Haute disponibilité avec SQL Managed Instance activé par Azure Arc
SQL Managed Instance doté d’Azure Arc est déployé sur Kubernetes en tant qu’application conteneurisée. Il utilise des constructions Kubernetes telles que des ensembles avec état et un stockage persistant pour fournir ces éléments intégrés :
- Surveillance de l’intégrité
- Détection des défaillances
- Basculement automatique pour maintenir l’intégrité du service.
Pour plus de fiabilité, vous pouvez également configurer SQL Managed Instance doté d’Azure Arc à des fins de déploiement avec des réplicas supplémentaires dans une configuration de haute disponibilité. Le contrôleur de données des services de données Arc gère :
- Surveillance
- Détection des défaillances
- Basculement automatique
Le service de données avec Arc fournit ce service sans intervention de l’utilisateur. Le service :
- Configure le groupe de disponibilité
- Configure les points de terminaison de mise en miroir de bases de données
- Ajouter des bases de données au groupe de disponibilité
- Coordonne le basculement et la mise à niveau.
Ce document explore les deux types de haute disponibilité.
SQL Managed Instance doté d’Azure Arc offre différents niveaux de haute disponibilité selon si l’instance gérée SQL a été déployée en tant que niveau de service Usage général ou Critique pour l’entreprise.
Haute disponibilité au niveau de service Usage général
Au niveau de service Usage général, un seul réplica est disponible et la haute disponibilité est obtenue via l’orchestration Kubernetes. Par exemple, si un pod ou un nœud contenant l’image de conteneur de l’instance managée se bloque, Kubernetes tente de faire fonctionner un autre pod ou un autre nœud, et de s’attacher au même stockage persistant. Pendant ce temps, l’instance gérée SQL n’est pas disponible pour les applications. Les applications doivent se reconnecter et réessayer la transaction quand le nouveau pod est opérationnel. Si load balancer est le type de service utilisé, les applications peuvent se reconnecter au même point de terminaison principal et Kubernetes redirige la connexion vers le nouveau principal. Si le type de service est nodeport, les applications doivent se reconnecter à la nouvelle adresse IP.
Vérifier la haute disponibilité intégrée
Pour vérifier la haute disponibilité intégrée fournie par Kubernetes, vous pouvez :
- Supprimer le pod d’une instance managée existante
- Vérifier que Kubernetes récupère de cette action
Pendant la récupération, Kubernetes démarre un autre pod et attache le stockage persistant.
Prérequis
- Le cluster Kubernetes nécessite un stockage distant partagé.
- Une instance gérée SQL Managed Instance dotée d’Azure Arc déployée avec un réplica (par défaut)
Affichez les pods.
kubectl get pods -n <namespace of data controller>Supprimez le pod d’instance gérée.
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>Par exemple
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedAffichez les pods pour vérifier que l’instance gérée est en phase de récupération.
kubectl get pods -n <namespace of data controller>Par exemple :
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
Une fois tous les conteneurs du pod récupérés, vous pouvez vous connecter à l’instance managée.
Haute disponibilité au niveau de service Critique pour l’entreprise
Dans le niveau de service Critique pour l’entreprise, en plus de ce qui est fourni nativement par l’orchestration Kubernetes, SQL Managed Instance pour Azure Arc fournit un groupe de disponibilité autonome. Le groupe de disponibilité autonome repose sur la technologie Always On de SQL Server. Il offre des niveaux de disponibilité plus élevés. L’instance gérée SQL Managed Instance dotée d’Azure Arc, déployée avec le niveau de service Critique pour l’entreprise, peut être déployée avec 2 ou 3 réplicas. Ces réplicas sont toujours synchronisés entre eux.
Avec les groupes de disponibilité autonomes, les incidents des pods ou les défaillances des nœuds sont transparents pour l’application. Le groupe de disponibilité autonome fournit au moins un autre pod qui a toutes les données du serveur principal et est prêt à accepter des connexions.
