Surveiller la qualité et l’utilisation des jetons des applications de flux d’invite déployées
Important
Les éléments marqués (préversion) dans cet article sont actuellement en préversion publique. Cette préversion est fournie sans contrat de niveau de service, nous la déconseillons dans des charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
La surveillance des applications déployées en production est une partie essentielle du cycle de vie des applications d’IA générative. Les changements dans les données et le comportement des consommateurs peuvent influencer votre application au fil du temps. Cela entraîne des systèmes obsolètes qui affectent négativement les résultats de l’entreprise et exposent les organisations à des risques économiques, de conformité et de réputation.
Remarque
Pour améliorer la surveillance continue des applications déployées (autres que le flux d'invite), envisagez d'utiliser l'évaluation en ligne Azure AI.
La surveillance d’Azure AI pour les applications d’IA générative vous permet de surveiller l’utilisation des jetons, la qualité de génération et les métriques opérationnelles de vos applications en production.
Les intégrations pour la surveillance d’un déploiement de flux d’invite vous permettent de :
- Collecter les données d’inférence de production à partir de votre application de flux d’invite déployée.
- Appliquer des métriques d’évaluation d’IA responsable telles que le fondement, la cohérence, la fluidité et la pertinence, qui sont interopérables avec les métriques d’évaluation de flux d’invite.
- Surveiller les prompts, la complétion et l’utilisation totale des jetons sur chaque déploiement de modèle dans votre flux d’invite.
- Surveiller les métriques opérationnelles, telles que le nombre de requêtes, la latence et le taux d’erreur.
- Utiliser des alertes préconfigurées et des paramètres par défaut afin d’exécuter la surveillance de manière périodique.
- Consommer des visualisations de données et configurer un comportement avancé dans le portail Azure AI Foundry.
Prérequis
Avant de suivre les étapes décrites dans cet article, vérifiez que vous disposez des composants requis suivants :
Un abonnement Azure avec un moyen de paiement valide. Les abonnements Azure gratuits ou d’essai ne sont pas pris en charge pour ce scénario. Si vous ne disposez pas d’un abonnement Azure, commencez par créer un compte Azure payant.
Un flux d’invite prêt pour le déploiement. Si vous n’en avez pas, consultez Développer un flux d’invite.
Les contrôles d’accès en fonction du rôle Azure (RBAC Azure) sont utilisés pour accorder l’accès aux opérations dans le portail Azure AI Foundry. Pour effectuer les étapes décrites dans cet article, votre compte d’utilisateur doit avoir le Rôle de développeur Azure AI sur le groupe de ressources. Pour plus d’informations sur les autorisations, consultez Contrôle d’accès en fonction du rôle sur le portail Azure AI Foundry.
Conditions requises pour les métriques de surveillance
Les métriques de surveillance sont générées par certains modèles de langage GPT de pointe configurés avec des instructions d’évaluation spécifiques (modèles de prompt). Ces modèles servent de modèles d’évaluation pour les tâches de séquence à séquence. L’utilisation de cette technique pour générer des métriques de surveillance a des résultats empiriques solides et une corrélation élevée avec le jugement humain par rapport aux métriques d’évaluation d’IA générative standard. Pour plus d’informations sur l’évaluation des flux d’invite, consultez Envoyer un test en bloc et évaluer un flux et Métriques d’évaluation et de monitoring pour l’IA générative.
Les modèles GPT qui génèrent des métriques de surveillance sont les suivants. Ces modèles GPT sont pris en charge avec une surveillance et configurés en tant que ressource Azure OpenAI :
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
Métriques prises en charge pour la surveillance
Les métriques suivantes sont prises en charge pour la surveillance :
| Métrique | Description |
|---|---|
| Fondement | Détermine la façon dont les réponses générées du modèle s’alignent sur les informations de la source d’entrée (contexte défini par l’utilisateur). |
| Pertinence | Détermine dans quelle mesure les réponses générées par le modèle sont pertinentes et directement liées aux questions données. |
| Cohérence | Mesure la mesure dans laquelle les réponses générées du modèle sont logiquement cohérentes et connectées. |
| Maîtrise | Détermine la maîtrise grammaticale d’une réponse prédite par l’IA générative. |
Mappage des noms de colonnes
Lors de la création de votre flux, vous devez vous assurer que vos noms de colonnes sont mappés. Les noms des colonnes des données d’entrée suivantes sont utilisés pour mesurer la sécurité et la qualité de la génération :
| Nom de la colonne d’entrée | Définition | Obligatoire ou facultatif |
|---|---|---|
| Question | L’invite d’origine donnée (également appelée « entrées » ou « question ») | Requis |
| Réponse | L’achèvement final de l’appel d’API retourné (également appelé « sorties » ou « réponse ») | Requis |
| Context | Toutes les données de contexte envoyées à l’appel d’API, ainsi que l’invite d’origine. Par exemple, si vous souhaitez obtenir des résultats de recherche uniquement à partir de certaines sources d’informations ou sites web certifiés, vous pouvez définir ce contexte dans les étapes d’évaluation. | Facultatif |
Paramètres requis pour les métriques
Les paramètres configurés dans votre ressource de données déterminent les métriques que vous pouvez produire, en fonction de ce tableau :
| Mesure | Question | Réponse | Context |
|---|---|---|---|
| Cohérence | Requis | Requis | - |
| Maîtrise | Requis | Requis | - |
| Fondement | Requis | Obligatoire | Requis |
| Pertinence | Requis | Obligatoire | Requis |
Pour plus d’informations sur les exigences de mappage de données spécifiques pour chaque métrique, consultez Exigences en matière de métriques de requête et de réponse.
