Les organisations se demandent souvent comment collecter des données à partir de plusieurs sources, dans différents formats. Il faut ensuite les déplacer vers un ou plusieurs magasins de données. Il se peut que la destination ne soit pas du même type de magasin de données que la source. Le format est souvent différent, ou les données doivent être mises en forme ou nettoyées avant d’être chargées dans leur destination finale.
Au fil des années, différents outils, services et processus ont été développés pour relever ces défis. Quel que soit le processus utilisé, il est nécessaire de coordonner le travail et d’appliquer un certain degré de transformation des données dans le pipeline de données. Les sections suivantes illustrent les méthodes couramment utilisées pour effectuer ces tâches.
Processus ETL (extraction, transformation et chargement)
L’extraction, transformation, chargement (ETL) est un pipeline de données utilisé pour collecter des données à partir de différentes sources. Il transforme ensuite les données en fonction de règles d’entreprise et les charge dans un magasin de données de destination. Le travail de transformation dans ETL a lieu dans un moteur spécialisé et implique souvent l’utilisation de tables intermédiaires pour conserver temporairement les données lors de leur transformation et leur chargement final vers leur destination.
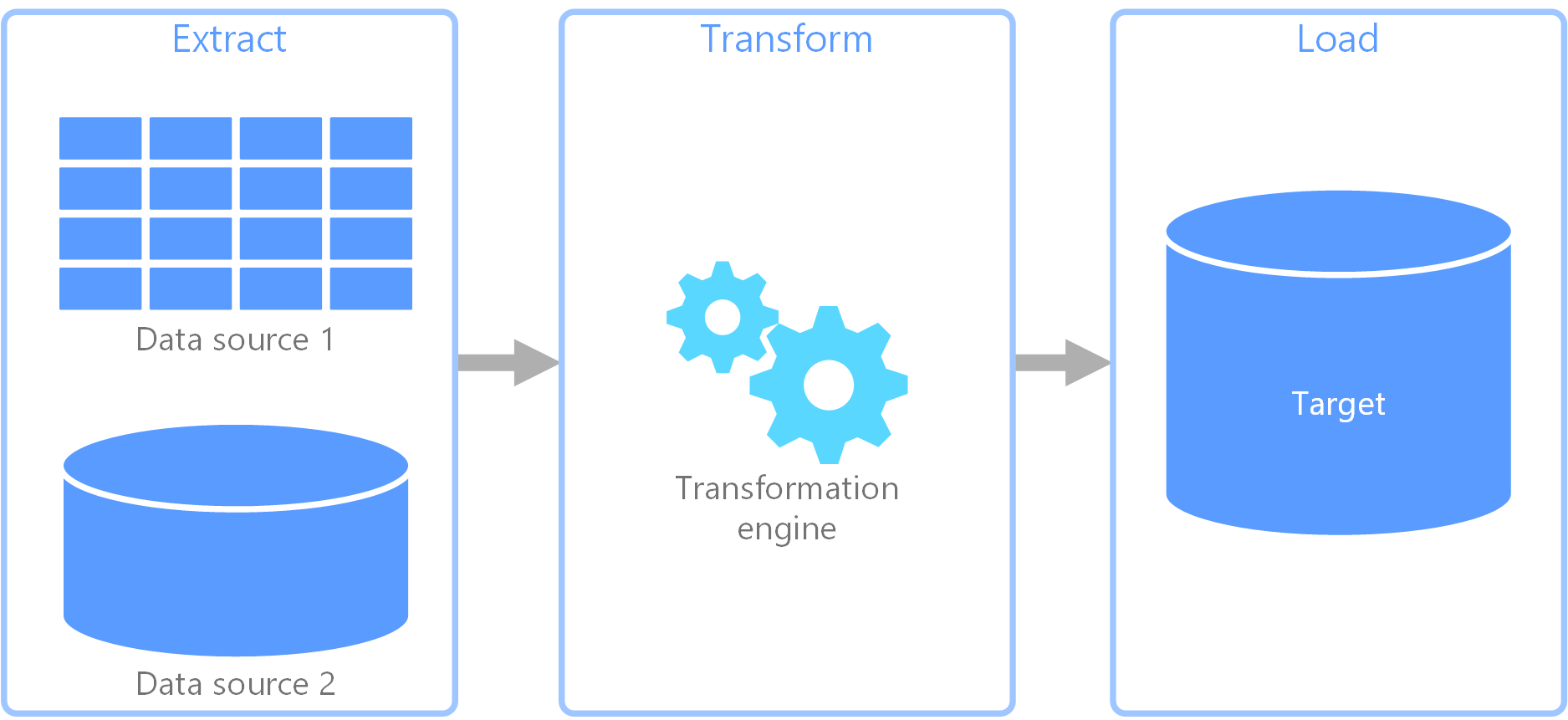
La transformation des données qui a lieu implique généralement plusieurs opérations, comme le filtrage, le tri, l’agrégation, la jointure des données, le nettoyage des données, la déduplication et la validation des données.
