Cet article décrit une architecture qui utilise Azure Machine Learning pour prédire les probabilités de défaut de paiement des demandeurs de prêt. Les prédictions du modèle sont basées sur le comportement fiscal du demandeur. Le modèle utilise un vaste ensemble de points de données pour classer les candidats et fournir un score d’éligibilité pour chaque candidat.
Apache®, Spark et le logo représentant une flamme sont des marques déposées ou des marques commerciales d’Apache Software Foundation aux États-Unis et/ou dans d’autres pays. L’utilisation de ces marques n’implique aucune approbation de l’Apache Software Foundation.
Architecture

Téléchargez un fichier Visio de cette architecture.
Dataflow
Le flux de données suivant correspond au diagramme précédent :
Stockage : les données sont stockées dans une base de données comme un pool Azure Synapse Analytics si elle est structurée. Les bases de données SQL plus anciennes peuvent être intégrées au système. Les données semi-structurées et non structurées peuvent être chargées dans un lac de données.
Ingestion et prétraitement : Les pipelines de traitement Azure Synapse Analytics et le traitement par extraction, transformation et chargement (ETL) peuvent se connecter aux données stockées dans Azure ou à des sources tierces via des connecteurs intégrés. Azure Synapse Analytics prend en charge plusieurs méthodologies d’analyse qui utilisent SQL, Spark, Azure Data Explorer et Power BI. Vous pouvez également utiliser l’orchestration Azure Data Factory existante pour les pipelines de données.
Traitement : Azure Machine Learning est utilisé pour développer et gérer les modèles Machine Learning.
Traitement initial : au cours de cette étape, les données brutes sont traitées pour créer un jeu de données organisé qui entraîne un modèle Machine Learning. Les opérations classiques incluent la mise en forme de type de données, l’imputation des valeurs manquantes, l’ingénierie de caractéristiques, la sélection des caractéristiques et la réduction de la dimensionnalité.
Apprentissage : pendant la phase d’apprentissage, Azure Machine Learning utilise le jeu de données traité pour entraîner le modèle de risque de crédit et sélectionner le meilleur modèle.
Entraînement de modèle : vous pouvez utiliser une gamme de modèles Machine Learning, y compris des modèles d’apprentissage automatique classiques et de Deep Learning. Vous pouvez utiliser l’optimisation des hyperparamètres pour optimiser les performances du modèle.
Évaluation du modèle : Azure Machine Learning évalue les performances de chaque modèle entraîné afin que vous puissiez sélectionner le meilleur pour le déploiement.
Inscription de modèle : vous inscrivez le modèle qui fonctionne le mieux dans Azure Machine Learning. Cette étape rend le modèle disponible pour le déploiement.
IA responsable : l’IA responsable est une approche du développement, de l’évaluation et du déploiement de systèmes IA de façon sûre, fiable et éthique. Étant donné que ce modèle déduit une décision d’approbation ou de refus pour une demande de prêt, vous devez implémenter les principes de l’IA responsable.
Les métriques d’impartialité évaluent l’effet d’un comportement injuste et permettent des stratégies d’atténuation. Les caractéristiques et attributs sensibles sont identifiés dans le jeu de données et dans les cohortes (sous-ensembles) des données. Pour plus d’informations, consultez Performances et impartialité du modèle.
L’interprétabilité est une mesure de la façon dont vous pouvez comprendre le comportement d’un modèle Machine Learning. Ce composant de l’IA responsable génère des descriptions compréhensibles par l’homme des prédictions du modèle. Pour plus d’informations, consultez Interprétabilité du modèle.
Déploiement de Machine Learning en temps réel : vous devez utiliser l’inférence de modèle en temps réel lorsque la demande doit être examinée immédiatement pour approbation.
- Point de terminaison en ligne de Machine Learning managé. Pour le scoring en temps réel, vous devez choisir une cible de calcul appropriée.
- Les demandes de prêts en ligne utilisent un scoring en temps réel basé sur les données du formulaire du demandeur ou de la demande de prêt.
- La décision et l’entrée utilisée pour le scoring du modèle sont stockées dans le stockage persistant et peuvent être récupérées pour référence ultérieure.
Déploiement de Machine Learning par lots : pour le traitement des prêts hors connexion, le modèle est planifié pour être déclenché à intervalles réguliers.
- Point de terminaison de lot managé. L’inférence par lots est planifiée et le jeu de données de résultat est créé. Les décisions sont basées sur la solvabilité du demandeur.
- L’ensemble de résultats du scoring du traitement par lots est conservé dans la base de données ou l’entrepôt de données Azure Synapse Analytics.
Interface avec les données relatives à l’activité du demandeur : les informations saisies par le demandeur, le profil de crédit interne et la décision du modèle sont toutes intermédiaires et stockées dans les services de données appropriés. Ces détails sont utilisés dans le moteur de décision pour le scoring futur. Ils sont donc documentés.