Configurer la surveillance pour le flux d’invite
Pour configurer la surveillance de votre application de flux d’invite, vous devez d’abord déployer votre application de flux d’invite avec une collecte de données d’inférence, après quoi vous pouvez configurer la surveillance de l’application déployée.
Déployer votre application de flux d’invite avec collecte de données d’inférence
Dans cette section, vous allez découvrir comment déployer votre flux d’invite avec la collecte de données d’inférence activée. Pour plus d’informations sur le déploiement de votre flux d’invite, consultez Déployer un flux pour l’inférence en temps réel.
Connectez-vous à Azure AI Foundry.
Si vous n’êtes pas déjà dans votre projet, sélectionnez-le.
Sélectionnez Flux d’invite dans la barre de navigation de gauche.
Sélectionnez le flux d’invite que vous avez créé précédemment.
Remarque
Cet article part du principe que vous avez déjà créé un flux d’invite prêt pour le déploiement. Si vous n’en avez pas, consultez Développer un flux d’invite.
Vérifiez que votre flux s’exécute correctement et que les entrées et sorties requises sont configurées pour les métriques que vous souhaitez évaluer.
Si vous ne spécifiez que les paramètres minimum requis (questions/entrées et réponses/sorties), seules deux métriques sont disponibles : cohérence et fluidité. Vous devez configurer votre flux comme décrit dans la section Conditions requises pour les métriques de surveillance. Cet exemple utilise
question(Question) etchat_history(Contexte) comme entrées de flux, etanswer(Réponse) comme sortie de flux.Sélectionnez Déployer pour commencer le déploiement de votre flux.
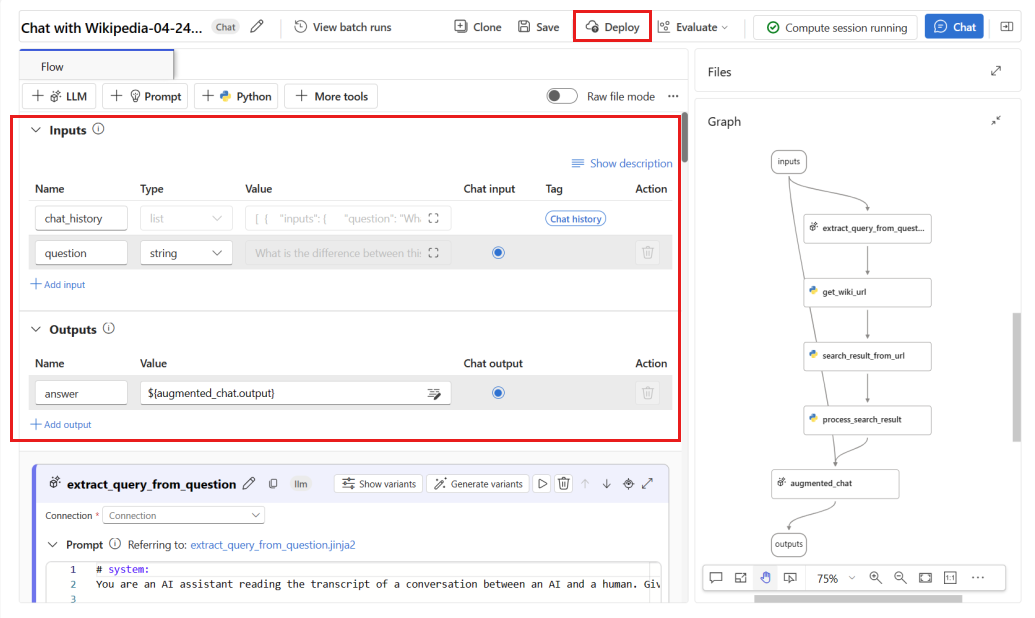
Dans la fenêtre de déploiement, vérifiez que la collecte de données d’inférence est activée, ce qui permet de collecter en toute transparence les données d’inférence de votre application vers Stockage Blob. Cette collecte de données est requise pour la surveillance.