Souvent, les trois phases ETL sont exécutées en parallèle pour gagner du temps. Par exemple, tandis que les données sont extraites, un processus de transformation peut travailler sur les données déjà reçues et les préparer pour le chargement, et un processus de chargement peut commencer à travailler sur les données préparées, au lieu d’attendre la fin du processus d’extraction complet.
Service Azure approprié :
Autres outils :
Extraction, chargement, transformation (ELT)
Le processus Extraction, chargement, transformation (ELT) diffère de l'ETL uniquement par l'endroit où la transformation a lieu. Dans le pipeline ELT, la transformation se produit dans le magasin de données cible. Au lieu d’utiliser un moteur de transformation distinct, les fonctionnalités de traitement du magasin de données cible sont utilisées pour transformer les données. Cela simplifie l’architecture en supprimant le moteur de transformation du pipeline. Un autre avantage de cette approche est que la montée en puissance du magasin de données cible permet également la montée en puissance des performances du pipeline ELT. Toutefois, ELT fonctionne bien uniquement lorsque le système cible est suffisamment puissant pour transformer les données de manière efficace.
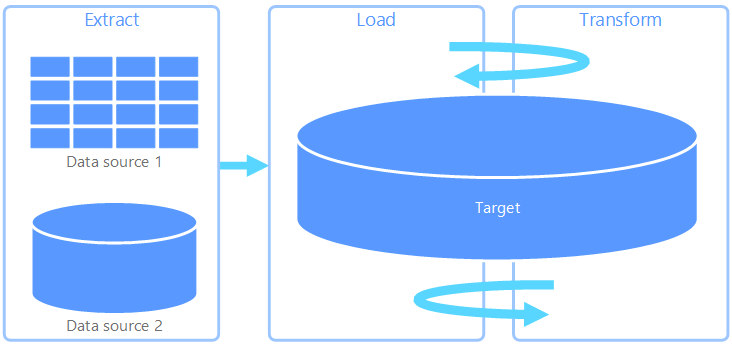
Les scénarios d’utilisation classiques d’ELT concernent le domaine du Big Data. Par exemple, vous pouvez commencer par extraire toutes les données sources vers des fichiers plats dans un stockage évolutif, tel qu'un système de fichiers distribués Hadoop, un magasin Azure Blob ou Azure Data Lake gen 2 (ou une combinaison des deux). Des technologies telles que Spark, Hive ou PolyBase peuvent ensuite être utilisées pour interroger les données sources. Le point clé avec ELT est que le magasin de données utilisé pour effectuer la transformation est le même magasin de données que celui où les données sont finalement consommées. Ce magasin de données lit directement à partir du stockage évolutif, au lieu de charger les données dans son propre stockage propriétaire. Cette approche ignore l’étape de copie des données présente dans ETL, qui peut être une opération longue pour les jeux de données volumineux.
En pratique, le magasin de données cible est un entrepôt de données à l’aide d’un cluster Hadoop (à l’aide de Hive ou Spark) ou d’un pool dédié SQL sur Azure Synapse Analytics. En général, un schéma est placé sur les données de fichier plat au moment de la requête et stocké sous la forme d’une table, permettant l’interrogation des données comme toute autre table dans le magasin de données. On parle de tables externes car les données ne résident pas dans le stockage géré par le magasin de données lui-même, mais dans un stockage externe évolutif tel que le magasin Azure Data Lake ou le stockage Azure Blob.
