API Temps réel GPT-4o pour les messages et l’audio (préversion)
Remarque
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service, nous la déconseillons dans des charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
L’API Temps réel GPT-4o d’Azure OpenAI pour les messages et l’audio fait partie de la famille de modèles GPT-4o qui prend en charge les interactions conversationnelles à latence faible « entrée vocale, sortie vocale ». L’API Audio realtime GPT-4o est conçue pour gérer les interactions conversationnelles en temps réel et à latence faible, ce qui en fait un excellent choix pour les cas d’usage impliquant des interactions directes entre un utilisateur et un modèle, comme des agents d’un service clientèle, des assistants vocaux et des traducteurs en temps réel.
La plupart des utilisateurs de l’API Temps réel doivent fournir et recevoir de l’audio d’un utilisateur final en temps réel, y compris des applications qui utilisent WebRTC ou un système de téléphonie. L’API Temps réel n’est pas conçue pour se connecter directement aux appareils des utilisateurs finaux et s’appuie sur des intégrations de clients pour mettre fin aux flux audio des utilisateurs finaux.
Modèles pris en charge
Les modèles GPT 4o en temps réel sont disponibles pour les déploiements globaux.
-
gpt-4o-realtime-preview(version2024-12-17) -
gpt-4o-mini-realtime-preview(version2024-12-17) -
gpt-4o-realtime-preview(version2024-10-01)
Pour plus d’informations, consultez la documentation sur les modèles et les versions.
Prise en charge des API
La prise en charge de l’API Temps réel a été ajoutée pour la première fois dans la version 2024-10-01-preview de l’API. Utilisez la dernière version 2024-12-17 du modèle.
Déployer un modèle pour l’audio en temps réel
Pour déployer le modèle gpt-4o-mini-realtime-preview dans le portail Azure AI Foundry :
- Accédez à la page Azure OpenAI Service dans le portail Azure AI Foundry. Vérifiez que vous êtes connecté avec l’abonnement Azure disposant de votre ressource Azure OpenAI Service (avec ou sans déploiements de modèles).
- Sélectionnez le terrain de jeu Audio en temps réel sous Terrains de jeu dans le volet gauche.
- Sélectionnez + Créer un déploiement>À partir de modèles de base pour ouvrir la fenêtre de déploiement.
- Recherchez et sélectionnez le modèle
gpt-4o-mini-realtime-preview, puis sélectionnez Déployer sur une ressource sélectionnée. - Dans l’Assistant de déploiement, sélectionnez la version du modèle
2024-12-17. - Suivez l’Assistant pour terminer le déploiement du modèle.
Maintenant que vous disposez d’un déploiement du modèle gpt-4o-mini-realtime-preview, vous pouvez interagir avec lui en temps réel dans le terrain de jeu Audio en temps réel le portail Azure AI Foundry ou l’API Temps réel.
Utiliser l’audio en temps réel GPT-4o
Pour discuter avec votre modèle gpt-4o-mini-realtime-preview déployé dans le terrain de jeu audio en temps réel d’Azure AI Foundry, procédez comme suit :
Accédez à la page Azure OpenAI Service dans le portail Azure AI Foundry. Vérifiez que vous êtes connecté avec l’abonnement Azure qui a votre ressource Azure OpenAI Service et le modèle
gpt-4o-mini-realtime-previewdéployé.Sélectionnez le terrain de jeu Audio en temps réel sous Terrains de jeu dans le volet gauche.
Sélectionnez votre modèle
gpt-4o-mini-realtime-previewdéployé dans la liste déroulante Déploiement.Sélectionnez Activer le microphone pour autoriser le navigateur à accéder à votre microphone. Si vous avez déjà accordé l’autorisation, vous pouvez ignorer cette étape.
