Tutoriel : Test de validation automatisé
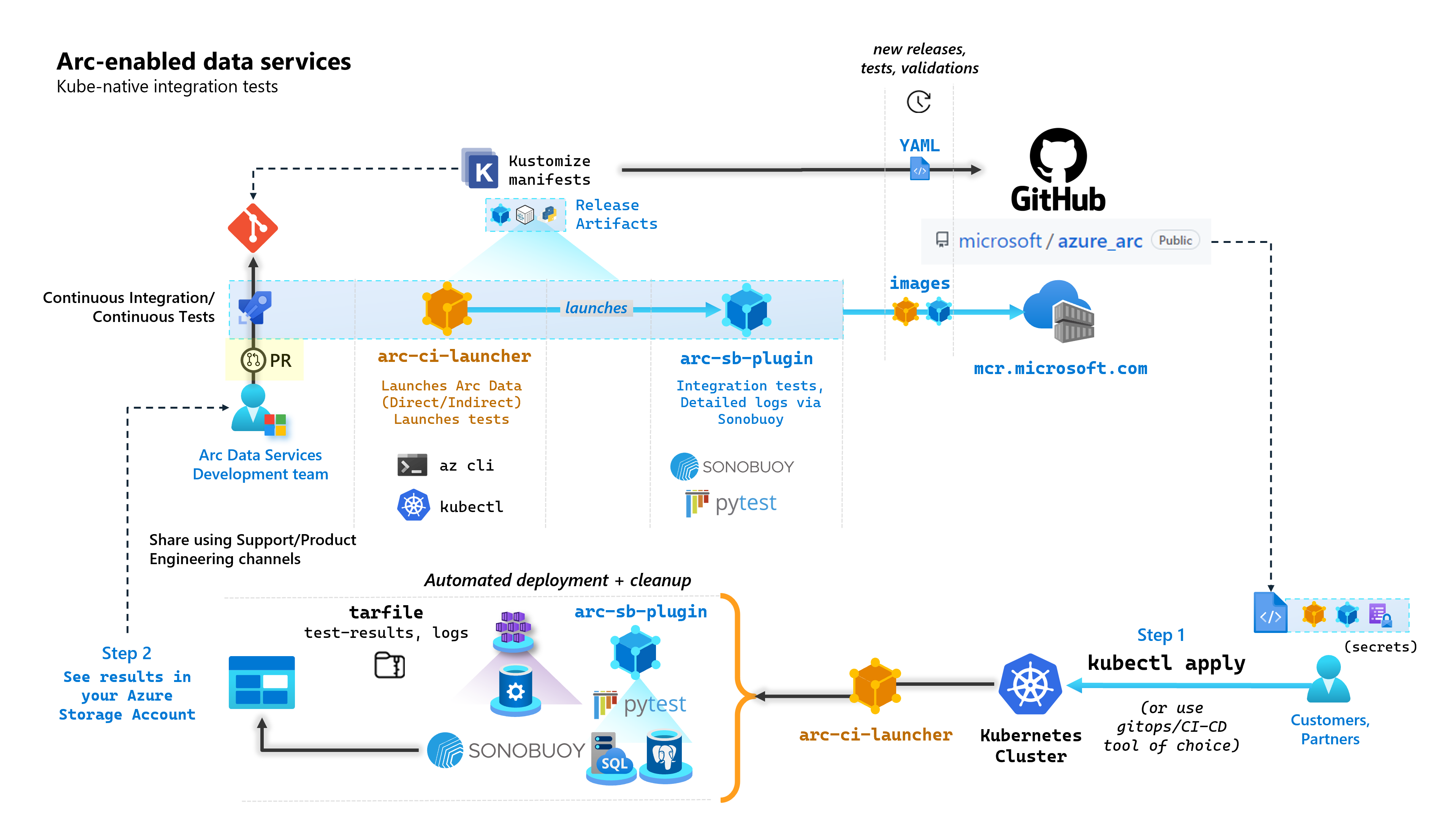
Dans le cadre de chaque validation qui génère des services de données avec Arc, Microsoft exécute des pipelines CI/CD automatisés qui effectuent des tests de bout en bout. Ces tests sont orchestrés au moyen de deux conteneurs gérés de même que le produit principal (contrôleur de données, SQL Managed Instance activé par le serveur Azure Arc et PostgreSQL Azure Arc). Ces conteneurs sont les suivants :
arc-ci-launcher: contenant des dépendances de déploiement (par exemple, des extensions CLI), ainsi que du code de déploiement de produit (à l’aide d’Azure CLI) pour les modes de connectivité directe et indirecte. Une fois Kubernetes intégré au contrôleur de données, le conteneur tire parti de Sonobuoy pour déclencher des tests d’intégration parallèles.arc-sb-plugin: plug-in Sonobuoy contenant des tests d’intégration de bout en bout basés sur Pytest, allant de simples tests d’acceptation (déploiements, suppressions), à des scénarios complexes de haute disponibilité, des tests de chaos (suppressions de ressources) etc.
Ces conteneurs de test sont mis publiquement à la disposition des clients et des partenaires pour effectuer des tests de validation des services de données avec Arc dans leurs propres clusters Kubernetes s’exécutant n’importe où, pour valider les éléments suivants :
- Distribution/versions de Kubernetes
- Distribution/versions de l’hôte
- Stockage (
StorageClass/CSI), mise en réseau (par exempleLoadBalancer, DNS) - Autre configuration Kubernetes ou infrastructure spécifique
Pour les clients qui ont l’intention d’exécuter les services de données avec Arc sur une distribution non documentée, ils doivent exécuter ces tests de validation pour être considérés comme pris en charge. En outre, les partenaires peuvent utiliser cette approche pour certifier que leur solution est conforme aux services de données compatibles Arc - voir Validation Kubernetes des services de données avec Azure Arc.