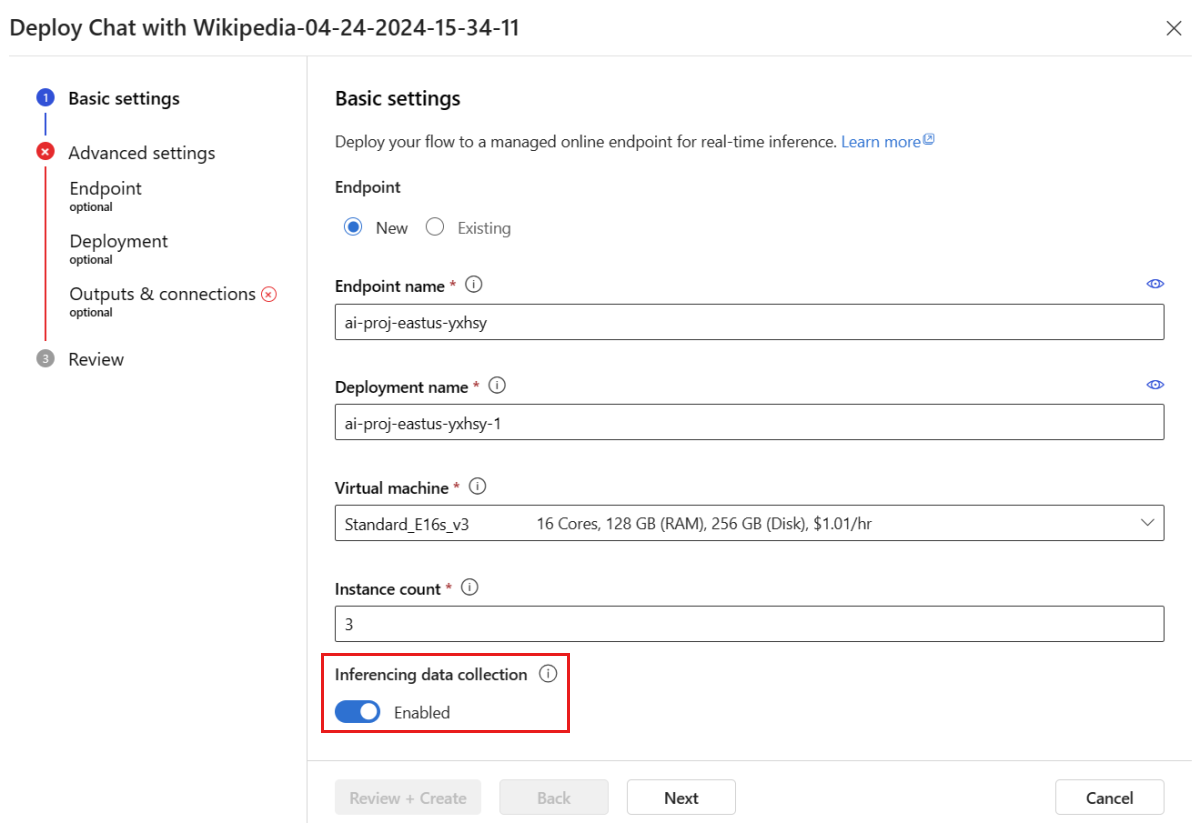
Suivez les étapes de la fenêtre de déploiement pour finir de spécifier les Paramètres avancés.
Dans la page « Vérifier », passez en revue la configuration du déploiement et sélectionnez Créer pour déployer votre flux.
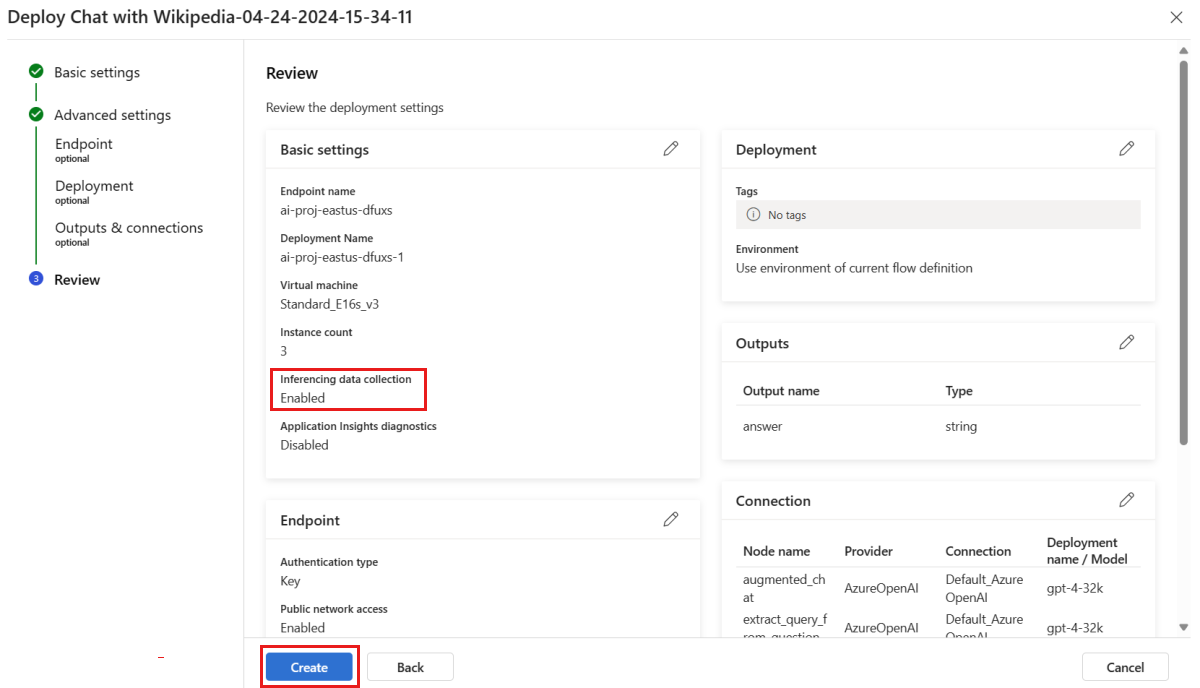
Remarque
Par défaut, toutes les entrées et sorties de votre application de flux d’invite déployée sont collectées dans votre service Stockage Blob. Lorsque le déploiement est appelé par les utilisateurs, les données sont collectées pour être utilisées par votre moniteur.
Sélectionnez l’onglet Test dans la page de déploiement, puis testez votre déploiement pour vérifier qu’il fonctionne correctement.