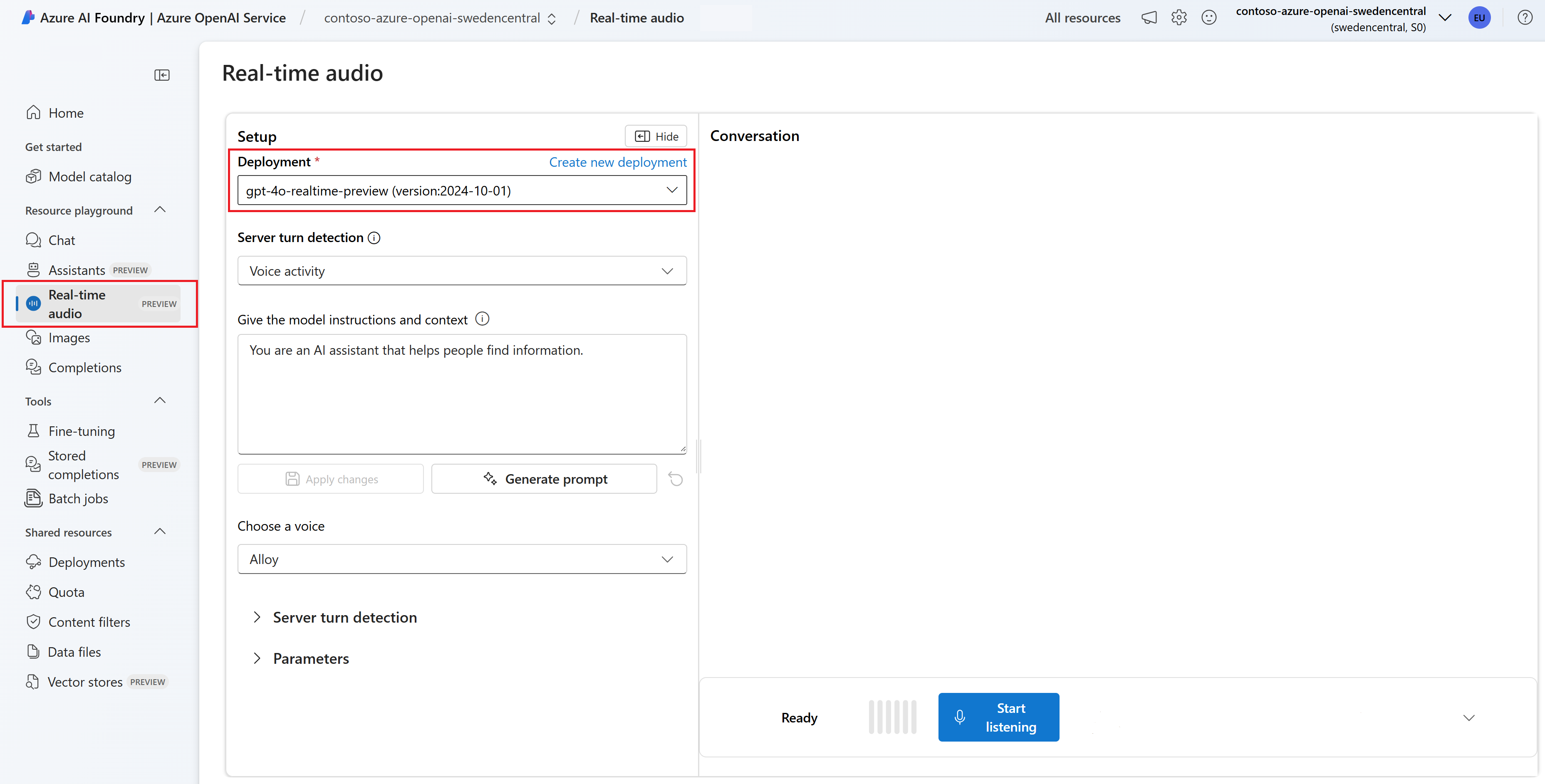
Si vous le souhaitez, vous pouvez modifier le contenu dans la zone de texte Fournir au modèle des instructions et un contexte. Fournissez au modèle des instructions sur son comportement et sur tout contexte qu’il doit référencer en générant une réponse. Vous pouvez décrire la personnalité de l’assistant, lui dire ce qu’il doit et ne doit pas répondre, et lui indiquer comment formater les réponses.
Si vous le souhaitez, modifiez les paramètres tels que le seuil, le remplissage de préfixes et la durée du silence.