Le diagramme suivant décrit ce processus de haut niveau :
Dans ce tutoriel, vous allez apprendre à :
- Déployez
arc-ci-launcheraveckubectl - Examiner les résultats des tests de validation dans votre compte Stockage Blob Azure
Prérequis
Informations d’identification :
- Le fichier
test.env.tmplcontient les informations d’identification nécessaires, et est une combinaison des pré-requis existants pour embarquer un Cluster connecté Azure Arc et un Contrôleur de données directement connecté. La configuration de ce fichier est expliquée ci-dessous avec des exemples. - Fichier kubeconfig sur le cluster Kubernetes testé avec accès
cluster-admin(requis pour l’intégration du cluster connecté pour le moment)
- Le fichier
Outils client :
kubectlinstallé - version minimale (Majeure : « 1 », Mineure : « 21 »)- Interface de ligne de commande
git(ou alternatives basées sur l’interface utilisateur)
Préparation du manifeste Kubernetes
Le lanceur est mis à disposition dans le cadre du référentiel microsoft/azure_arc, en tant que manifeste Kustomize - Kustomize est intégré dans kubectl - donc aucun outil supplémentaire n’est nécessaire.
- Clonez le référentiel localement :
git clone https://github.com/microsoft/azure_arc.git
- Accédez à
azure_arc/arc_data_services/test/launcherpour voir la structure de dossiers suivante :
├── base <- Comon base for all Kubernetes Clusters
│ ├── configs
│ │ └── .test.env.tmpl <- To be converted into .test.env with credentials for a Kubernetes Secret
│ ├── kustomization.yaml <- Defines the generated resources as part of the launcher
│ └── launcher.yaml <- Defines the Kubernetes resources that make up the launcher
└── overlays <- Overlays for specific Kubernetes Clusters
├── aks
│ ├── configs
│ │ └── patch.json.tmpl <- To be converted into patch.json, patch for Data Controller control.json
│ └── kustomization.yaml
├── kubeadm
│ ├── configs
│ │ └── patch.json.tmpl
│ └── kustomization.yaml
└── openshift
├── configs
│ └── patch.json.tmpl
├── kustomization.yaml
└── scc.yaml
Dans ce tutoriel, nous allons nous concentrer sur les étapes pour AKS, mais la structure de superposition ci-dessus peut être étendue pour inclure des distributions Kubernetes supplémentaires.
Le manifeste prêt à être déployé représente les éléments suivants :
├── base
│ ├── configs
│ │ ├── .test.env <- Config 1: For Kubernetes secret, see sample below
│ │ └── .test.env.tmpl
│ ├── kustomization.yaml
│ └── launcher.yaml
└── overlays
└── aks
├── configs
│ ├── patch.json.tmpl
│ └── patch.json <- Config 2: For control.json patching, see sample below
└── kustomization.yam
Il y a deux fichiers qui doivent être générés pour localiser le lanceur à exécuter au sein d’un environnement spécifique. Chacun de ces fichiers peut être généré en collant et en remplissant chacun des fichiers de modèle (*.tmpl) ci-dessus :
.test.env: remplir à partir de.test.env.tmplpatch.json: remplir à partir depatch.json.tmpl
Conseil
Le .test.env est un ensemble unique de variables d’environnement qui détermine le comportement du lanceur. Générez-le avec soin pour un environnement donné pour garantir la reproductibilité du comportement du lanceur.
Config 1 : .test.env
Un exemple complet du fichier .test.env, généré sur la base de .test.env.tmpl, est partagé avec un commentaire inline.
Important
La syntaxe export VAR="value" ci-dessous n’est pas destinée à être exécutée localement pour approvisionner des variables d’environnement de votre machine ; elle est présente pour le lanceur. Le lanceur monte ce fichier .test.envtel quel en tant que secret Kubernetes à l’aide de secretGenerator de Kustomize (Kustomize prend un fichier, encode en base64 le contenu entier du fichier et le transforme en un secret Kubernetes). Lors de l’initialisation, le lanceur exécute la commande bash source, qui importe les variables d’environnement à partir du fichier .test.env telles quelles dans l’environnement du lanceur.
En d’autres termes, après avoir copié-collé .test.env.tmpl et l’avoir modifié pour créer .test.env, le fichier généré devrait ressembler à l’exemple ci-dessous. Le processus de remplissage du fichier .test.env est identique entre les systèmes d’exploitation et les terminaux.
Conseil
Il existe quelques variables d’environnement qui nécessitent une explication supplémentaire pour la clarté de la reproductibilité. Celles-ci seront commentées avec see detailed explanation below [X].
Conseil
Notez que l’exemple .test.env ci-dessous est destiné au mode direct. Certaines de ces variables, comme ARC_DATASERVICES_EXTENSION_VERSION_TAG, ne s’appliquent pas au mode indirect. Pour simplifier, il est préférable de configurer le fichier .test.env avec les variables de mode direct à l’esprit, la commutation de CONNECTIVITY_MODE=indirect fera en sorte que le lanceur ignore les paramètres spécifiques du mode direct et utilise un sous-ensemble de la liste.
En d’autres termes, la planification du mode direct nous permet de satisfaire les variables du mode indirect.
Exemple terminé de .test.env :
# ======================================
# Arc Data Services deployment version =
# ======================================
# Controller deployment mode: direct, indirect
# For 'direct', the launcher will also onboard the Kubernetes Cluster to Azure Arc
# For 'indirect', the launcher will skip Azure Arc and extension onboarding, and proceed directly to Data Controller deployment - see `patch.json` file
export CONNECTIVITY_MODE="direct"
# The launcher supports deployment of both GA/pre-GA trains - see detailed explanation below [1]
export ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN="stable"
export ARC_DATASERVICES_EXTENSION_VERSION_TAG="1.11.0"
# Image version
export DOCKER_IMAGE_POLICY="Always"
export DOCKER_REGISTRY="mcr.microsoft.com"
export DOCKER_REPOSITORY="arcdata"
export DOCKER_TAG="v1.11.0_2022-09-13"
# "arcdata" Azure CLI extension version override - see detailed explanation below [2]
export ARC_DATASERVICES_WHL_OVERRIDE=""
# ================
# ARM parameters =
# ================
# Custom Location Resource Provider Azure AD Object ID - this is a single, unique value per Azure AD tenant - see detailed explanation below [3]
export CUSTOM_LOCATION_OID="..."
# A pre-rexisting Resource Group is used if found with the same name. Otherwise, launcher will attempt to create a Resource Group
# with the name specified, using the Service Principal specified below (which will require `Owner/Contributor` at the Subscription level to work)
export LOCATION="eastus"
export RESOURCE_GROUP_NAME="..."
# A Service Principal with "sufficient" privileges - see detailed explanation below [4]
export SPN_CLIENT_ID="..."
export SPN_CLIENT_SECRET="..."
export SPN_TENANT_ID="..."
export SUBSCRIPTION_ID="..."
