Enseignements tirés
- Assurez-vous que toutes les parties impliquées comprennent la différence entre la haute disponibilité (HAUTE disponibilité) et la récupération d’urgence (DR) : un piège courant consiste à confondre les deux concepts et la incompatibilité des solutions associées.
- Discutez avec les parties prenantes de leurs attentes concernant les aspects suivants, afin de définir les objectifs de point de récupération (RPO) et les objectifs de délai de récupération (RTO) :
- Combien de temps d’arrêt ils peuvent tolérer, en gardant à l’esprit que généralement, plus la récupération est rapide, plus le coût est élevé.
- Le type d’incidents contre lesquels ils veulent être protégés, en mentionnant la probabilité associée d’un tel événement. Par exemple, la probabilité qu’un serveur tombe en panne est plus élevée qu’une catastrophe naturelle qui a un impact sur tous les centres de données d’une région.
- Quel est l’impact de l’indisponibilité du système sur leur entreprise ?
- Le budget des dépenses opérationnelles (OPEX) pour la solution va de l’avant.
- Réfléchissez aux options de service dégradé que vos utilisateurs finaux peuvent accepter. Il peut s’agir des éléments suivants :
- Toujours avoir accès aux tableaux de bord de visualisation même sans les données les plus à jour, c’est-à-dire, si les pipelines d’ingestion ne fonctionnent pas, les utilisateurs finaux ont toujours accès à leurs données.
- Accès en lecture, mais pas d’accès en écriture.
- Vos métriques RTO et RPO cibles peuvent définir la stratégie de récupération d'urgence que vous choisissez d’implémenter :
- Actif/Actif.
- Actif/passif.
- Active/Redéploiement en cas d’urgence.
- Considérez votre propre objectif de niveau de service composite (SLO) pour prendre en compte les temps d’arrêt tolérables.
- Assurez-vous de comprendre tous les éléments susceptibles d'affecter la disponibilité de vos systèmes, tels que :
- Gestion des identités.
- Topologie de mise en réseau.
- Gestion des secrets/clés.
- Sources de données.
- Planificateur d’automatisation/travail.
- Référentiel source et pipelines de déploiement (GitHub, Azure DevOps).
- La détection précoce des pannes est également un moyen de réduire considérablement les valeurs RTO et RPO. Voici quelques aspects qui doivent être abordés :
- Définissez ce qu'est une panne et comment elle se mappe à la définition d'une panne de Microsoft. La définition Microsoft est disponible dans la page Contrat de niveau de service (SLA) Azure au niveau du produit ou du service.
- Un système de surveillance et d’alerte efficace avec des équipes responsables pour passer en revue ces métriques et alertes en temps voulu contribue à atteindre l’objectif.
- En ce qui concerne la conception de l’abonnement, l’infrastructure supplémentaire pour la reprise d’activité peut être stockée dans l’abonnement d’origine. les services PaaS (platform as a service), comme Azure Data Lake Storage Gen2 ou Azure Data Factory, ont généralement des fonctionnalités natives qui permettent de basculer vers des instances secondaires dans d’autres régions tout en restant contenus dans l’abonnement d’origine. Certains clients peuvent envisager d’avoir un groupe de ressources dédié pour les ressources utilisées uniquement dans les scénarios de récupération d’urgence à des fins de coût.
- Il convient de noter que les limites d’abonnement peuvent constituer une contrainte pour cette approche.
- D’autres contraintes peuvent inclure la complexité de la conception et les contrôles de gestion pour s’assurer que les groupes de ressources de récupération d’urgence ne sont pas utilisés pour les flux de travail métier comme d’habitude (BAU).
- Concevoir le workflow DR en fonction de la criticité et des dépendances d'une solution. Par exemple, n’essayez pas de reconstruire une instance Azure Analysis Services avant que votre entrepôt de données soit opérationnel, car il déclenche une erreur. Laissez les laboratoires de développement plus tard dans le processus, récupérez d’abord les principales solutions d’entreprise.
- Essayez d’identifier les tâches de récupération qui peuvent être parallélisées entre les solutions, ce qui réduit le nombre total de RTO.
- Si Azure Data Factory est utilisé dans une solution, n’oubliez pas d’inclure les runtimes d’intégration auto-hébergés dans l’étendue. Azure Site Recovery est idéal pour ces machines.
