Cet article décrit les considérations relatives à la gestion des données au sein d'une architecture de microservices. Dans la mesure où chaque microservice gère ses propres données, l’intégrité et la cohérence des données sont des problématiques majeures.
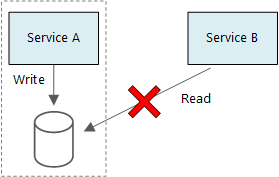
L’un des principes fondamentaux des microservices est que chaque service gère ses propres données. Deux services ne devraient pas partager un magasin de données. A contrario, chaque service est responsable de son propre magasin de données privé, auquel les autres services ne peuvent pas accéder directement.
Cette règle a vocation à éviter tout couplage non intentionnel entre les services, problème qui peut se produire dans les cas de figure où les services partagent des schémas de données sous-jacents. Si un schéma de données est modifié, le changement doit être coordonné sur chacun des services pris en charge par la base de données considérée. En isolant le magasin de données de chaque service, nous sommes en mesure de limiter la portée du changement et de préserver l’agilité de déploiements véritablement indépendants. Cela s’explique également par le fait que chaque microservice peut posséder ses propres modèles de données, requêtes ou modèles de lecture/écriture. En recourant à un magasin de données partagé, vous limitez la capacité des équipes à optimiser le stockage de données sur leur service respectif.
Cette approche entraîne naturellement une persistance polyglotte, à savoir l’utilisation de plusieurs technologies de stockage de données au sein d’une même application. Un service peut avoir besoin des fonctionnalités de schéma à la lecture d’une base de données documentaire. Un autre peut nécessiter l’intégrité référentielle fournie par un SGBDR. Chaque équipe est libre de prendre la décision la mieux adaptée pour son service.
Remarque
Il est tout à fait acceptable que les services partagent le même serveur de base de données physique. Le problème survient quand les services partagent le même schéma, ou lisent et écrivent sur le même jeu de tables de base de données.
Défis
Certains problèmes sont provoqués par cette approche distribuée de la gestion des données. Tout d’abord, une redondance peut être identifiée entre les magasins de données, le même élément de données apparaissant à plusieurs endroits. Par exemple, les données peuvent être stockées dans le cadre d’une transaction, puis déplacées ailleurs à des fins d’analyse, de génération de rapport ou d’archivage. Les données dupliquées ou partitionnées peuvent entraîner des problèmes d’intégrité et de cohérence des données. Lorsque les relations de données s’étendent sur plusieurs services, vous ne pouvez pas recourir aux techniques traditionnelles de gestion des données pour appliquer les relations.
La modélisation traditionnelle des données valorise la règle « chaque événement à sa place ». Chaque entité apparaît exactement une fois dans le schéma. D’autres entités peuvent y faire référence, sans qu’il n’y ait duplication. L’avantage évident de l’approche traditionnelle est identifié au niveau des mises à jour, qui sont effectuées de manière centralisée, ce qui permet d’éviter les soucis d’incohérence des données. Dans une architecture de microservices, vous devez réfléchir à la propagation des mises à jour entre les services et trouver un moyen d’obtenir la cohérence finale au sein d’un système où les données apparaissent à différents endroits sans forte cohérence initiale.
Approches de la gestion des données
Il n’existe aucune approche unique adaptée à tous les cas de figure, mais voici quelques recommandations relatives à la gestion des données dans une architecture de microservices.
Définissez le niveau de cohérence requis pour chaque composant, en privilégiant la cohérence finale lorsque cela est possible. Appréhendez les emplacements du système qui nécessitent une forte cohérence ou des transactions ACID, et les secteurs où une cohérence finale est acceptable. Veuillez consulter la section Utilisation de DDD tactique pour concevoir des microservices pour obtenir des conseils supplémentaires sur les composants.
Lorsque vous avez un besoin crucial de cohérence, un service peut représenter la source de vérité pour une entité donnée, exposée via une API. Les autres services peuvent conserver leur propre copie des données, ou un sous-ensemble des données qui présentent une cohérence finale avec les données de référence mais qui ne sont pas considérés comme la source de vérité. Par exemple, imaginez un système de commerce électronique pourvu d’un service de commande client et d’un service de recommandation. Le service de recommandation peut être à l’écoute des événements du service de commande, mais si un client sollicite un remboursement, il s’agit du service de commande et non du service de recommandation qui dispose de l’historique des transactions.