# Optional: certain integration tests test upload to Log Analytics workspace:
# https://learn.microsoft.com/azure/azure-arc/data/upload-logs
export WORKSPACE_ID="..."
export WORKSPACE_SHARED_KEY="..."
# ====================================
# Data Controller deployment profile =
# ====================================
# Samples for AKS
# To see full list of CONTROLLER_PROFILE, run: az arcdata dc config list
export CONTROLLER_PROFILE="azure-arc-aks-default-storage"
# azure, aws, gcp, onpremises, alibaba, other
export DEPLOYMENT_INFRASTRUCTURE="azure"
# The StorageClass used for PVCs created during the tests
export KUBERNETES_STORAGECLASS="default"
# ==============================
# Launcher specific parameters =
# ==============================
# Log/test result upload from launcher container, via SAS URL - see detailed explanation below [5]
export LOGS_STORAGE_ACCOUNT="<your-storage-account>"
export LOGS_STORAGE_ACCOUNT_SAS="?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=..."
export LOGS_STORAGE_CONTAINER="arc-ci-launcher-1662513182"
# Test behavior parameters
# The test suites to execute - space seperated array,
# Use these default values that run short smoke tests, further elaborate test suites will be added in upcoming releases
export SQL_HA_TEST_REPLICA_COUNT="3"
export TESTS_DIRECT="direct-crud direct-hydration controldb"
export TESTS_INDIRECT="billing controldb kube-rbac"
export TEST_REPEAT_COUNT="1"
export TEST_TYPE="ci"
# Control launcher behavior by setting to '1':
#
# - SKIP_PRECLEAN: Skips initial cleanup
# - SKIP_SETUP: Skips Arc Data deployment
# - SKIP_TEST: Skips sonobuoy tests
# - SKIP_POSTCLEAN: Skips final cleanup
# - SKIP_UPLOAD: Skips log upload
#
# See detailed explanation below [6]
export SKIP_PRECLEAN="0"
export SKIP_SETUP="0"
export SKIP_TEST="0"
export SKIP_POSTCLEAN="0"
export SKIP_UPLOAD="0"
Important
Si vous effectuez la génération de fichiers de configuration sur une machine Windows, vous devez convertir la séquence de fin de ligne de CRLF (Windows) en LF (Linux), car arc-ci-launcher s’exécute en tant que conteneur Linux. Laisser la fin de ligne comme CRLF peut provoquer une erreur au démarrage du conteneur arc-ci-launcher, comme : /launcher/config/.test.env: $'\r': command not found Par exemple, effectuez la modification en utilisant le VSCode (en bas à droite de la fenêtre) :

Explication détaillée de certaines variables
1. ARC_DATASERVICES_EXTENSION_* - Version d’extension et train de mise en production
Obligatoire : requis pour les déploiements en mode
direct.
Le lanceur peut déployer à la fois des versions de disponibilité générale et de pré-disponibilité générale.
La version d’extension pour le mappage de train de mise en production (ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN) s’obtient ici :
- Disponibilité générale :
stable- Journal des versions - Pré-disponibilité générale :
preview- Tests des préversions
2. ARC_DATASERVICES_WHL_OVERRIDE - URL de téléchargement de la version précédente d’Azure CLI
Facultatif : laissez cette valeur vide dans
.test.envpour utiliser la valeur par défaut pré-empaquetée.
L’image de lanceur est pré-empaquetée avec la dernière version de l’interface CLI arcdata au moment de chaque publication d’image conteneur. Cependant, pour travailler avec des versions plus anciennes et effectuer des tests de mise à niveau, il peut être nécessaire de fournir au lanceur un lien de téléchargement URL Blob Azure CLI, pour remplacer la version pré-empaquetée ; par exemple, pour demander au lanceur d’installer la version 1.4.3, indiquez :
export ARC_DATASERVICES_WHL_OVERRIDE="https://azurearcdatacli.blob.core.windows.net/cli-extensions/arcdata-1.4.3-py2.py3-none-any.whl"
La version CLI du mappage d’URL Blob est disponible ici.
3. CUSTOM_LOCATION_OID - ID d’objet d’emplacements personnalisés à partir de votre locataire Microsoft Entra spécifique
Obligatoire : obligatoire pour la création de l’emplacement personnalisé du cluster connecté.
Les étapes suivantes proviennent d’Activer les emplacements personnalisés sur votre cluster pour récupérer l’identifiant unique de l’objet d’emplacement personnalisé pour votre locataire Microsoft Entra.
Il existe deux approches pour obtenir le CUSTOM_LOCATION_OID pour votre locataire Microsoft Entra.
Via Azure CLI :
az ad sp show --id bc313c14-388c-4e7d-a58e-70017303ee3b --query objectId -o tsv # 51dfe1e8-70c6-4de... <--- This is for Microsoft's own tenant - do not use, the value for your tenant will be different, use that instead to align with the Service Principal for launcher.
Via le portail Azure - accédez à votre panneau Microsoft Entra et recherchez
Custom Locations RP: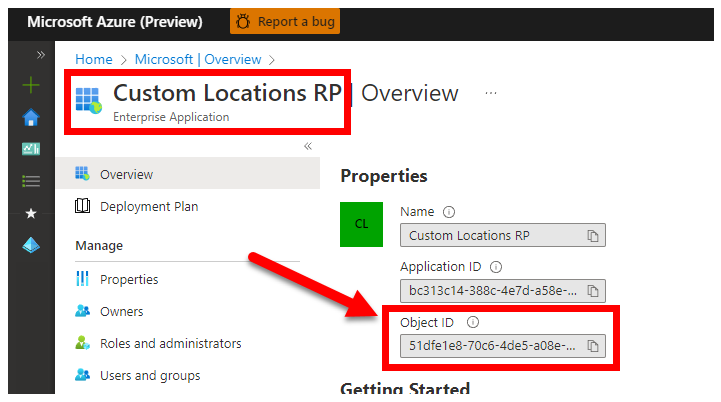
4. SPN_CLIENT_* - Informations d’identification du principal du service
Obligatoire : obligatoire pour les déploiements en mode direct.
Le lanceur se connecte à Azure à l’aide de ces informations d’identification.
