Comprendre les modèles de stockage de données
Les systèmes métier modernes gèrent de plus en plus de volumes de données hétérogènes. Cette hétérogénéité signifie qu’un magasin de données unique n’est généralement pas la meilleure approche. Au lieu de cela, il est souvent préférable de stocker différents types de données dans différents magasins de données, chacun axé sur une charge de travail ou un modèle d’utilisation spécifique. Le terme persistance polyglotte est utilisé pour décrire les solutions qui utilisent un mélange de technologies de stockage de données. Par conséquent, il est important de comprendre les principaux modèles de stockage et leurs compromis.
La sélection du magasin de données approprié pour vos besoins est une décision de conception clé. Il existe littéralement des centaines d’implémentations à choisir parmi les bases de données SQL et NoSQL. Les magasins de données sont souvent classés par la façon dont ils structurent les données et les types d’opérations qu’ils prennent en charge. Cet article décrit plusieurs des modèles de stockage les plus courants. Notez qu’une technologie de magasin de données particulière peut prendre en charge plusieurs modèles de stockage. Par exemple, un système de gestion de base de données relationnelle (SGBDR) peut également prendre en charge le stockage clé/valeur ou graphique. En fait, il existe une tendance générale pour ce que l'on appelle la prise en charge multimodèle, où un système de base de données unique prend en charge plusieurs modèles. Mais il est toujours utile de comprendre les différents modèles à un niveau élevé.
Tous les magasins de données d’une catégorie donnée ne fournissent pas le même jeu de fonctionnalités. La plupart des magasins de données fournissent des fonctionnalités côté serveur pour interroger et traiter les données. Parfois, cette fonctionnalité est intégrée au moteur de stockage de données. Dans d’autres cas, les fonctionnalités de stockage et de traitement des données sont séparées, et il peut y avoir plusieurs options de traitement et d’analyse. Les magasins de données prennent également en charge différentes interfaces programmatiques et de gestion.
En règle générale, vous devez commencer par prendre en compte le modèle de stockage le mieux adapté à vos besoins. Considérez ensuite un magasin de données particulier dans cette catégorie, en fonction de facteurs tels que l’ensemble de fonctionnalités, le coût et la facilité de gestion.
Remarque
En savoir plus sur l’identification et l’examen de vos exigences de service de données pour l’adoption du cloud, dans le Microsoft Cloud Adoption Framework pour Azure. De même, vous pouvez en apprendre davantage sur la sélection des outils et services de stockage.
Systèmes de gestion des bases de données relationnelles
Les bases de données relationnelles organisent les données sous la forme d’une série de tables à deux dimensions avec des lignes et des colonnes. La plupart des fournisseurs fournissent un dialecte du langage sql (Structured Query Language) pour récupérer et gérer des données. Un SGBDR implémente généralement un mécanisme de cohérence transactionnelle qui est conforme au modèle ACID (Atomic, Consistent, Isolé, Durable) pour mettre à jour les informations.
Un SGBDR prend généralement en charge un modèle de schéma en écriture, où la structure de données est définie à l’avance, et toutes les opérations de lecture ou d’écriture doivent utiliser le schéma.
Ce modèle est très utile lorsque des garanties de cohérence fortes sont importantes , où toutes les modifications sont atomiques et les transactions conservent toujours les données dans un état cohérent. Toutefois, un SGBDR ne peut généralement pas effectuer un scale-out horizontal sans partitionner les données d’une certaine manière. En outre, les données d’un SGBDR doivent être normalisées, ce qui n’est pas approprié pour chaque jeu de données.
Les services Azure
Azure SQL Database (base de référence de sécurité) - Azure Database for MySQL | (Référentiel de sécurité)
Azure base de données pour PostgreSQL (Base de référence de sécurité) - Azure Database for MariaDB | (Base de référence de sécurité)
Charge de travail
- Les enregistrements sont fréquemment créés et mis à jour.
- Plusieurs opérations doivent être effectuées dans une seule transaction.
- Les relations sont imposées à l’aide de contraintes de base de données.
- Les index sont utilisés pour optimiser les performances des requêtes.
Type de données
- Les données sont hautement normalisées.
- Les schémas de base de données sont requis et appliqués.
- Relations plusieurs à plusieurs entre les entités de données de la base de données.
- Les contraintes sont définies dans le schéma et imposées à toutes les données de la base de données.
