Les données sont souvent considérées comme la partie la plus importante d’une solution, car elles représentent des informations professionnelles précieuses pour vous et vos clients. Il est donc important de gérer vos données avec précaution. Lorsque vous planifiez des composants de stockage ou de données pour un système multilocataire, vous devez choisir une approche en matière de partage ou d’isolation des données de vos tenants.
Cet article présente les principaux éléments et exigences que les architectes de solutions doivent prendre en compte lors du choix d’une approche en matière de stockage des données dans un système multilocataire. Vous trouverez ensuite une présentation des modèles les plus couramment utilisés pour les services de stockage et de données multi-locataires, ainsi quelques anti-modèles à éviter. Enfin, vous bénéficierez de conseils adaptés à certaines situations.
Principaux éléments et exigences à prendre en compte
Il est important de considérer les approches que vous utilisez pour les services de stockage et de données d'un certain nombre de points de vue, y compris les piliers du cadre Azure Well-Architected Framework.
Mise à l’échelle
Lorsque vous utilisez des services de stockage des données, vous devez tenir compte du nombre de tenants dont vous disposez et du volume de données que vous stockez. Si vous n'avez qu'un petit nombre de locataires (cinq maximum) et que vous ne stockez que de petites quantités de données pour chacun d'entre eux, inutile de perdre votre temps à planifier une approche de stockage de données hautement évolutive ou à mettre en place une approche entièrement automatisée pour gérer vos ressources de données. Au fur et à mesure de votre expansion, une stratégie claire devient cependant nécessaire pour la mise à l’échelle de vos données et ressources de stockage, ainsi que pour l’automatisation de leur gestion. Si vous disposez de 50 locataires, ou si vous prévoyez d'atteindre ce niveau de mise à l'échelle, il est impératif de concevoir une approche des données et du stockage en mettant la mise à l'échelle au centre de vos préoccupations.
Déterminez jusqu'où vous souhaitez pousser la mise à l'échelle, et planifiez clairement votre approche architecturale du stockage des données pour atteindre ce niveau de mise à l'échelle.
Prévisibilité des performances
Les services de données et de stockage multi-locataires sont particulièrement sensibles au problème des voisins bruyants (ou Noisy Neighbors). Il est important de déterminer si vos tenants peuvent affecter leurs performances mutuelles. Par exemple, vos locataires présentent-ils des pics d'utilisation qui se chevauchent au fil du temps ? Vos clients utilisent-ils tous votre solution aux mêmes heures chaque jour, ou les requêtes sont-elles réparties de manière uniforme ? Ces facteurs détermineront le niveau d'isolation à concevoir, la quantité de ressources à approvisionner, et le degré de partage des ressources entre les locataires.
Dans le cadre de cette décision, il est important de prendre en compte les quotas de ressources et de requêtes d'Azure. Par exemple, supposons que vous ne déployiez qu'un seul compte de stockage pour accueillir toutes les données de vos locataires. Si vous dépassez un nombre spécifique d'opérations de stockage par seconde, Azure Storage rejettera les requêtes de votre application et tous vos locataires seront impactés. C'est ce qu'on appelle un comportement de limitation. Les requêtes limitées doivent être surveillées. Pour plus d’informations, consultez Guide du mécanisme de nouvelle tentative relatif aux services Azure.
Isolation des données
Lors de la conception d'une solution qui contient des services de données multi-locataires, différentes options et différents niveaux d'isolation des données sont généralement disponibles, chacun présentant ses propres avantages et inconvénients. Par exemple :
- Lorsque vous utilisez Azure Cosmos DB, vous pouvez déployer des conteneurs distincts pour chaque locataire, et partager des bases de données et des comptes entre plusieurs locataires. Vous pouvez également envisager de déployer des bases de données ou des comptes différents pour chaque locataire, en fonction du niveau d'isolation requis.
- Lorsque vous utilisez le service Stockage Azure pour les données blob, vous pouvez déployer des conteneurs d'objets blob distincts pour chaque locataire, ou déployer des comptes de stockage distincts.
