Vue d’ensemble des fonctionnalités de la passerelle d’IA générative dans Gestion des API Azure
S’APPLIQUE À : Tous les niveaux de Gestion des API
Cet article présente les fonctionnalités dans Gestion des API Azure pour vous aider à gérer les API d’IA générative, comme celles fournies par Azure OpenAI Service. Gestion des API Azure offre une gamme de stratégies, métriques et d’autres fonctionnalités pour améliorer la sécurité, les performances et la fiabilité pour les API servant vos applications intelligentes. Ces fonctionnalités sont collectivement appelées Fonctionnalités de la passerelle (GenAI) d’IA générative pour vos API d’IA générative.
Remarque
- Cet article se concentre sur les fonctionnalités pour gérer les API exposées par Azure OpenAI Service. Plusieurs des fonctionnalités de la passerelle GenAI s’appliquent aux API de grand modèle de langage (LLM), notamment celles disponibles via l’API Inférence de modèle Azure AI.
- Les fonctionnalités de la passerelle d’IA générative sont des fonctionnalités de la passerelle API existante de Gestion des API, et non d’une passerelle API distincte. Pour découvrir plus d’informations sur Gestion des API, consultez Vue d’ensemble de la Gestion des API Azure .
Défis liés à la gestion des API d’IA générative
Les jetons constituent l’une des principales ressources dont vous disposez dans les services d’IA générative. Azure OpenAI Service attribue un quota pour vos modèles de déploiements, exprimé en jetons par minute (TPM), qui est ensuite distribué dans vos consommateurs modèles, par exemple, diverses applications, équipes de développeurs, divers services au sein de la société, etc.
Azure facilite la connexion d’une seule application à Azure OpenAI Service : vous pouvez vous connecter directement en utilisant une clé API avec une limite de TPM configurée directement sur le niveau du modèle de déploiement. Toutefois, lorsque vous commencez à développer votre portefeuille d’applications, il vous est présenté plusieurs applications appelant un, voire plusieurs points de terminaison Azure OpenAI Service déployés en tant qu’instances de paiement à l’utilisation ou Unités de débit approvisionnées (PTU). Il en découle certaines problématiques :
- De quelle manière l’utilisation des jetons est-elle suivie sur plusieurs applications ? Les charges croisées peuvent-elles être calculées pour plusieurs applications/équipes qui utilisent des modèles Azure OpenAI Service ?
- Comment veiller à ce qu’une seule application ne consomme pas la totalité du quota de TPM, laissant les autres applications sans aucune option pour utiliser des modèles Azure OpenAI Service ?
- Comment la clé API est-elle distribuée en toute sécurité sur plusieurs applications ?
- Comment la charge est-elle distribuée sur plusieurs points de terminaison Azure OpenAI ? Pouvez-vous veiller à ce que la capacité validée en PTU soit épuisée avant de retourner aux instances avec paiement à l’utilisation ?
Le reste de cet article décrit comment Gestion des API Azure peut vous aider à résoudre ces problèmes.
Importer une ressource Azure OpenAI Service en tant qu’API
Importer une SPI à partir d’un point de terminaison Azure OpenAI Service pour Gestion des API Azure en utilisant une expérience en un seul clic. Gestion des API simplifie le processus d’intégration en important automatiquement le schéma OpenAI pour l’API Azure OpenAI et définit une authentification pour le point de terminaison Azure OpenAI en utilisant une identité managée, ce qui supprime le besoin de configuration manuelle. Avec la même expérience conviviale, vous pouvez préconfigurer des stratégies pour les limites de jetons et l’émission de métriques de jetons.

Stratégie de limite de jetons
Configurez la stratégie de limite de jetons Azure OpenAI pour gérer et appliquer des limites par client d’API en fonction de l’utilisation de jetons Azure OpenAI Service. Avec cette stratégie, vous pouvez définir des limites exprimées en jetons par minute (TPM).
