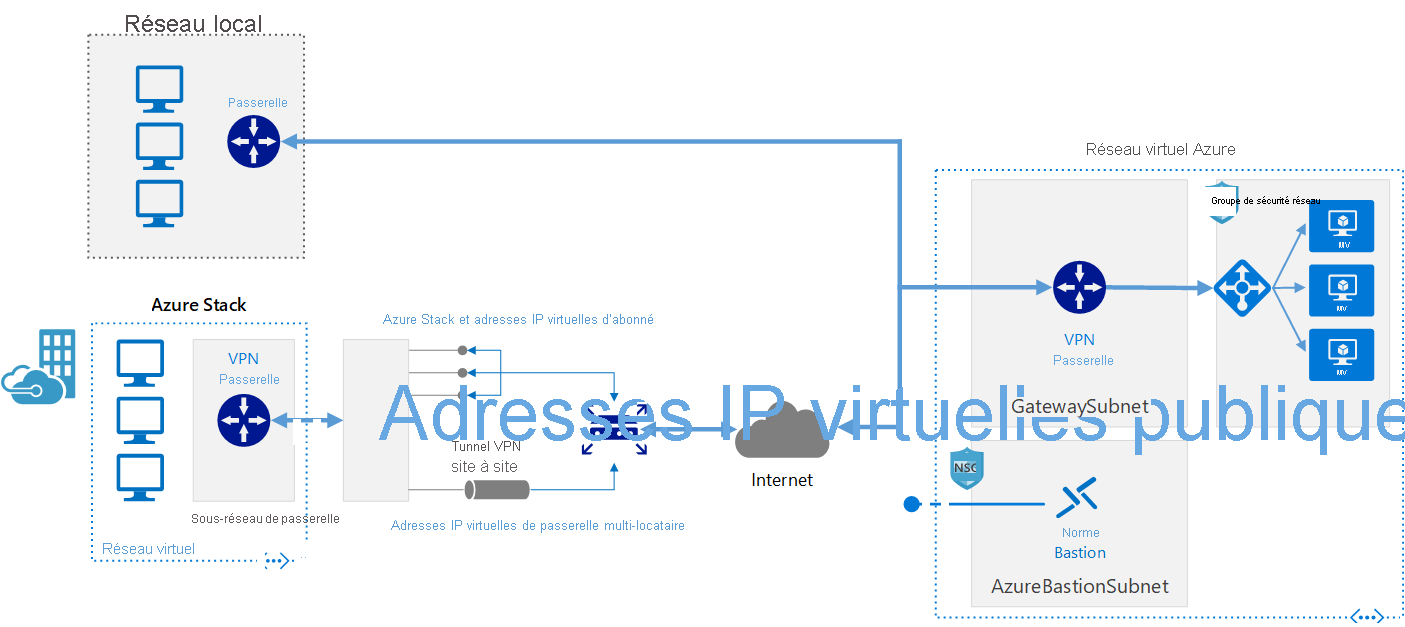
Connecter un réseau local à Azure à l’aide d’une passerelle VPN
Cette architecture de référence montre comment étendre un réseau local à Azure à l’aide d’un réseau privé virtuel (VPN) site à site.
Ce navigateur n’est plus pris en charge.
Effectuez une mise à niveau vers Microsoft Edge pour tirer parti des dernières fonctionnalités, des mises à jour de sécurité et du support technique.
Le calcul haute performance (HPC, High Performance Computing), également appelé Big Compute, utilise un grand nombre d’ordinateurs basés sur processeur ou GPU pour résoudre des tâches mathématiques complexes.
De nombreux secteurs d’activité utilisent HPC pour résoudre certains de leurs problèmes les plus complexes. Ces problèmes incluent notamment des charges de travail telles que les suivantes :
L’une des principales différences entre un système HPC local et un système HPC dans le cloud est la possibilité d’ajouter et de supprimer de façon dynamique des ressources en fonction des besoins. La mise à l’échelle dynamique supprime la capacité de calcul comme goulot d’étranglement et, à la place, permet aux clients de trouver la taille adaptée pour leur infrastructure pour satisfaire les exigences de leurs travaux.
Les articles suivants fournissent davantage de détails sur cette fonctionnalité de mise à l’échelle dynamique.
Comme vous cherchez à implémenter votre propre solution HPC sur Azure, vérifiez que vous avez consulté les rubriques suivantes :
De nombreux composants d’infrastructure sont nécessaires à la génération d’un système HPC. Calcul, stockage et réseau fournissent les composants sous-jacents, quelle que soit la façon dont vous choisissez de gérer vos charges de travail HPC.