Les tests de validation doivent être effectués sur un cluster Kubernetes et des abonnements Azure de non-production/de test en se concentrant sur la validation fonctionnelle de Kubernetes et de la configuration de l’infrastructure. Par conséquent, pour éviter les étapes manuelles requises pour effectuer les lancements, il est recommandé de fournir un SPN_CLIENT_ID/SECRET qui a Owner au niveau du groupe de ressources (ou de l’abonnement), car cela créera plusieurs ressources dans ce groupe de ressources, et attribuera des autorisations à ces ressources par rapport à plusieurs identités managées créées dans le cadre du déploiement (ces attributions de rôles nécessitent à leur tour que le principal du service ait Owner).
5. LOGS_STORAGE_ACCOUNT_SAS - URL SAS du compte de stockage Blob
Recommandé : laisser cette valeur vide signifie que vous n’obtiendrez pas les résultats et journaux de test.
Le lanceur a besoin d’un emplacement persistant (Stockage Blob Azure) pour charger les résultats, car Kubernetes ne permet pas (encore) de copier des fichiers à partir de pods arrêtés/complétés - voir ici. Le lanceur réussit à se connecter à Stockage Blob Azure à l’aide d’une URL SAS à portée de compte (par opposition à une portée de conteneur ou blob), une URL signée avec une définition d’accès limitée dans le temps (voir Accorder un accès limité aux ressources du Stockage Azure à l’aide des signatures d’accès partagé (SAP)), afin de :
- Créer un conteneur de stockage dans le compte de stockage pré-existant (
LOGS_STORAGE_ACCOUNT), s’il n’existe pas (nom basé surLOGS_STORAGE_CONTAINER) - Créer des objets blob nommés de manière unique (fichiers tar de journal de test)
Les étapes proviennent de l’article Accorder un accès limité aux ressources du Stockage Azure à l’aide des signatures d’accès partagé (SAS).
Conseil
Les URL SAP sont différentes de la clé de compte de stockage ; une URL SAP est mise en forme comme suit.
?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=...
Il existe plusieurs approches pour générer une URL SAP. Cet exemple montre le portail :
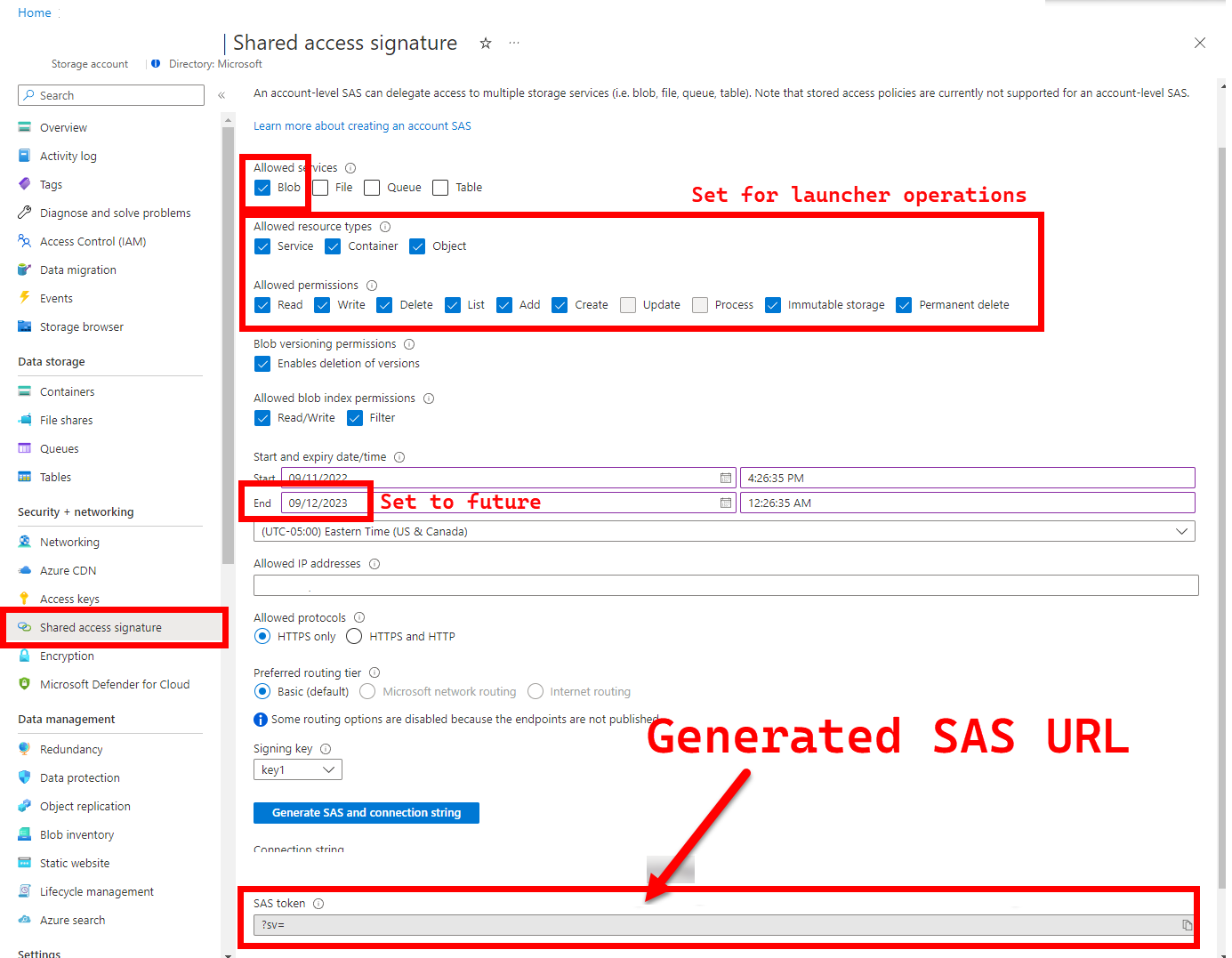
Pour utiliser Azure CLI à la place, consultez az storage account generate-sas
6. SKIP_* - Contrôler le comportement du lanceur en ignorant certaines étapes
Facultatif : laissez vide dans
.test.envpour exécuter toutes les étapes (équivalentes à0ou vides)
Le lanceur expose des variables SKIP_* pour exécuter et ignorer des étapes spécifiques, par exemple, pour effectuer une exécution « nettoyage uniquement ».