- Les données nécessitent une intégrité élevée. Les index et les relations doivent être gérés avec précision.
- Les données nécessitent une cohérence forte. Les transactions fonctionnent d’une manière qui garantit que toutes les données sont 100% cohérentes pour tous les utilisateurs et processus.
- La taille des entrées de données individuelles est de petite à moyenne taille.
Exemples
- Gestion des stocks
- Gestion des commandes
- Base de données de rapports
- Comptabilité
Magasins de clés/valeurs
Un magasin clé/valeur associe chaque valeur de données à une clé unique. La plupart des magasins clé/valeur prennent uniquement en charge les opérations de requête, d’insertion et de suppression simples. Pour modifier une valeur (partiellement ou complètement), une application doit remplacer les données existantes pour la valeur entière. Dans la plupart des implémentations, la lecture ou l’écriture d’une valeur unique est une opération atomique.
Une application peut stocker des données arbitraires sous la forme d’un ensemble de valeurs. Toutes les informations de schéma doivent être fournies par l’application. Le magasin de clés/valeurs récupère ou stocke simplement la valeur par clé.
diagramme 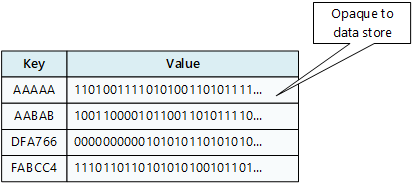
Les magasins de clés/valeurs sont hautement optimisés pour les applications effectuant des recherches simples, mais sont moins adaptés si vous devez interroger des données sur différents magasins de clés/valeurs. Les magasins de clés/valeurs ne sont pas non plus optimisés pour la requête par valeur.
Un magasin de clés/valeurs unique peut être extrêmement évolutif, car le magasin de données peut facilement distribuer des données sur plusieurs nœuds sur des machines distinctes.
Services Azure
- Azure Cosmos DB for Table et Azure Cosmos DB for NoSQL | (Base de référence de sécurité Azure Cosmos DB)
- Azure Cache for Redis | (Base de référence de sécurité)
- Azure Table Storage | (Base de référence de sécurité)
Charge de travail
- Les données sont accessibles à l’aide d’une clé unique, comme un dictionnaire.
- Aucune jointure, verrou ou union n’est requise.
- Aucun mécanisme d’agrégation n’est utilisé.
- Les index secondaires ne sont généralement pas utilisés.
Type de données
- Chaque clé est associée à une valeur unique.
- Absence d’application de schéma.
- Aucune relation entre les entités.
Exemples
- Mise en cache des données
- Gestion des sessions
- Préférence utilisateur et gestion des profils
- Recommandation de produit et service publicitaire
Bases de données de documents
Une base de données de documents stocke une collection de documents , où chaque document se compose de champs nommés et de données. Les données peuvent être des valeurs simples ou des éléments complexes tels que des listes et des collections enfants. Les documents sont récupérés par des clés uniques.
En règle générale, un document contient les données d’une entité unique, comme un client ou une commande. Un document peut contenir des informations qui seraient réparties sur plusieurs tables relationnelles dans un SGBDR. Les documents n’ont pas besoin d’avoir la même structure. Les applications peuvent stocker différentes données dans des documents à mesure que les exigences métier changent.
diagramme 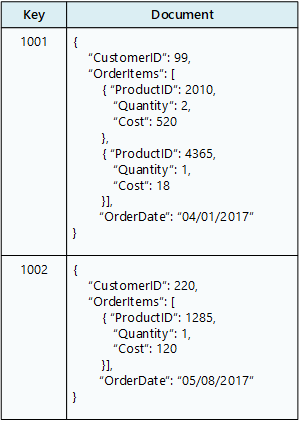
Service Azure
Charge de travail
- Les opérations d’insertion et de mise à jour sont courantes.
- Aucune incompatibilité d’impédance objet-relationnelle. Les documents peuvent mieux correspondre aux structures d’objet utilisées dans le code d’application.
- Les documents individuels sont récupérés et écrits sous la forme d’un bloc unique.
- Les données nécessitent un index sur plusieurs champs.
Type de données
- Les données peuvent être gérées de manière dénormalisée.
- La taille des données de document individuelles est relativement petite.
- Chaque type de document peut utiliser son propre schéma.
- Les documents peuvent inclure des champs facultatifs.
- Les données de document sont semi-structurées, ce qui signifie que les types de données de chaque champ ne sont pas strictement définis.