Sélectionnez Démarrer l’écoute pour démarrer la session. Vous pouvez parler dans le microphone pour démarrer une conversation.
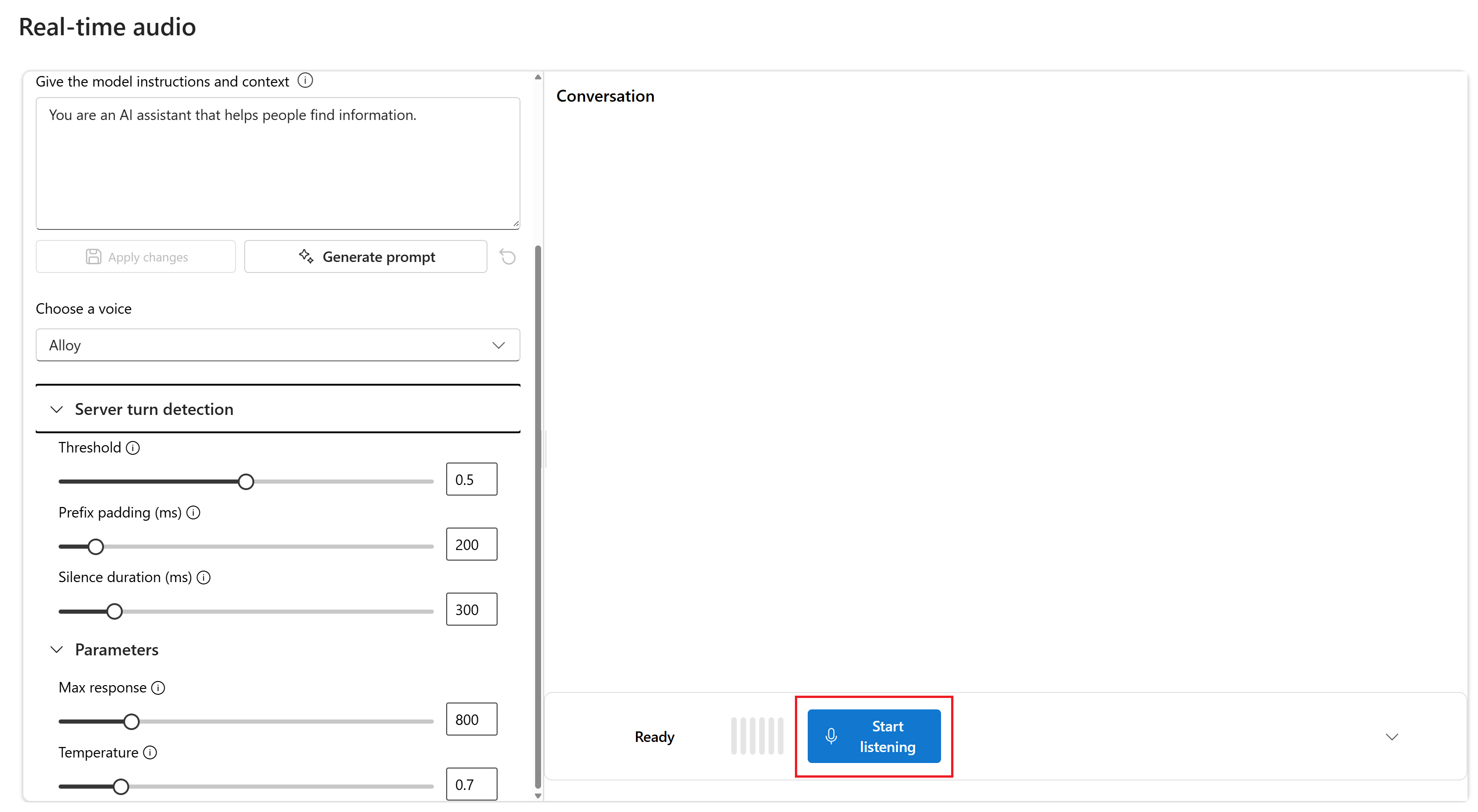
Vous pouvez interrompre la conversation à tout moment en parlant. Vous pouvez mettre fin à la conversation en sélectionnant le bouton Arrêter l’écoute.