- Les opérations manuelles doivent être automatisées autant que possible, afin d’éviter les erreurs humaines, en particulier sous pression. Il est recommandé d’effectuer les opérations suivantes :
- Adoptez le provisionnement de ressources via des modèles Bicep, ARM ou des scripts PowerShell.
- Adoptez le contrôle de version du code source et de la configuration des ressources.
- Utilisez des pipelines de mise en production CI/CD plutôt que des opérations de clic.
- Comme vous disposez d’un plan de basculement, vous devez prendre en compte les procédures de secours vers les instances principales.
- Définissez des indicateurs et des métriques clairs pour vérifier que le basculement a réussi et que les solutions sont opérationnelles ou que la situation est de retour à la normale (également appelée fonction principale).
- Déterminez si vos contrats de niveau de service (SLA) doivent rester identiques après un basculement ou si vous autorisez le service détérioré.
- Cette décision dépend grandement du processus de service métier pris en charge. Par exemple, le basculement d’un système de réservation de salles est très différent d’un système opérationnel de base.
- Une définition RTO/RPO doit être basée sur des scénarios utilisateur spécifiques plutôt qu’au niveau de l’infrastructure. Cela vous donnera plus de granularité sur les processus et composants à récupérer en premier s’il existe une panne ou un sinistre.
- Veillez à inclure des vérifications de capacité dans la région cible avant de passer à un basculement : s’il existe un incident majeur, n’oubliez pas que de nombreux clients essaieront de basculer vers la même région jumelée en même temps, ce qui peut entraîner des retards ou des conflits lors de l’approvisionnement des ressources.
- Si ces risques sont inacceptables, une stratégie de récupération d’urgence active/active ou active/passive doit être prise en compte.
- Un plan de reprise d’activité doit être créé et géré afin de documenter le processus de récupération et les propriétaires d’action. Tenez également compte du fait que certaines personnes peuvent être en congé. Veillez donc à inclure des contacts secondaires.
- Des exercices de récupération d’urgence réguliers doivent être effectués pour valider le flux de travail du plan de récupération d’urgence, qu’il répond au RTO/RPO requis et pour former les équipes responsables.
- Les sauvegardes des données et de la configuration doivent également être testées régulièrement afin de s'assurer qu'elles sont « adaptées à l'usage » pour soutenir toute activité de récupération.
- Une collaboration précoce avec les équipes responsables des réseaux, de l’identité et du provisionnement des ressources permettra de parvenir à un accord quant à la solution la plus optimale en ce qui concerne :
- La manière de rediriger les utilisateurs et le trafic de votre site principal vers votre site secondaire. Des concepts tels que la redirection DNS ou l’utilisation d’outils spécifiques comme Azure Traffic Manager peuvent être évalués.
- Comment fournir l’accès et les droits au site secondaire en temps opportun et sécurisé.
- Au cours d’une catastrophe, une communication efficace entre les nombreuses parties impliquées est essentielle à l’exécution efficace et rapide du plan. Teams peut inclure :
- Décideurs.
- Équipe de réponse aux incidents.
- Utilisateurs et équipes internes affectés.
- Équipes externes.
- L’orchestration des différentes ressources au bon moment garantit l’efficacité de l’exécution du plan de récupération d’urgence.
À propos de l’installation
Antimodèles
- Copiez/collez cette série d’articles Cette série d’articles est destinée à fournir des conseils aux clients qui recherchent le niveau de détail suivant pour un processus de récupération d’urgence spécifique à Azure. Ce document est basé sur l'IP générique de Microsoft et les architectures de référence plutôt que sur une implémentation d'Azure spécifique à un client.
Bien que les détails fournis permettent d'acquérir une solide compréhension de base, les clients doivent appliquer leur contexte, leur mise en œuvre et leurs exigences spécifiques avant d'obtenir une stratégie et un processus DR « adaptés à l'objectif ».
Traitement de la reprise d’activité en tant que processus « technique uniquement » Les parties prenantes de l’entreprise jouent un rôle essentiel dans la définition des exigences en matière de reprise d’activité et d’exécution des étapes de validation métier requises pour confirmer une récupération de service. En veillant à ce que les parties prenantes de l'entreprise soient impliquées dans toutes les activités de DR, vous obtiendrez un processus de DR « adapté à l'objectif », qui représente une valeur commerciale et qui est exécutable.