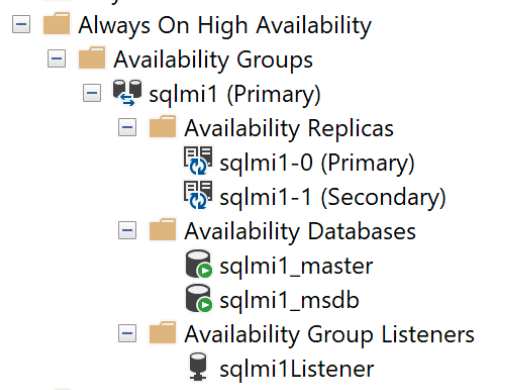
Groupes de disponibilité contenus
Un groupe de disponibilité lie une ou plusieurs bases de données utilisateur dans un groupe logique. Ainsi, en cas de basculement, l’ensemble du groupe de bases de données bascule vers le réplica secondaire en tant qu’unité unique. Un groupe de disponibilité réplique uniquement les données dans les bases de données utilisateur, mais pas les données dans les bases de données système telles que les connexions, les autorisations ou les travaux de l’agent. Un groupe de disponibilité contenu contient les métadonnées issues des bases de données système, telles que les bases de données msdb et master. Lorsque des connexions sont créées ou modifiées dans le réplica principal, elles sont également créées automatiquement dans les réplicas secondaires. De même, lors de la création ou de la modification d’un travail d’agent dans le réplica principal, les réplicas secondaires reçoivent également ces modifications.
SQL Managed Instance doté d’Azure Arc prend ce concept de groupe de disponibilité contenu et ajoute l’opérateur Kubernetes pour que ceux-ci puissent être déployés et gérés à grande échelle.
Fonctionnalités activées par les groupes de disponibilité contenus :
Lorsqu’il est déployé avec plusieurs réplicas, un groupe de disponibilité individuel portant le même nom que l’instance gérée SQL avec Arc est créé. Par défaut, le groupe de disponibilité contenu possède trois réplicas, y compris un réplica principal. Toutes les opérations CRUD pour le groupe de disponibilité sont gérées en interne, y compris la création du groupe de disponibilité ou la jonction des réplicas au groupe de disponibilité créé. Vous ne pouvez pas créer plus de groupes de disponibilité dans une instance.
Toutes les bases de données sont automatiquement ajoutées au groupe de disponibilité, y compris toutes les bases de données utilisateur et système telles que
masteretmsdb. Cette fonctionnalité fournit une vue monosystème sur les réplicas des groupes de disponibilité. Notez les bases de donnéescontainedag_masteretcontainedag_msdbsi vous vous connectez directement à l’instance. Les bases de donnéescontainedag_*représententmasteretmsdbau sein du groupe de disponibilité.Un point de terminaison externe est automatiquement provisionné pour la connexion aux bases de données au sein du groupe de disponibilité. Ce point de terminaison