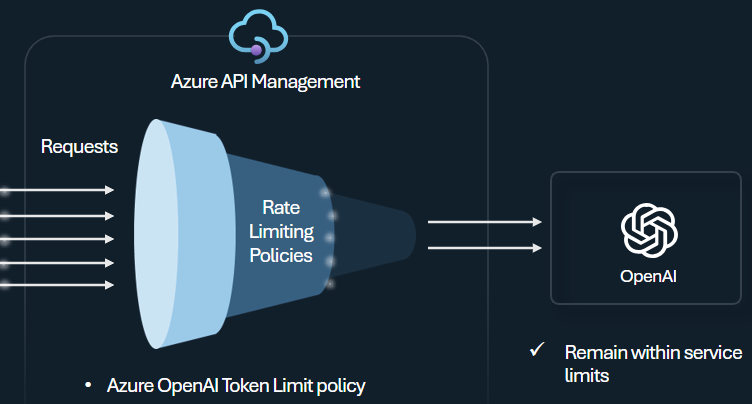
Cette stratégie offre une certaine flexibilité pour attribuer des limites basées sur les jetons sur n’importe quelle clé de compteur, comme une clé d’abonnement, une adresse IP d’origine ou une clé arbitraire définie via une expression de stratégie. La stratégie permet également un calcul préalable des jetons d’invite du côté de Gestion des API Azure, ce qui réduit les requêtes inutiles adressées au back-end Azure OpenAI Service si l’invite dépasse déjà la limite.
L’exemple de base suivant montre comment définir une limite de 500 TPM par clé d’abonnement :
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
Conseil
Pour gérer et appliquer les limites de jetons pour les API de grand modèle de langage disponibles via l’API Inférence de modèle Azure AI, Gestion des API fournit la stratégie llm-token-limit équivalente.
Émission d’une stratégie pour les métriques de jetons
La stratégie d’émission de métriques de jetons Azure OpenAI envoie des métriques à Application Insights sur la consommation de jetons d’un grand modèle de langage via les API Azure OpenAI Service. La stratégie fournit une vue d’ensemble de l’utilisation des modèles Azure OpenAI Service dans plusieurs applications ou clients d’API. Cette stratégie peut être utile pour les scénarios de rétrofacturation, le monitoring et la planification de capacité.
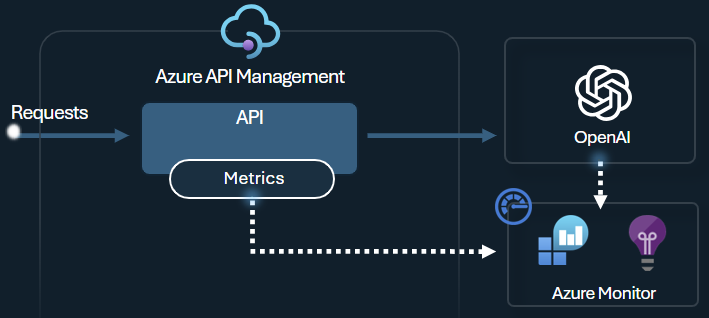
Cette stratégie capture les invites, saisies semi-automatiques et les métriques d’utilisation totale de jetons, puis les envoie à un espace de noms Application Insights de votre choix. De plus, vous pouvez configurer ou effectuer une sélection à partir de dimensions personnalisées pour fractionner les métriques d’utilisation de jetons afin que vous puissiez analyser des métriques par ID d’abonnement, adresse IP ou une dimension personnalisée de votre choix.
Par exemple, la stratégie suivante envoie des métriques à Application Insights fractionnées par adresse IP du client, API et utilisateur :
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
Conseil
Pour envoyer des métriques pour les API de grand modèle de langage disponibles via l’API Inférence de modèle Azure AI, Gestion des API fournit la stratégie llm-emit-token-metric équivalente.
Équilibreur de charge de back-end et disjoncteur
L’une des problématiques lors de la génération d’applications intelligentes est de veiller à ce qu’elles soient résilientes aux défaillances du back-end et puissent gérer des charges élevées. Si vous configurez vos points de terminaison Azure OpenAI Service en utilisant des back-ends dans Gestion des API Azure, vous pouvez équilibrer la charge entre eux. Vous pouvez également définir des règles de disjoncteur pour arrêter le transfert de requêtes vers des back-ends Azure OpenAI Service, s’ils ne répondent pas.
L’équilibrage de charge de back-end prend en charge l’équilibrage de charge de tourniquet, pondéré et basé sur la priorité, ce qui vous donne la souplesse de définir une stratégie de distribution de charge qui répond à vos exigences spécifiques. Par exemple, définissez des priorités dans la configuration de l’équilibreur de charge pour veiller à une utilisation optimale de points de terminaison Azure OpenAI spécifiques, en particulier ceux achetés en tant que PTU.