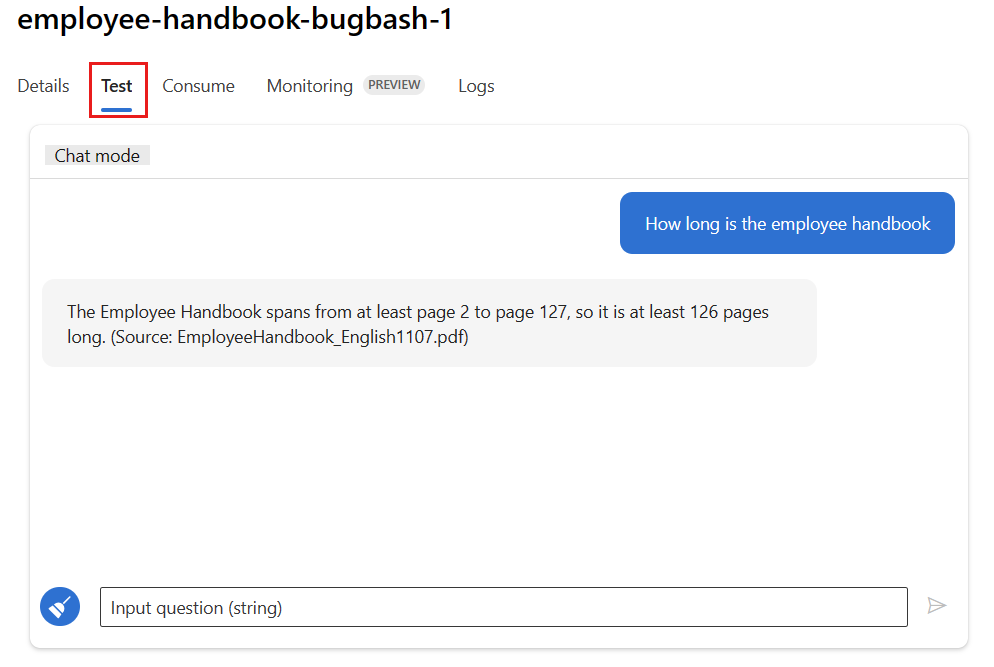
Remarque
La surveillance nécessite qu’au moins un point de données provienne d’une source autre que l’onglet Test dans le déploiement. Nous vous recommandons d’utiliser l’API REST disponible sous l’onglet Consommer pour envoyer des exemples de requêtes à votre déploiement. Pour plus d’informations sur l’envoi d’exemples de requêtes à votre déploiement, consultez Créer un déploiement en ligne.




Configuration de l’analyse
Dans cette section, vous allez apprendre à configurer la surveillance de votre application de flux d’invite déployée.
Dans la barre de navigation de gauche, accédez à Mes ressources>Modèles + points de terminaison.
Sélectionnez le déploiement de flux d’invite que vous avez créé.
Sélectionnez Activer dans la zone Activer la surveillance de la qualité de la génération.
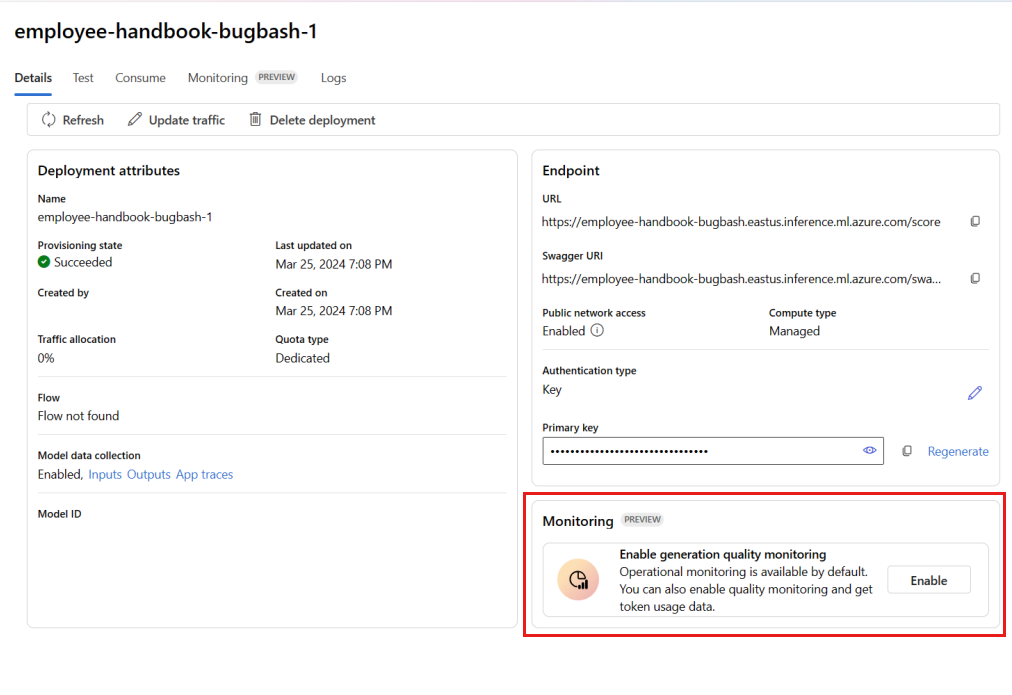
Commencez à configurer la surveillance en sélectionnant les métriques souhaitées.
Vérifiez que les noms des colonnes sont mappés à partir de votre flux, comme défini dans Mappage des noms de colonnes.
Sélectionnez la Connexion Azure OpenAI et le Déploiement que vous souhaitez utiliser pour effectuer la surveillance de votre application de flux d’invite.
Sélectionnez Options avancées pour afficher d’autres options à configurer.

Ajustez le taux d’échantillonnage et les seuils de vos métriques configurées, et spécifiez les adresses e-mail qui doivent recevoir des alertes lorsque le score moyen d’une métrique donnée est inférieur au seuil.