<managed_instance_name>-external-svcjoue le rôle de l’écouteur du groupe de disponibilité.
Déployer SQL Managed Instance activé par Azure Arc avec plusieurs réplicas en utilisant le portail Azure
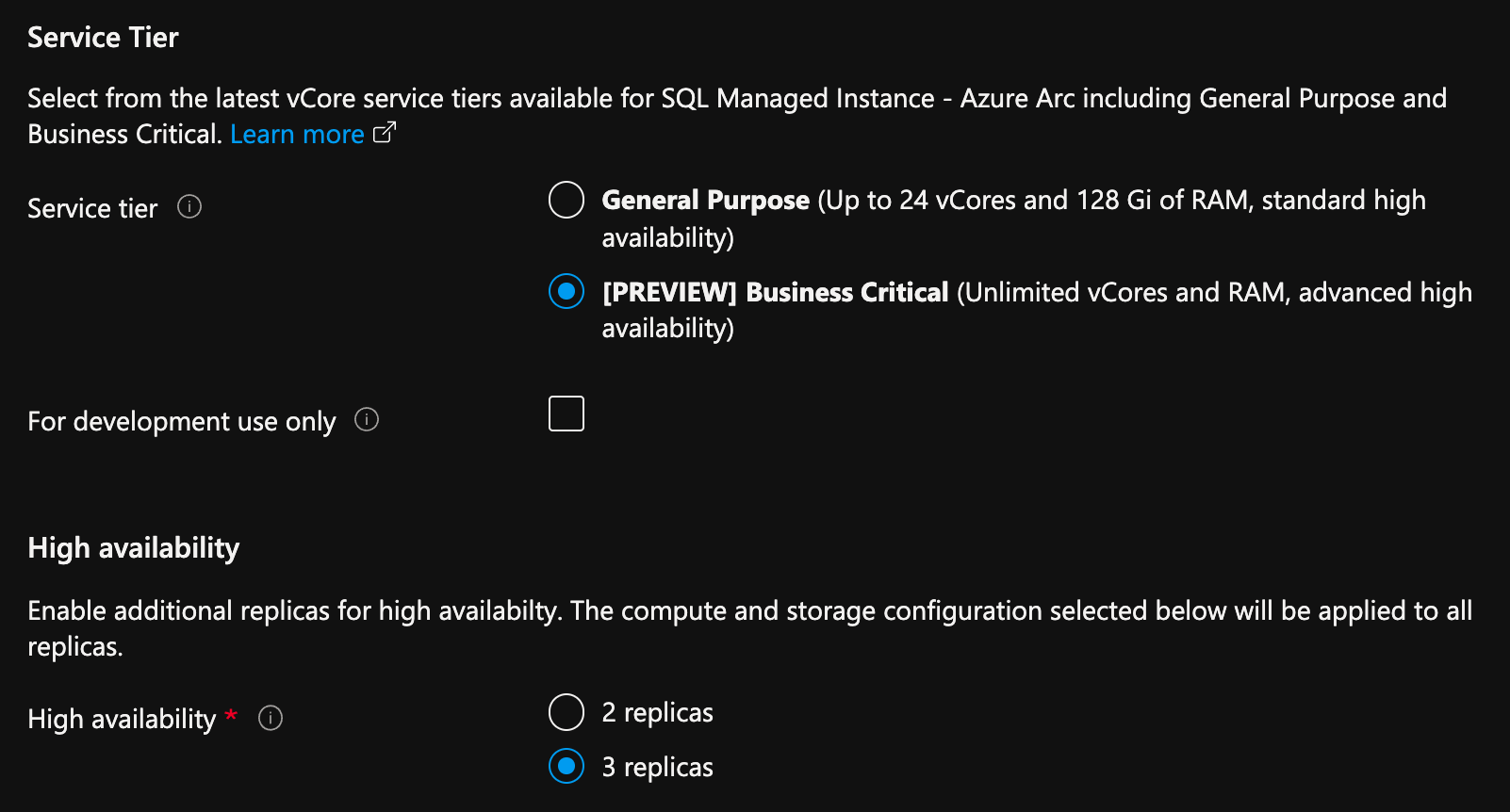
Dans le portail Azure, dans la page de création d’une instance SQL Managed Instance activée par Azure Arc :
- Sélectionnez Configurer calcul + stockage sous Calcul + Stockage. Le portail affiche les paramètres avancés.
- Sous Niveau de service, sélectionnez Critique pour l’entreprise.
- Cochez la case « Pour le développement uniquement », si vous l’utilisez à des fins de développement.
- Sous Haute disponibilité, sélectionnez 2 réplicas ou 3 réplicas.
Déployer avec plusieurs réplicas à l’aide d’Azure CLI
Quand une instance SQL Managed Instance activée par Azure Arc est déployée au niveau de service Critique pour l’entreprise, le déploiement crée plusieurs réplicas. L’installation et la configuration des groupes de disponibilité contenus parmi ces instances s’effectuent automatiquement au cours du provisionnement.
Par exemple, la commande suivante crée une instance géré avec 3 réplicas.
Mode de connexion indirecte :
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
Exemple :
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
Mode de connexion directe :
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
Exemple :
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
Par défaut, tous les réplicas sont configurés en mode synchrone. Cela signifie que les mises à jour sur l’instance principale sont répliquées de manière synchrone sur chacune des instances secondaires.
Afficher et surveiller l’état de haute disponibilité
Une fois le déploiement terminé, connectez-vous au point de terminaison principal à partir de SQL Server Management Studio.
Vérifiez et récupérez le point de terminaison du réplica principal et connectez-vous à celui-ci à partir de SQL Server Management Studio.
