Coordonnez les actions effectuées par un ensemble d’instances de collaboration dans une application distribuée en élisant l’instance responsable qui sera chargée de gérer les autres. Vous pourrez ainsi éviter les conflits entre les instances, la contention pour des ressources partagées ou des interférences inopinées avec le travail effectué par d’autres instances.
Contexte et problème
Une application cloud type a de nombreuses tâches simultanées à coordonner. Ces tâches peuvent toutes être des instances exécutant le même code et accédant aux mêmes ressources. Elles peuvent aussi travailler ensemble en parallèle pour effectuer chacune leur part d’un calcul complexe.
Si les instances de tâche s’exécutent la plupart du temps séparément, il peut aussi s’avérer nécessaire de coordonner leurs actions individuelles pour éviter les conflits, la contention pour des ressources partagées ou des interférences inopinées avec le travail effectué par d’autres instances de tâche.
Par exemple :
- Dans un système cloud qui implémente une mise à l’échelle horizontale, plusieurs instances d’une même tâche peuvent s’exécuter en même temps, chaque instance servant un utilisateur différent. Si ces instances écrivent dans une ressource partagée, il est nécessaire de coordonner leurs actions pour éviter que chaque instance remplace les modifications apportées par les autres.
- Si les tâches effectuent chacune en parallèle une partie d’un calcul complexe, les résultats doivent être agrégés une fois que toutes les tâches sont terminées.
Les instances de tâche étant toutes des homologues, il n’y a pas de responsable naturel pouvant faire office de coordinateur ou d’agrégateur.
Solution
Une instance de tâche unique doit être élue pour remplir le rôle de responsable dans le but de coordonner les actions des autres instances de tâche subordonnée. Si toutes les instances de tâche exécutent le même code, chacune est capable de jouer le rôle de responsable. Par conséquent, le processus d’élection doit être géré avec soin pour éviter que deux ou plusieurs instances prennent simultanément la position de leader.
Le mécanisme de sélection du responsable proposé par le système doit être fiable. Cette méthode doit faire face à certains événements tels que les pannes réseau ou les échecs de processus. Dans bon nombre de solutions, les instances de tâche subordonnée surveillent le responsable via une méthode de vérification des pulsations d’un certain type ou par l’interrogation. Si le responsable désigné s’arrête de manière inattendue ou si les instances de tâche subordonnée ne peuvent plus y accéder du fait d’une défaillance réseau, elles doivent élire un nouveau responsable.
Il existe plusieurs stratégies pour élire un responsable parmi différentes tâches au sein d’un environnement distribué, à savoir :
- Course à l’acquisition d’un mutex partagé et distribué. La première instance de tâche qui acquiert le mutex est le responsable. Cependant, le système doit garantir que si le responsable s’arrête ou se déconnecte du reste du système, le mutex est libéré pour permettre à une autre instance de tâche de devenir le responsable. Cette stratégie est illustrée dans l’exemple ci-dessous.
- Implémentation de l’un des algorithmes d’élection du responsable courants tels que l’algorithme du plus fort (Bully), l’algorithme de consensus Raft ou l’algorithme en anneau (Ring). Ces algorithmes considèrent que chaque candidat à l’élection possède un ID unique et qu’il peut communiquer de manière fiable avec les autres candidats.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
- Le processus d’élection d’un responsable doit être résilient face aux défaillances temporaires et permanentes.
- Une défaillance du responsable ou son indisponibilité (par exemple, suite à un échec de communication) doit pouvoir être détectée. Les exigences de rapidité de détection varient en fonction du système. Certains systèmes peuvent fonctionner sans responsable pendant un bref laps de temps, au cours duquel une défaillance temporaire pourra éventuellement être résolue. Dans d’autres cas, la défaillance du responsable doit être détectée immédiatement de façon à déclencher une nouvelle élection.
- Dans un système qui implémente une mise à l’échelle automatique horizontale, le responsable peut s’arrêter si le système diminue ses capacités et retire certaines ressources informatiques.
- L’utilisation d’un mutex partagé et distribué crée une dépendance vis-à-vis du service externe qui fournit le mutex. Le service constitue un point de défaillance unique. S’il devient inaccessible pour une raison quelconque, le système ne peut plus élire de responsable.
- L’utilisation d’un processus dédié unique comme responsable est une approche simple. Cependant, si le processus subit une défaillance, son redémarrage risque de prendre beaucoup de temps. Or, la latence qui en découle peut nuire aux performances et aux temps de réponse des autres processus si ceux-ci attendent que le responsable coordonne une opération.
- L’implémentation manuelle de l’un des algorithmes d’élection du responsable offre davantage de souplesse quand il s’agit d’ajuster et d’optimiser le code.
- Évitez de faire du responsable un goulot d’étranglement dans le système. Le rôle du responsable est de coordonner le travail lié aux tâches subordonnées. Il n’est pas nécessairement tenu de participer à ce travail proprement dit, même s’il doit être en mesure de le faire si la tâche n’est pas élue responsable.