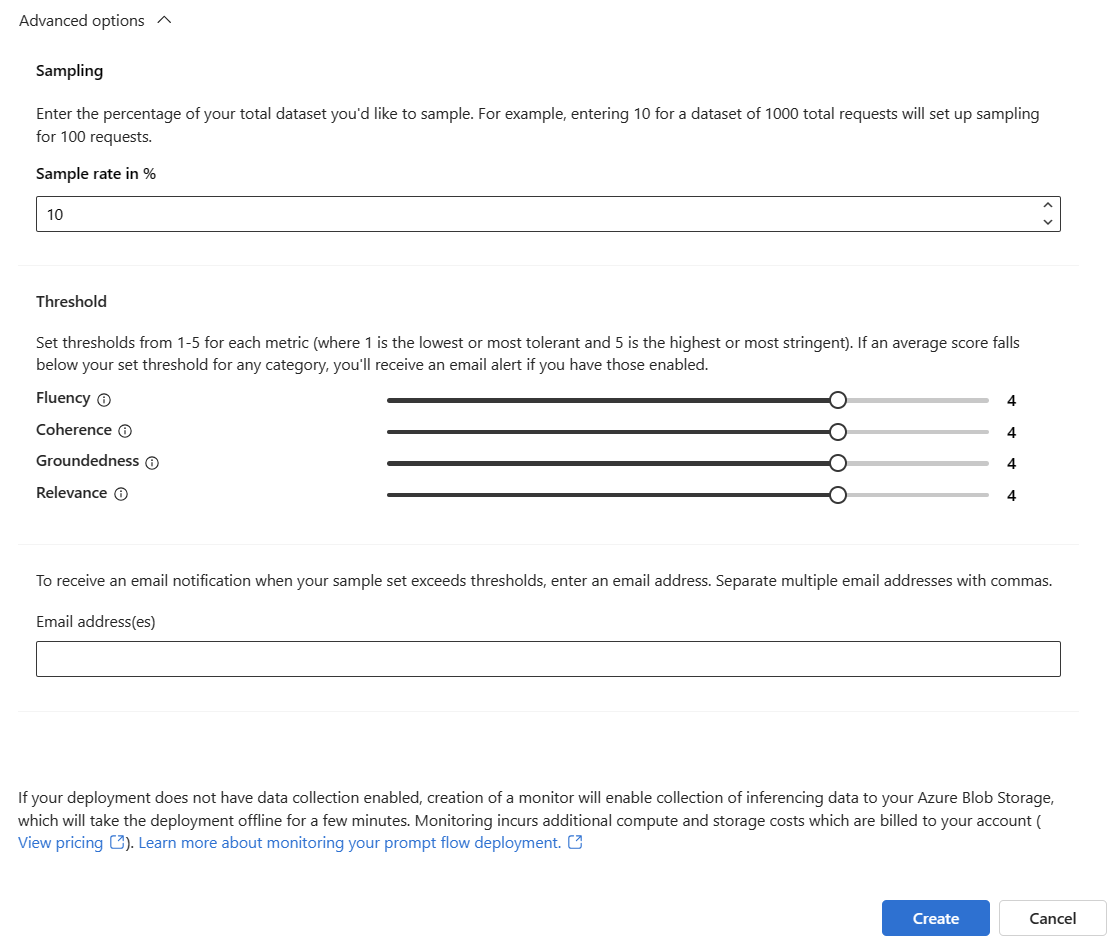
Remarque
Si la collecte de données n’est pas activée pour votre déploiement, la création d’un moniteur active la collecte de données d’inférence vers votre service Stockage Blob Azure, ce qui provoquera la mise hors connexion du déploiement pendant quelques minutes.
Sélectionnez Créer pour créer votre moniteur.



Consommer les résultats de la supervision
Après avoir créé votre moniteur, il s’exécute quotidiennement pour calculer les métriques d’utilisation des jetons et de qualité de génération.