Bien que le lanceur soit conçu pour faire le ménage au début et à la fin de chaque exécution, il est possible que des échecs de lancement et/ou de test laissent des résidus de ressources derrière eux. Pour exécuter le lanceur en mode « nettoyage uniquement », définissez les variables suivantes dans .test.env :
export SKIP_PRECLEAN="0" # Run cleanup
export SKIP_SETUP="1" # Do not setup Arc-enabled Data Services
export SKIP_TEST="1" # Do not run integration tests
export SKIP_POSTCLEAN="1" # POSTCLEAN is identical to PRECLEAN, although idempotent, not needed here
export SKIP_UPLOAD="1" # Do not upload logs from this run
Les paramètres ci-dessus indiquent au lanceur de nettoyer toutes les ressources Arc et Arc Data Services, et de ne pas déployer/tester/charger les journaux.
Config 2 : patch.json
Un exemple complet du fichier patch.json, généré sur la base de patch.json.tmpl, est partagé ci-dessous :
Notez que le
spec.docker.registry, repository, imageTagdoit être identique aux valeurs dans.test.envci-dessus
Exemple terminé de patch.json :
{
"patch": [
{
"op": "add",
"path": "spec.docker",
"value": {
"registry": "mcr.microsoft.com",
"repository": "arcdata",
"imageTag": "v1.11.0_2022-09-13",
"imagePullPolicy": "Always"
}
},
{
"op": "add",
"path": "spec.storage.data.className",
"value": "default"
},
{
"op": "add",
"path": "spec.storage.logs.className",
"value": "default"
}
]
}
Déploiement du lanceur
Il est recommandé de déployer le lanceur dans un cluster non-production/de test, car il effectue des actions destructrices sur Arc et d’autres ressources Kubernetes utilisées.
Spécification imageTag
Le lanceur est défini dans le manifeste Kubernetes comme un Job, ce qui nécessite d’indiquer à Kubernetes où trouver l’image du lanceur. Vous définissez cela dans base/kustomization.yaml :
images:
- name: arc-ci-launcher
newName: mcr.microsoft.com/arcdata/arc-ci-launcher
newTag: v1.11.0_2022-09-13
Conseil
Pour récapituler, à ce stade - il y a 3 endroits que nous avons spécifiés imageTag, pour plus de clarté, voici une explication des différentes utilisations de chacun. En règle générale, lors du test d’une version donnée, les 3 valeurs sont identiques (alignées sur une version donnée) :
| # | Nom de fichier | Nom de la variable | Pourquoi ? | Utilisé par ? |
|---|---|---|---|---|
| 1 | .test.env |
DOCKER_TAG |
Approvisionnement de l’image de démarrage dans le cadre de l’installation de l’extension | az k8s-extension create dans le lanceur |
| 2 | patch.json |
value.imageTag |
Approvisionnement de l’image du contrôleur de données | az arcdata dc create dans le lanceur |
| 3 | kustomization.yaml |
images.newTag |
Approvisionnement de l’image du lanceur | kubectl apply sur le lanceur |
kubectl apply
Pour vérifier que le manifeste a été correctement configuré, essayez la validation côté client avec --dry-run=client, qui imprime les ressources Kubernetes à créer pour le lanceur :
kubectl apply -k arc_data_services/test/launcher/overlays/aks --dry-run=client
# namespace/arc-ci-launcher created (dry run)
# serviceaccount/arc-ci-launcher created (dry run)
# clusterrolebinding.rbac.authorization.k8s.io/arc-ci-launcher created (dry run)
# secret/test-env-fdgfm8gtb5 created (dry run) <- Created from Config 1: `patch.json`
# configmap/control-patch-2hhhgk847m created (dry run) <- Created from Config 2: `.test.env`
# job.batch/arc-ci-launcher created (dry run)
Pour déployer le lanceur et les journaux, exécutez ce qui suit :
