Déploiement et test des charges de travail stratégiques sur Azure
Le déploiement et le test de l’environnement critique de mission constituent un élément crucial de l’architecture de référence globale. Les empreintes d’application individuelles sont déployées à l’aide d’une infrastructure en tant que code à partir d’un référentiel de code source. Les mises à jour de l’infrastructure, puis de l’application, devraient être déployées sans temps d’arrêt de l’application. Un pipeline d’intégration continue de DevOps est recommandé pour récupérer le code source à partir du référentiel et déployer les empreintes individuelles dans Azure.
Le déploiement et les mises à jour sont le processus central dans l’architecture. Les mises à jour liées à l’infrastructure et aux applications doivent être déployées sur des tampons entièrement indépendants. Seuls les composants d’infrastructure globaux de l’architecture sont partagés entre les empreintes. Les empreintes existantes dans l’infrastructure ne sont pas touchées. Les mises à jour de l'infrastructure sont déployées sur ces nouveaux timbres De même, les nouvelles versions d’application sont déployées sur ces nouveaux tampons.
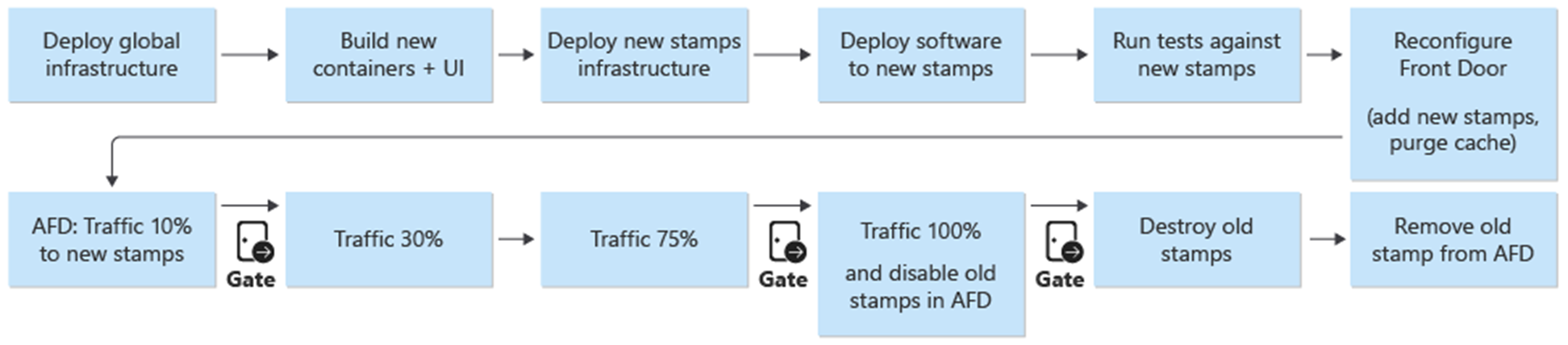
Les nouveaux tampons sont ajoutés à Azure Front Door. Le trafic est progressivement déplacé vers les nouveaux timbres. Lorsque le trafic est servi à partir des nouveaux timbres sans problème, les timbres précédents sont supprimés.
Les tests de pénétration, de chaos et de contrainte sont recommandés pour l’environnement déployé. Le test proactif de l’infrastructure détecte les faiblesses et le comportement de l’application déployée en cas de défaillance.
Déploiement
Le déploiement de l’infrastructure dans l’architecture de référence dépend des processus et composants suivants :
DevOps : code source à partir de GitHub et de pipelines pour l’infrastructure.
Mises à jour de temps d’arrêt zéro : les mises à jour et mises à niveau sont déployées sur l’environnement sans temps d’arrêt pour l’application déployée.
Environnements : environnements de courte durée et permanents utilisés pour l’architecture.
Ressources partagées et dédiées - Ressources Azure dédiées et partagées pour les timbres et l'infrastructure globale.
Pour plus d’informations, consultez Déploiement et test pour les charges de travail stratégiques sur Azure : Considérations relatives à la conception
Déploiement : DevOps
Les composants DevOps fournissent le référentiel de code source et les pipelines CI/CD pour le déploiement de l’infrastructure et des mises à jour. GitHub et Azure Pipelines ont été choisis comme composants.
gitHub : contient les référentiels de code source pour l’application et l’infrastructure.
Azure Pipelines : pipelines utilisés par l’architecture pour toutes les tâches de génération, de test et de mise en production.