Les plans de DR « set and forget » Azure est en constante évolution, tout comme l'utilisation des différents composants et services par les clients. Un processus DR « adapté à l'objectif » doit évoluer avec eux. Soit via le processus de cycle de vie du développement logiciel (SDLC) soit des révisions périodiques, les clients doivent régulièrement revoir leur plan de récupération d’urgence. L’objectif est de garantir la validité du plan de récupération de service et de vérifier que les deltas entre les composants, services ou solutions ont été pris en compte.
Évaluations sur papier Bien que la simulation de bout en bout d'un événement DR soit difficile dans un écosystème de données moderne, des efforts doivent être faits pour s'approcher le plus possible d'une simulation complète dans les composants concernés. Des exercices réguliers permettront de développer la « mémoire musculaire » nécessaire à l'organisation pour être en mesure d'exécuter le plan DR en toute confiance.
S'en remettre à Microsoft pour tout faire Au sein des services Microsoft Azure, il existe une division claire des responsabilités, ancrée par le niveau de service cloud utilisé :
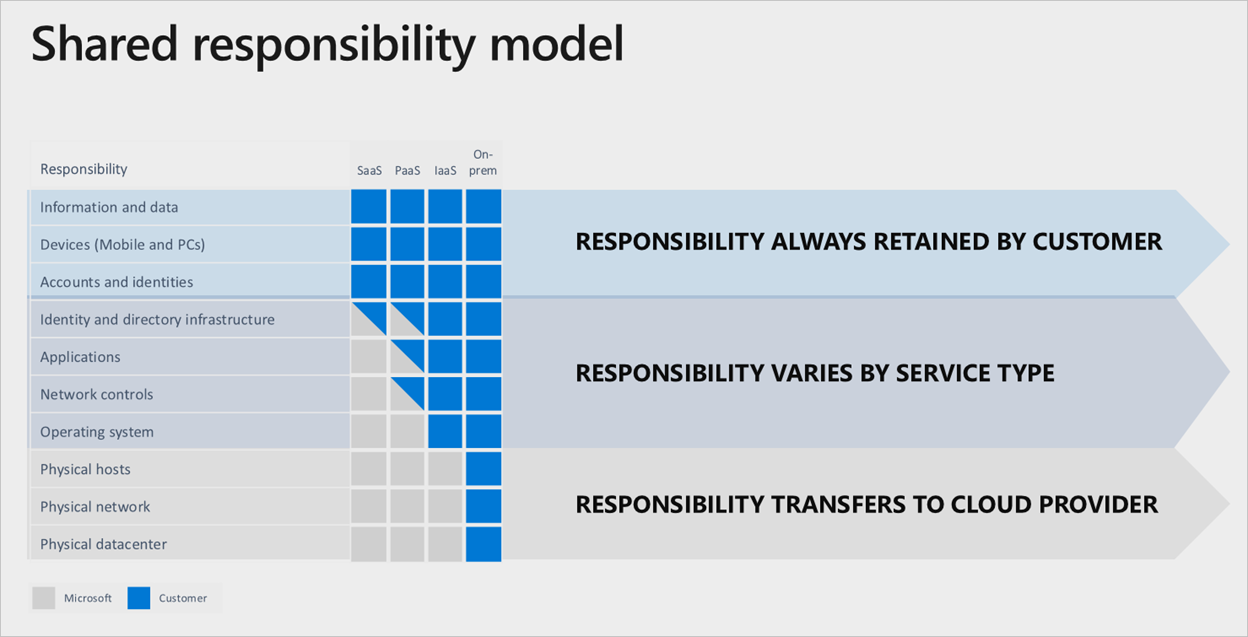 Même si un logiciel en tant que service (SaaS) complet est utilisé, le client conserve la responsabilité de s'assurer que les comptes, les identités et les données sont corrects et à jour, ainsi que les appareils utilisés pour interagir avec les services Azure.
Même si un logiciel en tant que service (SaaS) complet est utilisé, le client conserve la responsabilité de s'assurer que les comptes, les identités et les données sont corrects et à jour, ainsi que les appareils utilisés pour interagir avec les services Azure.