Prérequis
- Un abonnement Azure - En créer un gratuitement
- Prise en charge de Node.js LTS ou ESM.
- Une ressource Azure OpenAI créée dans l’une des régions prises en charge. Pour plus d’informations sur la disponibilité régionale, consultez la documentation sur les modèles et les versions.
- Ensuite, vous devez déployer un modèle
gpt-4o-mini-realtime-previewavec votre ressource Azure OpenAI. Pour plus d’informations, consultez l’article Créer une ressource et déployer un modèle à l’aide d’Azure OpenAI.
Prérequis pour Microsoft Entra ID
Pour l’authentification sans clé recommandée avec Microsoft Entra ID, vous devez effectuer les tâches suivantes :
- Installez l’interface Azure CLI utilisée pour l’authentification sans clé avec Microsoft Entra ID.
- Attribuez le rôle
Cognitive Services Userà votre compte d’utilisateur. Vous pouvez attribuer des rôles dans le Portail Azure sous Contrôle d’accès (IAM)>Ajouter une attribution de rôle.
Déployer un modèle pour l’audio en temps réel
Pour déployer le modèle gpt-4o-mini-realtime-preview dans le portail Azure AI Foundry :
- Accédez à la page Azure OpenAI Service dans le portail Azure AI Foundry. Vérifiez que vous êtes connecté avec l’abonnement Azure disposant de votre ressource Azure OpenAI Service (avec ou sans déploiements de modèles).
- Sélectionnez le terrain de jeu Audio en temps réel sous Terrains de jeu dans le volet gauche.
- Sélectionnez + Créer un déploiement>À partir de modèles de base pour ouvrir la fenêtre de déploiement.
- Recherchez et sélectionnez le modèle
gpt-4o-mini-realtime-preview, puis sélectionnez Déployer sur une ressource sélectionnée. - Dans l’Assistant de déploiement, sélectionnez la version du modèle
2024-12-17. - Suivez l’Assistant pour terminer le déploiement du modèle.
Maintenant que vous disposez d’un déploiement du modèle gpt-4o-mini-realtime-preview, vous pouvez interagir avec lui en temps réel dans le terrain de jeu Audio en temps réel le portail Azure AI Foundry ou l’API Temps réel.
Configurer
Créez un dossier
realtime-audio-quickstartpour contenir l’application et ouvrez Visual Studio Code dans ce dossier avec la commande suivante :mkdir realtime-audio-quickstart && code realtime-audio-quickstartCréez le
package.jsonavec la commande suivante :npm init -yMettez à jour le
package.jsonvers ECMAScript avec la commande suivante :npm pkg set type=moduleInstallez la bibliothèque de client audio en temps réel pour JavaScript avec :
npm install https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/js/v0.5.2/rt-client-0.5.2.tgzPour l’authentification sans clé recommandée avec Microsoft Entra ID, installez le package
@azure/identityavec :npm install @azure/identity
Récupérer des informations sur les ressources
Vous devez récupérer les informations suivantes pour authentifier votre application auprès de votre ressource Azure OpenAI :
| Nom de la variable | Valeur |
|---|---|
AZURE_OPENAI_ENDPOINT |
Cette valeur se trouve dans la section Clés et point de terminaison quand vous examinez votre ressource à partir du portail Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Cette valeur correspond au nom personnalisé que vous avez choisi pour votre déploiement lorsque vous avez déployé un modèle. Cette valeur peut être trouvée dans le Portail Azure sous Gestion des ressources>Déploiements de modèles. |
OPENAI_API_VERSION |
En savoir plus sur les versions d’API. |
En savoir plus sur l’authentification sans clé et la définition de variables d’environnement.
Attention
Pour utiliser l’authentification sans clé recommandée avec le kit de développement logiciel (SDK), vérifiez que la variable d’environnement AZURE_OPENAI_API_KEY n’est pas définie.
