Configurer un groupe de basculement – Interface CLI
Cet article explique comment configurer la récupération d’urgence pour SQL Managed Instance activé par Azure Arc avec l’interface CLI Avant de continuer, consultez les informations et les prérequis dans SQL Managed Instance activé par Azure Arc - récupération d’urgence.
Prérequis
Les conditions préalables suivantes doivent être remplies avant de configurer des groupes de basculement entre deux instances de SQL Managed Instance activé par Azure Arc :
- Un contrôleur de données Azure Arc et une instance SQL Managed Instance avec Azure Arc configurés sur le site principal avec
--license-typeen tant queBasePriceouLicenseIncluded. - Un contrôleur de données Azure Arc et une instance SQL Managed Instance avec Azure Arc configurés sur le site secondaire avec une configuration identique au site principal en termes de :
- UC
- Mémoire
- Stockage
- Niveau de service
- Classement
- Autres paramètres de l’instance
- L’instance du site secondaire nécessite
--license-typecommeDisasterRecovery. Cette instance doit être nouvelle, sans aucun objet utilisateur.
Remarque
- Il est important de spécifier le
--license-typependant la création de l’instance managée. Cela permet à l’instance de récupération d’urgence d’être amorcée à partir de l’instance principale dans le centre de données principal. La mise à jour de cette propriété après le déploiement n’aura pas le même effet.
Processus de déploiement
Pour configurer un groupe de basculement Azure entre deux instances, procédez comme suit :
- Créer une ressource personnalisée pour le groupe de disponibilité distribué sur le site principal
- Créer une ressource personnalisée pour le groupe de disponibilité distribué sur le site secondaire
- Copier les données binaires des certificats de mise en miroir
- Configurez le groupe de disponibilité distribué entre les sites principaux et secondaires soit en mode
syncouasync
L’illustration suivante montre un groupe de disponibilité distribué correctement configuré :
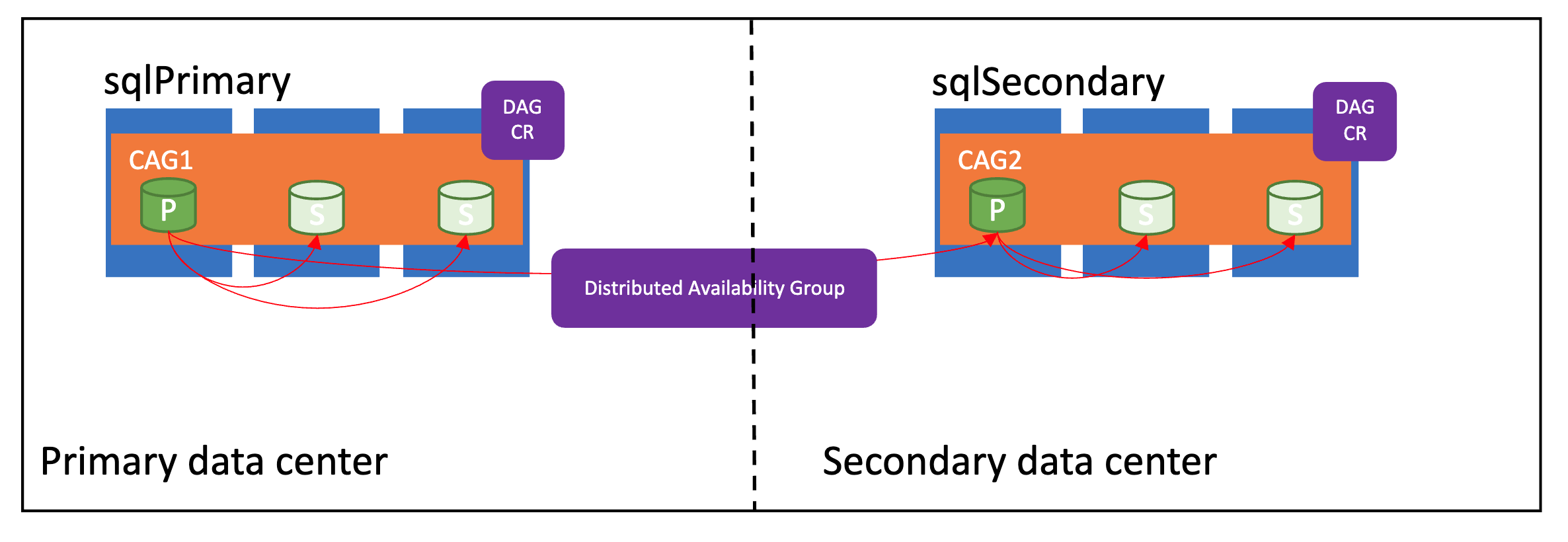
Modes de synchronisation
Les groupes de basculement dans les services de données Azure Arc prennent en charge deux modes de synchronisation : sync et async. Le mode de synchronisation affecte directement la synchronisation des données entre les instances et potentiellement les performances sur l’instance gérée principale.