Exemples
- Catalogue de produits
- Gestion du contenu
- Gestion des stocks
Bases de données graphes
Une base de données de graphe stocke deux types d’informations, de nœuds et de bords. Les arêtes spécifient des relations entre les nœuds. Les nœuds et les arêtes peuvent avoir des propriétés qui fournissent des informations sur ce nœud ou ce bord, comme les colonnes d’une table. Les arêtes peuvent également avoir une direction indiquant la nature de la relation.
Les bases de données graphes peuvent effectuer efficacement des requêtes sur le réseau de nœuds et de périphéries et analyser les relations entre les entités. Le diagramme suivant montre la base de données du personnel d’une organisation structurée sous forme de graphique. Les entités sont des employés et des services, et les arêtes indiquent les liens hiérarchiques et les services dans lesquels les employés travaillent.
diagramme 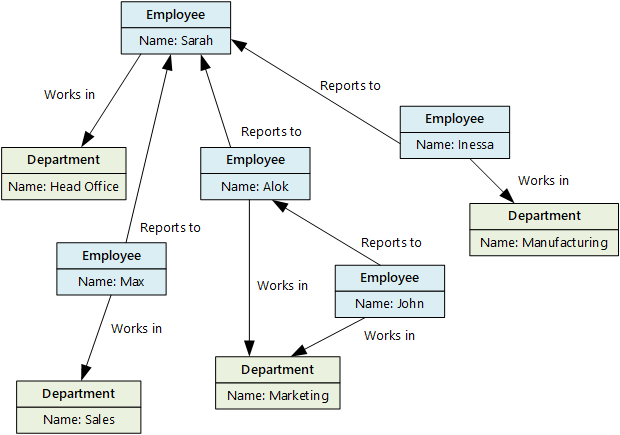
Cette structure facilite l’exécution de requêtes telles que « Rechercher tous les employés qui signalent directement ou indirectement à Sarah » ou « Qui travaille dans le même service que John ? » Pour les graphiques volumineux avec beaucoup d’entités et de relations, vous pouvez effectuer des analyses très complexes très rapidement. De nombreuses bases de données de graphe fournissent un langage de requête que vous pouvez utiliser pour parcourir efficacement un réseau de relations.
Services Azure
Azure Cosmos DB pour Apache Gremlin (base de référence de sécurité) - | SQL Server (base de référence de sécurité)
Charge de travail
- Relations complexes entre les éléments de données impliquant de nombreux tronçons entre les éléments de données associés.
- La relation entre les éléments de données est dynamique et change au fil du temps.
- Les relations entre les objets sont des entités de première classe, sans qu’il soit nécessaire de traverser des clés étrangères et des jointures.
Type de données
- Nœuds et relations.
- Les nœuds sont similaires aux lignes de table ou aux documents JSON.
- Les relations sont aussi importantes que les nœuds et sont exposées directement dans le langage de requête.
- Les objets composites, tels qu’une personne avec plusieurs numéros de téléphone, ont tendance à être divisés en nœuds distincts, plus petits, combinés à des relations traversables
Exemples
- Organigrammes
- Graphiques sociaux
- Détection des fraudes
- Moteurs de recommandation
Analytique des données
Les magasins d’analytique des données fournissent des solutions massivement parallèles pour l’ingestion, le stockage et l’analyse des données. Les données sont distribuées sur plusieurs serveurs pour optimiser l’extensibilité. Les formats de fichiers de données volumineux, tels que les fichiers de délimiteur (CSV), les fichiersParquetet ORC sont largement utilisés dans l’analytique données. Les données historiques sont généralement stockées dans des entrepôts de données tels que le stockage de blobs ou Azure Data Lake Storage Gen2, qui sont ensuite accessibles par Azure Synapse, Databricks ou HDInsight sous forme de tables externes. L’article Utiliser des tables externes avec Synapse SQL décrit un scénario classique avec l’utilisation des données stockées en tant que fichiers Parquet pour des raisons de performances.
Services Azure
- | Azure Synapse Analytics (base de référence de sécurité)
Azure Data Lake (base de référence de sécurité) - | Azure Data Explorer (base de référence de sécurité)
- Azure Analysis Services
- | HDInsight (base de référence de sécurité)
- | Azure Databricks (base de référence de sécurité)
Charge de travail
- Analytique des données
- Intelligence d’entreprise
Type de données
- Données historiques provenant de plusieurs sources.