Texte en entrée et audio en sortie
Remplacez le fichier
text-in-audio-out.jsavec le code suivant :import { DefaultAzureCredential } from "@azure/identity"; import { LowLevelRTClient } from "rt-client"; import dotenv from "dotenv"; dotenv.config(); async function text_in_audio_out() { // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "yourEndpoint"; const deployment = "gpt-4o-mini-realtime-preview"; if (!endpoint || !deployment) { throw new Error("You didn't set the environment variables."); } const client = new LowLevelRTClient(new URL(endpoint), new DefaultAzureCredential(), { deployment: deployment }); try { await client.send({ type: "response.create", response: { modalities: ["audio", "text"], instructions: "Please assist the user." } }); for await (const message of client.messages()) { switch (message.type) { case "response.done": { break; } case "error": { console.error(message.error); break; } case "response.audio_transcript.delta": { console.log(`Received text delta: ${message.delta}`); break; } case "response.audio.delta": { const buffer = Buffer.from(message.delta, "base64"); console.log(`Received ${buffer.length} bytes of audio data.`); break; } } if (message.type === "response.done" || message.type === "error") { break; } } } finally { client.close(); } } await text_in_audio_out();Connectez-vous à Azure à l’aide de la commande suivante :
az loginExécutez le fichier JavaScript.
node text-in-audio-out.js
Attendez quelques instants pour obtenir une réponse.
Sortie
Le script obtient une réponse du modèle et affiche les données de transcription et audio reçues.
La sortie ressemble à l'exemple suivant :
Received text delta: Hello
Received text delta: !
Received text delta: How
Received text delta: can
Received text delta: I
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: help
Received 12000 bytes of audio data.
Received text delta: you
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 24000 bytes of audio data.
Exemple d’application web
Notre exemple web JavaScript sur GitHub montre comment utiliser l’API GPT-4o Realtime pour interagir avec le modèle en temps réel. L’exemple de code inclut une interface web simple qui capture l’audio à partir du microphone de l’utilisateur et l’envoie au modèle pour traitement. Le modèle répond avec du texte et de l’audio, que l’exemple de code affiche dans l’interface web.
Vous pouvez exécuter l’exemple de code localement sur votre ordinateur en suivant ces étapes. Reportez-vous au dépôt sur GitHub pour obtenir les instructions les plus à jour.
Si vous n’avez pas installé Node.js, téléchargez et installez la version LTS de Node.js.
Clonez le dépôt sur votre machine locale :
git clone https://github.com/Azure-Samples/aoai-realtime-audio-sdk.gitAccédez au dossier
javascript/samples/webdans votre éditeur de code préféré.cd ./javascript/samplesExécutez
download-pkg.ps1oudownload-pkg.shpour télécharger les packages requis.Accédez au dossier
webdu dossier./javascript/samples.cd ./webExécutez
npm installpour installer les dépendances du package.Exécutez
npm run devpour démarrer le serveur web, en accédant à toutes les invites des autorisations du pare-feu selon vos besoins.Accédez à une des URI fournies dans la sortie de la console (par exemple
http://localhost:5173/) dans un navigateur.Entrez les informations suivantes dans l’interface web :
-
Point de terminaison : le point de terminaison de ressource d’une ressource Azure OpenAI. Vous n’avez pas besoin d’ajouter le chemin d’accès
/realtime. Un exemple de structure seraithttps://my-azure-openai-resource-from-portal.openai.azure.com. - Clé API : une clé API correspondante pour la ressource Azure OpenAI.
-
Déploiement : le nom du modèle
gpt-4o-mini-realtime-previewque vous avez déployé dans la section précédente. - Message système : si vous le souhaitez, vous pouvez fournir un message système tel que « Vous parlez toujours comme un pirate amical. ».
- Température : si vous le souhaitez, vous pouvez fournir une température personnalisée.
- Voix : si vous le souhaitez, vous pouvez sélectionner une voix.
-
Point de terminaison : le point de terminaison de ressource d’une ressource Azure OpenAI. Vous n’avez pas besoin d’ajouter le chemin d’accès
Sélectionnez le bouton Enregistrer pour démarrer la session. Si vous y êtes invité, acceptez les autorisations d’utilisation de votre microphone.