Un composant supplémentaire dans la conception, utilisé pour le déploiement, est celui des agents de build. Les agents de build hébergés par Microsoft sont utilisés dans le cadre d’Azure Pipelines pour déployer l’infrastructure et les mises à jour. L’utilisation des agents de build hébergés par Microsoft supprime le fardeau de gestion pour que les développeurs conservent et mettent à jour l’agent de build.
Pour plus d’informations sur Azure Pipelines, consultez Qu’est-ce qu’Azure Pipelines ?.

Pour plus d’informations, consultez Déploiement et tests de charges de travail stratégiques sur Azure : Déploiements d’infrastructure en tant que code
Déploiement : Mises à jour sans temps d'arrêt
La stratégie de mise à jour sans temps d’arrêt dans l’architecture de référence est essentielle à l’application stratégique globale. La méthodologie de remplacement plutôt que de mise à niveau des empreintes garantit une nouvelle installation de l’application dans un empreinte d’infrastructure. L’architecture de référence utilise une approche bleue/verte et permet des environnements de test et de développement distincts.
Il existe deux composants principaux de l’architecture de référence :
Infrastructure - Services et ressources Azure. Déployé avec Terraform et sa configuration associée.
application : service hébergé ou application qui sert les utilisateurs. Basée sur des conteneurs Docker et des artefacts générés npm en HTML et JavaScript pour l’interface utilisateur d’application monopage (SPA).
Dans de nombreux systèmes, il existe une hypothèse selon laquelle les mises à jour d’application sont plus fréquentes que les mises à jour d’infrastructure. Par conséquent, différentes procédures de mise à jour sont développées pour chacun d’eux. Avec une infrastructure de cloud public, les modifications peuvent se produire à un rythme plus rapide. Un processus de déploiement pour les mises à jour d’application et les mises à jour d’infrastructure a été choisi. Une approche garantit que les mises à jour de l’infrastructure et des applications sont toujours synchronisées. Cette approche permet :
un processus cohérent : moins de chances d’erreurs si les mises à jour d’infrastructure et d’application sont mélangées dans une version, intentionnellement ou non.
Active le déploiement bleu/vert : chaque mise à jour est déployée à l’aide d’une migration progressive du trafic vers la nouvelle version.
Déploiement et débogage de l'application facilités - L'ensemble du cachet n'héberge jamais plusieurs versions de l'application côte à côte.
Retour en arrière simple - Le trafic peut être basculé vers les timbres qui exécutent la version précédente si des erreurs ou des problèmes sont rencontrés.
Élimination des modifications manuelles et de la dérive de configuration : chaque environnement est un nouveau déploiement.
Pour plus d’informations, consultez Déploiement et test des charges de travail stratégiques sur Azure : déploiements bleu/vert éphémères
Stratégie de branchement
La base de la stratégie de mise à jour est l’utilisation de branches dans le référentiel Git. L’architecture de référence utilise trois types de branches :
| Branche | Description |
|---|---|
feature/* et fix/* |
Points d’entrée pour toute modification. Les développeurs créent ces branches et doivent avoir un nom descriptif, comme feature/catalog-update ou fix/worker-timeout-bug. Lorsque les modifications sont prêtes à être fusionnées, un pull request (PR) sur la branche main est créé. Au moins un réviseur doit approuver toutes les pull requests. Avec des exceptions limitées, chaque modification proposée dans une demande de tirage doit s’exécuter via le pipeline de validation de bout en bout (E2E). Les développeurs doivent utiliser le pipeline E2E pour tester et déboguer les modifications apportées à un environnement complet. |
main |
La branche en constante progression et stable. Principalement utilisé pour les tests d’intégration. Les modifications sont apportées à main uniquement via des demandes de tirage. Une stratégie de branche interdit les écritures directes. Les publications nocturnes sur l’environnement integration (int) permanent sont exécutées automatiquement à partir de la branche main. La branche main est considérée comme stable. Il est raisonnable de supposer qu'à tout moment, une version peut être créée à partir de celle-ci. |
release/* |
Des branches de publication sont créées uniquement à partir de la branche main. Les branches suivent le format release/2021.7.X. Les stratégies de branche sont utilisées afin que seuls les administrateurs de dépôt soient autorisés à créer des branches release/*. Seules ces branches sont utilisées pour effectuer le déploiement dans l’environnement prod. |
Pour plus d’informations, consultez Déploiement et test des charges de travail stratégiques sur Azure : Stratégie de branchement
Correctifs logiciels
Lorsqu’un correctif logiciel est requis de manière urgente en raison d’un bogue ou d’un autre problème et ne peut pas passer par le processus de mise en production standard, un chemin d’accès au correctif logiciel est disponible. Les mises à jour et correctifs de sécurité critiques de l’expérience utilisateur qui n’ont pas été découverts lors des tests initiaux sont considérés comme des exemples valides de correctifs logiciels.
