Filtrage de contenu dans Azure AI Studio
Azure AI Studio inclut un système de filtrage du contenu qui fonctionne avec les modèles de base et les modèles de génération d’images DALL-E.
Important
Le système de filtrage de contenu n’est pas appliqué aux invites et aux complétions traitées par le modèle Whisper dans Azure OpenAI Service. Apprenez-en davantage sur le modèle Whisper dans Azure OpenAI.
Fonctionnement
Ce système de filtrage de contenu est alimenté par Azure AI Sécurité du Contenu, et fonctionne en exécutant à la fois l’entrée d’invite et la sortie d’achèvement à travers un ensemble de modèles de classification visant à détecter et à empêcher la sortie de contenu dangereux. Les écarts au niveau des configurations d’API et de la conception de l’application pourraient affecter les achèvements et, par conséquent, le comportement de filtrage.
Avec les modèles de déploiement Azure OpenAI, vous pouvez utiliser le filtre de contenu par défaut ou créer votre propre filtre de contenu (décrit plus loin). Le filtre de contenu par défaut est également disponible pour d’autres modèles de texte organisés par Azure AI dans le catalogue de modèles, mais les filtres de contenu personnalisés ne sont pas encore disponibles pour ces modèles. Les modèles disponibles via les modèles en tant que service ont le filtrage de contenu activé par défaut et ne peuvent pas être configurés.
Support multilingue
Les modèles de filtrage du contenu ont été formés et testés dans les langues suivantes : anglais, allemand, japonais, espagnol, français, italien, portugais et chinois. Toutefois, le service peut fonctionner dans de nombreuses autres langues, mais la qualité peut varier. Dans tous les cas, vous devez effectuer vos propres tests pour vous assurer qu’il fonctionne pour votre application.
Filtres de risque de contenu (filtres d’entrée et de sortie)
Les filtres spéciaux suivants fonctionnent à la fois pour l’entrée et la sortie des modèles IA générative :
Catégories
| Category | Description |
|---|---|
| Déteste | La catégorie Haine décrit des attaques ou des utilisations de langage qui incluent des termes péjoratifs ou discriminatoires faisant référence à une personne ou à un groupe identitaire sur la base de certains attributs de différenciation de ces groupes, notamment la race, l’origine ethnique, la nationalité, l’identité et l’expression de genre, l’orientation sexuelle, la religion, le statut d’immigration, les aptitudes, l’apparence personnelle et la taille du corps. |
| Contenu sexuel | La catégorie Sexualité décrit le langage relatif aux organes anatomiques et génitaux, aux relations amoureuses, aux actes présentés en termes érotiques ou affectueux, aux actes sexuels physiques, y compris les actes présentés comme une agression ou un acte violent sexuel forcé contre sa volonté, la prostitution, la pornographie et les abus. |
| Violence | La catégorie Violence décrit le langage relatif aux actes physiques visant à blesser quelqu’un ou quelque chose, à lui porter atteinte ou à le tuer ; décrit les armes, etc. |
| Automutilation | La catégorie Automutilation décrit le langage lié aux actes physiques destinés à se blesser, à porter atteinte à son corps ou à se tuer. |
Niveaux de gravité
| Category | Description |
|---|---|
| Safe | Le contenu peut être lié à la catégorie de violence, d’automutilation, de sexualité ou de haine, mais les termes sont utilisés dans le domaine général, journalistique, scientifique, médical et dans des contextes professionnels similaire qui conviennent à la plupart des publics. |
| Faible | Contenu qui exprime des préjugés, des jugements ou des opinions, qui inclut une utilisation choquante du langage, des stéréotypes, des cas d’usage appartenant à un monde fictif (par exemple, les jeux, la littérature) et des représentations à faible intensité. |
| Moyenne | Contenu qui utilise des propos offensants, insultants, moqueurs, intimidants ou dégradants envers des groupes identitaires spécifiques, comprend des représentations de recherche et d’exécution d’instructions nuisibles, des fantasmes, de la glorification, de la promotion des atteintes à une intensité moyenne. |
| Élevée | Contenu qui présente des instructions, des actes, des atteintes ou des abus explicites et graves, qui comprend l’approbation, la glorification ou la promotion d’actes nuisibles graves, de formes extrêmes ou illégales de préjudice, de radicalisation ou d’échange ou d’abus de pouvoir non consentis. |
Autres filtres d’entrée
Vous pouvez également activer des filtres spéciaux pour les scénarios d’IA générative :
- Attaques de jailbreak : les attaques de jailbreak sont des invites utilisateur conçues pour provoquer le modèle d’IA générative dans des comportements qu’elle a été formée pour éviter ou pour rompre les règles définies dans le message système.
