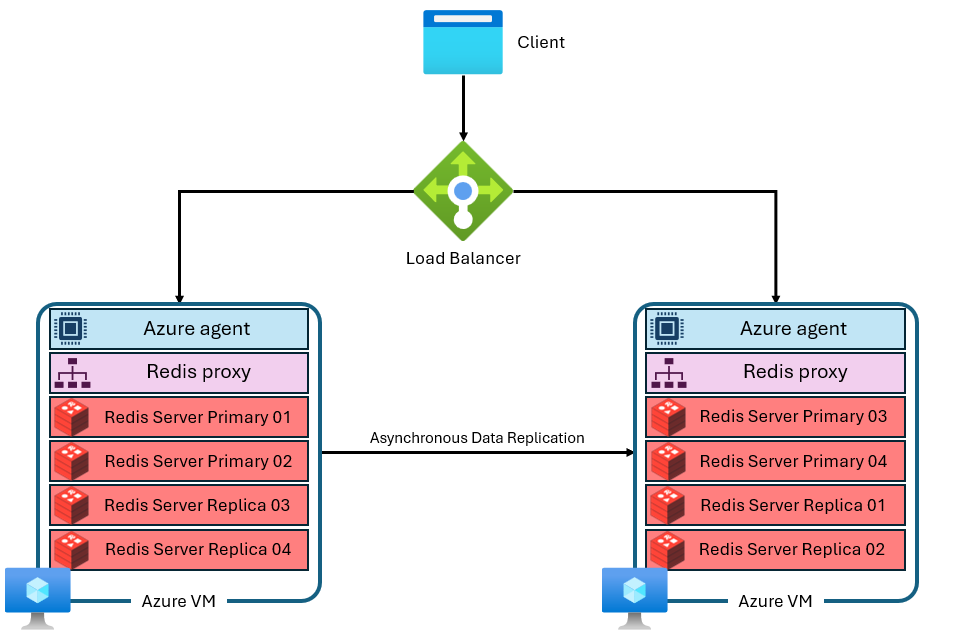
Un cache se compose de plusieurs machines virtuelles avec des adresses IP privées et distinctes. Chaque machine virtuelle (ou « nœud ») exécute plusieurs processus de serveur Redis (appelés « partitions ») en parallèle. Plusieurs partitions permettent une utilisation plus efficace des processeurs virtuels sur chaque machine virtuelle et des performances plus élevées. Toutes les partitions Redis principales ne se trouvent pas sur la même machine virtuelle ou sur le même nœud. Au lieu de cela, les partitions principales et de réplica sont réparties entre les deux nœuds. Étant donné que les partitions principales utilisent plus de ressources de processeur que les partitions de réplica, cette approche permet d’exécuter plus de partitions principales en parallèle. Chaque nœud dispose d’un processus de proxy hautes performances pour gérer les partitions et la gestion des connexions, et pour déclencher la réparation automatique. Une partition peut être en panne pendant que les autres restent disponibles.
Pour plus d’informations sur l’architecture d’Azure Managed Redis, consultez ceci.
Explication d’un basculement
Un basculement se produit lorsqu’une ou plusieurs partitions de réplicas sont promues pour devenir des partitions primaires et que les anciennes partitions primaires ferment les connexions existantes. Un basculement peut être planifié ou non.
Un basculement planifié a lieu à deux moments différents :
- Mises à jour système, telles que les mises à niveau du système d’exploitation ou les mises à jour correctives Redis.
- Opérations de gestion, telles que la mise à l’échelle et le redémarrage.
Étant donné que les nœuds sont avertis à l’avance de la mise à jour, ils peuvent échanger des rôles de manière coopérative et indiquer rapidement la modification à l’équilibreur de charge. Un basculement planifié se termine généralement en moins de 1 seconde.
Un basculement non planifié peut se produire en raison d’une défaillance matérielle, d’une défaillance de réseau ou d’autres pannes inattendues d’un ou de plusieurs nœuds du cluster. La ou les partitions de réplica sur le ou les nœuds restants sont promues en serveur principal pour maintenir la disponibilité, mais le processus prend plus de temps. La partition de réplica doit tout d’abord détecter que sa partition principale n’est pas disponible avant de pouvoir démarrer le processus de basculement. La partition de réplica doit également vérifier que cette défaillance non planifiée n’est ni temporaire ni locale, afin d’éviter un basculement inutile. Ce retard de détection signifie qu’un basculement non planifié se termine généralement dans un délai de 10 à 15 secondes.
Comment la mise à jour corrective a-t-elle lieu ?
Le service Azure Managed Redis met régulièrement à jour votre cache avec les fonctionnalités et les correctifs les plus récents de la plateforme. Pour corriger un cache, le service effectue les étapes suivantes :
- Le service crée de nouvelles machines virtuelles à jour pour remplacer toutes les machines virtuelles en cours de mise à jour.
- Il promeut ensuite l’une des nouvelles machines virtuelles « responsable du cluster ».