- Généralement dénormalisé dans un schéma « en étoile » ou « en flocon », constitué de tables de faits et de dimensions.
- Généralement chargé avec de nouvelles données sur une base régulière.
- Les tables de dimension incluent souvent plusieurs versions historiques d’une entité, appelées dimension à variation lente.
Exemples
- Entrepôt de données d’entreprise
Bases de données à famille de colonnes
Une base de données de famille de colonnes organise les données en lignes et colonnes. Dans sa forme la plus simple, une base de données de famille de colonnes peut sembler très similaire à une base de données relationnelle, au moins conceptuellement. La véritable puissance d’une base de données de famille de colonnes réside dans son approche dénormalisée pour structurer les données éparses.
Vous pouvez considérer une base de données de famille de colonnes comme contenant des données tabulaires avec des lignes et des colonnes, mais les colonnes sont divisées en groupes appelés familles de colonnes . Chaque famille de colonnes contient un ensemble de colonnes qui sont liées logiquement ensemble et sont généralement récupérées ou manipulées en tant qu’unité. D’autres données accessibles séparément peuvent être stockées dans des familles de colonnes distinctes. Dans une famille de colonnes, de nouvelles colonnes peuvent être ajoutées dynamiquement et les lignes peuvent être éparses (autrement dit, une ligne n’a pas besoin d’avoir une valeur pour chaque colonne).
Le diagramme suivant montre un exemple avec deux familles de colonnes, Identity et Contact Info. Les données d’une entité unique ont la même clé de ligne dans chaque famille de colonnes. Cette structure, où les lignes d’un objet donné dans une famille de colonnes peuvent varier dynamiquement, est un avantage important de l’approche de la famille de colonnes, ce qui rend cette forme de magasin de données hautement adaptée au stockage de données structurées et volatiles.
diagramme 
Contrairement à un magasin clé/valeur ou à une base de données de documents, la plupart des bases de données de familles de colonnes stockent les données dans l'ordre des clés, plutôt qu'en calculant un hachage. De nombreuses implémentations vous permettent de créer des index sur des colonnes spécifiques dans une famille de colonnes. Les index vous permettent de récupérer des données par valeur de colonnes, plutôt que par clé de ligne.
Les opérations de lecture et d’écriture d’une ligne sont généralement atomiques avec une seule famille de colonnes, bien que certaines implémentations fournissent une atomicité sur toute la ligne, couvrant plusieurs familles de colonnes.
Services Azure
- Azure Cosmos DB pour Apache Cassandra | (base de référence de sécurité)
- HBase dans HDInsight | (Base de référence de sécurité)
Charge de travail
- La plupart des bases de données de famille de colonnes effectuent des opérations d’écriture extrêmement rapidement.
- Les opérations de mise à jour et de suppression sont rares.
- Conçu pour fournir un débit élevé et un accès à faible latence.
- Prend en charge l’accès facile aux requêtes à un ensemble particulier de champs au sein d’un enregistrement beaucoup plus volumineux.
- Scalabilité massive.
Type de données
- Les données sont stockées dans des tables composées d’une colonne clé et d’une ou plusieurs familles de colonnes.
- Certaines colonnes peuvent varier en fonction des lignes.
- Des cellules individuelles sont accessibles via des commandes get et put
- Plusieurs lignes sont retournées en utilisant une commande scan.
Exemples
- Recommandations
- Personnalisation
- Données de capteur
- Télémétrie
- Messagerie
- Analyse des réseaux sociaux
- Analytique web
- Surveillance de l’activité
- Données météo et autres séries chronologiques
Bases de données du moteur de recherche
Une base de données du moteur de recherche permet aux applications de rechercher des informations contenues dans des magasins de données externes. Une base de données du moteur de recherche peut indexer des volumes massifs de données et fournir un accès quasi en temps réel à ces index.
Les index peuvent être multidimensionnels et peuvent prendre en charge des recherches en texte libre sur de grands volumes de données de texte. L’indexation peut être effectuée à l’aide d’un modèle d’extraction, déclenchée par la base de données du moteur de recherche ou à l’aide d’un modèle push, lancée par le code d’application externe.
La recherche peut être exacte ou approximative. Une recherche approximative recherche des documents qui correspondent à un ensemble de termes et calcule le degré de correspondance. Certains moteurs de recherche prennent également en charge l’analyse linguistique qui peut fournir des correspondances basées sur des synonymes, des expansions de catégories (par exemple, la correspondance de dogs à pets) et la racinisation (correspondance de mots avec la même racine).