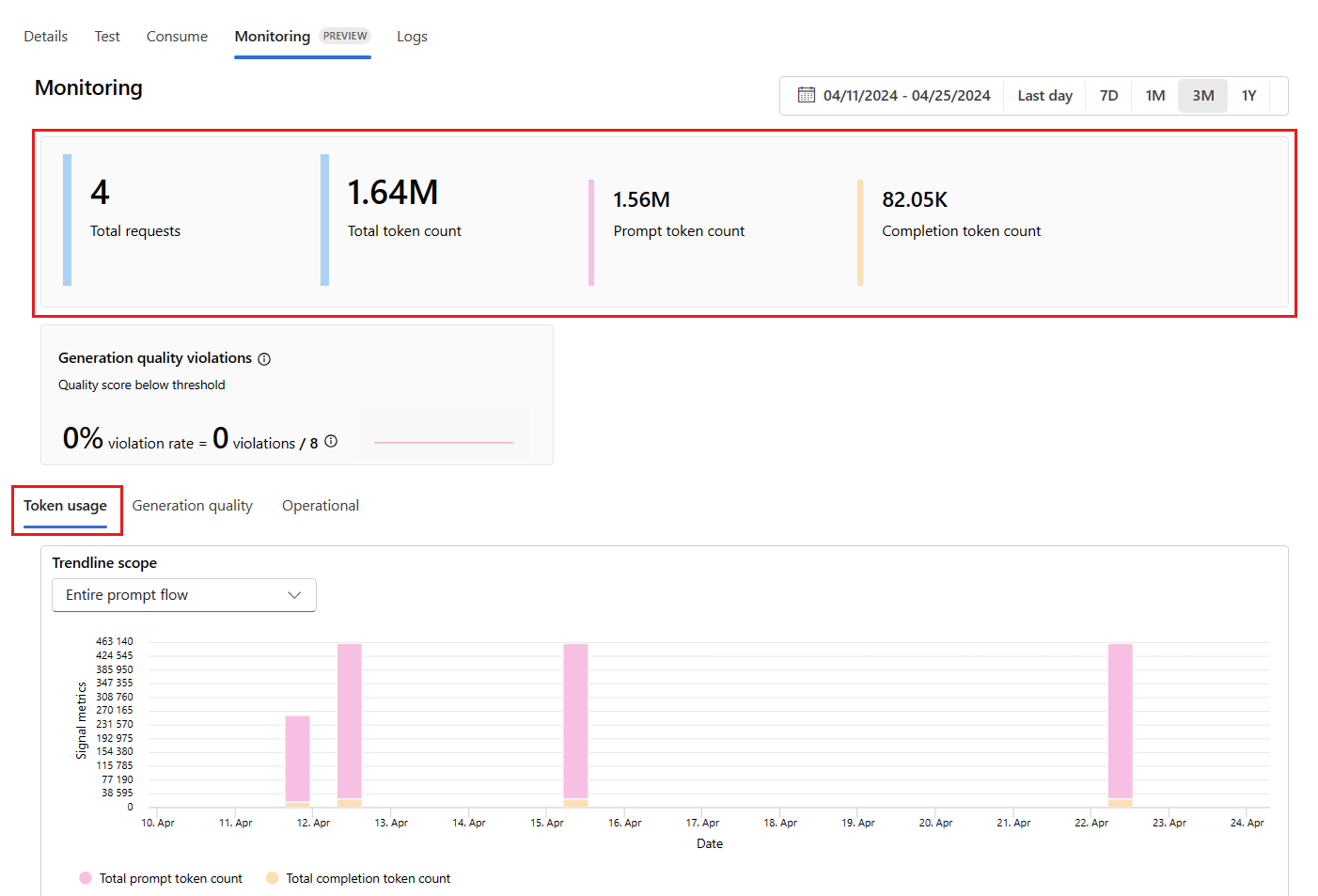
Accédez à l’onglet Surveillance (préversion) à partir du déploiement pour afficher les résultats de la surveillance. Ici, vous voyez une vue d’ensemble des résultats de surveillance pendant la fenêtre de temps sélectionnée. Vous pouvez utiliser le sélecteur de dates pour modifier la fenêtre de temps des données que vous surveillez. Les métriques suivantes sont disponibles dans cette vue d’ensemble :
- Nombre total de requêtes : nombre total de requêtes envoyées au déploiement pendant la fenêtre de temps sélectionnée.
- Nombre total de jetons : nombre total de jetons utilisés par le déploiement pendant la fenêtre de temps sélectionnée.
- Nombre de jetons d’invite : nombre de jetons d’invite utilisés par le déploiement pendant la fenêtre de temps sélectionnée.
- Nombre de jetons de complétion : nombre de jetons de complétion utilisés par le déploiement pendant la fenêtre de temps sélectionnée.
Affichez les métriques sous l’onglet Utilisation de jeton (cet onglet est sélectionné par défaut). Ici, vous pouvez afficher l’utilisation des jetons de votre application au fil du temps. Vous pouvez également afficher la distribution des jetons d’invite et de complétion au fil du temps. Vous pouvez modifier l’Étendue de courbe de tendance pour surveiller tous les jetons dans l’ensemble de l’application ou l’utilisation des jetons pour un déploiement particulier (par exemple, gpt-4) utilisé dans votre application.
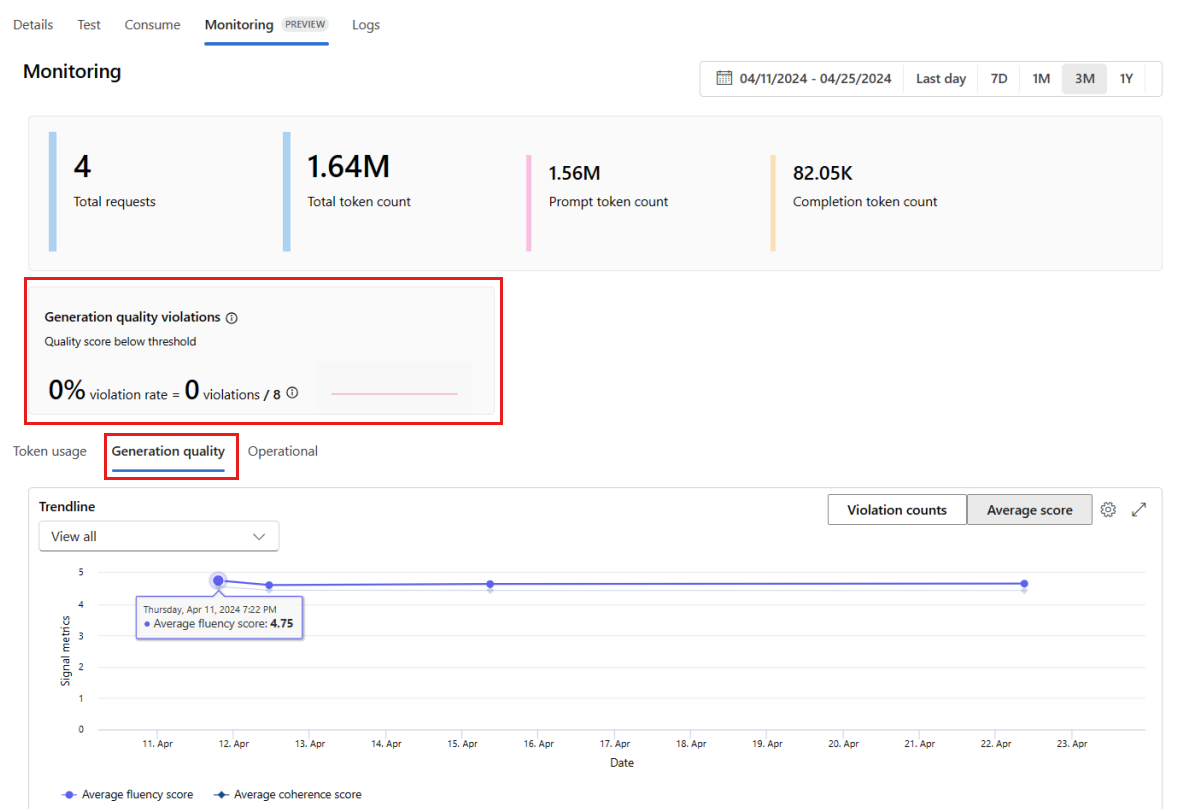
Accédez à l’onglet Qualité de génération pour surveiller la qualité de votre application au fil du temps. Les métriques suivantes sont affichées dans l’organigramme :