- Attaques indirectes : les attaques indirectes, également appelées attaques par prompt indirectes ou attaques par injection de prompt inter-domaines, constituent une vulnérabilité potentielle dans laquelle des tiers placent des instructions malveillantes à l’intérieur de documents auxquels le système d’IA générative peut accéder et traiter.
Autres filtres de sortie
Vous pouvez également activer les filtres de sortie spéciaux suivants :
- Matériau protégé pour le texte : le texte de matériau protégé décrit le contenu texte connu (par exemple, les paroles de chanson, les articles, les recettes et le contenu web sélectionné) qui peuvent être générés par de grands modèles de langage.
- Matériau protégé pour le code : le code de matériau protégé décrit le code source qui correspond à un ensemble de code source à partir de référentiels publics, qui peuvent être générés par de grands modèles de langage sans citation appropriée des référentiels sources.
- Fondement : le filtre de détection du fondement détecte si les réponses textuelles de grands modèles de langage (LLM) sont fondées dans les documents sources fournis par les utilisateurs.
Créer un filtre de contenu
Pour n’importe quel modèle de déploiement dans Azure AI Studio, vous pouvez utiliser directement le filtre de contenu par défaut, mais vous souhaiterez peut-être avoir plus de contrôle. Par exemple, vous pouvez rendre un filtre plus ou moins strict, ou activer des fonctionnalités plus avancées telles que les boucliers d’invite et la détection de matériel protégé.
Pour créer un filtre de contenu, effectuez les étapes suivantes :
Accédez à AI Studio et naviguez jusqu’à votre projet/hub. Sélectionnez ensuite l’onglet Sécurité dans le volet de navigation gauche, puis sélectionnez les Filtres de contenu.
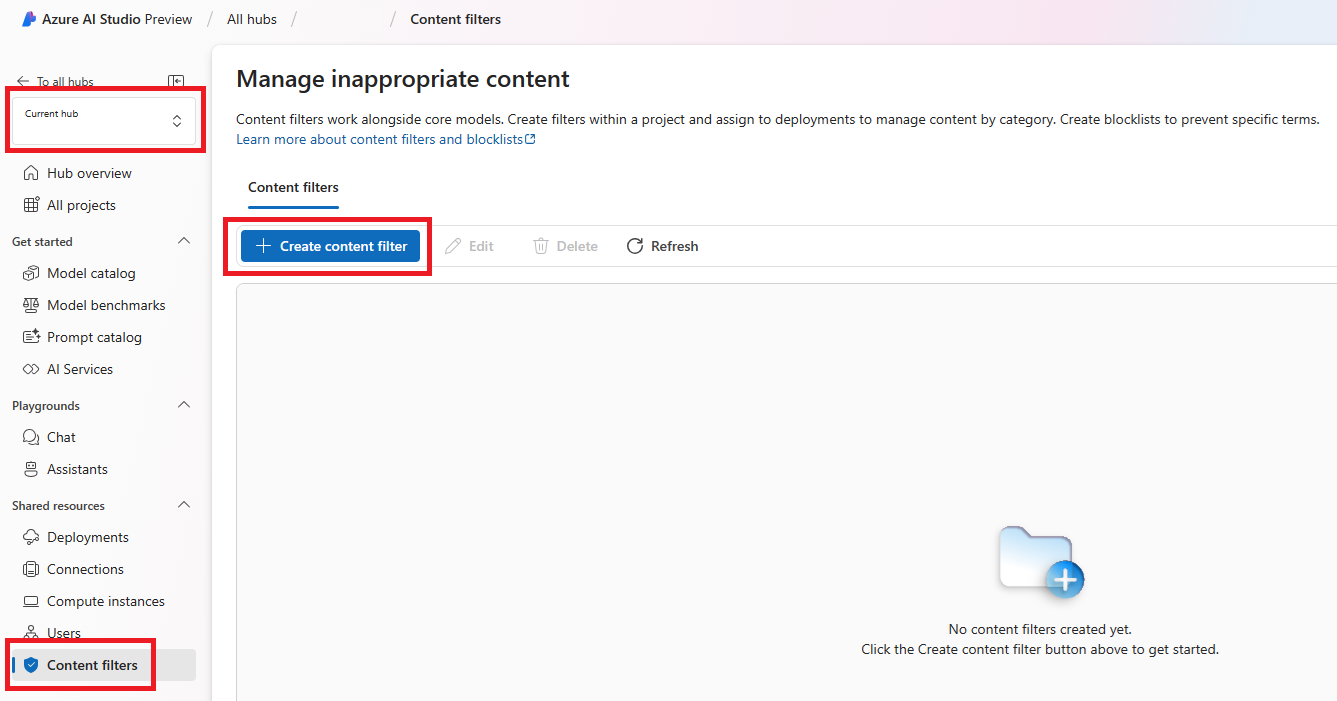
Sur la page Informations de base, entrez un nom pour votre filtre de contenu. Sélectionnez une connexion à associer au filtre de contenu. Sélectionnez ensuite Suivant.