Azure propose une gamme de tailles qui sont optimisées pour les charges de travail intensives processeur et GPU.
Les machines virtuelles de série N comportent des processeurs graphiques NVIDIA conçus pour des applications graphiques ou de calcul nécessitant beaucoup de ressources système, y compris la visualisation et l’apprentissage de l’intelligence artificielle (AI).
Les charges de travail HPC et Batch à grande échelle nécessitent un stockage des données et un accès à ces dernières dépassant les capacités des systèmes de fichiers cloud classiques. De nombreuses solutions permettent de gérer les besoins de vitesse et de capacité des applications HPC sur Azure.
Pour plus d’informations sur la comparaison de Lustre, de GlusterFS et de BeeGFS sur Azure, consultez le livre électronique Systèmes de fichiers parallèles sur Azure et le blog Lustre on Azure.
Les machines virtuelles H16r, H16mr, A8 et A9 peuvent se connecter à un réseau RDMA back-end à débit élevé. Ce réseau peut améliorer les performances d’applications parallèles étroitement liées s’exécutant sous l’interface de passage de messages Microsoft, plus connue sous le nom de MPI ou Intel MPI.
La génération d’un système HPC à partir de zéro sur Azure offre une grande flexibilité, mais elle nécessite souvent beaucoup de maintenance.
Si vous avez un système HPC local existant que vous voulez connecter à Azure, il existe plusieurs ressources pour vous aider à commencer.
Tout d’abord, consultez l’article Options pour la connexion d’un réseau local à Azure de la documentation. Vous y trouverez des informations supplémentaires sur ces options de connectivité :
Cette architecture de référence montre comment étendre un réseau local à Azure à l’aide d’un réseau privé virtuel (VPN) site à site.
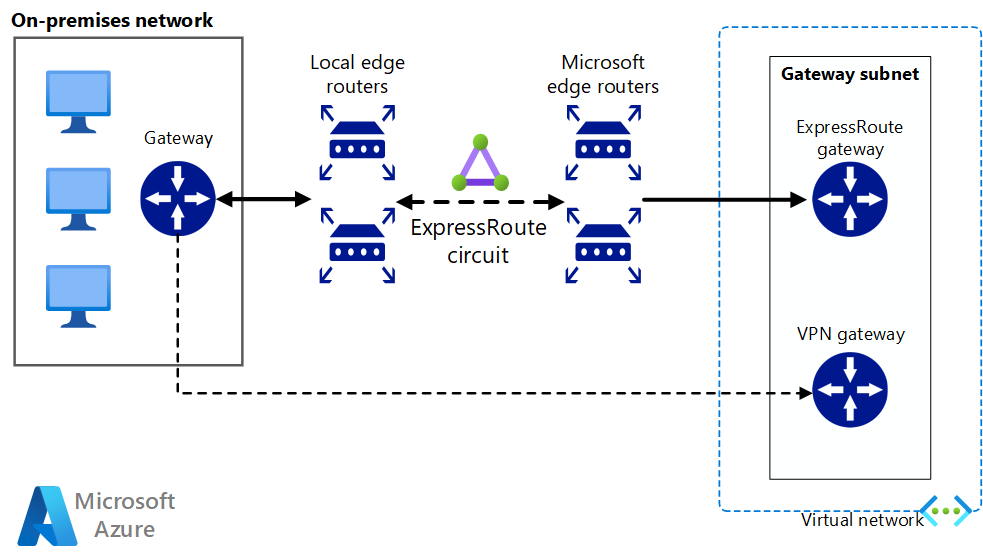
Implémentez une architecture réseau de site à site sécurisée et hautement disponible qui s’étend sur un réseau virtuel Azure et un réseau local connecté à l’aide d’ExpressRoute avec basculement de passerelle VPN.
Une fois la connectivité réseau établie de manière sécurisée, vous pouvez commencer à utiliser des ressources de calcul cloud à la demande avec les fonctionnalités d’éclatement de votre gestionnaire de charges de travail existant.
De nombreux gestionnaires de charges de travail sont proposés dans la Place de marché Azure.
Azure Batch est un service de plateforme qui permet d’exécuter efficacement des applications HPC en parallèle et à grande échelle dans le cloud. Azure Batch planifie les travaux nécessitant une grande quantité de ressources système à exécuter sur un pool géré de machines virtuelles. Il peut mettre automatiquement à l’échelle les ressources de calcul pour répondre aux besoins de vos travaux.
