Synchronisation des ressources
La synchronisation des ressources vous permet de créer, mettre à jour ou supprimer des ressources directement sur le cluster Kubernetes à l’aide des API Kubernetes en mode connexion directe et de synchroniser automatiquement ces modifications sur Azure. Cet article explique la synchronisation des ressources.
Remarque
En tant que fonctionnalité en préversion, la technologie présentée dans cet article est soumise aux conditions d’utilisation supplémentaires des préversions de Microsoft Azure.
Les dernières mises à jour sont disponibles dans les notes de publication.
Lorsque vous déployez des services de données avec Azure Arc en mode connexion directe, le déploiement crée une règle de synchronisation de ressources. Cette règle de synchronisation de ressources garantit que les ressources Arc, comme l’instance managée SQL créée ou mise à jour en appelant directement les API Kubernetes, sont mises à jour de manière appropriée dans les ressources mappées dans Azure, et que les métadonnées de ressources sont synchronisées en permanence vers Azure. Cette règle est créée dans le même groupe de ressources que le contrôleur de données.
Remarque
La règle de synchronisation des ressources est créée par défaut, pendant le déploiement du contrôleur de données Azure Arc, et s’applique uniquement en mode connexion directe.
Sans la règle de synchronisation des ressources, l’instance managée SQL est créée à l’aide de la commande suivante :
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> -–subscription <subscription> --custom-location <custom-location> --storage-class-backups <RWX capable storageclass>
Dans ce scénario, les API Azure ARM sont d’abord appelées et la ressource Azure mappée est créée. Une fois cette ressource mappée créée avec succès, l’API Kubernetes est appelée pour créer l’instance managée SQL sur le cluster Kubernetes.
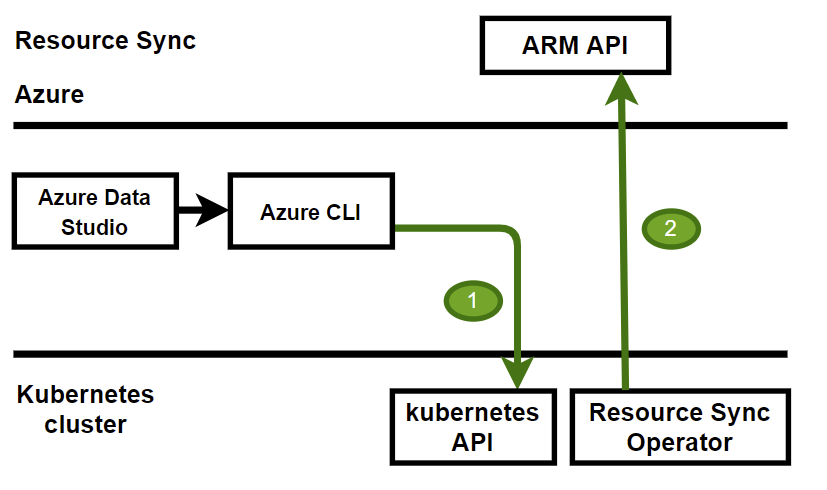
Avec la règle de synchronisation des ressources, vous pouvez utiliser l’API Kubernetes pour créer l’instance managée SQL avec Arc, comme suit :
az sql mi-arc create --name <name> --k8s-namespace <namespace> --use-k8s --storage-class-backups <RWX capable storageclass>
Dans ce scénario, l’instance managée SQL est directement créée dans le cluster Kubernetes. La règle de synchronisation des ressources garantit que la ressource équivalente dans Azure est également créée.
Si la règle de synchronisation des ressources est supprimée accidentellement, vous pouvez l’ajouter à nouveau pour restaurer la fonctionnalité de synchronisation à l’aide de l’API REST ci-dessous. Reportez-vous à la référence de l’API REST Azure pour obtenir des conseils sur l’exécution d’API REST. Veillez à utiliser l’abonnement aux ressources et le groupe de ressources du contrôleur de données.
https://management.azure.com/subscriptions/{{subscription}}/resourcegroups/{{resource_group}}/providers/microsoft.extendedlocation/customlocations/{{custom_location_name}}/resourcesyncrules/defaultresourcesyncrule?api-version=2021-08-31-preview
"location": "{{Azure region}}",
"properties": {
"targetResourceGroup": "/subscriptions/{{subscription}}/resourcegroups/{{resource_group_of_ data_controller}}",
"priority": 100,
"selector": {
"matchLabels": {
"management.azure.com/resourceProvider": "Microsoft.AzureArcData" //Mandatory
}
}
}
}
Limites
- La règle de synchronisation des ressources ne projette pas le contrôleur de données Azure Arc. Le contrôleur de données Azure Arc doit être déployé via l’API ARM.
- La synchronisation des ressources s’applique uniquement aux services de données comme l’instance managée SQL avec Arc, après le déploiement du contrôleur de données.
- La règle de synchronisation des ressources ne projette pas PostgreSQL avec Azure Arc
- La règle de synchronisation des ressources ne projette pas le connecteur Azure Arc Active Directory
- La règle de synchronisation des ressources ne projette pas les groupes de basculement d’instance Azure Arc
Contenu connexe
Créer un contrôleur de données Azure Arc en mode de connexion directe à l’aide de l’interface CLI