Le correctif logiciel doit être créé dans une nouvelle branche fix, puis fusionné dans main à l’aide d’une demande de tirage ordinaire. Au lieu de créer une nouvelle branche de version, le correctif logiciel est intégré (« cherry-picked ») dans une branche de version existante. Cette branche est déjà déployée dans l’environnement prod. Le pipeline CI/CD qui a déployé à l'origine la branche release avec tous les tests est exécuté à nouveau et déploie le correctif dans le cadre du pipeline.
Pour éviter des problèmes majeurs, il est important que le correctif logiciel contienne quelques validations isolées qui peuvent facilement être sélectionnées et intégrées dans la branche de publication. Si des validations isolées ne peuvent pas être sélectionnées pour intégration dans la branche de publication, cela indique que la modification ne peut pas être considérée comme un correctif logiciel. Déployez la modification en tant que nouvelle version complète. Combinez-la avec une restauration vers une ancienne version stable jusqu’à ce que la nouvelle version puisse être déployée.
Déploiement : Environnements
L’architecture de référence utilise deux types d’environnements pour l’infrastructure :
Court terme : le pipeline de validation E2E est utilisé pour déployer des environnements temporaires. Les environnements de courte durée sont utilisés pour des environnements de validation ou de débogage purs pour les développeurs. Les environnements de validation peuvent être créés à partir de la branche
feature/*, soumis à des tests, puis détruits si tous les tests ont réussi. Les environnements de débogage sont déployés de la même façon que la validation, mais ne sont pas détruits immédiatement. Ces environnements ne devraient pas exister pendant plus de quelques jours et devraient être supprimés une fois que la demande de tirage correspondante de la branche de fonctionnalité est fusionnée.Permanent - Dans les environnements permanents, il existe des versions
integration (int)etproduction (prod). Ces environnements vivent en permanence et ne sont pas détruits. Les environnements utilisent des noms de domaine fixes commeint.mission-critical.app. Dans une implémentation réelle de l’architecture de référence, un environnementstaging(préprod) doit être ajouté. L’environnementstagingest utilisé pour déployer et validerreleasebranches avec le même processus de mise à jour queprod(déploiement bleu/vert).Integration (int) : la version
intest déployée nocturnement à partir de la branchemainavec le même processus queprod. Le basculement de trafic est plus rapide que pour l’unité de publication précédente. Au lieu de basculer le trafic progressivement sur plusieurs jours, comme dansprod, le processus pourintprend quelques minutes ou heures. Ce basculement plus rapide garantit que l’environnement mis à jour est prêt le lendemain matin. Les anciennes empreintes sont automatiquement supprimées si tous les tests du pipeline réussissent.Production (prod) - La version
prodn'est déployée qu'à partir des branchesrelease/*. Le basculement de trafic utilise des étapes plus précises. Une barrière d’approbation manuelle est placée entre chaque étape. Chaque version crée de nouveaux tampons régionaux et déploie la nouvelle version de l’application sur les tampons. Les empreintes existantes ne sont pas touchées dans le processus. L’aspect le plus important à prendre en considération pour l’environnementprodest qu’il devrait être « Always-on ». Aucun temps d’arrêt planifié ou non planifié ne doit jamais se produire. La seule exception est les modifications fondamentales apportées à la couche de base de données. Une fenêtre de maintenance planifiée peut être nécessaire.
Déploiement : Ressources partagées et dédiées
Les environnements permanents (int et prod) dans l’architecture de référence ont différents types de ressources selon qu’elles sont partagées avec l’ensemble de l’infrastructure ou dédiées à un tampon individuel. Les ressources peuvent être dédiées à une version particulière et existent uniquement jusqu’à ce que l’unité de mise en production suivante prenne le relais.