- Lorsque vous utilisez Azure SQL, vous pouvez utiliser des tables distinctes dans des bases de données partagées, ou déployer des bases de données ou des serveurs distincts pour chaque locataire.
- Dans tous les services Azure, vous pouvez déployer des ressources au sein d’un seul abonnement Azure partagé, ou utiliser plusieurs abonnements Azure (voire un par tenant).
Il n'existe pas de solution unique qui convienne à toutes les situations. L'option à choisir dépend d'un certain nombre de facteurs et des exigences de vos locataires. Par exemple, si vos locataires doivent respecter des normes de conformité ou des normes réglementaires spécifiques, vous devrez peut-être appliquer un niveau d'isolation plus élevé. De même, vous pouvez être soumis à des exigences commerciales qui vous obligent à isoler physiquement les données de vos clients, ou vous pouvez avoir recours à l'isolation pour éviter tout problème de voisins bruyants. En outre, si les locataires doivent utiliser leurs propres clés de chiffrement, s'ils disposent de stratégies de sauvegarde et de restauration individuelles, ou si leurs données doivent être stockées dans des emplacements géographiques différents, vous devrez peut-être les isoler des autres locataires ou les regrouper auprès de locataires qui disposent de stratégies similaires.
Complexité de l'implémentation
Il est important de tenir compte de la complexité de votre implémentation. Une bonne pratique consiste à concevoir une architecture capable de répondre à vos besoins tout en restant simple. Évitez de vous lancer dans une architecture qui deviendra de plus en plus complexe au fil des mises à l'échelle, ou dans une architecture pour le développement ou le maintien de laquelle vous ne disposez pas des ressources ou de l'expertise nécessaires.
De même, si votre solution n'a pas besoin d'être mise à l'échelle vers un grand nombre de locataires, ou si vous ne souhaitez pas renforcer les performances ou l'isolation des données, il est préférable de conserver votre solution telle quelle pour éviter de la rendre inutilement plus complexe.
Le niveau de personnalisation à prendre en charge doit être pris en compte pour les solutions de données multi-locataires. Par exemple, un locataire peut-il étendre votre modèle de données ou appliquer des règles de données personnalisées ? Veillez à concevoir d’avance cette exigence. Évitez la duplication (fork) ou la fourniture d’une infrastructure personnalisée pour des tenants individuels. Une infrastructure personnalisée empêche votre capacité à mettre à l’échelle, à tester votre solution et à déployer des mises à jour. Envisagez plutôt d'utiliser des indicateurs de fonctionnalités et d'autres formes de configuration des locataires.
Complexité de la gestion et des opérations
Réfléchissez à la manière dont vous prévoyez d'utiliser votre solution, et à l'impact de votre approche multi-locataire sur vos opérations et processus. Par exemple :
- Gestion : réfléchissez aux opérations de gestion inter-locataire, comme les activités de maintenance régulières. Si vous utilisez plusieurs comptes, serveurs ou bases de données, comment comptez-vous lancer et surveiller les opérations de chaque locataire ?
- Surveillance et contrôle : si vous surveillez ou mesurez vos tenants, déterminez la manière dont votre solution communique des mesures, et si celles-ci peuvent être facilement liées au tenant qui a déclenché la requête.
- Création de rapports : il est possible que la création de rapports sur des données provenant de tenants isolés nécessite que chaque tenant publie des données dans un entrepôt de données centralisé, plutôt que d’exécuter des requêtes sur chaque base de données individuellement, puis d’agréger les résultats.
- Mises à jour de schémas : si vous utilisez une base de données qui applique un schéma, planifiez le mode de déploiement des mises à jour de schémas dans votre patrimoine. Réfléchissez à la façon dont votre application saura quelle version de schéma utiliser pour les requêtes de base de données d'un locataire spécifique.
- Configuration requise : tenez compte des exigences de haute disponibilité de vos tenants (par exemple, les contrats au niveau de la durée de bon fonctionnement ou contrats SLA) et des exigences de récupération d’urgence (par exemple, les objectifs de temps de récupération, ou RTO, et les objectifs de point de récupération, ou RPO). Si les locataires ont des attentes différentes, serez-vous en mesure de répondre aux exigences de chacun d'entre eux ?
