Une architecture Big Data est conçue pour gérer l’ingestion, le traitement et l’analyse des données trop volumineuses ou complexes pour les systèmes de base de données traditionnels.
diagramme logique 
Les solutions Big Data impliquent généralement un ou plusieurs des types de charge de travail suivants :
- Traitement par lots de sources big data au repos.
- Traitement en temps réel du Big Data en mouvement.
- Exploration interactive du Big Data.
- Analytique prédictive et Machine Learning.
La plupart des architectures Big Data incluent certains ou tous les composants suivants :
sources de données: toutes les solutions Big Data commencent par une ou plusieurs sources de données. Voici quelques exemples :
- Magasins de données d’application, tels que les bases de données relationnelles.
- Fichiers statiques générés par les applications, tels que les fichiers journaux du serveur web.
- Sources de données en temps réel, telles que les appareils IoT.
stockage de données: les données pour les opérations de traitement par lots sont généralement stockées dans un magasin de fichiers distribué qui peut contenir des volumes élevés de fichiers volumineux dans différents formats. Ce type de magasin est souvent appelé data lake. Les options d’implémentation de ce stockage incluent Azure Data Lake Store ou des conteneurs d’objets blob dans Stockage Azure.
traitement par lots: étant donné que les jeux de données sont si volumineux, souvent une solution Big Data doit traiter les fichiers de données à l’aide de travaux batch de longue durée pour filtrer, agréger et préparer les données à des fins d’analyse. En règle générale, ces travaux impliquent la lecture de fichiers sources, leur traitement et l’écriture de la sortie dans de nouveaux fichiers. Les options incluent l’utilisation de dataflows, de pipelines de données dans Microsoft Fabric.
l’ingestion de messages en temps réel: si la solution inclut des sources en temps réel, l’architecture doit inclure un moyen de capturer et de stocker des messages en temps réel pour le traitement de flux. Il peut s’agir d’un magasin de données simple, où les messages entrants sont supprimés dans un dossier pour traitement. Toutefois, de nombreuses solutions ont besoin d’un magasin d’ingestion de messages pour agir comme mémoire tampon pour les messages et de prendre en charge le traitement avec montée en puissance parallèle, la remise fiable et d’autres sémantiques de mise en file d’attente de messages. Les options incluent Azure Event Hubs, Azure IoT Hubs et Kafka.
traitement de flux: après avoir capturé des messages en temps réel, la solution doit les traiter en filtrant, en les agrégeant et en préparant les données à des fins d’analyse. Les données de flux traitées sont ensuite écrites dans un récepteur de sortie. Azure Stream Analytics fournit un service de traitement de flux managé basé sur l’exécution perpétuelle de requêtes SQL qui fonctionnent sur des flux non liés. Une autre option consiste à utiliser l’intelligence en temps réel dans Microsoft Fabric, ce qui vous permet d’exécuter des requêtes KQL lorsque les données sont ingérées.
magasin de données analytiques: de nombreuses solutions Big Data préparent les données pour l’analyse, puis servent les données traitées dans un format structuré qui peut être interrogé à l’aide d’outils analytiques. Le magasin de données analytiques utilisé pour répondre à ces requêtes peut être un entrepôt de données relationnelles de style Kimball, comme indiqué dans la plupart des solutions décisionnels (BI) traditionnelles ou un lakehouse avec architecture de médaillon (Bronze, Silver et Gold). Azure Synapse Analytics fournit un service managé pour l’entreposage de données à grande échelle basé sur le cloud. Vous pouvez également interroger Microsoft Fabric à l’aide de SQL et spark respectivement.
d’analyse et de création de rapports : l’objectif de la plupart des solutions Big Data consiste à fournir des insights sur les données via l’analyse et la création de rapports. Pour permettre aux utilisateurs d’analyser les données, l’architecture peut inclure une couche de modélisation des données, telle qu’un cube OLAP multidimensionnel ou un modèle de données tabulaire dans Azure Analysis Services. Il peut également prendre en charge le décisionnel en libre-service, à l’aide des technologies de modélisation et de visualisation dans Microsoft Power BI ou Microsoft Excel. L’analyse et la création de rapports peuvent également prendre la forme d’une exploration interactive des données par des scientifiques des données ou des analystes de données. Pour ces scénarios, Microsoft Fabric vous fournit des outils tels que des notebooks où l’utilisateur peut choisir SQL ou un langage de programmation de son choix.
Orchestration: la plupart des solutions Big Data consistent en opérations répétées de traitement des données, encapsulées dans des flux de travail, qui transforment les données sources, déplacent des données entre plusieurs sources et récepteurs, chargent les données traitées dans un magasin de données analytique ou poussent les résultats directement vers un rapport ou un tableau de bord. Pour automatiser ces flux de travail, vous pouvez utiliser une technologie d’orchestration telle qu’Azure Data Factory ou des pipelines Microsoft Fabric.
Azure inclut de nombreux services qui peuvent être utilisés dans une architecture Big Data. Ils se répartissent approximativement en deux catégories :
- Services managés, notamment Microsoft Fabric, Azure Data Lake Store, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub et Azure Data Factory.