Unités de publication
Une unité de publication est constitué de plusieurs empreintes régionales par version spécifique. Les timbres contiennent toutes les ressources qui ne sont pas partagées avec les autres timbres. Ces ressources sont des réseaux virtuels, un cluster Azure Kubernetes Service, Event Hubs et Azure Key Vault. Azure Cosmos DB et ACR sont configurés avec des sources de données Terraform.
Ressources partagées globalement
Toutes les ressources partagées entre les unités de mise en production sont définies dans un modèle Terraform indépendant. Ces ressources sont Front Door, Azure Cosmos DB, Container Registry (ACR) et les espaces de travail Log Analytics et d’autres ressources liées à la surveillance. Ces ressources sont déployées avant le déploiement de la première empreinte régionale d’une unité de publication. Les ressources sont référencées dans les modèles Terraform pour les tampons.
Porte d'entrée
Alors que Front Door est une ressource partagée mondialement entre les timbres, sa configuration est légèrement différente des autres ressources globales. Front Door doit être reconfiguré après le déploiement d’une nouvelle empreinte. Front Door doit être reconfiguré pour basculer progressivement le trafic vers les nouvelles empreintes.
La configuration back-end de Front Door ne peut pas être directement définie dans le modèle Terraform. La configuration est insérée avec des variables Terraform. Les valeurs de variable sont construites avant le démarrage du déploiement Terraform.
La configuration des composants individuels pour le déploiement Front Door est définie comme suit :
Interface utilisateur - L'affinité de session est configurée pour s'assurer que les utilisateurs ne basculent pas entre différentes versions de l'interface utilisateur lors d'une session unique.
Origines - Front Door est configuré avec deux types de groupes d'origines :
Groupe d’origine pour le stockage statique qui sert l’interface utilisateur. Le groupe contient les comptes de stockage de site web de toutes les unités de publication actuellement actives. Différentes pondérations peuvent être attribuées aux origines de différentes unités de publication afin de déplacer progressivement le trafic vers une unité plus récente. La même pondération doit être attribuée à chaque origine d’une unité de publication.
Groupe d’origine pour l’API, qui est hébergé sur Azure Kubernetes Service. S’il existe des unités de mise en production avec différentes versions d’API, un groupe d’origines d’API existe pour chaque unité de mise en production. Si toutes les unités de mise en production offrent la même API compatible, toutes les origines sont ajoutées au même groupe et affectées à différents poids.
règles de routage : il existe deux types de règles de routage :
Règle de routage pour l’interface utilisateur liée au groupe d’origine du stockage de l’interface utilisateur.
Règle de routage pour chaque API actuellement prise en charge par les origines. Par exemple :
/api/1.0/*et/api/2.0/*.
Si une version introduit une nouvelle version des API back-end, les modifications reflètent l’interface utilisateur déployée dans le cadre de la version. Une version spécifique de l’interface utilisateur appelle toujours une version spécifique de l’URL de l’API. Les utilisateurs pris en charge par une version de l’interface utilisateur utilisent automatiquement l’API back-end correspondante. Des règles de routage spécifiques sont nécessaires pour différentes instances de la version de l’API. Ces règles sont liées aux groupes d’origine correspondants. Si aucune nouvelle API n’a été introduite, toutes les règles de routage associées à l’API sont liées au groupe d’origine unique. Dans ce cas, il n’est pas important qu’un utilisateur soit servi à partir d’une version différente de celle de l’API.
Déploiement : processus de déploiement
Un déploiement bleu/vert est l’objectif du processus de déploiement. Une nouvelle version d’une branche release/* est déployée dans l’environnement prod. Le trafic utilisateur est progressivement déplacé vers les empreintes destinées à la nouvelle version.
Lors de la première étape du processus de déploiement d’une nouvelle version, l’infrastructure de la nouvelle unité de mise en production est déployée avec Terraform. L’exécution du pipeline de déploiement d’infrastructure a pour effet de déployer la nouvelle infrastructure à partir d’une branche de publication sélectionnée. En parallèle de l’approvisionnement de l'infrastructure, les images de conteneur sont générées ou importées et transférées dans le registre de conteneurs global partagé (ACR). Une fois les processus précédents terminés, l’application est déployée sur les tampons. Du point de vue de l’implémentation, il s’agit d’un pipeline avec plusieurs étapes dépendantes. Le même pipeline peut être réexécuté pour des déploiements de correctifs logiciels.
Une fois la nouvelle unité de mise en production déployée et validée, la nouvelle unité est ajoutée à Front Door pour recevoir le trafic utilisateur.