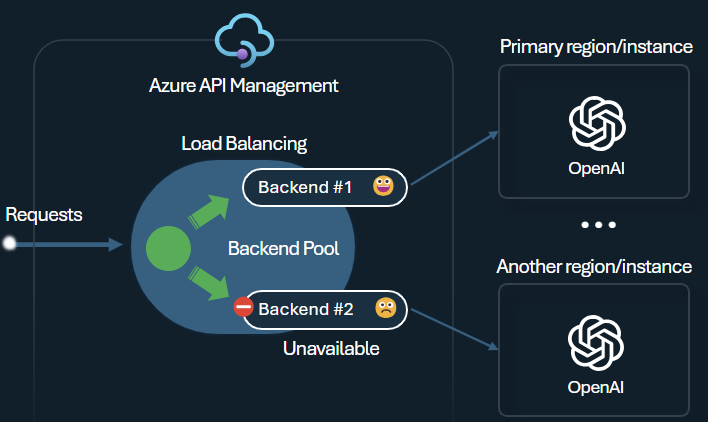
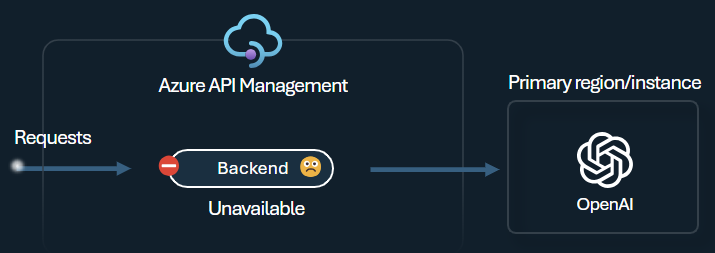
Le disjoncteur de back-end présente une durée de trajet dynamique et applique des valeurs à partir de l’en-tête Retry-After fourni par le back-end. Il veille à une récupération précise et opportune des back-ends et maximise ainsi l’utilisateur de votre back-ends prioritaires.
Stratégie de mise en cache sémantique
Configurez des stratégies de mise en cache sémantique Azure OpenAI pour optimiser l’utilisation de jetons en stockant des saisies semi-automatiques pour des prompts similaires.
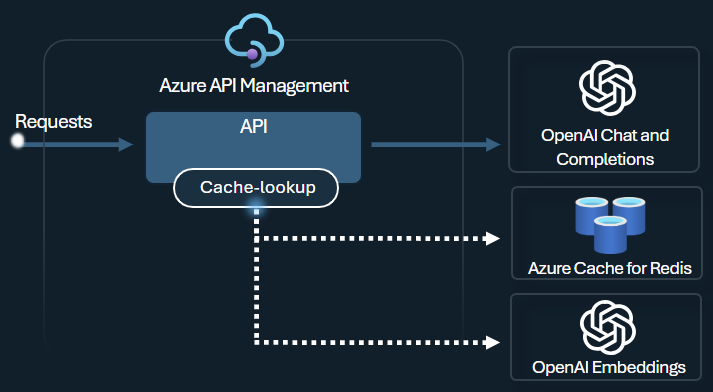
Dans Gestion des API, activez la mise en cache sémantique en tirant parti d’Azure Redis Enterprise ou un autre cache externe compatible avec RediSearch et intégré à Gestion des API Azure. L’utilisation de l’API Incorporations Azure OpenAI Service permet aux stratégies azure-openai-semantic-cache-store et azure-openai-semantic-cache-lookup de stocker et de récupérer des saisies semi-automatiques de prompt similaires à partir du cache. Cette approche veille à une réutilisation des saisies semi-automatiques et a donc pour effet de réduire la consommation de jetons et d’améliorer les performances des réponses.
Conseil
Pour activer la mise en cache sémantique pour les API de grand modèle de langage via l’API Inférence de modèle Azure AI, Gestion des API fournit les stratégies llm-semantic-cache-store-policy et llm-semantic-cache-lookup-policy équivalentes.
Labos et exemples
- Labos pour les fonctionnalités de la passerelle GenAI dans Gestion des API Azure
- Gestion des API Azure (APIM) – Exemple Azure OpenAI (Node.js)
- Exemple de code Python pour utiliser Azure OpenAI avec Gestion des API
Considérations relatives à l'architecture et à la conception
- Architecture de référence de la passerelle GenAI en utilisant Gestion des API
- Accélérateur de zone d’atterrissage de la passerelle de hub IA
- Conception et implémentation d’une solution de passerelle avec des ressources Azure OpenAI
- Utilisez une passerelle devant plusieurs déploiements ou instances Azure OpenAI.
Contenu connexe
- Blog : présentation des fonctionnalités de GenAI dans Gestion des API Azure
- Blog : intégration d’Azure Sécurité du Contenu à Gestion des API pour Points de terminaison Azure OpenAI
- Formation : gérer vos API d’IA générative avec Gestion des API Azure
- Équilibrage de charge intelligent pour les points de terminaison OpenAI et Gestion des API
- Authentifier et autoriser l’accès aux API Azure OpenAI en utilisant Gestion des API Azure