Pour les transactions, utilisez des modèles comme Superviseur de l’agent du planificateur et Transaction de compensation pour garantir la cohérence des données entre les différents services. Il vous faudra éventuellement stocker un volume supplémentaire de données capturant l’état d’une unité de travail s’étendant sur plusieurs services, afin d’éviter toute défaillance partielle entre plusieurs services. Par exemple, conservez un élément de travail dans une file d’attente durable lorsqu’une transaction à plusieurs étapes est en cours.
Stockez uniquement les données dont un service a besoin. Un service peut n'avoir besoin que d'un sous-ensemble d'informations sur une entité de domaine. Par exemple, dans une limite de contexte Expédition, nous devons savoir quel client est associé à une livraison spécifique. Nous n’avons toutefois pas besoin de l’adresse de facturation du client, qui est gérée par la limite de contexte Comptes. Une analyse approfondie du domaine et l’application d’une approche de conception pilotée par domaine sont vos alliés.
Vérifiez si vos services sont cohérents et couplés souplement. Si deux services échangent continuellement des informations entre eux, entraînant de fait une riche interaction entre les API, il vous faudra redessiner vos limites de service, en fusionnant deux services ou en refactorisant leur fonctionnalité.
Valorisez un style d’architecture basée sur les événements. Dans ce style d’architecture, un service publie un événement si des modifications sont apportées à ses entités ou modèles publics. Les services intéressés peuvent s’abonner à ces événements. Par exemple, un autre service peut utiliser les événements pour établir une vue matérialisée des données, davantage adaptée au modèle de requête.
Un service détenant les événements doit publier un schéma servant à automatiser la sérialisation et la désérialisation des événements, ceci pour éviter tout couplage étroit entre les éditeurs et les abonnés. Envisagez le schéma JSON ou une infrastructure comme Microsoft Bond, Protobuf ou Avro.
À grande échelle, les événements peuvent constituer un goulot d’étranglement sur le système ; aussi, envisagez l’agrégation ou le traitement par lot afin de réduire la charge totale.
Exemple : Choix des magasins de données pour l'application de livraison par drone (Drone Delivery)
Les articles précédents de cette série traitent, à titre d'exemple, d'un service de livraison par drone. Pour en savoir plus sur le scénario et l'implémentation de référence correspondante, cliquez ici. Cet exemple est idéal pour les secteurs de l’aéronautique et de l’aérospatiale.
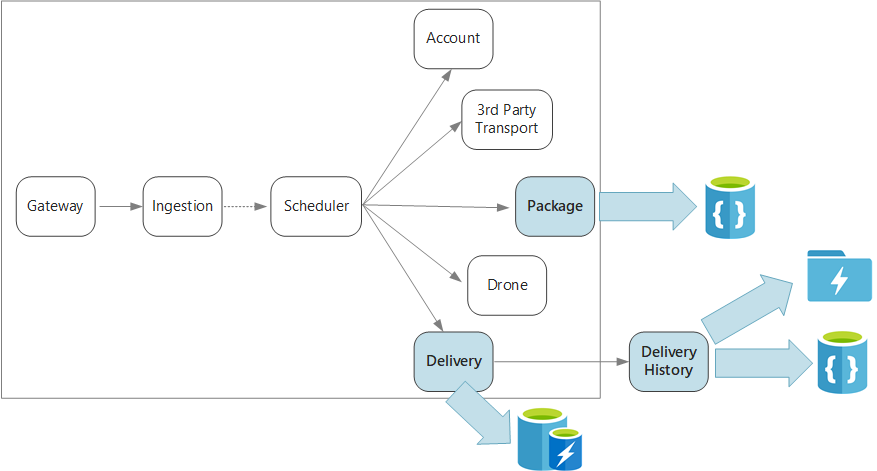
Pour récapituler, cette application définit plusieurs microservices permettant de planifier les livraisons par drone. Lorsqu'un utilisateur planifie une nouvelle livraison, la requête du client comprend des informations sur la livraison, comme les emplacements de la collecte et du dépôt, mais aussi sur le colis, comme la taille et le poids. Ces informations définissent une unité de travail.