Un commutateur/paramètre qui fait la distinction entre les versions qui font et qui n’introduisent pas de nouvelle version d’API doit être planifié. En fonction de si la version introduit une nouvelle version d'API, un nouveau groupe source avec les backends de l'API doit être créé. Vous pouvez également ajouter de nouveaux back-ends d’API à un groupe d’origines existant. Les nouveaux comptes de stockage d’interface utilisateur sont ajoutés au groupe d’origine existant correspondant. Les pondérations pour les nouvelles origines doivent être définies en fonction du fractionnement de trafic souhaité. Une nouvelle règle de routage, comme décrit précédemment, doit être créée qui correspond au groupe d’origine approprié.
Dans le cadre de l’ajout de la nouvelle unité de publication, les pondérations des nouvelles origines doivent être définies sur le trafic utilisateur minimal souhaité. Si aucun problème n’est détecté, la quantité de trafic utilisateur doit être augmentée au nouveau groupe de sources sur une certaine période. Pour ajuster les paramètres de pondération, les mêmes étapes de déploiement doivent être réexécuter avec les valeurs souhaitées.
Désactivation d’unité de publication
Dans le cadre du pipeline de déploiement d’une unité de publication, il existe une étape de destruction qui supprime tous les empreintes une fois qu’une unité de publication n’est plus nécessaire. Tout le trafic est déplacé vers une nouvelle version de publication. Cette étape inclut la suppression des références d’unité de publication de Front Door. Cette suppression est essentielle pour activer la publication d’une nouvelle version à une date ultérieure. Front Door doit pointer vers une unité de publication unique afin d’être préparé pour la prochaine publication.
Listes de contrôle
Dans le cadre de la cadence de publication, une liste de contrôle avant et après publication doit être utilisée. L’exemple suivant est des éléments qui doivent figurer dans n’importe quelle liste de contrôle au minimum.
liste de vérification avant publication - Avant de lancer une publication, vérifiez les éléments suivants :
Vérifiez que l’état le plus récent de la branche
maina été correctement déployé dans l’environnementintet y a été testé.Mettez à jour le fichier changelog via une demande de tirage sur la branche
main.Créez une branche
release/à partir de la branchemain.
Liste de contrôle post-publication - Avant que les anciens timbres ne soient détruits et que leurs références soient supprimées de Front Door, vérifiez que :
Les clusters ne reçoivent plus de trafic entrant.
Event Hubs et d’autres files d’attente de messages ne contiennent aucun message non traité.
Déploiement : Limitations et risques de la stratégie de mise à jour
La stratégie de mise à jour décrite dans cette architecture de référence présente des limitations et des risques qui doivent être mentionnés :
Coût plus élevé : lors de la publication des mises à jour, de nombreux composants d’infrastructure sont actifs deux fois pour la période de publication.
Complexité de Front Door : le processus de mise à jour dans Front Door est complexe à implémenter et à gérer. La possibilité d’exécuter des déploiements bleus/verts effectifs avec un temps d’arrêt nul dépend de son bon fonctionnement.
Petites modifications prennent du temps : le processus de mise à jour entraîne un processus de mise en production plus long pour les petites modifications. Cette limitation peut être partiellement atténuée avec le processus de correctif logiciel décrit dans la section précédente.
Déploiement : Considérations relatives à la compatibilité des données d’application
La stratégie de mise à jour peut prendre en charge plusieurs versions d’une API et des composants de travail s’exécutant simultanément. Étant donné qu’Azure Cosmos DB est partagé entre deux versions ou plusieurs versions, il est possible que les éléments de données modifiés par une version ne correspondent pas toujours à la version de l’API ou aux workers qui les consomment. Les couches et workers d’API doivent implémenter une conception de compatibilité ascendante. Les versions antérieures de l’API ou des composants worker traitent les données insérées par une version ultérieure d’UNE API ou d’un composant Worker. Il ignore les parties qu’il ne comprend pas.
Test
L’architecture de référence contient différents tests utilisés à différentes étapes de l’implémentation de test.
Ces tests sont les suivants :
tests unitaires : ces tests valident que la logique métier de l’application fonctionne comme prévu. L’architecture de référence contient un exemple de suite de tests unitaires exécutés automatiquement avant chaque build de conteneur par Azure Pipelines. Si un test échoue, le pipeline s’arrête. La construction et le déploiement s’arrêtent. Le développeur doit résoudre le problème avant que le pipeline puisse être réexécuté.