Sélectionnez Créer un filtre de contenu.
Sur la page Filtres d’entrée, vous pouvez définir le filtre pour l’invite d’entrée. Définissez le seuil d’action et de niveau de gravité pour chaque type de filtre. Vous configurez à la fois les filtres par défaut et d’autres filtres (comme les Boucliers de prompt pour les attaques de jailbreak) sur cette page. Sélectionnez ensuite Suivant.

Le contenu est annoté par catégorie et bloqué en fonction du seuil que vous définissez. Pour les catégories violence, haine, sexuel et automutilation, ajustez le curseur pour bloquer le contenu de gravité haute, moyenne ou faible.
Sur la page Filtres de sortie, vous pouvez configurer le filtre de sortie, qui sera appliqué à tout le contenu de sortie généré par votre modèle. Configurez les filtres individuels comme avant. Cette page propose également l’option Mode de diffusion en continu, qui vous permet de filtrer le contenu en quasi-temps réel au fur et à mesure qu’il est généré par le modèle, réduisant ainsi la latence. Lorsque vous avez terminé, sélectionnez Suivant.
Le contenu est annoté pour chaque catégorie et bloqué en fonction du seuil. Pour le contenu violence, haine, sexuel et automutilation, ajustez le seuil pour bloquer le contenu dangereux avec des niveaux de gravité égaux ou supérieurs.
Si vous le souhaitez, sur la page Déploiement, vous pouvez associer le filtre de contenu à un déploiement. Si un déploiement sélectionné a déjà un filtre attaché, vous devez confirmer que vous souhaitez le remplacer. Vous pouvez également associer le filtre de contenu à un déploiement ultérieurement. Sélectionnez Créer.

Les configurations du filtrage de contenu sont créées au niveau du hub dans AI Studio. En savoir plus sur les possibilités de configuration dans la documentation Azure OpenAI.
Sous l’onglet Vérifier, passez en revue les paramètres, puis sélectionnez Créer le filtre.