Les fournisseurs et développeurs SaaS peuvent utiliser les outils et kits de développement logiciel (SDK) pour intégrer des applications HPC ou des charges de travail de conteneur dans Azure, stocker des données dans Azure et générer des pipelines d’exécution du travail.
Dans Azure Batch, tous les services s’exécutent dans le cloud, l’image ci-dessous montre à quoi ressemble l’architecture avec Azure Batch, dont la scalabilité et les configurations de planification des travaux s’exécutent dans le cloud, tandis que les résultats et les rapports peuvent être envoyés dans votre environnement local.

Azure CycleCloud La manière la plus simple de gérer les charges de travail HPC à l’aide d’un planificateur (tel que Slurm, Grid Engine, HPC Pack, HTCondor, LSF, PBS Pro ou Symphony), sur Azure
CycleCloud vous permet d’effectuer les opérations suivantes :
Dans cet exemple de diagramme hybride, nous pouvons clairement voir comment ces services sont distribués entre le cloud et l’environnement local. Possibilité d’exécuter des travaux dans les deux charges de travail.

L’exemple de diagramme d’un modèle natif cloud ci-dessous montre comment la charge de travail gère tout dans le cloud tout en conservant la connexion à l’environnement local.

| Fonctionnalité | Azure Batch | Azure CycleCloud |
|---|---|---|
| Scheduler | API et outils batch et scripts de ligne de commande dans le portail Azure (natif cloud). | Utilisez des planificateurs HPC standard tels que Slurm, PBS Pro, LSF, Grid Engine et HTCondor, ou étendez les plug-ins de mise à l’échelle automatique CycleCloud pour travailler avec votre propre planificateur. |
| Ressources de calcul | Nœuds Software as a service – Platform as a service | Logiciel Platform as a service – Platform as a service |
| Outils d’analyse | Azure Monitor | Azure Monitor, Grafana |
| Personnalisation | Pools d’images personnalisés, images de tiers, accès à l’API Batch. | Utiliser l’API complète RESTful pour personnaliser et étendre des fonctionnalités, déployer votre propre planificateur et prendre en charge les gestionnaires de charges de travail existants |
| Intégration | Synapse Pipelines, Azure Data Factory, Azure CLI | CLI intégré pour Windows et Linux |
| Type d’utilisateur | Développeurs | Administrateurs et utilisateurs HPC classiques |
| Type de travail | Batch, Workflows | Fortement couplé (interface de passage de messages/MPI). |
| Prise en charge de Windows | Oui | Varie, selon le choix du planificateur |
Voici quelques exemples de cluster et de gestionnaires de charges de travail qui peuvent s’exécuter dans une architecture Azure. Créer des clusters autonomes dans des machines virtuelles Azure ou effectuez un burst dans les machines virtuelles Azure depuis un cluster local.
Les conteneurs peuvent également être utilisés pour gérer certaines charges de travail HPC. Des services comme Azure Kubernetes Service (AKS) simplifie le déploiement d’un cluster Kubernetes managé dans Azure.
Il existe différentes manières de gérer vos coûts HPC sur Azure. Vérifiez que vous avez consulté les options d’achat Azure afin de trouver la méthode qui convient le mieux à votre organisation.
Pour obtenir une vue d’ensemble des bonnes pratiques de sécurité sur Azure, consultez la documentation sur la sécurité Azure.
Outre les configurations réseau disponibles dans la section Cloud bursting, vous pouvez implémenter une configuration hub/spoke pour isoler vos ressources de calcul :

Le hub est un réseau virtuel (VNet) dans Azure qui centralise la connectivité à votre réseau local. Les rayons (spokes) sont des réseaux virtuels qui s’homologuent avec le hub et qui peuvent être utilisés pour isoler les charges de travail.