Par exemple, si l’instance SQL a été déployée à l’aide de service-type=loadbalancer, exécutez la commande ci-dessous pour récupérer le point de terminaison auquel vous connecter :
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
or
kubectl get sqlmi -A
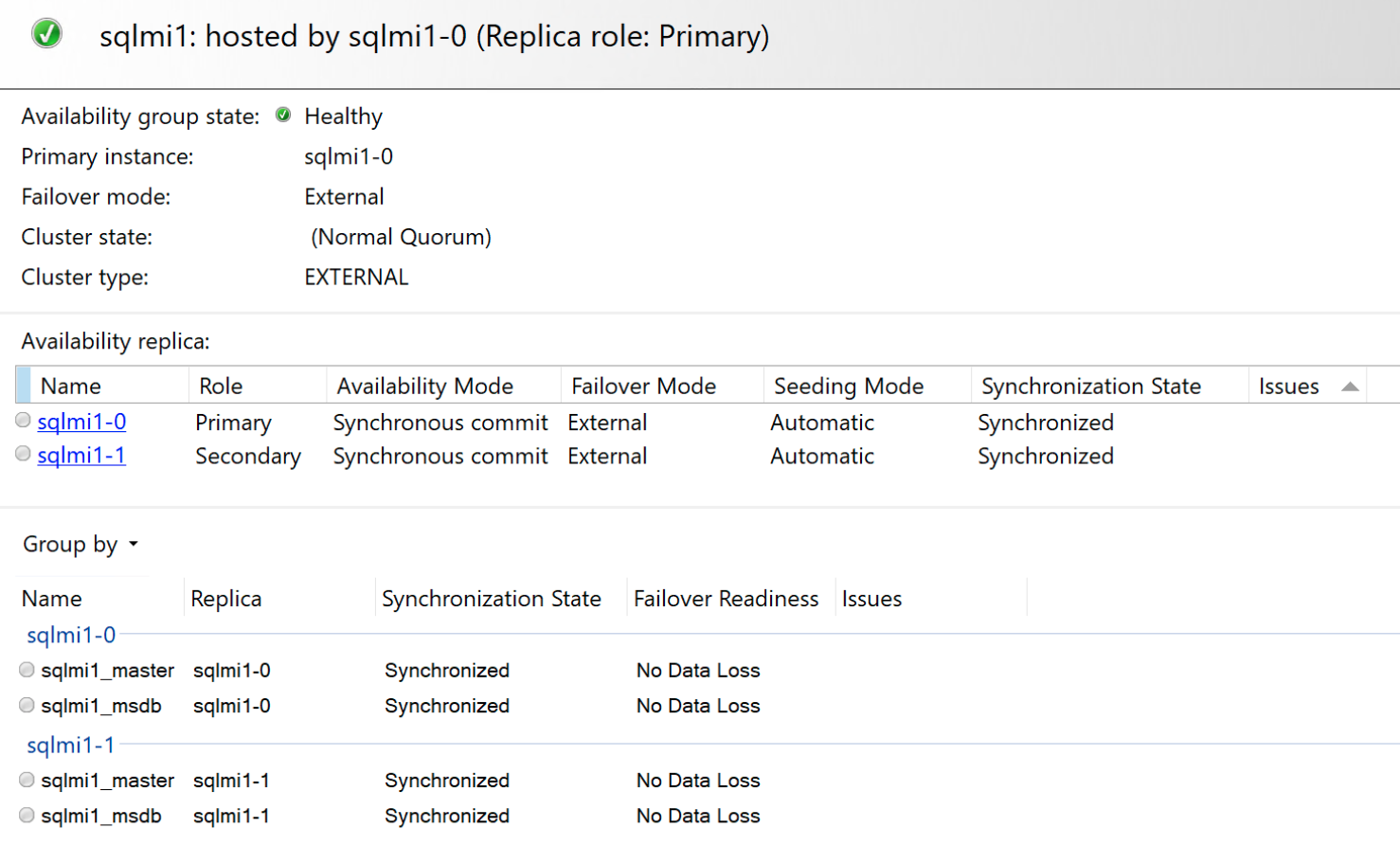
Obtenir les points de terminaison principal et secondaire et l’état du groupe de disponibilité
Utilisez la commande kubectl describe sqlmi ou az sql mi-arc show pour afficher les points de terminaison principaux et secondaires, ainsi que l’état de haute disponibilité.
Exemple :
kubectl describe sqlmi sqldemo -n my-namespace
or
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
Exemple de sortie :
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
Vous pouvez vous connecter au point de terminaison principal avec SQL Server Management Studio et vérifier des vues de gestion dynamiques telles que :
SELECT * FROM sys.dm_hadr_availability_replica_states
Et le tableau de bord de disponibilité contenu :
Scénario de basculement
Contrairement aux groupes de disponibilité Always On de SQL Server, le groupe de disponibilité contenu est une solution de haute disponibilité gérée. Par conséquent, les modes de basculement sont limités par rapport aux modes standard disponibles avec les groupes de disponibilité Always On de SQL Server.
Déployez des instances gérées SQL de niveau de service Critique pour l’entreprise dans une configuration à deux réplicas ou à trois réplicas. Les effets des échecs et la récupérabilité qui s’en suit sont différents avec chaque configuration. Une instance à trois réplicas fournit un niveau de disponibilité et de récupération plus élevé qu’une instance à deux réplicas.