Quand utiliser ce modèle
Utilisez ce modèle quand les tâches au sein d’une application distribuée, telle qu’une solution hébergé dans le cloud, a besoin d’une coordination minutieuse et qu’il n’existe pas de responsable naturel.
Ce modèle peut ne pas avoir d’utilité dans les cas suivants :
- Il existe un responsable naturel ou un processus dédié qui peut toujours faire office de responsable. Par exemple, il est peut-être possible d’implémenter un processus de singleton qui coordonne les instances de tâche. Si ce processus échoue ou devient instable, le système peut l’arrêter et le redémarrer.
- La coordination entre les tâches peut être accomplie en utilisant une méthode plus légère. Par exemple, si plusieurs instances de tâche ont simplement besoin d’un accès coordonné à une ressource partagée, une meilleure solution est d’utiliser le verrouillage optimiste ou pessimiste pour contrôler l’accès.
- Une solution tierce, comme Apache Zookeeper, peut être une solution plus efficace.
Conception de la charge de travail
Un architecte devrait évaluer comment le modèle d’Élection de Leader peut être utilisé dans la conception de leur charge de travail pour répondre aux objectifs et principes couverts par les piliers d’Azure Well-Architected Framework. Par exemple :
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| Les décisions relatives à la fiabilité contribuent à rendre votre charge de travail résiliente aux dysfonctionnements et à s’assurer qu’elle retrouve un état de fonctionnement optimal après une défaillance. | Ce modèle atténue l’effet des dysfonctionnements des nœuds en redirigeant de manière fiable le travail. Il implémente également la reprise via des algorithmes de consensus lorsque le leader dysfonctionne. - RE :05 Redondance - RE:07 Auto-réparation |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Exemple
L’exemple d’Élection de Leader sur GitHub montre comment utiliser un bail sur un blob de stockage Azure pour fournir un mécanisme permettant de mettre en œuvre un mutex partagé et distribué. Ce mutex peut être utilisé pour élire un leader parmi un groupe d’instances de travail disponibles. La première instance à acquérir le bail est élue leader et reste le leader jusqu’à ce qu’elle libère le bail ou ne soit pas en mesure de renouveler le bail. Les autres instances de travail peuvent continuer à surveiller le bail du blob au cas où le leader ne serait plus disponible.
Un bail d’objet blob est un verrou d’écriture exclusif sur un objet blob. Un même objet blob peut être l’objet d’un seul bail à un instant donné. Une instance de travail peut demander un bail sur un blob spécifié, et elle obtiendra le bail si aucune autre instance de travail ne détient déjà un bail sur le même blob. Sinon, la demande générera une exception.
Pour éviter qu’une instance leader défaillante ne retienne le bail indéfiniment, spécifiez une durée de vie pour le bail. Une fois arrivé à expiration, le bail deviendra disponible. Cependant, tant qu’une instance détient le bail, elle peut demander le renouvellement du bail, et elle obtiendra le bail pour une période supplémentaire. L’instance leader peut répéter ce processus continuellement si elle souhaite conserver le bail. Pour plus d’informations sur la façon de louer un objet blob, consultez Louer un objet blob (API REST).
La classe BlobDistributedMutex dans l’exemple C# ci-dessous contient la méthode RunTaskWhenMutexAcquired qui permet à une instance de travail de tenter d’acquérir un bail sur un blob spécifié. Les détails de l’objet blob (nom, conteneur et compte de stockage) sont passés au constructeur dans un objet BlobSettings au moment où l’objet BlobDistributedMutex est créé (cet objet est un struct simple qui est inclus dans l’exemple de code). Le constructeur accepte également un Task qui fait référence au code que l’instance de travail devrait exécuter si elle acquiert avec succès le bail sur le blob et est élue leader. Notez que le code qui gère les détails de bas niveau de l’acquisition du bail est implémenté dans une classe d’assistance distincte nommée BlobLeaseManager.
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
La méthode RunTaskWhenMutexAcquired dans l’exemple de code ci-dessus appelle la méthode RunTaskWhenBlobLeaseAcquired figurant dans l’exemple de code suivant pour acquérir le bail. La méthode RunTaskWhenBlobLeaseAcquired s’exécute de façon asynchrone. Si le bail est acquis avec succès, l’instance de travail est élue leader. Le but du taskToRunWhenLeaseAcquired est d’effectuer le travail qui coordonne les autres instances de travail. Si le bail n’est pas acquis, une autre instance de travail a été élue leader et l’instance de travail actuelle reste subordonnée. Notez que TryAcquireLeaseOrWait est une méthode d’assistance qui utilise l’objet BlobLeaseManager pour acquérir le bail.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
La tâche démarrée par le responsable s’exécute aussi de façon asynchrone. Pendant l’exécution de cette tâche, la méthode RunTaskWhenBlobLeaseAcquired figurant dans l’exemple de code suivant tente régulièrement de renouveler le bail. Cela aide à garantir que l’instance de travail reste leader. Dans la solution d’exemple, le délai entre les demandes de renouvellement est inférieur au temps spécifié pour la durée du bail afin d’empêcher qu’une autre instance de travail ne soit élue leader. Si le renouvellement échoue pour une raison quelconque, la tâche spécifique au leader est annulée.