Le magasin de données gère uniquement le schéma des données et applique le schéma lors de la lecture. Par exemple, un cluster Hadoop utilisant Hive décrit une table Hive où la source des données est en réalité un chemin d’accès à un ensemble de fichiers dans HDFS. Dans Azure Synapse, PolyBase peut obtenir le même résultat, en créant une table à partir de données stockées en externe dans la base de données. Une fois la source de données chargée, les données présentes dans les tables externes peuvent être traitées grâce aux fonctionnalités du magasin de données. Dans les scénarios Big Data, cela signifie que le magasin de données doit être capable d’un traitement parallèle massif (MPP), qui fractionne les données en segments plus petits et distribue le traitement des segments sur plusieurs nœuds en parallèle.
La dernière phase du pipeline ELT consiste généralement à transformer la source de données dans un format final plus efficace pour les types de requêtes qui doivent être pris en charge. Par exemple, les données peuvent être partitionnées. En outre, ELT peut utiliser des formats de stockage optimisés comme Parquet, qui stocke les données orientées lignes sous forme de colonnes et fournit une indexation optimisée.
Service Azure approprié :
- Pools dédiés SQL sur Azure Synapse Analytics
- Pools SQL serverless sur Azure Synapse Analytics
- HDInsight avec Hive
- Azure Data Factory.
- Datamarts dans Power BI
Autres outils :
Flux de données et flux de contrôle
Dans le contexte de pipelines de données, le flux de contrôle garantit le traitement de façon ordonnée d’un ensemble de tâches. Pour appliquer l’ordre de traitement correct de ces tâches, des contraintes de priorité sont utilisées. Vous pouvez comparer ces contraintes à des connecteurs dans un diagramme de flux de travail, comme indiqué dans l’image ci-dessous. Chaque tâche a un résultat, comme la réussite, l’échec ou l’achèvement. Le traitement de la tâche suivante n’est lancé que lorsque la tâche précédente est terminée avec l’un de ces résultats.
Les flux de contrôle exécutent les flux de données en tant que tâche. Dans une tâche de flux de données, les données sont extraites d’une source, transformées ou chargées dans un magasin de données. La sortie d'une tâche de flux de données peut correspondre à l'entrée de la prochaine tâche de flux de données, et les flux de données peuvent s'exécuter en parallèle. Contrairement aux flux de contrôle, vous ne pouvez pas ajouter de contraintes entre les tâches d’un flux de données. Toutefois, vous pouvez ajouter une visionneuse de données afin d’observer les données lorsqu’elles sont traitées par chaque tâche.
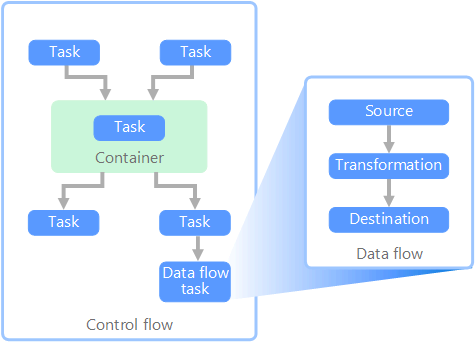
Dans le schéma ci-dessus, le flux de contrôle comporte plusieurs tâches, notamment une tâche de flux de données. L’une des tâches est imbriquée dans un conteneur. Les conteneurs peuvent être utilisés pour donner une structure aux tâches, fournissant une unité de travail. La répétition d’éléments dans une collection, comme des fichiers dans un dossier ou des instructions dans une base de données, en est un exemple.
Service Azure approprié :
Autres outils :
Choix de technologie
- Magasins de données de traitement transactionnel en ligne (OLTP)
- Magasins de données de traitement analytique en ligne (OLAP)
- Entrepôts de données
- Orchestration de pipeline
Étapes suivantes
- Intégrer des données à un pipeline Azure Data Factory ou Azure Synapse
- Présentation d’Azure Synapse Analytics
- Orchestrer le déplacement et la transformation des données dans le pipeline Azure Data Factory ou Azure Synapse
Ressources associées
Les architectures de référence suivantes présentent des pipelines ELT de bout en bout sur Azure :