- Un par un, tous les nœuds corrigés sont supprimés du cluster. Toutes les partitions de ces machines virtuelles seront rétrogradées et migrées vers l’une des nouvelles machines virtuelles.
- Enfin, toutes les machines virtuelles qui ont été remplacées sont supprimées.
Chaque fragment d'un cache en cluster est corrigé séparément et ne ferme pas les connexions à un autre fragment.
Si plusieurs caches se trouvent dans le même groupe de ressources et la même région, ils sont également corrigés un à un. Les caches qui se trouvent dans des groupes de ressources différents ou des régions différentes peuvent être corrigés simultanément.
Étant donné que la synchronisation complète des données se produit avant la répétition du processus, il est peu probable que des données soient perdues pour votre cache. Vous pouvez vous prémunir davantage contre la perte de données en exportant les données et en activant la persistance.
Charge de cache supplémentaire
Chaque fois qu’un basculement se produit, les caches doivent répliquer les données d’un nœud à l’autre. Cette réplication entraîne une augmentation de la charge au niveau de la mémoire et du processeur du serveur. Si l’instance de cache est déjà très chargée, les applications clientes peuvent subir une latence accrue. Dans des cas extrêmes, les applications clientes peuvent recevoir des exceptions de délai d’expiration.
Quel est l’impact d’un basculement sur mon application cliente ?
Des applications clientes pourraient recevoir des erreurs de leur instance Azure Managed Redis. Le nombre d’erreurs détectées par une application cliente dépend du nombre d’opérations en attente sur cette connexion au moment du basculement. Toute connexion acheminée via le nœud ayant fermé ses connexions rencontre des erreurs.
De nombreuses bibliothèques clientes peuvent lever différents types d’erreurs en cas d’interruption des connexions, à savoir :
- Exceptions de délai d’attente
- Exceptions de connexion
- Exceptions de socket
Le nombre et le type d’exceptions dépendent de l’emplacement de la demande dans le chemin du code quand le cache ferme ses connexions. Par exemple, une opération qui envoie une requête mais qui ne reçoit pas de réponse quand le basculement se produit peut obtenir une exception de délai d’expiration. Les nouvelles requêtes sur l’objet de connexion fermé reçoivent des exceptions de connexion jusqu’à ce que la connexion soit rétablie.
La plupart des bibliothèques clientes tentent de se reconnecter au cache si elles sont configurées pour ce faire. Toutefois, des bogues imprévus peuvent parfois placer les objets de bibliothèque dans un état irrécupérable. Si les erreurs persistent plus longtemps qu’une durée préconfigurée, l’objet de connexion doit être recréé. Dans Microsoft.NET et d’autres langages orientés objet, il est possible de recréer la connexion sans redémarrer l’application à l’aide d’un modèle ForceReconnect.
Quelles sont les mises à jour incluses sous maintenance ?
La maintenance inclut ces mises à jour :
- Mises à jour du serveur Redis : toutes les mises à jour ou correctifs des fichiers binaires du serveur Redis.
- Mises à jour de machine virtuelle : toutes les mises à jour de la machine virtuelle hébergeant le service Redis. Les mises à jour de machine virtuelle comprennent des correctifs pour les composants de logiciels dans l’environnement d’hébergement à la mise à niveau des composants réseau ou à la désactivation de matériel.
La maintenance apparaît-elle dans l’intégrité du service dans le portail Azure avant un correctif ?
Non, la maintenance n’apparaît pas sous Intégrité du service dans le portail ou ailleurs.
Modifications de la configuration réseau du client
Certaines modifications de la configuration réseau côté client peuvent déclencher des erreurs de type Aucune connexion disponible. Ces modifications peuvent inclure :
- Le remplacement de l’adresse IP virtuelle d’une application cliente entre les emplacements intermédiaires et de production.
- Mise à l’échelle de la taille ou du nombre d’instances de votre application.
De telles modifications peuvent entraîner un problème de connectivité qui dure en général moins d’une minute. Il est probable que votre application client perde sa connexion avec d’autres ressources réseau externes, mais aussi avec le service Azure Managed Redis.
Intégrer la résilience
Vous ne pouvez pas éviter complètement les basculements. Au lieu de cela, écrivez vos applications clientes pour qu’elles soient résilientes aux interruptions de connexion et aux demandes ayant échoué. La plupart des bibliothèques de clients se reconnectent automatiquement au point de terminaison de cache, mais seules quelques-unes retentent les demandes ayant échoué. Selon le scénario de l’application, il peut être utile d’utiliser la logique de nouvelle tentative avec retrait.
Comment faire rendre mon application résiliente ?
Reportez-vous aux modèles de conception ci-dessous pour créer des clients résilients, en particulier aux modèles de disjoncteur et de nouvelle tentative :
- Modèles de fiabilité – Modèles de conception cloud
- Guide de nouvelle tentative pour les services Azure – Bonnes pratiques pour les applications cloud
- Implémenter de nouvelles tentatives avec interruption exponentielle