Les divers services principaux s’intéressent à différentes portions des données de la requête, et présentent par ailleurs différents profils de lecture et d’écriture.
Service de livraison
Le service de livraison stocke les données sur les livraisons qui sont planifiées ou en cours. Il est à l’écoute des événements des drones, et effectue le suivi de l’état des livraisons en cours. Il transmet également les événements de domaine avec les mises à jour des états de livraison.
Il est probable que les utilisateurs attendant un colis contrôlent régulièrement l’état de la livraison associée. Par conséquent, le service de livraison doit pouvoir compter sur un magasin de données qui mette l’accent sur le débit (en lecture et en écriture) de traitement des données stockées sur le long terme. En outre, le service de livraison n’effectue aucune requête ni analyse complexes ; il récupère simplement l’état d’une livraison donnée. Son équipe a choisi Azure Cache pour Redis en raison de ses hautes performances de lecture-écriture. Les données stockées dans Redis présentent une durée de vie relativement courte. Une fois la livraison effectuée, le service d’historique des livraisons constitue le système d’enregistrement.
Service d’historique des livraisons
Ce service est à l’écoute des événements d’état de livraison du service de livraison. Il stocke ces données dans un système de stockage à long terme. Il existe deux cas d’utilisation différents pour ces données d’historique, qui présentent des exigences propres en matière de stockage des données.
Le premier scénario consiste en l’agrégation des données à des fins d’analyse, dans l’objectif d’optimiser les activités ou d’améliorer la qualité de service. Notez que le service d’historique des données n’effectue pas l’analyse des données en tant que telle. Il est seulement en charge de l’ingestion et du stockage. Pour ce scénario, le stockage doit être optimisé pour l’analyse de données sur un grand ensemble de données, à l’aide d’une approche de schéma à la lecture prenant en charge diverses sources de données. Azure Data Lake Store convient parfaitement pour ce scénario. Azure Data Lake Store est un système de fichiers Apache Hadoop compatible avec Hadoop Distributed File System (HDFS) ; il est parfaitement adapté aux scénarios d’analyse des données.
L’autre scénario permet aux utilisateurs d’effectuer une recherche dans l’historique d’une livraison effectuée. La solution Azure Data Lake n'est pas optimisée pour ce scénario. Pour des performances optimales, Microsoft recommande de stocker les données de séries chronologiques dans Data Lake, dans des dossiers partitionnés par date. (Voir Paramétrage d’Azure Data Lake Store pour les performances). Toutefois, cette structure n’est pas optimale pour rechercher des enregistrements individuels par identifiant. Sauf si vous connaissez également l’horodatage, une recherche par identifiant nécessite d’analyser l’ensemble de la collection. Par conséquent, le service en charge de l’historique des livraisons stocke également un sous-ensemble des données d’historique dans Azure Cosmos DB, à des fins d’accélération des procédures de recherche. Il n’est pas nécessaire de conserver indéfiniment les enregistrements dans Azure Cosmos DB. Les livraisons plus anciennes peuvent être archivées, après un mois par exemple. Cela peut se faire en exécutant un processus régulier par lot. L’archivage des données plus anciennes peut réduire les coûts de Cosmos DB, tout en veillant à ce que les données soient toujours disponibles pour les rapports d’historique à partir de Data Lake.
Service de package
Le service en charge des packages stocke les informations relatives à tous les packages. Les exigences de stockage du service sont les suivantes :
- Un stockage à long terme.
- Capacité à gérer un volume important de packages, nécessitant un débit élevé en écriture.
- Prise en charge de requêtes simples par ID de package. Aucune jointure complexe ni exigence pour l’intégrité référentielle.
Les données de package n'étant pas relationnelles, une base de données documentaire est adaptée, tandis que Azure Cosmos DB peut prendre en charge un débit élevé en valorisant les collections partagées. L’équipe en charge du service Package, qui maîtrise la pile MEAN (MongoDB, Express.js, AngularJS et Node.js), sélectionne l’API MongoDB pour Azure Cosmos DB. Cela lui permet de valoriser son expérience avec MongoDB, tout en profitant des avantages d’Azure Cosmos DB, qui est un service géré Azure.
Étapes suivantes
Découvrez les modèles de conception qui peuvent aider à atténuer certains défis courants dans une architecture de microservices.