Si le site principal et le site secondaire se trouvent à quelques kilomètres l’un de l’autre, utilisez le mode sync. Sinon, utilisez le mode async pour éviter tout impact de performances sur le site principal.
Configurer le groupe de basculement Azure - mode direct
Suivez les étapes ci-dessous si les services de données Azure Arc sont déployés en mode connecté directly.
Une fois les conditions préalables remplies, exécutez la commande ci-dessous pour configurer le groupe de basculement Azure entre les deux instances :
az sql instance-failover-group-arc create --name <name of failover group> --mi <primary SQL MI> --partner-mi <Partner MI> --resource-group <name of RG> --partner-resource-group <name of partner MI RG>
Exemple :
az sql instance-failover-group-arc create --name sql-fog --mi sql1 --partner-mi sql2 --resource-group rg-name --partner-resource-group rg-name
La commande ci-dessus :
- Crée les ressources personnalisées requises sur le site principal et le site secondaire
- Copie les certificats de mise en miroir et configure le groupe de basculement entre les instances
Configurer le groupe de basculement Azure - mode indirect
Suivez les étapes ci-dessous si les services de données Azure Arc sont déployés en mode connecté indirectly.
Provisionnez l’instance gérée sur le site principal.
az sql mi-arc create --name <primaryinstance> --tier bc --replicas 3 --k8s-namespace <namespace> --use-k8sBasculez sur le contexte du cluster secondaire en exécutant
kubectl config use-context <secondarycluster>et en provisionnant l’instance managée dans le site secondaire prévu pour l’instance de reprise d’activité. À ce stade, les bases de données système ne font pas partie du groupe de disponibilité contenu.Remarque
Il est important de spécifier
--license-type DisasterRecoverypendant l’instance managée. Cela permet à l’instance de récupération d’urgence d’être amorcée à partir de l’instance principale dans le centre de données principal. La mise à jour de cette propriété après le déploiement n’aura pas le même effet.az sql mi-arc create --name <secondaryinstance> --tier bc --replicas 3 --license-type DisasterRecovery --k8s-namespace <namespace> --use-k8sCertificats de mise en miroir – les données binaires contenues dans la propriété Certificat de mise en miroir de l'instance gérée sont nécessaires à la création du groupe de basculement d'instance CR (ressource personnalisée).
Vous pouvez le faire de différentes manières :
(a) Si vous utilisez l’interface CLI
az, générez d’abord le fichier de certificat de mise en miroir, puis pointez vers ce fichier pour la configuration du groupe de basculement d’instance afin que les données binaires soient lues dans le fichier et copiées dans la ressource personnalisée. Les fichiers de certificat ne sont pas nécessaires après la création du groupe de basculement.(b) Si vous utilisez
kubectl, copiez et collez directement les données binaires du CR d'instance géré dans le fichier yaml qui sera utilisé pour créer le groupe de basculement d'instance.Si vous utilisez (a) ci-dessus :
Créez le fichier de certificat de mise en miroir pour l’instance principale :
az sql mi-arc get-mirroring-cert --name <primaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sExemple :
az sql mi-arc get-mirroring-cert --name sqlprimary --cert-file $HOME/sqlcerts/sqlprimary.pem --k8s-namespace my-namespace --use-k8sConnectez-vous au cluster secondaire et créez le fichier de certificat de mise en miroir pour l’instance secondaire :
az sql mi-arc get-mirroring-cert --name <secondaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sExemple :
az sql mi-arc get-mirroring-cert --name sqlsecondary --cert-file $HOME/sqlcerts/sqlsecondary.pem --k8s-namespace my-namespace --use-k8sUne fois les fichiers de certificat de mise en miroir créés, copiez le certificat de l’instance secondaire vers un chemin partagé/local sur le cluster de l’instance principale et vice versa.
Créez des groupes de basculement des ressources sur les deux sites.
Remarque
Vérifiez que les instances SQL ont des noms différents pour les sites principaux et secondaires. La valeur
shared-namedoit être identique sur les deux sites.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for primary failover group resource> --mi <local SQL managed instance name> --role primary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<secondary IP> --partner-mirroring-cert-file <secondary.pem> --k8s-namespace <namespace> --use-k8sExemple :
az sql instance-failover-group-arc create --shared-name myfog --name primarycr --mi sqlinstance1 --role primary --partner-mi sqlinstance2 --partner-mirroring-url tcp://10.20.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance2.pem --k8s-namespace my-namespace --use-k8sSur l’instance secondaire, exécutez la commande suivante pour configurer la ressource personnalisée du groupe de basculement. Le
--partner-mirroring-cert-filedans ce cas doit pointer vers un chemin contenant le fichier de certificat de mise en miroir généré à partir de l’instance principale, comme décrit dans 3(a) ci-dessus.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for secondary failover group resource> --mi <local SQL managed instance name> --role secondary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<primary IP> --partner-mirroring-cert-file <primary.pem> --k8s-namespace <namespace> --use-k8sExemple :
az sql instance-failover-group-arc create --shared-name myfog --name secondarycr --mi sqlinstance2 --role secondary --partner-mi sqlinstance1 --partner-mirroring-url tcp://10.10.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance1.pem --k8s-namespace my-namespace --use-k8s
Récupérer l’état d’intégrité du groupe de basculement Azure
Des informations sur le groupe de basculement, comme le rôle principal, le rôle secondaire et l’état d’intégrité actuel, peuvent être consultées sur la ressource personnalisée sur le site principal ou secondaire.