Étendue d’événement et stratégie
Étendue des événements de sinistre
Différents événements auront une étendue d’impact différente et, par conséquent, une réponse différente. Le diagramme suivant illustre cela pour un événement de sinistre : 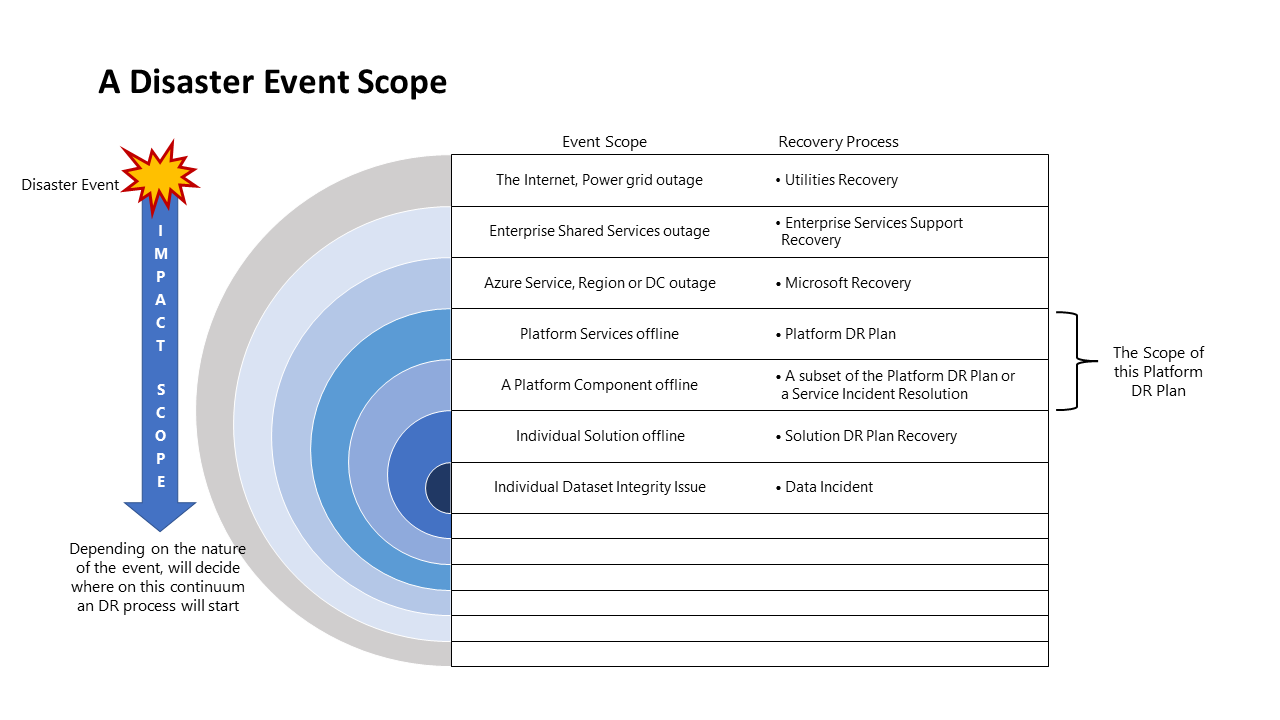
Options de stratégie en cas de sinistre
Il existe quatre options générales pour une stratégie de reprise d’activité :
- Attendre Microsoft - Comme son nom l'indique, la solution est hors ligne jusqu'à la reprise complète des services dans la région affectée par Microsoft. Une fois récupérée, la solution est validée par le client, puis mise à jour pour la récupération du service.
- Redéploiement en cas d’urgence : la solution est redéployée manuellement dans une région disponible à partir de zéro, après sinistre.
- Échange semi-automatique (Actif/Passif) : une solution hébergée secondaire est créée dans une autre région, et des composants sont déployés pour garantir une capacité minimale ; cependant, les composants ne reçoivent pas de trafic de production. Les services secondaires de la région alternative peuvent être « désactivés » ou exécutés à un niveau de performances inférieur jusqu’à ce qu’un événement de récupération d’urgence se produise.
- Échange à chaud (Actif/Actif) : la solution est hébergée dans une configuration Actif/Actif dans plusieurs régions. La solution hébergée secondaire reçoit, traite et sert des données dans le cadre du système plus grand.
Impact de la stratégie de reprise d’activité
Bien que le coût d’exploitation attribué aux niveaux plus élevés de résilience du service domine souvent la décision de conception clé (KDD) pour une stratégie de reprise d’activité, il existe d’autres considérations importantes :
Remarque
L'optimisation des coûts est l'un des cinq piliers de l'excellence architecturale du cadre Azure Well-Architected. Son objectif est de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle.