- Stockage : tous les détails du traitement du crédit sont conservés dans le stockage persistant.
- Interface utilisateur : la décision d’approbation ou de refus est présentée au demandeur.
Rapports : les informations en temps réel sur le nombre de demandes traitées et les résultats d’approbation ou de refus sont présentées en permanence aux managers et aux dirigeants. Parmi les exemples de rapports, citons les rapports en quasi-temps réel des montants approuvés, le portefeuille de prêts créé et les performances du modèle.
Composants
- Stockage Blob Azure est une solution de stockage d’objets évolutive pour les données non structurées. Il est optimisé pour le stockage de fichiers tels que des fichiers binaires, des journaux d’activité et des fichiers qui n’adhèrent pas à un format spécifique.
- Azure Data Lake Storage est la base de stockage pour créer des lacs de données rentables sur Azure. Il fournit un stockage d’objets blob avec une structure de dossiers hiérarchique et des performances, une gestion et une sécurité améliorées. Il traite plusieurs pétaoctets d’informations tout en maintenant un débit de plusieurs centaines de gigabits.
- Azure Synapse Analytics est un service d’analytique qui regroupe les meilleures technologies SQL et Spark et une expérience utilisateur unifiée pour l’exploration et les pipelines de données. Il s’intègre à Power BI, Azure Cosmos DB et Azure Machine Learning. Le service prend en charge les modèles de ressources dédiés et serverless et la possibilité de basculer entre ces modèles.
- Azure SQL Database est une base de données relationnelle toujours à jour et complètement managée, conçue pour le cloud.
- Azure Machine Learning est un service cloud permettant de gérer les cycles de vie des projets de Machine Learning. Il fournit un environnement intégré pour l’exploration des données, la création et la gestion des modèles et le déploiement, et prend en charge les approches code-first et low-code/no-code pour le Machine Learning.
- Power BI est un outil de visualisation qui offre une intégration facile aux ressources Azure.
- Azure App Service vous permet de créer et d’héberger des applications web, des back ends mobiles et des API RESTful sans gérer l’infrastructure. Les langages pris en charge incluent .NET, .NET Core, Java, Ruby, Node.js, PHP et Python.
Autres solutions
Vous pouvez utiliser Azure Databrickspour développer, déployer et gérer des modèles Machine Learning et des charges de travail d’analyse. Le service fournit un environnement unifié pour le développement de modèles.
Détails du scénario
Les organisations du secteur financier doivent prédire le risque de crédit des individus ou des entreprises qui sollicitent un crédit. Ce modèle évalue les probabilités de défaut de paiement des demandeurs de prêt.
La prédiction du risque de crédit implique une analyse approfondie du comportement de la population et la classification de la base de clients en segments en fonction de la responsabilité financière. D’autres variables incluent les facteurs du marché et les conditions économiques, qui ont une influence significative sur les résultats.
Défis. Les données d’entrée incluent des dizaines de millions de profils clients et des données sur le comportement des clients en matière de crédit et les habitudes de dépense basées sur des milliards d’enregistrements provenant de systèmes disparates, tels que les systèmes d’activité client internes. Les données tierces sur les conditions économiques et l’analyse du marché du pays/de la région peuvent provenir d’instantanés mensuels ou trimestriels qui nécessitent le chargement et la maintenance de centaines de gigaoctets de fichiers. Des informations du bureau de crédit sur le demandeur ou des lignes semi-structurées de données client, ainsi que des jointures croisées entre ces jeux de données et des vérifications de qualité pour valider l’intégrité des données, sont nécessaires.
Les données se composent généralement de tables à colonnes larges d’informations sur les clients provenant des bureaux de crédit, ainsi que d’une analyse du marché. L’activité du client se compose d’enregistrements avec une disposition dynamique qui peut ne pas être structurée. Les données sont également disponibles en texte libre à partir des notes du service clientèle et des formulaires d’interaction avec le demandeur.
Le traitement de ces grands volumes de données et la vérification de la mise à jour des résultats nécessitent un traitement simplifié. Vous avez besoin d’un processus de stockage et de récupération à faible latence. L’infrastructure de données doit pouvoir être mise à l’échelle pour prendre en charge des sources de données disparates et fournir la possibilité de gérer et de sécuriser le périmètre de données. La plateforme de Machine Learning doit prendre en charge l’analyse complexe des nombreux modèles entraînés, testés et validés sur de nombreux segments de population.
Confidentialité des données. Le traitement des données pour ce modèle implique des données personnelles et des détails démographiques. Vous devez éviter le profilage des populations. La visibilité directe de toutes les données personnelles doit être restreinte. Parmi les exemples de données personnelles, citons les numéros de compte, les détails des cartes de crédit, les numéros de sécurité sociale, les noms, les adresses et les codes postaux.