Tests de charge - Ces tests permettent d'évaluer la capacité, l'évolutivité et les goulets d'étranglement potentiels pour une charge de travail ou une pile donnée. L’implémentation de référence contient un générateur de charge utilisateur pour créer des modèles de charge synthétique qui peuvent être utilisés pour simuler le trafic réel. Le générateur de charge peut également être utilisé indépendamment de l’implémentation de référence.
Tests de fumée - Ces tests permettent d'identifier si l'infrastructure et la charge de travail sont disponibles et agissent comme prévu. Les tests de fumée sont exécutés dans le cadre de chaque déploiement.
tests de l’interface utilisateur : ces tests valident que l’interface utilisateur a été déployée et fonctionne comme prévu. L’implémentation actuelle capture uniquement des captures d’écran de plusieurs pages après le déploiement sans test réel.
Tests d'injection de défaillance - Ces tests peuvent être automatisés ou exécutés manuellement. Le test automatisé dans l’architecture intègre Azure Chaos Studio dans le cadre des pipelines de déploiement.
Pour plus d’informations, consultez Déploiement et test des charges de travail stratégiques sur Azure : validation et test continus
Tests : infrastructures
Implémentation de référence en ligne des fonctionnalités et infrastructures de test existantes chaque fois que c’est possible.
| Cadre | Test | Description |
|---|---|---|
| NUnit | Unité | Cette infrastructure est utilisée pour le test unitaire de la partie .NET Core de l’implémentation. Azure Pipelines exécute automatiquement des tests unitaires avant les builds de conteneur. |
| JMeter avec Test de charge Azure | Load | Test de charge Azure est un service géré utilisé pour exécuter les définitions des tests de charge Apache JMeter. |
| sauterelle | Load | Locust est une infrastructure de test de charge open source écrite en Python. |
| Dramaturge | Interface utilisateur et fumée | Playwright est une bibliothèque open source Node.js pour automatiser Chromium, Firefox et WebKit avec une SEULE API. La définition du test Playwright peut également être utilisée indépendamment de l’implémentation de référence. |
| Azure Chaos Studio | Injection de défaillances | L’implémentation de référence utilise Azure Chaos Studio comme étape facultative dans le pipeline de validation E2E pour injecter des échecs pour la validation de résilience. |
Tests : tests par injection de défaillances et ingénierie du chaos
Les applications distribuées doivent être résilientes aux pannes de service et de composants. Les tests par injection de défaillances (également appelé Injection d’erreurs ou Ingénierie du chaos) relèvent de la pratique consistant à soumettre des applications et services à des contraintes et défaillances réelles.
La résilience est une propriété d’un système entier et l’injection d’erreurs permet de trouver des problèmes dans l’application. La résolution de ces problèmes permet de valider la résilience de l’application aux conditions non fiables, aux dépendances manquantes et à d’autres erreurs.
Les tests manuels et automatiques peuvent être exécutés sur l’infrastructure pour rechercher des erreurs et des problèmes dans l’implémentation.
Automatique
L’architecture de référence intègre Azure Chaos Studio pour déployer et exécuter un ensemble d’expériences Azure Chaos Studio consistant à injecter diverses erreurs au niveau de l’empreinte. Les expériences chaos peuvent être exécutées en tant que partie facultative du pipeline de déploiement E2E. Lorsque les tests sont exécutés, le test de charge facultatif est toujours exécuté en parallèle. Le test de charge est utilisé pour créer la charge sur le cluster pour valider l’effet des erreurs injectées.
Manuel
Les tests par injection de défaillances manuels doivent être effectués dans un environnement de validation E2E. Cet environnement garantit des tests représentatifs complets sans risque d’interférence à partir d’autres environnements. La plupart des défaillances générées avec les tests peuvent être observées directement dans l’affichage Métriques en temps réel d’Application Insights. Les autres échecs sont disponibles dans la vue Échecs et les tables de journal correspondantes. D’autres échecs nécessitent un débogage plus approfondi, comme l’utilisation de kubectl pour observer le comportement à l’intérieur d’Azure Kubernetes Service.
Voici deux exemples de tests par injection de défaillances effectués sur l’architecture de référence :
DNS (Domain Name Service) - injection de défaillance basée - Un cas de test qui peut simuler plusieurs problèmes. Échecs de résolution DNS en raison de l’échec d’un serveur DNS ou d’Azure DNS. Les tests DNS peuvent aider à simuler des problèmes généraux de connexion entre un client et un service, par exemple lorsque le BackgroundProcessor ne peut pas se connecter à Event Hubs.