Dans une configuration à deux réplicas, lorsque les états du nœud sont SYNCHRONIZED, si le réplica principal devient indisponible, le réplica secondaire est automatiquement promu comme réplica principal. Quand le réplica défaillant redevient disponible, il est mis à jour avec toutes les modifications en attente. En cas de problèmes de connectivité entre les réplicas, le réplica principal peut ne pas valider de transactions, car chaque transaction doit être validée sur les deux réplicas avant qu’un succès soit renvoyé sur le réplica principal.
Dans une configuration à trois réplicas, une transaction doit être validée sur au moins 2 des 3 réplicas avant de renvoyer un message de réussite à l’application. En cas de défaillance, l’un des réplicas secondaires est automatiquement promu en réplica principal, tandis que Kubernetes tente de récupérer le réplica qui a échoué. Quand le réplica devient disponible, il est joint automatiquement au groupe de disponibilité autonome et les modifications en attente sont synchronisées. En cas de problèmes de connectivité entre les réplicas et si plus de 2 réplicas ne sont plus synchronisés, le réplica principal ne valide aucune transaction.
Remarque
Il est recommandé de déployer une instance gérée SQL au niveau Critique pour l’entreprise dans une configuration à trois réplicas au lieu d’une configuration à deux réplicas pour obtenir une perte de données quasiment nulle.
Pour effectuer un basculement du réplica principal vers l’un des réplicas secondaires, pour un événement planifié, exécutez la commande suivante :
Si vous vous connectez au réplica principal, vous pouvez utiliser le code T-SQL suivant pour basculer l’instance SQL vers l’un des réplicas secondaires :
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
Si vous vous connectez au réplica secondaire, vous pouvez utiliser le code T-SQL suivant pour promouvoir le réplica secondaire souhaité en réplica principal.
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
Réplica principal préféré
Vous pouvez également définir un réplica spécifique comme réplica principal à l’aide de la commande AZ dans l’interface CLI, comme suit :
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
Exemple :
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
Remarque
Kubernetes tente de définir le réplica préféré, mais il n’est pas garanti.
Restauration d’une base de données sur une instance à plusieurs réplicas
Des étapes supplémentaires sont nécessaires pour restaurer une base de données dans un groupe de disponibilité. Les étapes suivantes montrent comment restaurer une base de données dans une instance gérée et l’ajouter à un groupe de disponibilité.
Exposez le point de terminaison externe d’instance principale en créant un nouveau service Kubernetes.
Déterminez le pod qui héberge le réplica principal. Connectez-vous à l’instance managée et exécutez :
SELECT @@SERVERNAMELa requête retourne le pod qui héberge le réplica principal.
Créez le service Kubernetes sur l’instance principale en exécutant la commande suivante si votre cluster Kubernetes utilise des services
NodePort. Remplacez<podName>par le nom du serveur retourné à l’étape précédente,<serviceName>par le nom favori du service Kubernetes créé.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortPour un service LoadBalancer, exécutez la même commande, sauf que le type du service créé est
LoadBalancer. Par exemple :kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerVoici un exemple de cette commande exécutée sur Azure Kubernetes Service, où le pod hébergeant le réplica principal est
sql2-0:kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancerObtenez l’adresse IP du service Kubernetes créé :
kubectl get services -n <namespaceName>Restaurez la base de données sur le point de terminaison d’instance principale.
Ajoutez le fichier de sauvegarde de base de au conteneur d’instance principale.
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>Exemple
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arcRestaurez le fichier de sauvegarde de base de données en exécutant la commande ci-dessous.
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GOExemple
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GOAjoutez la base de données au groupe de disponibilité.
Pour que la base de données soit ajoutée au groupe de disponibilité, elle doit s’exécuter en mode de récupération complète et une sauvegarde de fichier journal doit être effectuée. Exécutez les instructions TSQL ci-dessous pour ajouter la base de données restaurée au groupe de disponibilité.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>L’exemple suivant ajoute une base de données nommée
WideWorldImportersqui a été restaurée sur l’instance :ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
Important
En guide de bonne pratique, vous devez supprimer le service Kubernetes créé ci-dessus en exécutant cette commande :
kubectl delete svc sql2-0-p -n arc
Limites
Les groupes de disponibilité SQL Managed Instance doté d’Azure Arc présentent les mêmes limitations que les groupes de disponibilité de cluster Big Data. Pour plus d’informations, consultez Déployer Cluster Big Data SQL Server avec la haute disponibilité.
Contenu connexe
En savoir plus sur les Fonctionnalités et capacités de SQL Managed Instance doté d’Azure Arc