Les cartes de crédit et les numéros de comptes bancaires doivent toujours être obfusqués. Certains éléments de données doivent être masqués et toujours chiffrés, ce qui ne fournit aucun accès aux informations sous-jacentes, mais permet leur analyse.
Les données doivent être chiffrées au repos, en transit et pendant le traitement via des enclaves sécurisées. L’accès aux éléments de données est enregistré dans une solution de monitoring. Le système de production doit être configuré avec des pipelines CI/CD appropriés avec des approbations qui déclenchent des déploiements et des processus de modèle. L’audit des journaux et du workflow doit fournir les interactions avec les données pour tous les besoins de conformité.
Traitement : Ce modèle nécessite une puissance de calcul élevée pour l’analyse, la contextualisation et l’entraînement et le déploiement du modèle. Le scoring du modèle est validé sur des échantillons aléatoires pour s’assurer que les décisions de crédit n’incluent pas de biais de race, de sexe, d’origine ethnique ni de localisation géographique. Le modèle de décision doit être documenté et archivé pour référence ultérieure. Chaque facteur impliqué dans les résultats de la décision est stocké.
Le traitement des données nécessite une utilisation élevée du processeur. Il comprend le traitement SQL des données structurées au format DB et JSON, le traitement Spark des trames de données ou l’analyse Big Data sur des téraoctets d’informations dans différents formats de document. Les tâches d'extraction, chargement et transformation des données (ELT)/ETL sont programmées ou déclenchées à intervalles réguliers ou en temps réel, en fonction de la valeur des données les plus récentes.
Infrastructure de conformité et réglementaire. Chaque détail du traitement du prêt doit être documenté, y compris l’application soumise, les fonctionnalités utilisées dans le scoring du modèle et le jeu de résultats du modèle. Les informations d’entraînement des modèles, les données utilisées pour l’entraînement et les résultats de l’entraînement doivent être enregistrés pour les demandes de référence et d’audit et de conformité futures.
Scoring par lots et en temps réel. Certaines tâches sont proactives et peuvent être traitées en tant que travaux par lots, comme les transferts de solde préapprouvés. Certaines demandes, comme les augmentations de la ligne de crédit en ligne, nécessitent une approbation en temps réel.
L’accès en temps réel à l’état des demandes de prêt en ligne doit être disponible pour le demandeur. L’institution financière émettrice de prêts supervise en permanence les performances du modèle de crédit et a besoin d’informations sur des mesures telles que les états d’approbation des prêts, le nombre de prêts approuvés, les montants en dollars émis et la qualité des nouveaux prêts.
Intelligence artificielle responsable
Le tableau de bord de l’IA responsable fournit une interface unique pour plusieurs outils qui peuvent vous aider à implémenter une IA responsable. La norme d’IA responsable repose sur six principes :
Impartialité et inclusivité dans Azure Machine Learning. Ce composant du tableau de bord de l’IA responsable vous aide à évaluer les comportements injustes en évitant les effets néfastes en matière d’allocation et de qualité de service. Vous pouvez l’utiliser pour évaluer l’impartialité entre les groupes sensibles définis en termes de sexe, d’âge, d’origine ethnique et d’autres caractéristiques. Pendant la phase d’évaluation, l’impartialité est quantifiée à l’aide de mesures de disparité. Vous devez implémenter les algorithmes d’atténuation dans le package open source Fairlearn, qui utilisent des contraintes de parité.
Fiabilité et sécurité dans Azure Machine Learning. Le composant d’analyse des erreurs de l’IA responsable peut vous aider à :
- Comprendre de manière approfondie comment l’échec est distribué pour un modèle.
- Identifier les cohortes de données avec un taux d’erreur supérieur au taux d’erreur de référence global
Transparence dans Azure Machine Learning. Une partie essentielle de la transparence consiste à comprendre comment les fonctionnalités affectent le modèle Machine Learning.
- L’interprétabilité du modèle vous aide à comprendre ce qui influence le comportement du modèle. Il génère des descriptions compréhensibles par l’homme des prédictions du modèle. Cette compréhension vous permet de garantir que vous pouvez faire confiance au modèle et vous aide à déboguer et à l’améliorer. InterpretML peut vous aider à comprendre la structure des modèles de boîte en verre ou la relation entre les fonctionnalités des modèles de réseau neural profond de boîte noire.
- Les simulations contrefactuelles peuvent vous aider à comprendre et à déboguer un modèle Machine Learning en termes de réaction aux modifications et perturbations des fonctionnalités.