- Technologies open source basées sur la plateforme Apache Hadoop, notamment HDFS, HBase, Hive, Spark et Kafka. Ces technologies sont disponibles sur Azure dans le service Azure HDInsight.
Ces options ne sont pas mutuellement exclusives et de nombreuses solutions combinent des technologies open source avec des services Azure.
Quand utiliser cette architecture
Tenez compte de ce style d’architecture lorsque vous devez :
- Stockez et traitez les données dans des volumes trop volumineux pour une base de données traditionnelle.
- Transformez des données non structurées pour l’analyse et la création de rapports.
- Capturez, traitez et analysez des flux de données non liés en temps réel ou avec une faible latence.
- Utilisez Azure Machine Learning ou Azure Cognitive Services.
Avantages
- choix technologiques. Vous pouvez combiner et mettre en correspondance les services managés Azure et les technologies Apache dans les clusters HDInsight pour tirer parti des compétences ou des investissements technologiques existants.
- Performances par le biais du parallélisme. Les solutions Big Data tirent parti du parallélisme, ce qui permet des solutions hautes performances qui s’adaptent à de grands volumes de données.
- d’échelle élastique . Tous les composants de l’architecture Big Data prennent en charge l’approvisionnement avec montée en puissance parallèle, afin que vous puissiez ajuster votre solution à des charges de travail petites ou volumineuses et payer uniquement pour les ressources que vous utilisez.
- Interopérabilité avec les solutions existantes. Les composants de l’architecture Big Data sont également utilisés pour le traitement IoT et les solutions décisionnels d’entreprise, ce qui vous permet de créer une solution intégrée entre les charges de travail de données.
Défis
- complexité. Les solutions Big Data peuvent être extrêmement complexes, avec de nombreux composants pour gérer l’ingestion des données à partir de plusieurs sources de données. Il peut s’avérer difficile de créer, de tester et de dépanner des processus Big Data. De plus, il peut y avoir un grand nombre de paramètres de configuration sur plusieurs systèmes qui doivent être utilisés pour optimiser les performances.
- Skillset. De nombreuses technologies Big Data sont hautement spécialisées et utilisent des frameworks et des langages qui ne sont pas typiques des architectures d’application plus générales. D’autre part, les technologies Big Data évoluent de nouvelles API qui s’appuient sur des langages plus établis.
- maturité technologique. De nombreuses technologies utilisées dans le Big Data évoluent. Bien que les technologies Hadoop de base telles que Hive et Spark se stabilisent, les technologies émergentes telles que delta ou iceberg introduisent des changements et des améliorations considérables. Les services managés tels que Microsoft Fabric sont relativement jeunes, comparés à d’autres services Azure, et évolueront probablement au fil du temps.
- de sécurité . Les solutions Big Data s’appuient généralement sur le stockage de toutes les données statiques dans un lac de données centralisé. La sécurisation de l’accès à ces données peut être difficile, en particulier lorsque les données doivent être ingérées et consommées par plusieurs applications et plateformes.
Meilleures pratiques
tirer parti du parallélisme. La plupart des technologies de traitement big data distribuent la charge de travail entre plusieurs unités de traitement. Cela nécessite que les fichiers de données statiques soient créés et stockés dans un format fractionné. Les systèmes de fichiers distribués tels que HDFS peuvent optimiser les performances de lecture et d’écriture, et le traitement réel est effectué par plusieurs nœuds de cluster en parallèle, ce qui réduit les temps de travail globaux. L’utilisation du format de données fractionnable est fortement recommandée, comme Parquet.
partitionner des données. Le traitement par lots se produit généralement selon une planification périodique, par exemple, hebdomadaire ou mensuelle. Partitionnez des fichiers de données et des structures de données, telles que des tables, en fonction de périodes temporelles qui correspondent à la planification de traitement. Cela simplifie l’ingestion des données et la planification des travaux, ce qui facilite la résolution des défaillances. En outre, le partitionnement de tables utilisées dans les requêtes Hive, Spark ou SQL peut améliorer considérablement les performances des requêtes.
Appliquer la sémantique de lecture de schéma. L’utilisation d’un lac de données vous permet de combiner le stockage pour les fichiers dans plusieurs formats, qu’ils soient structurés, semi-structurés ou non structurés. Utilisez sémantique de de schéma en lecture, qui projettent un schéma sur les données lorsque les données sont traitées, et non lorsque les données sont stockées. Cela génère de la flexibilité dans la solution et empêche les goulots d’étranglement lors de l’ingestion des données causées par la validation des données et la vérification de type.
Traiter des données sur place. Les solutions BI traditionnelles utilisent souvent un processus d’extraction, de transformation et de chargement (ETL) pour déplacer des données dans un entrepôt de données. Avec des volumes plus volumineux et un plus grand nombre de formats, les solutions Big Data utilisent généralement des variantes d’ETL, telles que la transformation, l’extraction et la charge (TEL). Avec cette approche, les données sont traitées dans le magasin de données distribué, en les transformant en structure requise, avant de déplacer les données transformées dans un magasin de données analytique.