Utilisation d’une liste de blocage comme filtre
Vous pouvez appliquer une liste de blocage en tant que filtre d’entrée ou de sortie, ou les deux. Activez l’option Liste de blocage sur la page Filtre d’entrée et/ou Filtre de sortie. Sélectionnez une ou plusieurs listes de blocage dans la liste déroulante, ou utilisez la liste de blocage de profanité intégrée. Vous pouvez combiner plusieurs listes de blocage dans le même filtre.
Application d’un filtre de contenu
Le processus de création de filtre vous donne la possibilité d’appliquer le filtre aux déploiements que vous souhaitez. Vous pouvez également modifier ou supprimer les filtres de contenu de vos déploiements à tout moment.
Procédez comme suit pour appliquer un filtre de contenu à un déploiement :
Accédez à AI Studio et sélectionnez un hub et un projet.
Sélectionnez Modèles + points de terminaison dans le volet gauche, puis choisissez l’un de vos déploiements, puis sélectionnez Modifier.

Dans la fenêtre Mettre à jour le déploiement, sélectionnez le filtre de contenu que vous souhaitez appliquer au déploiement.



Maintenant, vous pouvez accéder au terrain de jeu pour tester si le filtre de contenu fonctionne comme prévu.
Configuration (préversion)
La configuration du filtrage de contenu par défaut pour la série de modèles GPT est définie pour filtrer au seuil de gravité moyenne pour les quatre catégories de contenu dangereux (haine, violence, sexuel et automutilation) et s’applique aux invites (texte, texte/image multimodal) et aux achèvements (texte). Cela signifie que le contenu détecté au niveau de gravité moyenne ou élevée est filtré, tandis que le contenu détecté au niveau de gravité faible n’est pas filtré par les filtres de contenu. Pour DALL-E, le seuil de gravité par défaut est défini sur faible pour les invites (texte) et les achèvements (images), de sorte que le contenu détecté aux niveaux de gravité faible, moyenne ou élevée est filtré.
La fonctionnalité de configurabilité permet aux clients d’ajuster les paramètres, séparément pour les prompts et les achèvements, afin de filtrer le contenu pour chaque catégorie de contenu à différents niveaux de gravité, comme décrit dans le tableau ci-dessous :
| Gravité filtrée | Configurable pour les invites | Configurable pour la saisie semi-automatique | Descriptions |
|---|---|---|---|
| Faible, moyen, élevé | Oui | Oui | Configuration de filtrage la plus stricte. Le contenu détecté aux niveaux de gravité bas, moyen et élevé est filtré. |
| Moyen, élevé | Oui | Oui | Le contenu détecté au niveau de gravité faible n’est pas filtré. Le contenu moyen et élevé est filtré. |
| Élevé | Oui | Oui | Le contenu détecté aux niveaux de gravité faible et moyen n'est pas filtré. Seul le contenu au niveau de gravité élevé est filtré. Nécessite une approbation1. |
| Aucun filtre | En cas d’approbation1 | En cas d’approbation1 | Aucun contenu n’est filtré quel que soit le niveau de gravité détecté. Nécessite une approbation1. |
1Pour les modèles Azure OpenAI, seuls les clients qui ont été approuvés pour le filtrage de contenu modifié disposent d’un contrôle total sur le filtrage de contenu, y compris la configuration des filtres de contenu à un niveau de gravité élevé uniquement ou la désactivation des filtres de contenu. Demander un filtre de contenu modifié via ce formulaire : Révision d’accès limité Azure OpenAI : filtres de contenu modifié et surveillance des abus (microsoft.com)
Les clients sont chargés de s’assurer que les applications intégrant Azure OpenAI sont conformes au Code de conduite.
Étapes suivantes
- Découvrez-en plus sur les modèles sous-jacents d’Azure OpenAI.
- Le filtrage de contenu Azure AI Studio est optimisé par Azure AI Sécurité du Contenu.
- En savoir plus sur la compréhension et l’atténuation des risques associés à votre application : Vue d’ensemble des pratiques d’IA responsable pour les modèles Azure OpenAI.
- En savoir plus sur l’évaluation de vos modèles IA et systèmes d’IA générative via Azure AI Evaluation.