Si le renouvellement du bail échoue ou si la tâche est annulée (éventuellement en raison de l’arrêt de l’instance de travail), le bail est libéré. À ce stade, cette ou une autre instance de travail peut être élue leader. L’extrait de code ci-dessous illustre cette partie du processus.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
KeepRenewingLease est une méthode d’assistance qui utilise l’objet BlobLeaseManager pour renouveler le bail. La méthode CancelAllWhenAnyCompletes annule les tâches spécifiées comme étant les deux premiers paramètres. Le diagramme suivant illustre l’utilisation de la classe BlobDistributedMutex pour élire un responsable et exécuter une tâche qui coordonne les opérations.
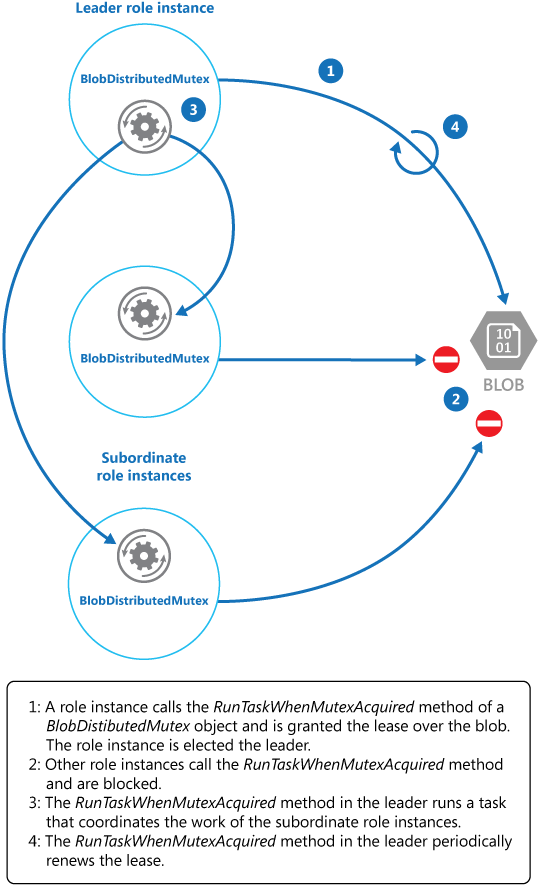
L’exemple de code suivant montre comment utiliser la classe BlobDistributedMutex au sein d’une instance de travail. Ce code acquiert un bail sur un blob nommé MyLeaderCoordinatorTask dans le conteneur de bail du stockage de blobs Azure, et spécifie que le code défini dans la méthode MyLeaderCoordinatorTask doit s’exécuter si l’instance de travail est élue leader.
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
Notez les points suivants à propos de l’exemple de solution :
- L’objet blob est potentiellement un point de défaillance unique. Si le service de blob devient indisponible ou inaccessible, le leader ne pourra pas renouveler le bail et aucune autre instance de travail ne pourra acquérir le bail. Dans ce cas, aucune instance de travail ne pourra agir en tant que leader. Cependant, le service BLOB étant résilient par sa conception, sa défaillance complète est considérée comme très improbable.
- Si la tâche effectuée par le leader est bloquée, le leader peut continuer à renouveler le bail, empêchant toute autre instance de travail d’acquérir le bail et de prendre la position de leader pour coordonner les tâches. Dans la réalité, l’intégrité du responsable doit être vérifiée à intervalles fréquents.
- Le processus d’élection est non déterministe. On ne peut pas faire d’hypothèses sur l’instance de travail qui acquerra le bail de blob et deviendra le leader.
- L’objet blob utilisé comme cible du bail d’objet blob ne doit pas être utilisé à d’autres fins. Si une instance de travail tente de stocker des données dans ce blob, ces données ne seront pas accessibles à moins que l’instance de travail ne soit le leader et ne détienne le bail de blob.
Étapes suivantes
Les recommandations suivantes peuvent aussi s’avérer utiles pendant l’implémentation de ce modèle :
- Ce modèle contient un exemple d’application téléchargeable.
- Mise à l’échelle automatique. il est possible de démarrer et d’arrêter des instances des hôtes de tâche à mesure que la charge varie au niveau de l’application. La mise à l’échelle automatique peut contribuer à maintenir le débit et les performances pendant les périodes d’intense traitement.
- Modèle asynchrone basé sur des tâches.
- exemple illustrant l’algorithme du plus fort (Bully).
- Exemple illustrant l’algorithme en anneau (Ring).
- Apache Curator, bibliothèque cliente pour Apache ZooKeeper.
- Article Lease Blob (API REST) sur MSDN.