Dans les scénarios à hôte unique, vous pouvez modifier le fichier de
hostslocal pour remplacer la résolution DNS. Dans un environnement plus grand avec plusieurs serveurs dynamiques comme AKS, un fichierhostsn’est pas réalisable. Les zones DNS privées Azure peuvent être utilisées comme alternative pour tester des scénarios de défaillance.Azure Event Hubs et Azure Cosmos DB sont deux des services Azure utilisés dans l’implémentation de référence qui peuvent être utilisés pour injecter des défaillances basées sur DNS. La résolution DNS Event Hubs peut être manipulée avec une zone DNS privé Azure liée au réseau virtuel de l’un des empreintes. Azure Cosmos DB est un service répliqué globalement avec des points de terminaison régionaux spécifiques. La manipulation des enregistrements DNS pour ces points de terminaison peut simuler un échec pour une région spécifique et tester le basculement des clients.
blocage par le pare-feu - La plupart des services Azure prennent en charge les restrictions d'accès par le pare-feu en fonction des réseaux virtuels et/ou des adresses IP. Dans l’infrastructure de référence, ces restrictions sont utilisées pour restreindre l’accès à Azure Cosmos DB ou Event Hubs. Une procédure simple consiste à supprimer des règles d’Autorisation existantes ou à ajouter des règles de Blocage . Cette procédure peut simuler des erreurs de configuration de pare-feu ou des pannes de service.
Les exemples de services suivants dans l’implémentation de référence peuvent être testés avec un test de pare-feu :
Service Résultat Key Vault Lorsque l’accès au Key Vault est bloqué, l’effet le plus direct est l’échec de génération de nouveaux pods. Le pilote CSI du Key Vault qui récupère les secrets au démarrage du pod ne peut pas effectuer ses tâches et empêche le démarrage du pod. Les messages d’erreur correspondants peuvent être observés avec kubectl describe po CatalogService-deploy-my-new-pod -n workload. Les pods existants continuent de fonctionner, bien que le même message d’erreur soit observé. Les résultats de la vérification de la mise à jour périodique des secrets génèrent le message d'erreur. Bien que non testé, l’exécution d’un déploiement ne fonctionne pas lorsque Key Vault est inaccessible. Les tâches Terraform et Azure CLI au sein de l’exécution du pipeline effectuent des requêtes à Key Vault.Hubs d'événements Lorsque l’accès à Event Hubs est bloqué, les nouveaux messages envoyés par le CatalogService et HealthService échouent. Les récupérations de messages par BackgroundProcess échouent lentement, avec une défaillance totale en quelques minutes.Azure Cosmos DB La suppression de la stratégie de pare-feu existante pour un réseau virtuel a pour effet que le service de contrôle d’intégrité commence à échouer avec un retard minime. Cette procédure simule uniquement un cas spécifique, une panne complète d’Azure Cosmos DB. La plupart des cas d’échec qui se produisent au niveau régional sont atténués automatiquement avec le basculement transparent du client vers une autre région Azure Cosmos DB. Les tests par injection de défaillance DNS décrits précédemment sont plus significatifs pour Azure Cosmos DB. Container Registry (ACR) Lorsque l’accès à ACR est bloqué, la création de nouveaux pods extraits et mis en cache précédemment sur un nœud AKS continue de fonctionner. La création fonctionne toujours grâce à l'indicateur de déploiement de K8s pullPolicy=IfNotPresent. Les nœuds ne peuvent pas créer un nouveau pod et échouent immédiatement avec des erreursErrImagePullsi le nœud ne tire pas et ne met pas en cache une image avant le bloc.kubectl describe podaffiche le message de403 Forbiddencorrespondant.Équilibreur de charge d’entrée AKS La modification des règles de trafic entrant en Refuser pour HTTP(S) (ports 80 et 443) dans le groupe de sécurité réseau (NSG) managé par AKS a pour effet que le trafic utilisateur ou de la sonde d’intégrité ne parvient pas à atteindre le cluster. Il est difficile d’identifier la cause profonde de cette défaillance dont le test simule un blocage entre le chemin réseau de Front Door et une empreinte régionale. Front Door détecte immédiatement cette défaillance et retire l’empreinte de la rotation.