- Migration : comment procéderez-vous à la migration des tenants s’ils doivent passer à un autre type de service, à un autre déploiement ou à une autre région ?
Coût
En règle générale, plus la densité de locataires de votre infrastructure de déploiement est élevée, plus le coût d'approvisionnement de cette infrastructure est faible. Cela dit, l'infrastructure partagée augmente la probabilité de rencontrer des problèmes, tels que le problème des voisins bruyants, d'où la nécessité de bien réfléchir aux compromis à faire.
Approches et modèles à prendre en compte
Différents modèles de conception du Centre des architectures Azure sont pertinents pour les services de stockage et de données multi-locataires. Vous pouvez choisir de suivre un modèle de manière cohérente. Ou vous pouvez envisager de mélanger et d'assortir les modèles. Par exemple, vous pouvez utiliser une base de données multi-locataire pour la majorité de vos locataires, mais déployer des empreintes à un seul locataire pour les locataires qui paient plus cher ou qui ont des exigences inhabituelles. De même, il est souvent judicieux d'effectuer des mises à l'échelle à l'aide d'empreintes de déploiement, même lorsque vous utilisez une base de données multi-locataire ou des bases de données partitionnées au sein d'une empreinte.
Modèle d’empreintes de déploiement
Pour plus d’informations sur la façon dont le modèle Empreintes de déploiement peut être utilisé pour prendre en charge une solution multilocataire, consultez Vue d’ensemble.
Bases de données multi-locataires et magasins de fichiers partagés
Vous envisager peut-être de déployer une base de données multi-locataire partagée, un compte de stockage ou un partage de fichiers, et de les partager entre tous vos locataires.
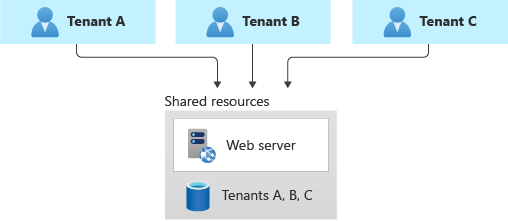
Cette approche offre la plus forte densité de locataires par rapport à l'infrastructure, et son coût est donc généralement le plus bas. De plus, elle réduit souvent les frais de gestion, car il n’y a qu’une seule base de données ou ressource à gérer, à sauvegarder et à sécuriser.
Toutefois, lorsque vous utilisez une infrastructure partagée, tenez compte des mises en garde suivantes :
- Limites de mise à l’échelle : lorsque vous vous appuyez sur une seule ressource, tenez compte de l’échelle et des limites prises en charge pour cette ressource. Par exemple, la taille maximale d'une base de données ou d'un magasin de fichiers, ou les limites maximales de débit, finiront par devenir un obstacle majeur si votre architecture repose sur une seule base de données. Avant de choisir ce modèle, déterminez avec soin l'échelle maximale à atteindre et comparez-la à vos limites actuelles et futures.
- Voisins bruyants : il est possible que le problème de voisin bruyant deviennent gênant, surtout si vous avez des tenants particulièrement occupés ou générant des charges de travail plus élevées que les autres. Pour atténuer ces effets, envisagez d'appliquer le modèle Limitation ou le modèle Limitation de débit.
- Surveillance de chaque tenant : vous rencontrerez peut-être des difficultés pour surveiller l’activité et mesurer la consommation d’un seul tenant. Certains services, tels qu'Azure Cosmos DB, fournissent des rapports sur l'utilisation des ressources pour chaque requête. Ces informations peuvent ainsi être suivies pour mesurer la consommation de chaque locataire. D'autres services ne fournissent pas le même niveau de détail. Par exemple, les métriques Azure Files relatives à la capacité des fichiers sont disponibles par dimension de partage de fichiers, mais uniquement lorsque vous utilisez des partages Premium. Le niveau Standard, quant à lui, ne fournit des métriques qu'au niveau du compte de stockage.