Vous devez voir un message
<< Session Started >>dans la sortie principale. Vous pouvez ensuite parler dans le microphone pour démarrer une conversation.Vous pouvez interrompre la conversation à tout moment en parlant. Vous pouvez mettre fin à la conversation en sélectionnant le bouton Arrêter.
Prérequis
- Un abonnement Azure. Créez-en un gratuitement.
- Python 3.8 ou version ultérieure. Nous vous recommandons d’utiliser Python 3.10 ou version ultérieure, mais l’utilisation d’au moins Python 3.8 est requise. Si vous n’avez pas installé une version appropriée de Python, vous pouvez suivre les instructions du didacticiel Python VS Code pour le moyen le plus simple d’installer Python sur votre système d’exploitation.
- Une ressource Azure OpenAI créée dans l’une des régions prises en charge. Pour plus d’informations sur la disponibilité régionale, consultez la documentation sur les modèles et les versions.
- Ensuite, vous devez déployer un modèle
gpt-4o-mini-realtime-previewavec votre ressource Azure OpenAI. Pour plus d’informations, consultez l’article Créer une ressource et déployer un modèle à l’aide d’Azure OpenAI.
Prérequis pour Microsoft Entra ID
Pour l’authentification sans clé recommandée avec Microsoft Entra ID, vous devez effectuer les tâches suivantes :
- Installez l’interface Azure CLI utilisée pour l’authentification sans clé avec Microsoft Entra ID.
- Attribuez le rôle
Cognitive Services Userà votre compte d’utilisateur. Vous pouvez attribuer des rôles dans le Portail Azure sous Contrôle d’accès (IAM)>Ajouter une attribution de rôle.
Déployer un modèle pour l’audio en temps réel
Pour déployer le modèle gpt-4o-mini-realtime-preview dans le portail Azure AI Foundry :
- Accédez à la page Azure OpenAI Service dans le portail Azure AI Foundry. Vérifiez que vous êtes connecté avec l’abonnement Azure disposant de votre ressource Azure OpenAI Service (avec ou sans déploiements de modèles).
- Sélectionnez le terrain de jeu Audio en temps réel sous Terrains de jeu dans le volet gauche.
- Sélectionnez + Créer un déploiement>À partir de modèles de base pour ouvrir la fenêtre de déploiement.
- Recherchez et sélectionnez le modèle
gpt-4o-mini-realtime-preview, puis sélectionnez Déployer sur une ressource sélectionnée. - Dans l’Assistant de déploiement, sélectionnez la version du modèle
2024-12-17. - Suivez l’Assistant pour terminer le déploiement du modèle.
Maintenant que vous disposez d’un déploiement du modèle gpt-4o-mini-realtime-preview, vous pouvez interagir avec lui en temps réel dans le terrain de jeu Audio en temps réel le portail Azure AI Foundry ou l’API Temps réel.
Configurer
Créez un dossier
realtime-audio-quickstartpour contenir l’application et ouvrez Visual Studio Code dans ce dossier avec la commande suivante :mkdir realtime-audio-quickstart && code realtime-audio-quickstartCréez un environnement virtuel. Si Python 3.10, ou une version ultérieure est déjà installé, vous pouvez créer un environnement virtuel à l’aide des commandes suivantes :
L'activation de l'environnement Python signifie que lorsque vous exécutez
pythonoupipdepuis la ligne de commande, vous utilisez alors l'interpréteur Python contenu dans le dossier.venvde votre application. Vous pouvez utiliser la commandedeactivatepour quitter l’environnement virtuel Python et la réactiver ultérieurement si nécessaire.Conseil
Nous vous recommandons de créer et d’activer un nouvel environnement Python pour installer les packages dont vous avez besoin pour ce tutoriel. N’installez pas de packages dans votre installation globale de Python. Vous devez toujours utiliser un environnement virtuel ou conda lors de l’installation de packages Python. Sinon, votre installation globale de Python peut être interrompue.