équilibrer l’utilisation et les coûts de temps. Pour les travaux de traitement par lots, il est important de prendre en compte deux facteurs : le coût par unité des nœuds de calcul et le coût par minute d’utilisation de ces nœuds pour terminer le travail. Par exemple, un travail de traitement par lots peut prendre huit heures avec quatre nœuds de cluster. Toutefois, il peut arriver que le travail utilise les quatre nœuds uniquement pendant les deux premières heures, et après cela, seuls deux nœuds sont requis. Dans ce cas, l’exécution de l’ensemble du travail sur deux nœuds augmenterait le temps total du travail, mais ne le doublerait pas, de sorte que le coût total serait inférieur. Dans certains scénarios métier, un temps de traitement plus long peut être préférable au coût plus élevé d’utilisation de ressources de cluster sous-utilisées.
Les ressources distinctes. Dans la mesure du possible, visez à séparer les ressources en fonction des charges de travail pour éviter des scénarios tels qu’une charge de travail utilisant toutes les ressources pendant que l’autre attend.
Orchestrer l’ingestion des données. Dans certains cas, les applications métier existantes peuvent écrire des fichiers de données pour le traitement par lots directement dans des conteneurs d’objets blob de stockage Azure, où elles peuvent être consommées par des services en aval comme Microsoft Fabric. Toutefois, vous devez souvent orchestrer l’ingestion des données à partir de sources de données locales ou externes dans le lac de données. Utilisez un workflow d’orchestration ou un pipeline, tel que ceux pris en charge par Azure Data Factory ou Microsoft Fabric, pour y parvenir de manière prévisible et centralisée.
nettoyer les données sensibles tôt. Le flux de travail d’ingestion des données doit traiter les données sensibles dès le début du processus, afin d’éviter de les stocker dans le lac de données.
Architecture IoT
Internet des objets (IoT) est un sous-ensemble spécialisé de solutions Big Data. Le diagramme suivant montre une architecture logique possible pour IoT. Le diagramme met en évidence les composants de streaming d’événements de l’architecture.
diagramme 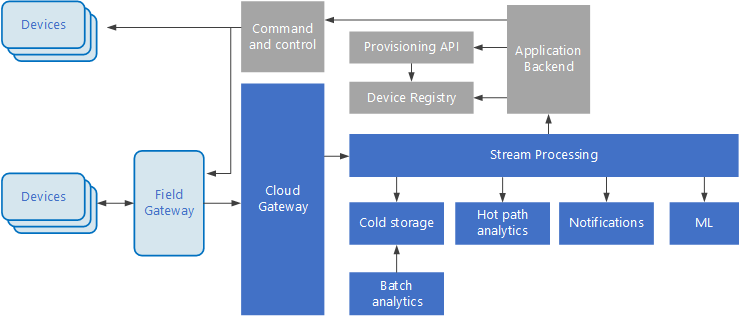
La passerelle cloud ingère des événements d’appareil au niveau de la limite cloud, à l’aide d’un système de messagerie fiable et à faible latence.
Les appareils peuvent envoyer des événements directement à la passerelle cloud, ou via une passerelle de champ . Une passerelle de champ est un appareil ou un logiciel spécialisé, généralement colocalisé avec les appareils, qui reçoit des événements et les transfère à la passerelle cloud. La passerelle de champ peut également prétraiter les événements d’appareil bruts, en effectuant des fonctions telles que le filtrage, l’agrégation ou la transformation de protocole.
Après l’ingestion, les événements passent par un ou plusieurs processeurs de flux qui peuvent acheminer les données (par exemple, vers le stockage) ou effectuer des analyses et d’autres traitements.
Voici quelques types courants de traitement. (Cette liste n’est certainement pas exhaustive.)
Écriture de données d’événement dans le stockage à froid, pour l’archivage ou l’analytique par lots.
Analyse des chemins d’accès chauds, analyse du flux d’événements en temps réel (proche) pour détecter les anomalies, reconnaître les modèles sur les fenêtres de temps propagé ou déclencher des alertes lorsqu’une condition spécifique se produit dans le flux.
Gestion de types spéciaux de messages non de télémétrie à partir d’appareils, tels que les notifications et les alarmes.
Apprentissage automatique.
Les zones qui sont gris ombrées affichent les composants d’un système IoT qui ne sont pas directement liés à la diffusion en continu d’événements, mais sont inclus ici pour obtenir l’exhaustivité.
Le registre d’appareils est une base de données des appareils approvisionnés, y compris les ID d’appareil et généralement les métadonnées de l’appareil, telles que l’emplacement.
L’API d’approvisionnement est une interface externe commune pour l’approvisionnement et l’inscription de nouveaux appareils.
Certaines solutions IoT permettent d’envoyer des messages de commande et de contrôle aux appareils.
Cette section a présenté une vue très générale de l’IoT, et il existe de nombreuses subtilités et défis à prendre en compte. Pour plus d’informations, consultez architectures IoT.