- Exigences du tenant : les tenants peuvent avoir des exigences différentes en matière de sécurité, de sauvegarde, de disponibilité ou d’emplacement de stockage. Si ces exigences ne sont pas conformes à la configuration de votre ressource unique, vous risquez de ne pas pouvoir les satisfaire.
- Personnalisation du schéma : lorsque vous utilisez une base de données relationnelle, ou dans toute autre situation où le schéma des données est important, la personnalisation du schéma au niveau du tenant est alors difficile.
Modèle de partitionnement
Le Modèle de partitionnement implique le déploiement de plusieurs bases de données distinctes, appelées partitions, qui contiennent chacune les données d’un ou plusieurs tenants. Contrairement aux empreintes de déploiement, les partitions n'impliquent pas que toute l'infrastructure soit dupliquée. Vous pouvez partitionner des bases de données sans dupliquer ou partitionner d'autres infrastructures dans votre solution.
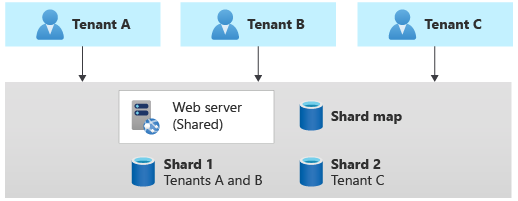
Le terme « sharding », synonyme de partitionnement, peut également être utilisé. Les deux termes sont interchangeables. Consultez Partitionnement des données horizontales, verticales et fonctionnelles.
Le modèle Partitionnement peut s'adapter à un très grand nombre de locataires. En outre, en fonction de votre charge de travail, vous pouvez atteindre une densité élevée de locataires par rapport aux partitions, ce qui rend le coût intéressant. Le modèle Partitionnement peut également être utilisé pour répondre aux quotas, limites et contraintes des abonnements et services Azure.
Certains magasins de données, tels qu'Azure Cosmos DB, offrent une prise en charge native du partitionnement. Lorsque vous utilisez d’autres solutions, comme Azure SQL, il peut être plus complexe de créer une infrastructure de partitionnement et d’acheminer des requêtes vers la partition appropriée, pour un tenant donné.
Le partitionnement rend également difficile la prise en charge des différences de configuration au niveau du tenant et la possibilité pour les clients de fournir leurs propres clés de chiffrement.
Application multi-locataire avec bases de données dédiées pour chaque locataire
Une autre approche courante consiste à déployer une seule application mult-locataire, avec des bases de données dédiées pour chaque locataire.
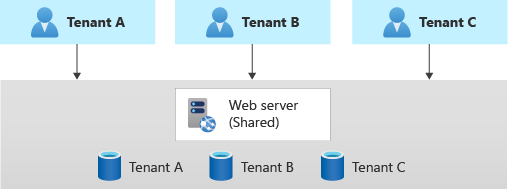
Dans ce modèle, les données de chaque locataire sont isolées de celles des autres, et vous pouvez prendre en charge un certain degré de personnalisation pour chacun d'entre eux.
Dans la mesure où vous approvisionnez des ressources de données dédiées pour chaque locataire, le coût de cette approche peut être plus élevé que celui des modèles d'hébergement partagé. Cela dit, Azure propose plusieurs options que vous pouvez envisager d'utiliser afin de partager le coût d'hébergement des ressources de données individuelles entre plusieurs locataires. Par exemple, lorsque vous utilisez Azure SQL, vous pouvez envisager des pools élastiques. Pour Azure Cosmos DB, vous pouvez approvisionner le débit pour une base de données et le débit est partagé entre les conteneurs de cette base de données, bien que cette approche ne soit pas appropriée lorsque vous avez besoin de performances garanties pour chaque conteneur.
Dans cette approche, étant donné que seuls les composants de données sont déployés individuellement pour chaque locataire, vous pouvez atteindre une densité élevée pour les autres composants de votre solution et réduire le coût de ces composants.
Il est important d'utiliser des approches de déploiement automatisé lorsque vous approvisionnez des bases de données pour chaque locataire.