Exécutez la commande ci-dessous sur le site principal et/ou secondaire pour répertorier les ressources personnalisées des groupes de basculement :
kubectl get fog -n <namespace>
Décrivez la ressource personnalisée pour récupérer l’état du groupe de basculement, comme suit :
kubectl describe fog <failover group cr name> -n <namespace>
Opérations de groupe de basculement
Une fois le groupe de basculement configuré entre les instances gérées, différentes opérations de basculement peuvent être effectuées en fonction des circonstances.
Les scénarios de basculement possibles sont les suivants :
Les instances des deux sites sont dans un état sain et un basculement doit être effectué :
- effectuez un basculement manuel du site principal vers le site secondaire sans perte de données en définissant
role=secondarysur l’instance SQL MI.
- effectuez un basculement manuel du site principal vers le site secondaire sans perte de données en définissant
Le site principal n’est pas sain/inaccessible et un basculement doit être effectué :
- l’instance SQL Managed Instance principale activée par Azure Arc est hors service/non saine/inaccessible
- l’instance SQL Managed Instance secondaire activée par Azure Arc doit être promue par force vers le serveur principal avec une perte de données potentielle
- lorsque l’instance SQL Managed Instance principale d’origine activée par Azure Arc revient en ligne, elle signale un rôle
Primaryet un état non sain et doit être forcée dans un rôlesecondarypour rejoindre le groupe de basculement et que les données puissent être synchronisées.
Basculement manuel (sans perte de données)
Utilisez le groupe de commande az sql instance-failover-group-arc update ... pour lancer un basculement du site principal vers le site secondaire. Toutes les transactions en attente sur l’instance géoprimaire sont répliquées sur l’instance géosecondaire avant le basculement.
Mode de connexion directe
Exécutez la commande suivante pour lancer un basculement manuel, en mode connecté direct à l’aide de l’API ARM :
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <primary instance> --role secondary --resource-group <resource group>
Exemple :
az sql instance-failover-group-arc update --name myfog --mi sqlmi1 --role secondary --resource-group myresourcegroup
Mode de connexion indirecte
Exécutez la commande suivante pour lancer un basculement manuel, en mode connecté indirect à l’aide de l’API Kubernetes :
az sql instance-failover-group-arc update --name <name of failover group resource> --role secondary --k8s-namespace <namespace> --use-k8s
Exemple :
az sql instance-failover-group-arc update --name myfog --role secondary --k8s-namespace my-namespace --use-k8s
Basculement forcé avec perte de données
Dans le cas où l’instance géoprimaire devient indisponible, les commandes suivantes peuvent être exécutées sur l’instance de reprise d’activité géosecondaire pour la promouvoir en instance principale avec un basculement forcé entraînant une perte de données potentielle.
Sur l’instance de reprise d’activé géosecondaire, exécutez la commande suivante pour la promouvoir au rôle principal, avec perte de données.
Remarque
Si --partner-sync-mode a été configuré comme sync, il doit être réinitialisé en async lorsque le site secondaire est promue site principal.
Mode de connexion directe
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <instance> --role force-primary-allow-data-loss --resource-group <resource group> --partner-sync-mode async
Exemple :
az sql instance-failover-group-arc update --name myfog --mi sqlmi2 --role force-primary-allow-data-loss --resource-group myresourcegroup --partner-sync-mode async
Mode de connexion indirecte
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-primary-allow-data-loss --partner-sync-mode async
Lorsque l'instance géo-principale devient disponible, exécutez la commande ci-dessous pour l'intégrer au groupe de basculement et synchroniser les données :
Mode de connexion directe
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <old primary instance> --role force-secondary --resource-group <resource group>
Mode de connexion indirecte
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-secondary
Si vous le souhaitez, --partner-sync-mode peut être reconfiguré en mode sync.
Opérations de post-basculement
Une fois que vous avez effectué un basculement du site principal vers le site secondaire, avec ou sans perte de données, vous devez peut-être effectuer les opérations suivantes :
- Mettre à jour la chaîne de connexion de vos applications pour se connecter à l’instance gérée SQL Arc principale nouvellement promue
- Si vous envisagez de continuer à exécuter la charge de travail de production hors du site secondaire, mettez à jour le
--license-typeversBasePriceouLicenseIncludedpour lancer la facturation pour les vCores consommés.