Installez la bibliothèque de client audio en temps réel pour Python avec :
pip install "https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/py%2Fv0.5.3/rtclient-0.5.3.tar.gz"Pour l’authentification sans clé recommandée avec Microsoft Entra ID, installez le package
azure-identityavec :pip install azure-identity
Récupérer des informations sur les ressources
Vous devez récupérer les informations suivantes pour authentifier votre application auprès de votre ressource Azure OpenAI :
| Nom de la variable | Valeur |
|---|---|
AZURE_OPENAI_ENDPOINT |
Cette valeur se trouve dans la section Clés et point de terminaison quand vous examinez votre ressource à partir du portail Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Cette valeur correspond au nom personnalisé que vous avez choisi pour votre déploiement lorsque vous avez déployé un modèle. Cette valeur peut être trouvée dans le Portail Azure sous Gestion des ressources>Déploiements de modèles. |
OPENAI_API_VERSION |
En savoir plus sur les versions d’API. |
En savoir plus sur l’authentification sans clé et la définition de variables d’environnement.
Texte en entrée et audio en sortie
Remplacez le fichier
text-in-audio-out.pyavec le code suivant :import base64 import asyncio from azure.identity.aio import DefaultAzureCredential from rtclient import ( ResponseCreateMessage, RTLowLevelClient, ResponseCreateParams ) # Set environment variables or edit the corresponding values here. endpoint = os.environ["AZURE_OPENAI_ENDPOINT"] deployment = "gpt-4o-mini-realtime-preview" async def text_in_audio_out(): async with RTLowLevelClient( url=endpoint, azure_deployment=deployment, token_credential=DefaultAzureCredential(), ) as client: await client.send( ResponseCreateMessage( response=ResponseCreateParams( modalities={"audio", "text"}, instructions="Please assist the user." ) ) ) done = False while not done: message = await client.recv() match message.type: case "response.done": done = True case "error": done = True print(message.error) case "response.audio_transcript.delta": print(f"Received text delta: {message.delta}") case "response.audio.delta": buffer = base64.b64decode(message.delta) print(f"Received {len(buffer)} bytes of audio data.") case _: pass async def main(): await text_in_audio_out() asyncio.run(main())Exécutez le fichier Python.
python text-in-audio-out.py
Attendez quelques instants pour obtenir une réponse.
Sortie
Le script obtient une réponse du modèle et affiche les données de transcription et audio reçues.
La sortie ressemble à l'exemple suivant :
Received text delta: Hello
Received text delta: !
Received text delta: How
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: can
Received 12000 bytes of audio data.
Received text delta: I
Received text delta: assist
Received text delta: you
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 28800 bytes of audio data.
Prérequis
- Un abonnement Azure - En créer un gratuitement
- Prise en charge de Node.js LTS ou ESM.
- TypeScript installé globalement.
- Une ressource Azure OpenAI créée dans l’une des régions prises en charge. Pour plus d’informations sur la disponibilité régionale, consultez la documentation sur les modèles et les versions.
- Ensuite, vous devez déployer un modèle
gpt-4o-mini-realtime-previewavec votre ressource Azure OpenAI. Pour plus d’informations, consultez l’article Créer une ressource et déployer un modèle à l’aide d’Azure OpenAI.
Prérequis pour Microsoft Entra ID
Pour l’authentification sans clé recommandée avec Microsoft Entra ID, vous devez effectuer les tâches suivantes :
- Installez l’interface Azure CLI utilisée pour l’authentification sans clé avec Microsoft Entra ID.
- Attribuez le rôle
Cognitive Services Userà votre compte d’utilisateur. Vous pouvez attribuer des rôles dans le Portail Azure sous Contrôle d’accès (IAM)>Ajouter une attribution de rôle.
Déployer un modèle pour l’audio en temps réel
Pour déployer le modèle gpt-4o-mini-realtime-preview dans le portail Azure AI Foundry :
- Accédez à la page Azure OpenAI Service dans le portail Azure AI Foundry. Vérifiez que vous êtes connecté avec l’abonnement Azure disposant de votre ressource Azure OpenAI Service (avec ou sans déploiements de modèles).
- Sélectionnez le terrain de jeu Audio en temps réel sous Terrains de jeu dans le volet gauche.
- Sélectionnez + Créer un déploiement>À partir de modèles de base pour ouvrir la fenêtre de déploiement.