kubectl apply -k arc_data_services/test/launcher/overlays/aks
kubectl wait --for=condition=Ready --timeout=360s pod -l job-name=arc-ci-launcher -n arc-ci-launcher
kubectl logs job/arc-ci-launcher -n arc-ci-launcher --follow
À ce stade, le lanceur doit démarrer et vous devriez voir les éléments suivants :
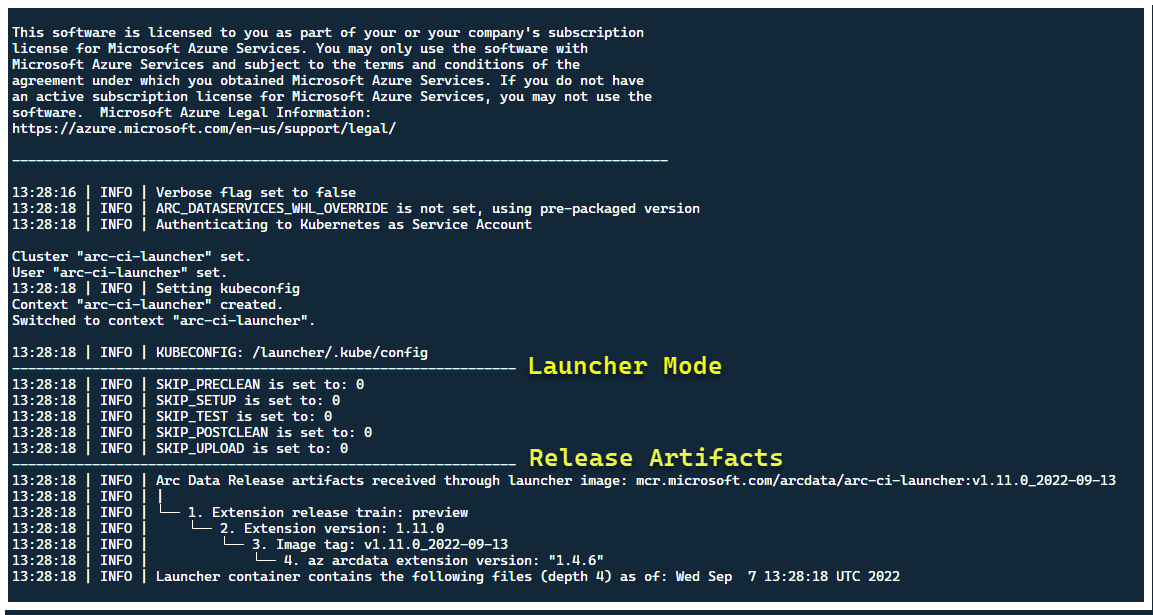
Bien qu’il soit préférable de déployer le lanceur dans un cluster sans ressources Arc préexistantes, le lanceur contient une validation préliminaire pour découvrir les CRD et les ressources ARM Arc et Arc Data Services préexistants, et tente de les nettoyer au mieux (en utilisant les informations d’identification de principal de service fournies), avant de déployer la nouvelle version :
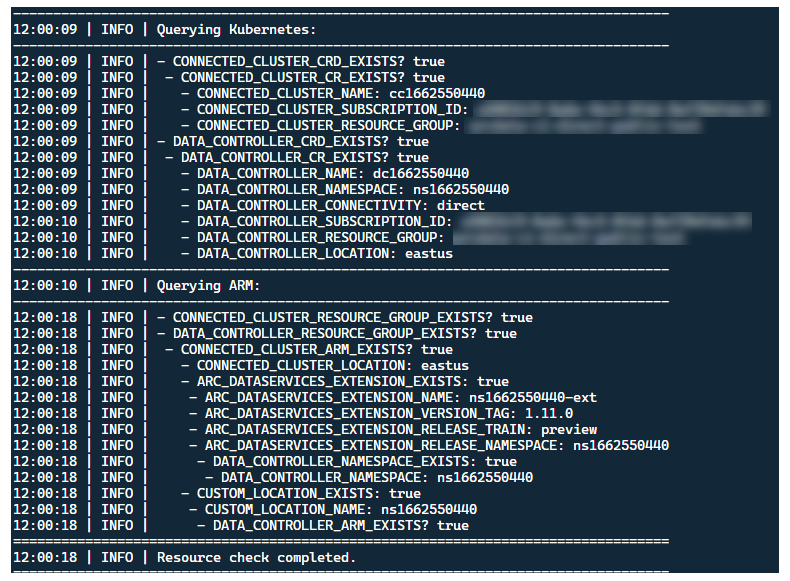
Ce même processus de découverte et de nettoyage des métadonnées est également exécuté lors de la sortie du lanceur, pour laisser le cluster aussi proche que possible de son état pré-existant avant le lancement.
Étapes effectuées par le lanceur
À un niveau élevé, le lanceur effectue la séquence d’étapes suivante :
S’authentifier auprès de l’API Kubernetes à l’aide d’un compte de service monté sur pod
S’authentifier auprès de l’API ARM à l’aide du principal de service monté par secret
Effectuer une analyse des métadonnées CRD pour découvrir les ressources personnalisées Arc et Arc Data Services existantes
Nettoyer toutes les ressources personnalisées existantes dans Kubernetes et les ressources suivantes dans Azure. En cas d’incompatibilité entre les informations d’identification dans
.test.envpar rapport aux ressources existantes dans le cluster, quitter.Générer un ensemble unique de variables d’environnement en fonction du nom du cluster Arc, du contrôleur de données et de l’emplacement/espace de noms personnalisé. Imprime les variables d’environnement, en dissimulant les valeurs sensibles (par exemple, mot de passe du principal de service, etc.)
a. Pour le mode direct : intégrez le cluster à Azure Arc, puis déployez le contrôleur.
b. Pour le mode indirect : déployer le contrôleur de données
Une fois que le contrôleur de données est
Ready, générez un ensemble de journaux Azure CLI (az arcdata dc debug) et stockez-le localement, étiquetésetup-complete, comme base de référence.Utilisez la variable d’environnement
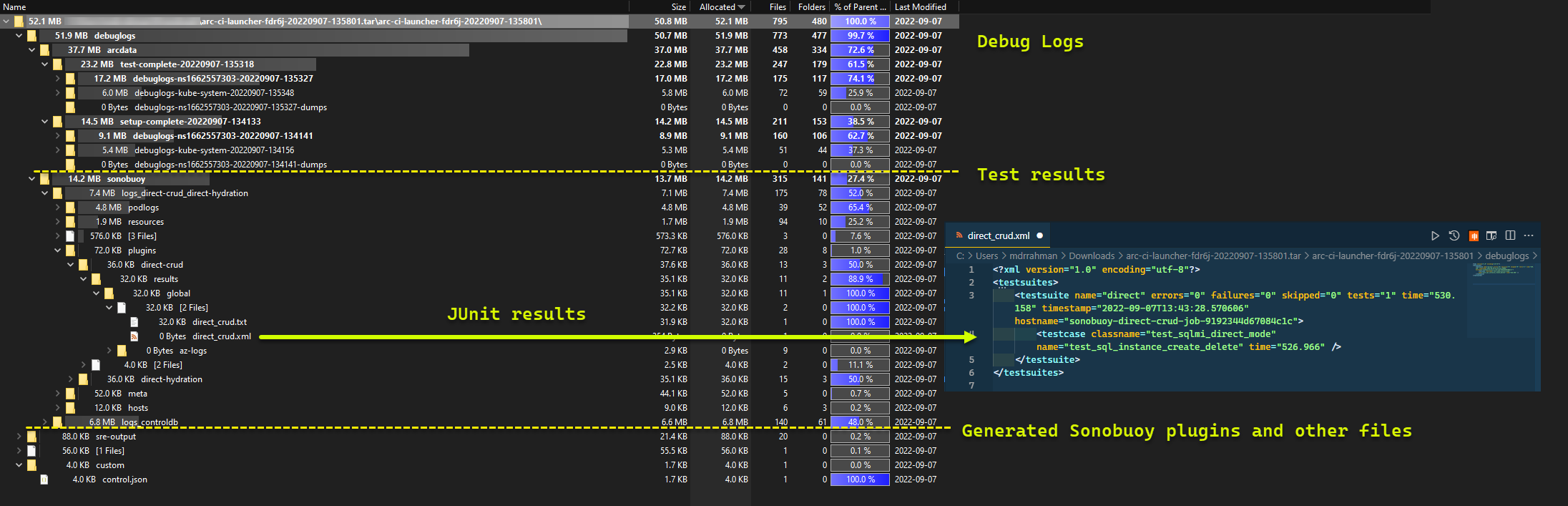
TESTS_DIRECT/INDIRECTà partir de.test.envpour lancer une série de tests Sonobuoy parallélisés en fonction d’un tableau séparé par des espaces (TESTS_(IN)DIRECT). Ces exécutions s’exécutent dans un nouvel espace de nomssonobuoy, à l’aide du podarc-sb-pluginqui contient les tests de validation Pytest.L’agrégateur Sonobuoy accumule les résultats des tests
junitet journaux par série de testsarc-sb-plugin, qui sont exportés dans le pod de lanceur.Retournez le code de sortie des tests et générez un autre ensemble de journaux de débogage - Azure CLI et
sonobuoy- stockés localement, étiquetés commetest-complete.Effectuer une analyse des métadonnées CRD, comme à l’étape 3, pour découvrir les ressources personnalisées Arc et Arc Data Services existantes. Ensuite, passez à la destruction de toutes les ressources Arc et Arc Data dans l’ordre inverse à partir du déploiement, ainsi que des CRD, Role/ClusterRoles, PV/PVC, etc.