Modèle Geode
Le modèle Géode a été spécialement conçu pour les solutions géographiquement distribuées, y compris les solutions multi-locataires. Il prend en charge une charge élevée et de hauts niveaux de résilience. Si vous implémentez le modèle Géode, votre couche Données doit être en mesure de répliquer les données dans les différentes régions géographiques, et elle doit prendre en charge les écritures dans les différents emplacements géographiques.
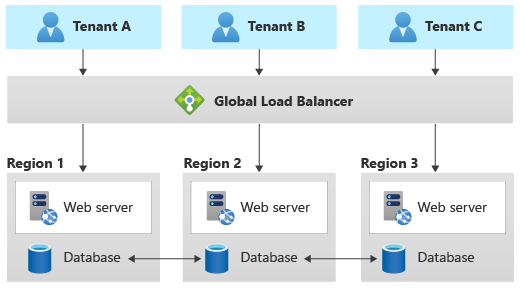
Azure Cosmos DB fournit des écritures multirégionales pour prendre en charge ce modèle, et Cassandra prend en charge les clusters multirégions. Les autres services de données ne sont généralement pas en mesure de prendre en charge ce modèle sans une personnalisation importante.
Antimodèles à éviter
Lorsque vous créez des services de données multilocataires, il est impératif d’éviter les situations qui entravent votre capacité de mise à l’échelle.
Pour les bases de données relationnelles, il s'agit notamment des situations suivantes :
- Isolation basée sur les tables. Lorsque vous travaillez dans une base de données unique, évitez de créer des tables individuelles pour chaque locataire. Avec cette approche, une base de données unique ne pourra pas prendre en charge un très grand nombre de locataires, et vous aurez de plus en plus de mal à interroger, gérer et mettre à jour les données. Envisagez plutôt d'utiliser un ensemble unique de tables multi-locataires avec une colonne d'identification des locataires. Vous pouvez également utiliser l'un des modèles décrits ci-dessus afin de déployer des bases de données distinctes pour chaque locataire.
- Personnalisation des locataires au niveau des colonnes. Évitez les mises à jour de schéma qui ne s'appliquent qu'à un seul locataire. Supposons par exemple que vous disposiez d'une seule base de données multi-locataire. Évitez d'ajouter une nouvelle colonne pour répondre aux exigences d'un locataire spécifique. Bien qu'acceptable pour un petit nombre de personnalisations, cela devient rapidement ingérable lorsque vous devez prendre en compte un grand nombre de personnalisations. Envisagez plutôt de réviser votre modèle de données pour suivre les données personnalisées de chaque locataire dans une table dédiée.
- Modifications manuelles du schéma. Évitez de mettre à jour manuellement le schéma de votre base de données, même si vous ne disposez que d'une seule base de données partagée. Il est facile de perdre la trace des mises à jour que vous avez appliquées et, si vous devez effectuer un scale-out vers d'autres bases de données, il est difficile d'identifier le schéma à appliquer. Créez plutôt un pipeline automatisé pour déployer vos modifications de schéma, et utilisez-le de manière cohérente. Suivez la version du schéma utilisée pour chaque locataire dans une base de données ou une table de choix dédiée.
- Dépendances de versions. Veillez à ce que votre application ne dépende pas d'une seule version de votre schéma de base de données. Au fil des mises à l’échelle, il peut être nécessaire d’appliquer des mises à jour de schéma à différents moments pour différents tenants. Assurez-vous plutôt que la version de votre application est rétrocompatible avec au moins une version du schéma, et évitez les mises à jour de schéma destructives.
Bases de données
Certaines fonctionnalités peuvent être utiles à l'architecture multi-locataire. Mais selon les services de base de données, elles ne sont pas toutes disponibles. Demandez-vous si vous en avez besoin lorsque vous choisissez le service à utiliser pour votre scénario :
La sécurité au niveau des lignes peut fournir une isolation de sécurité pour des données de locataires spécifiques dans une base de données multi-locataire partagée. Cette fonctionnalité est disponible dans certaines bases de données, telles qu’Azure SQL et Postgres Flex.