Confidentialité et sécurité dans Azure Machine Learning. Les administrateurs Machine Learning doivent créer une configuration sécurisée pour développer et gérer le déploiement de modèles. Les fonctionnalités de sécurité et de gouvernance peuvent vous aider à vous conformer aux stratégies de sécurité de votre organisation. D’autres outils peuvent vous aider à évaluer et à sécuriser vos modèles.
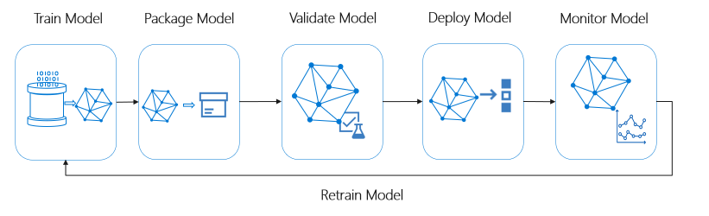
Responsabilité dans Azure Machine Learning. Les opérations d’apprentissage automatique (MLOps) s’appuient sur des principes et pratiques de DevOps, qui augmentent l’efficacité des workflows d’IA. Azure Machine Learning peut vous aider à implémenter des fonctionnalités MLOps :
- Inscrire, empaqueter et déployer des modèles
- Obtenir des notifications et des alertes pour les modifications apportées aux modèles
- Capturer les données de gouvernance pour le cycle de vie de bout en bout
- Superviser les applications pour les problèmes opérationnels
Ce diagramme illustre les fonctionnalités MLOps d’Azure Machine Learning :
Cas d’usage potentiels
Vous pouvez appliquer cette solution aux scénarios suivants :
- Finance : obtenez une analyse financière des clients ou une analyse des ventes croisées des clients pour des campagnes marketing ciblées.
- Soins : utilisez l’information des patients comme entrée pour suggérer des offres de traitement.
- Hospitalité : créez un profil client pour suggérer des offres pour les hôtels, les vols, les forfaits croisière et les abonnements.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework, un ensemble de principes directeurs que vous pouvez utiliser pour améliorer la qualité d’une charge de travail. Pour plus d'informations, consultez Microsoft Azure Well-Architected Framework.
Sécurité
La sécurité fournit des garanties contre les attaques délibérées, et contre l’utilisation abusive de vos données et systèmes importants. Pour en savoir plus, consultez Liste de contrôle de l'examen de la conception pour la sécurité.
Les solutions Azure fournissent une défense en profondeur et une approche Confiance Zéro.
Envisagez d’implémenter les fonctionnalités de sécurité suivantes dans cette architecture :
- Déploiement de services Azure dédiés dans des réseaux virtuels
- Fonctionnalités de sécurité d’Azure SQL Database
- Sécuriser les informations d’identification dans la fabrique de données à l’aide de Key Vault
- Sécurité et gouvernance de l’entreprise pour Azure Machine Learning
- Base de référence de la sécurité Azure pour l’espace de travail Synapse Analytics
Optimisation des coûts
L’optimisation des coûts consiste à réduire les dépenses inutiles et à améliorer les efficacités opérationnelles. Pour plus d'informations, consultez Liste de contrôle de la révision de la conception pour l'optimisation des coûts.
Pour estimer le coût d’implémentation de cette solution, utilisez la Calculatrice de prix Azure.
Tenez également compte des ressources suivantes :
- Planifier et gérer les coûts pour Azure Synapse Analytics
- Planifier et gérer les coûts d’Azure Machine Learning
Excellence opérationnelle
L’excellence opérationnelle couvre les processus opérationnels qui déploient une application et la maintiennent en production. Pour plus d’informations, consultez la Liste de contrôle de l'examen de la conception pour l'excellence opérationnelle.
Les solutions de Machine Learning doivent être évolutives et standardisées pour faciliter la gestion et la maintenance. Assurez-vous que votre solution prend en charge l’inférence en cours avec des cycles de réentraînement et des redéploiements automatisés de modèles.
Pour plus d’informations, consultez le référentiel GitHub d’Azure MLOps v2.
Efficacité des performances
L’efficacité des performances est la capacité de votre charge de travail à s’adapter à la demande des utilisateurs de façon efficace. Pour en savoir plus, consultez Liste de vérification de l'examen de la conception pour l'efficacité des performances
- Pour plus d’informations sur la conception de solutions évolutives, consultez Check-list pour l’efficacité des performances.
- Gérez votre environnement Azure Synapse Analytics avec SQL, Spark ou des pools SQL serverless.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Charitha Basani | Architecte de solutions cloud senior
Autre contributeur :
- Mick Alberts | Rédacteur technique
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Ligne de base de la sécurité Azure pour Azure Machine Learning
- Azure Synapse Analytics
- Déployer des modèles Machine Learning sur Azure
- Qu’est-ce que l’IA responsable ?