Essayez d’utiliser le jeton SAP
LOGS_STORAGE_ACCOUNT_SASfourni pour créer un conteneur de compte de stockage nommé en fonction deLOGS_STORAGE_CONTAINERdans le compte de stockage pré-existantLOGS_STORAGE_ACCOUNT. Si le conteneur de compte de stockage existe déjà, utilisez-le. Chargez tous les résultats et journaux de test locaux dans ce conteneur de stockage en tant que tarball (voir ci-dessous).Quitter.
Tests effectués par suite de tests
Il existe environ 375 tests d’intégration uniques disponibles, répartis dans 27 suites de tests, chacune testant une fonctionnalité distincte.
| Suite n° | Nom de la suite de tests | Description du test |
|---|---|---|
| 1 | ad-connector |
Teste le déploiement et la mise à jour d’un connecteur Active Directory (connecteur AD). |
| 2 | billing |
Les tests de différents types de licences critique pour l’entreprise sont reflétés dans la table de ressources dans le contrôleur, utilisée pour le chargement de facturation. |
| 3 | ci-billing |
Similaire à billing, mais avec plus de permutations processeur/mémoire. |
| 4 | ci-sqlinstance |
Tests durables pour la création de réplicas multiples, de mises à jour, de mises à jour GP -> BC, de validation de sauvegardes et de SQL Server Agent. |
| 5 | controldb |
Tests de la base de données de contrôle : vérification du SA secret, vérification de la connexion au système, création d’un audit et vérification de l’intégrité de la version de build SQL. |
| 6 | dc-export |
Facturation du mode indirect et chargement de l’utilisation. |
| 7 | direct-crud |
Crée un instance SQL à l’aide d’appels ARM, valide à la fois dans Kubernetes et ARM. |
| 8 | direct-fog |
Crée plusieurs instances SQL ainsi qu’un groupe de basculement entre celles-ci à l’aide d’appels ARM. |
| 9 | direct-hydration |
Crée une instance SQL avec l’API Kubernetes, valide la présence dans l’ARM. |
| 10 | direct-upload |
Validation du chargement de la facturation en mode direct |
| 11 | kube-rbac |
Garantit que les autorisations de compte de service Kubernetes pour Arc Data Services correspondent aux attentes en matière de privilèges minimum. |
| 12 | nonroot |
Garantit que les conteneurs s’exécutent en tant qu’utilisateur non racine |
| 13 | postgres |
Effectue divers tests de création, de mise à l’échelle et de sauvegarde/restauration de Postgres. |
| 14 | release-sanitychecks |
Vérifie l’intégrité des versions mensuelles, telles que les versions de build SQL Server. |
| 15 | sqlinstance |
Version plus courte de ci-sqlinstance, pour des validations rapides. |
| 16 | sqlinstance-ad |
Teste la création d’instances SQL avec le connecteur Active Directory. |
| 17 | sqlinstance-credentialrotation |
Teste la rotation automatisée des informations d’identification pour l’usage général et l’usage critique pour l’entreprise. |
| 18 | sqlinstance-ha |
Divers tests de contrainte de haute disponibilité, y compris des redémarrages de pods, des basculements forcés et des suspensions. |
| 19 | sqlinstance-tde |
Divers tests TDE (Transparent Data Encryption). |
| 20 | telemetry-elasticsearch |
Valide l’ingestion de journal dans Elasticsearch. |
| 21 | telemetry-grafana |
Valide que Grafana est accessible. |
| 22 | telemetry-influxdb |
Valide l’ingestion de métriques dans InfluxDB. |
| 23 | telemetry-kafka |
Divers tests pour Kafka à l’aide de SSL, configuration simple/multi-répartiteur. |
| 24 | telemetry-monitorstack |
Tests les composants d’analyse, tels que Fluentbit et Collectd sont fonctionnels. |
| 25 | telemetry-telemetryrouter |
Teste Open Telemetry. |
| 26 | telemetry-webhook |
Teste les Webhooks Data Services avec des appels valides et non valides. |
| 27 | upgrade-arcdata |
Met à niveau une suite complète d’instances SQL (GP, réplica BC 2, réplica BC 3, avec Active Directory) et met à niveau la version du mois précédent vers la version la plus récente. |
Par exemple, pour sqlinstance-ha, les tests suivants sont effectués :
test_critical_configmaps_present: garantit que les ConfigMaps et les champs pertinents sont présents pour une instance SQL.test_suspended_system_dbs_auto_heal_by_orchestrator: garantit quemasteretmsdbsont suspendus par un moyen (dans ce cas, utilisateur). La maintenance d’Orchestrator réconcilie le rétablissement automatique.test_suspended_user_db_does_not_auto_heal_by_orchestrator: garantit que si une base de données utilisateur est délibérément suspendue par l’utilisateur, la maintenance d’Orchestrator ne réconcilie pas le rétablissement automatique.test_delete_active_orchestrator_twice_and_delete_primary_pod: supprime le pod d’orchestrateur plusieurs fois, suivi du réplica principal et vérifie que tous les réplicas sont synchronisés. Les attentes de temps de basculement pour 2 réplica sont assouplies.test_delete_primary_pod: supprime les réplica primaires et vérifie que tous les réplicas sont synchronisés. Les attentes de temps de basculement pour 2 réplica sont assouplies.test_delete_primary_and_orchestrator_pod: supprime le réplica primaire et le pod orchestrateur et vérifie que tous les réplicas sont synchronisés.test_delete_primary_and_controller: Supprime le réplica primaire et le pod du contrôleur de données, vérifie que le point de terminaison primaire est accessible et que le nouveau réplica primaire est synchronisé. Les attentes de temps de basculement pour 2 réplica sont assouplies.test_delete_one_secondary_pod: supprime le réplica secondaire et le pod du contrôleur de données et vérifie que tous les réplicas sont synchronisés.test_delete_two_secondaries_pods: supprime les réplicas secondaires et le pod du contrôleur de données et vérifie que tous les réplicas sont synchronisés.test_delete_controller_orchestrator_secondary_replica_pods:test_failaway: force le basculement du groupe de disponibilité en dehors du primaire actuel, garantit que le nouveau groupe de disponibilité n’est pas le même que l’ancien. Vérifie que tous les réplicas sont synchronisés.test_update_while_rebooting_all_non_primary_replicas: teste les mises à jour pilotées par le contrôleur sont résistantes avec des tentatives en dépit de diverses circonstances turbulentes.