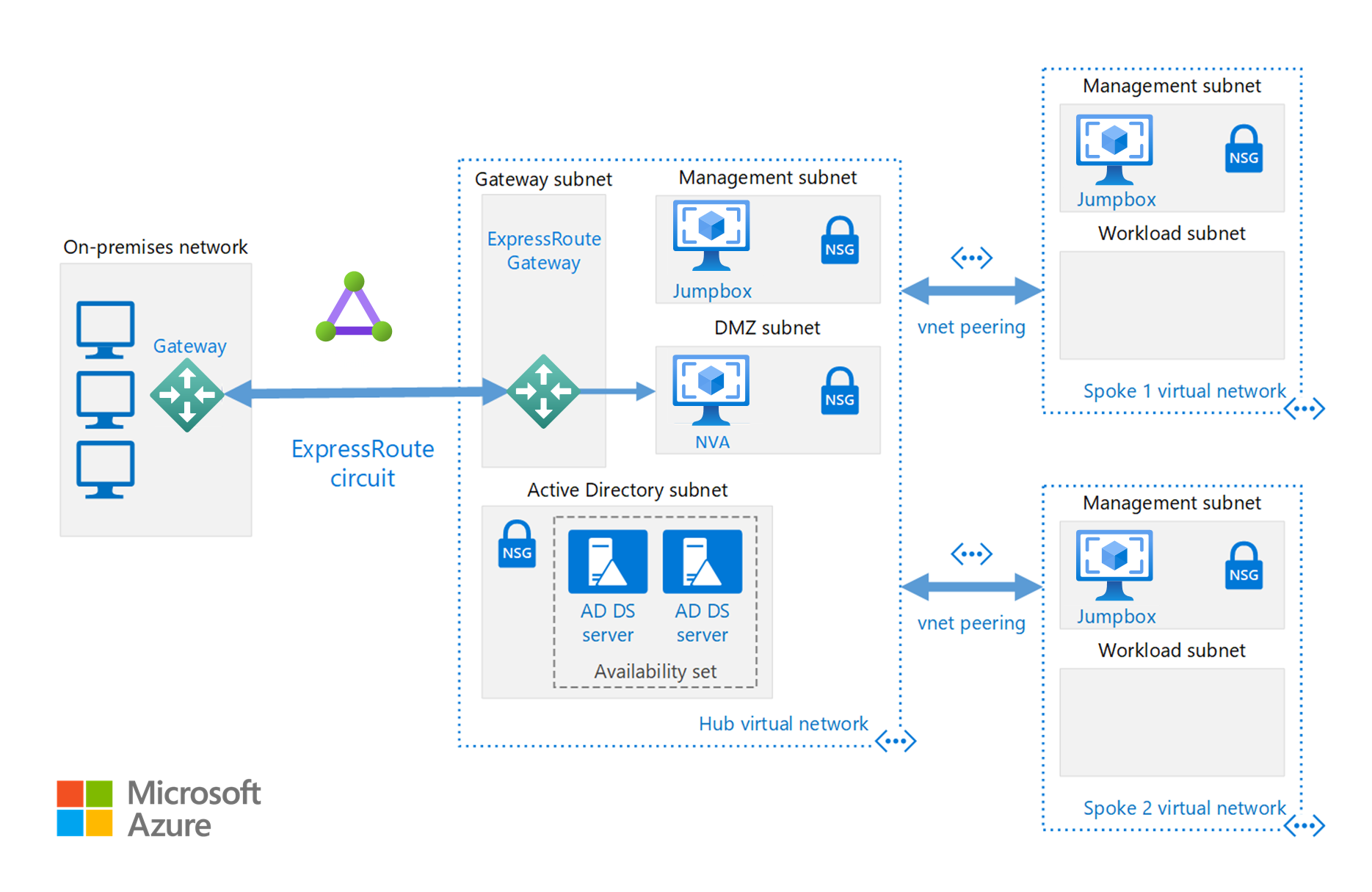
Cette architecture de référence s’appuie sur l’architecture de référence hub-and-spoke de manière à inclure dans le hub des services partagés qui peuvent être utilisés par tous les spokes.
Exécuter des applications HPC commerciales ou personnalisées dans Azure. Plusieurs exemples dans cette section ont été testés et se montrent efficaces pour la mise à l’échelle avec des machines virtuelles ou des cœurs de calcul supplémentaires. Visitez la Place de marché Azure pour obtenir des solutions prêtes au déploiement.
Notes
Vérifiez auprès du fournisseur de toute application commerciale les questions de licence ou toute autre restriction relative à l’exécution dans le cloud. Tous les fournisseurs ne proposent pas le paiement à l'utilisation pour les licences. Vous aurez peut-être besoin d’un serveur de licences dans le cloud pour votre solution ou de vous connecter à un serveur de licences sur site.
Exécutez des machines virtuelles alimentées par GPU dans Azure dans la même région que la sortie HPC pour bénéficier de la plus faible latence, d'un accès et pour visualiser à distance via Azure Virtual Desktop.
Un grand nombre de clients ont connu beaucoup de succès grâce à l’utilisation d’Azure pour leurs charges de travail HPC. Voici quelques-unes de ces études de cas clients :
Pour obtenir les dernières annonces, consultez les ressources suivantes :
Les tutoriels suivants vous fourniront des informations détaillées sur l’exécution d’applications sur Microsoft Batch :