Le scénario de reprise d’activité de cet exemple est une panne régionale Azure complète qui a un impact direct sur la région primaire hébergeant la plateforme de données Contoso.
Pour ce scénario de panne, l’impact relatif sur les quatre stratégies de reprise d’activité de haut niveau est : 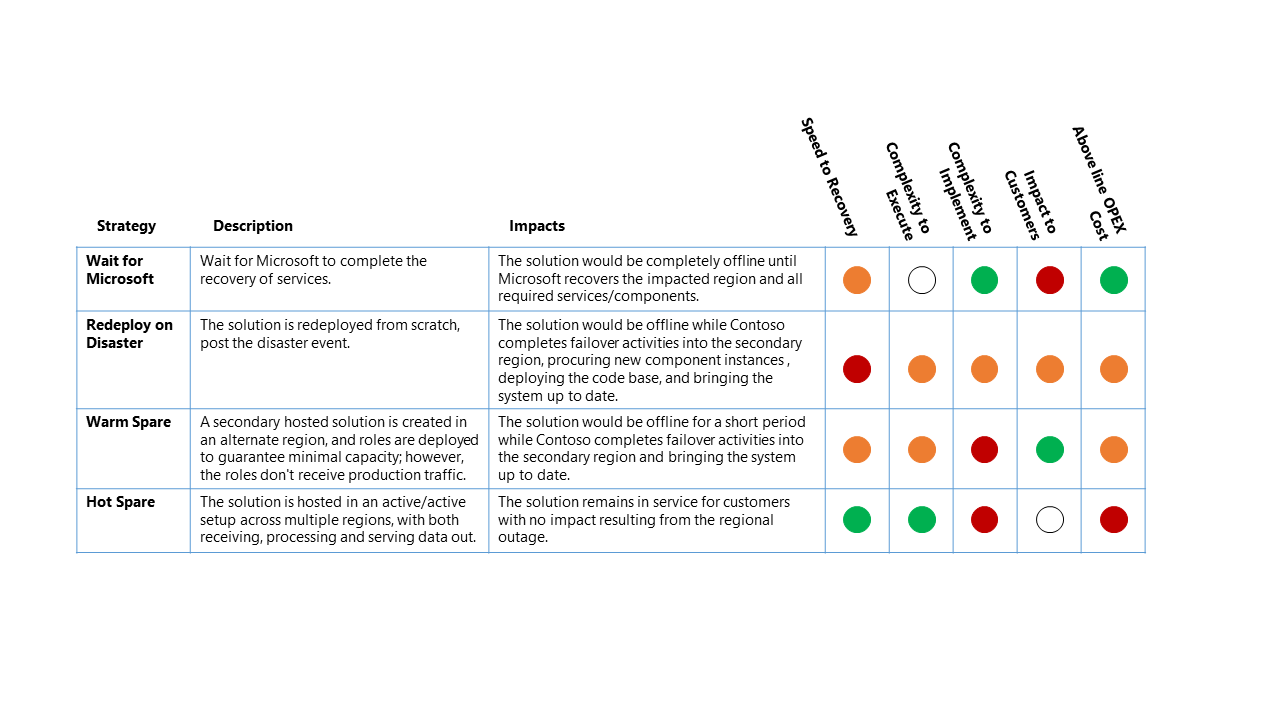
Clé de classification
- Objectif de temps de récupération (RTO) : temps écoulé attendu entre l’événement d’urgence et la récupération du service de plateforme.
- Complexité à exécuter : complexité pour l’organisation d’exécuter les activités de récupération.
- Complexité à implémenter : complexité pour que l’organisation implémente la stratégie de récupération d’urgence.
- Impact sur les clients : impact direct sur les clients du service de plateforme de données à partir de la stratégie de récupération d’urgence.
- Coût OPEX au-dessus de la ligne : coût supplémentaire attendu de l’implémentation de cette stratégie, comme une facturation mensuelle accrue pour Azure pour des composants supplémentaires et des ressources supplémentaires nécessaires à la prise en charge.
Remarque
Le tableau ci-dessus doit être lu comme une comparaison entre les options : une stratégie qui a un indicateur vert est meilleure pour cette classification qu’une autre stratégie avec un indicateur jaune ou rouge.
Étapes suivantes
Maintenant que vous avez découvert les recommandations liées au scénario, vous pouvez apprendre à déployer ce scénario.