Notes
Certains tests peuvent nécessiter du matériel spécifique, comme l’accès privilégié aux contrôleurs de domaine pour les tests ad pour la création de compte et d’entrée DNS, qui peuvent ne pas être disponibles dans tous les environnements qui cherchent à utiliser arc-ci-launcher.
Examen des résultats des tests
Un exemple de conteneur de stockage et de fichier chargé par le lanceur :
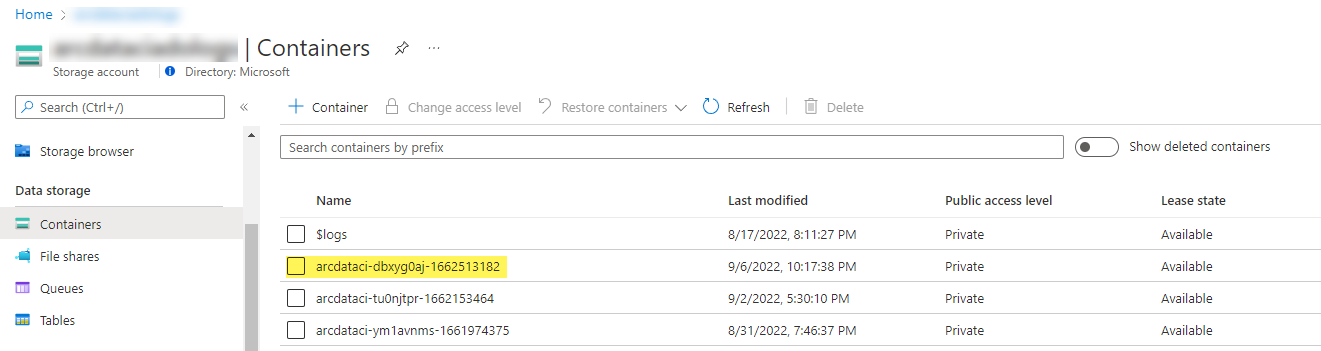
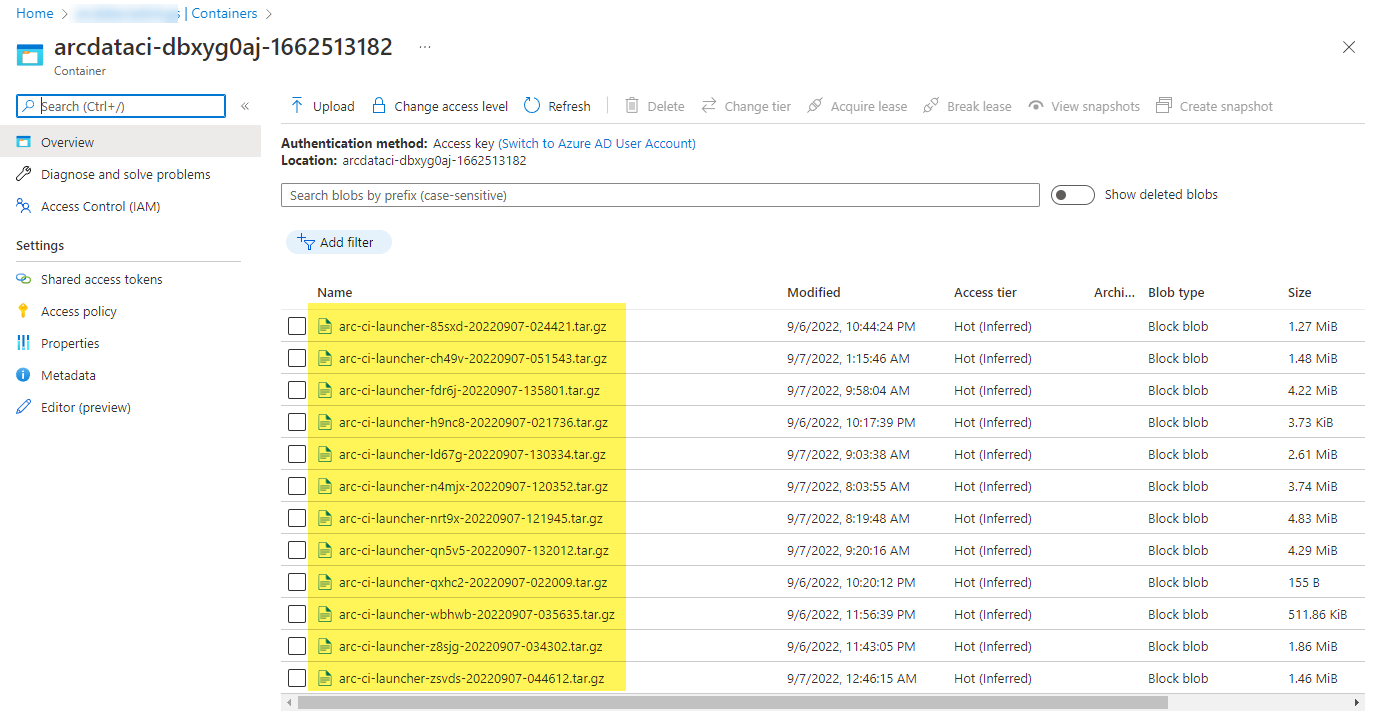
Et les résultats des tests générés à partir de l’exécution :
Nettoyer les ressources
Pour supprimer le lanceur, exécutez :
kubectl delete -k arc_data_services/test/launcher/overlays/aks
Cela nettoie les manifestes de ressources déployés dans le cadre du lanceur.