- Nombre de violations : le nombre de violations pour une métrique donnée (par exemple, Fluidité) est la somme des violations pendant la fenêtre de temps sélectionnée. Une violation se produit pour une métrique lorsque les métriques sont calculées (par défaut, quotidiennement) si la valeur calculée de la métrique est inférieure à la valeur de seuil définie.
- Score moyen : le score moyen d’une métrique donnée (par exemple, Fluidité) correspond à la somme des scores pour toutes les instances (ou requêtes) divisée par le nombre d’instances (ou requêtes) pendant la fenêtre de temps sélectionnée.
La carte Violations de qualité de génération affiche le taux de violation pendant la fenêtre de temps sélectionnée. Le taux de violation est le nombre de violations divisé par le nombre total de violations possibles. Vous pouvez ajuster les seuils des métriques dans les paramètres. Par défaut, les métriques sont calculées quotidiennement ; cette fréquence peut également être ajustée dans les paramètres.
Sous l’onglet Surveillance (préversion), vous pouvez également afficher un tableau complet de toutes les requêtes échantillonnées envoyées au déploiement pendant la fenêtre de temps sélectionnée.
Remarque
La surveillance définit le taux d’échantillonnage par défaut à 10 %. Cela signifie que si 100 requêtes sont envoyées à votre déploiement, 10 sont échantillonnées et utilisées pour calculer les métriques de qualité de génération. Vous pouvez ajuster le taux d’échantillonnage dans les paramètres.
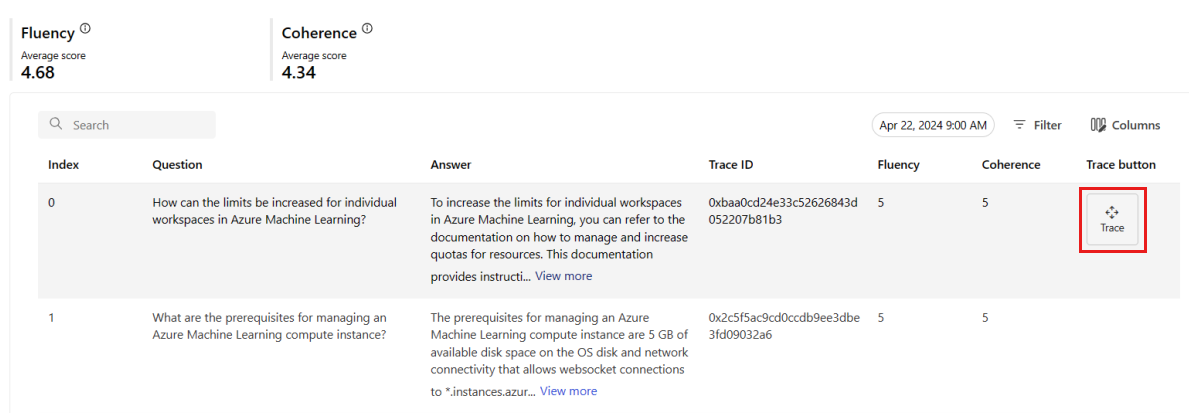
Sélectionnez le bouton Trace à droite d’une ligne du tableau pour afficher les détails du traçage pour une requête donnée. Cette vue fournit des détails de trace complets pour la requête adressée à votre application.