Lorsque vous utilisez la sécurité au niveau des lignes, vous devez vous assurer que l’identité de l’utilisateur et l’identité de locataire sont propagées via l’application et dans le magasin de données avec chaque requête. Cette approche peut être complexe à concevoir, implémenter, tester et gérer. De nombreuses solutions multilocataires n’utilisent pas de sécurité au niveau des lignes en raison de ces complexités.
Le chiffrement au niveau du locataire peut être nécessaire afin de prendre en charge les locataires qui fournissent leurs propres clés de chiffrement pour leurs données. Cette fonctionnalité est disponible dans Azure SQL avec Always Encrypted. Azure Cosmos DB fournit des clés gérées par le client au niveau du compte et prend également en charge Always Encrypted.
La mise en commun des ressources permet de partager les ressources et les coûts entre plusieurs bases de données ou conteneurs. Cette fonctionnalité est disponible dans les pools élastiques et instances gérées d'Azure SQL, ainsi que dans le débit de base de données d'Azure Cosmos DB. Soyez cependant conscient que chaque option a ses limites.
Le partitionnement bénéficie d'une meilleure prise en charge native dans certains services que dans d'autres. Cette fonctionnalité est disponible dans Azure Cosmos DB, en utilisant son partitionnement logique et physique. Bien qu'Azure SQL ne prenne pas en charge le partitionnement en mode natif, il fournit des outils de partitionnement pour prendre en charge ce type d'architecture.
En outre, lorsque vous utilisez des bases de données relationnelles ou d’autres bases de données basées sur des schémas, déterminez où le processus de mise à niveau des schémas doit être déclenché lorsque vous gérez une flotte de bases de données. Dans un petit domaine de bases de données, vous pouvez envisager d'utiliser un pipeline de déploiement pour déployer les modifications de schéma. Au fur et à mesure que le nombre de bases de données augmente, il peut être préférable que votre couche Application détecte la version du schéma d'une base de données spécifique et lance le processus de mise à niveau.
Stockage de fichiers et d'objets blob
Réfléchissez à l'approche à utiliser pour isoler les données au sein d'un compte de stockage. Par exemple, vous pouvez déployer des comptes de stockage distincts pour chaque locataire, ou partager des comptes de stockage et déployer des conteneurs individuels. Vous pouvez également créer des conteneurs d'objets blob partagés, puis utiliser le chemin d'accès aux objets blob pour séparer les données de chaque locataire. Tenez compte des limites et quotas d'abonnement Azure, et planifiez avec soin votre croissance afin de veiller à ce que vos ressources Azure soient mises à l'échelle pour répondre à vos besoins futurs.
Si vous utilisez des conteneurs partagés, planifiez soigneusement votre stratégie d'authentification et d'autorisation afin de veiller à ce que les locataires n'aient pas mutuellement accès à leurs données respectives. Pensez au modèle Clé de valet lorsque vous fournissez aux clients un accès aux ressources de Stockage Azure.
Affectation des coûts
Réfléchissez à la façon dont vous allez mesurer la consommation et répartir les coûts entre les locataires pour l'utilisation des services de données partagés. Si possible, essayez d'utiliser des métriques intégrées au lieu de calculer vos propres métriques. Toutefois, avec une infrastructure partagée, il devient difficile de fractionner les données de télémétrie pour des tenants individuels, et vous devrez peut-être envisager une mesure personnalisée au niveau de l'application.
En général, les services natifs Cloud, comme Azure Cosmos DB et Stockage Blob Azure, fournissent des métriques plus précises pour suivre et modéliser l'utilisation d'un locataire spécifique. Par exemple, Azure Cosmos DB fournit le débit consommé pour chaque requête et chaque réponse.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- John Downs | Ingénieur logiciel principal
Autres contributeurs :
- Paul Burpo | Ingénieur client principal, FastTrack for Azure
- Daniel Scott-Raynsford | Stratégiste de la technologie partenaire
- Arsen Vladimirskiy | Ingénieur client principal, FastTrack for Azure
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
Pour plus d’informations sur l’architecture mutualisée et sur les services Azure spécifiques, consultez :