Service Azure
Charge de travail
- Index de données provenant de plusieurs sources et services.
- Les requêtes sont ad hoc et peuvent être complexes.
- La recherche en texte intégral est requise.
- Une requête en libre-service ad hoc est requise.
Type de données
- Texte semi-structuré ou non structuré
- Texte avec référence aux données structurées
Exemples
- Catalogues de produits
- Recherche de site
- Exploitation forestière
Bases de données de séries chronologiques
Les données de série chronologique sont un ensemble de valeurs organisées par heure. Les bases de données de série chronologique collectent généralement de grandes quantités de données en temps réel à partir d’un grand nombre de sources. Les mises à jour sont rares et les suppressions sont souvent effectuées en tant qu’opérations en bloc. Bien que les enregistrements écrits dans une base de données de série chronologique soient généralement petits, il existe souvent un grand nombre d’enregistrements et la taille totale des données peut croître rapidement.
Service Azure
Charge de travail
- Les enregistrements sont généralement ajoutés séquentiellement dans l’ordre horaire.
- La plupart des opérations (95-99%) sont des opérations d'écriture.
- Les mises à jour sont rares.
- Les suppressions se produisent en bloc et sont apportées à des blocs ou enregistrements contigus.
- Les données sont lues séquentiellement dans l’ordre croissant ou décroissant du temps, souvent en parallèle.
Type de données
- Un horodatage est utilisé comme clé primaire et mécanisme de tri.
- Les balises peuvent définir des informations supplémentaires sur le type, l’origine et d’autres informations sur l’entrée.
Exemples
- Surveillance et télémétrie des événements.
- Capteur ou autres données IoT.
Stockage d’objets
Le stockage d’objets est optimisé pour stocker et récupérer des objets binaires volumineux (images, fichiers, flux vidéo et audio, objets et documents de données d’application volumineux, images de disque de machine virtuelle). Les fichiers de données volumineux sont également couramment utilisés dans ce modèle, par exemple, un fichier délimiteur (CSV), parquetet ORC. Les magasins d’objets peuvent gérer des quantités extrêmement importantes de données non structurées.
Service Azure
- | Azure Blob Storage (référentiel de sécurité)
- | Azure Data Lake Storage Gen2 (base de référence de sécurité)
Charge de travail
- Identifié par clé.
- Le contenu est généralement une ressource telle qu’un délimiteur, une image ou un fichier vidéo.
- Le contenu doit être durable et externe à n’importe quel niveau d’application.
Type de données
- La taille des données est importante.
- La valeur est opaque.
Exemples
- Images, vidéos, documents Office, PDF
- HTML statique, JSON, CSS
- Fichiers de journalisation et d'audit
- Sauvegardes de base de données
Fichiers partagés
Parfois, l’utilisation de fichiers plats simples peut être le moyen le plus efficace de stocker et de récupérer des informations. L’utilisation de partages de fichiers permet d’accéder aux fichiers sur un réseau. Étant donné les mécanismes de sécurité et de contrôle d’accès simultanés appropriés, le partage de données de cette façon peut permettre aux services distribués de fournir un accès aux données hautement évolutif pour effectuer des opérations de base et de bas niveau, telles que des demandes de lecture et d’écriture simples.
Service Azure
Charge de travail
- Migration à partir d’applications existantes qui interagissent avec le système de fichiers.
- Nécessite l’interface SMB.
Type de données
- Fichiers dans un ensemble hiérarchique de dossiers.
- Accessible avec des bibliothèques d’E/S standard.
Exemples
- Fichiers hérités
- Contenu partagé accessible entre plusieurs machines virtuelles ou instances d’application
Grâce à cette compréhension des différents modèles de stockage de données, l’étape suivante consiste à évaluer votre charge de travail et votre application et à déterminer le magasin de données qui répond à vos besoins spécifiques. Utilisez l’arbre de décision de stockage de données pour faciliter ce processus.
Étapes suivantes
- solutions et services de stockage cloud Azure
- Passer en revue vos options de stockage
- Introduction au stockage Azure
- Présentation d’Azure Data Explorer
Ressources associées
- architectures de Big Data
- Choisir une technologie de stockage de données
- arbre de décision du stockage de données