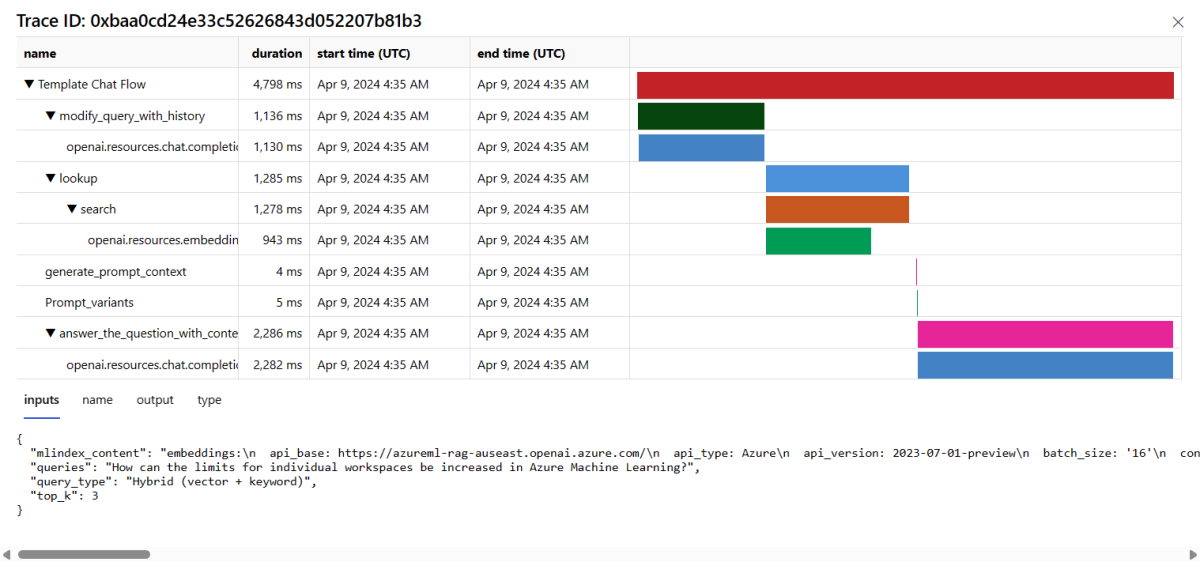
Fermez la vue Trace.
Accédez à l’onglet Opérationnel pour afficher les métriques opérationnelles du déploiement en quasi-temps réel. Nous prenons en charge les métriques opérationnelles suivantes :
- Nombre de demandes
- Latence
- Taux d’erreur
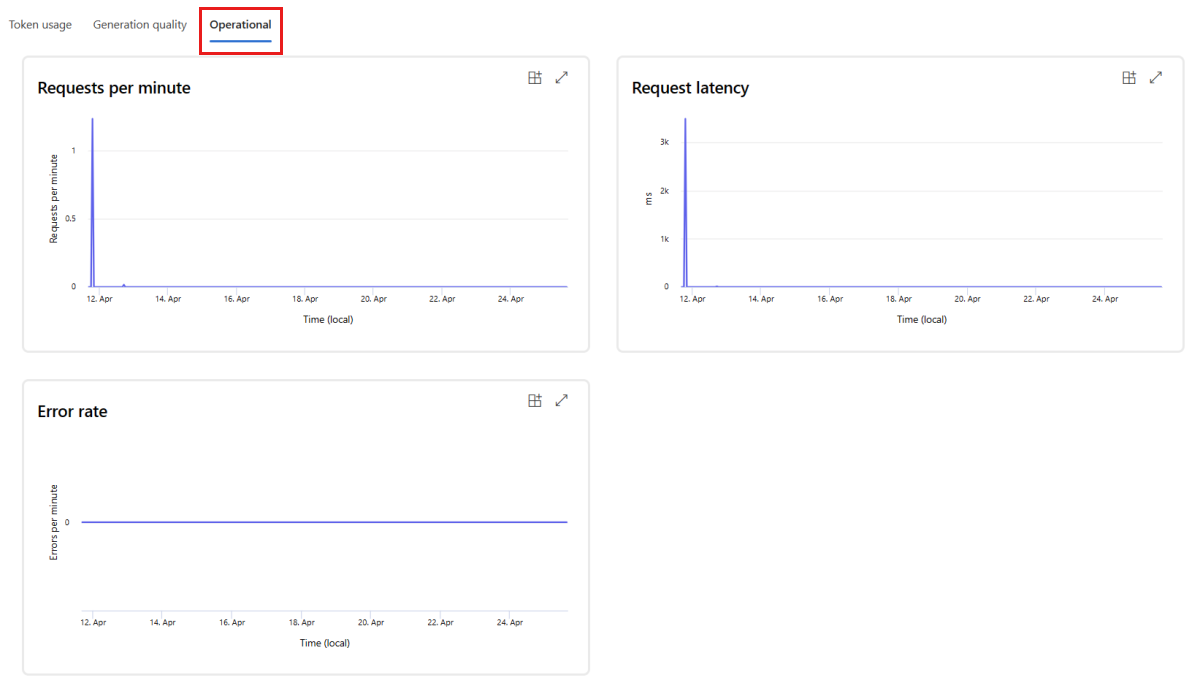





Les résultats affichés sous l’onglet Surveillance (préversion) de votre déploiement fournissent des insights pour vous aider à améliorer de manière proactive les performances de votre application de flux d’invite.
Configuration avancée de la surveillance avec le SDK v2
La surveillance prend également en charge des options de configuration avancées avec le SDK v2. Les scénarios suivants sont pris en charge :
Activer la surveillance de l’utilisation des jetons
Si vous souhaitez uniquement activer la surveillance de l’utilisation des jetons pour votre application de flux d’invite déployée, vous pouvez adapter le script suivant à votre scénario :
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Activer la surveillance de la qualité de génération
Si vous souhaitez uniquement activer la surveillance de la qualité de génération pour votre application de flux d’invite déployée, vous pouvez adapter le script suivant à votre scénario :
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{project_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Après avoir créé votre moniteur à partir du kit SDK, vous pouvez consommer les résultats de surveillance dans Azure AI Foundry.
Contenu connexe
- En savoir plus sur ce que vous pouvez faire dans Azure AI Foundry.
- Obtenez des réponses aux questions les plus fréquentes dans la FAQ Azure AI.