- Recherchez et sélectionnez le modèle
gpt-4o-mini-realtime-preview, puis sélectionnez Déployer sur une ressource sélectionnée. - Dans l’Assistant de déploiement, sélectionnez la version du modèle
2024-12-17. - Suivez l’Assistant pour terminer le déploiement du modèle.
Maintenant que vous disposez d’un déploiement du modèle gpt-4o-mini-realtime-preview, vous pouvez interagir avec lui en temps réel dans le terrain de jeu Audio en temps réel le portail Azure AI Foundry ou l’API Temps réel.
Configurer
Créez un dossier
realtime-audio-quickstartpour contenir l’application et ouvrez Visual Studio Code dans ce dossier avec la commande suivante :mkdir realtime-audio-quickstart && code realtime-audio-quickstartCréez le
package.jsonavec la commande suivante :npm init -yMettez à jour le
package.jsonvers ECMAScript avec la commande suivante :npm pkg set type=moduleInstallez la bibliothèque de client audio en temps réel pour JavaScript avec :
npm install https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/js/v0.5.2/rt-client-0.5.2.tgzPour l’authentification sans clé recommandée avec Microsoft Entra ID, installez le package
@azure/identityavec :npm install @azure/identity
Récupérer des informations sur les ressources
Vous devez récupérer les informations suivantes pour authentifier votre application auprès de votre ressource Azure OpenAI :
| Nom de la variable | Valeur |
|---|---|
AZURE_OPENAI_ENDPOINT |
Cette valeur se trouve dans la section Clés et point de terminaison quand vous examinez votre ressource à partir du portail Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Cette valeur correspond au nom personnalisé que vous avez choisi pour votre déploiement lorsque vous avez déployé un modèle. Cette valeur peut être trouvée dans le Portail Azure sous Gestion des ressources>Déploiements de modèles. |
OPENAI_API_VERSION |
En savoir plus sur les versions d’API. |
En savoir plus sur l’authentification sans clé et la définition de variables d’environnement.
Attention
Pour utiliser l’authentification sans clé recommandée avec le kit de développement logiciel (SDK), vérifiez que la variable d’environnement AZURE_OPENAI_API_KEY n’est pas définie.
Texte en entrée et audio en sortie
Remplacez le fichier
text-in-audio-out.tsavec le code suivant :import { DefaultAzureCredential } from "@azure/identity"; import { LowLevelRTClient } from "rt-client"; import dotenv from "dotenv"; dotenv.config(); async function text_in_audio_out() { // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "yourEndpoint"; const deployment = "gpt-4o-mini-realtime-preview"; if (!endpoint || !deployment) { throw new Error("You didn't set the environment variables."); } const client = new LowLevelRTClient( new URL(endpoint), new DefaultAzureCredential(), {deployment: deployment} ); try { await client.send({ type: "response.create", response: { modalities: ["audio", "text"], instructions: "Please assist the user." } }); for await (const message of client.messages()) { switch (message.type) { case "response.done": { break; } case "error": { console.error(message.error); break; } case "response.audio_transcript.delta": { console.log(`Received text delta: ${message.delta}`); break; } case "response.audio.delta": { const buffer = Buffer.from(message.delta, "base64"); console.log(`Received ${buffer.length} bytes of audio data.`); break; } } if (message.type === "response.done" || message.type === "error") { break; } } } finally { client.close(); } } await text_in_audio_out();Créez le fichier
tsconfig.jsonpour transpiler le code TypeScript et copiez le code suivant pour ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpiler de TypeScript à JavaScript.
tscConnectez-vous à Azure à l’aide de la commande suivante :
az loginExécutez le code avec la commande suivante :
node text-in-audio-out.js
Attendez quelques instants pour obtenir une réponse.
Sortie
Le script obtient une réponse du modèle et affiche les données de transcription et audio reçues.
La sortie ressemble à l'exemple suivant :
Received text delta: Hello
Received text delta: !
Received text delta: How
Received text delta: can
Received text delta: I
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: help
Received 12000 bytes of audio data.
Received text delta: you
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 24000 bytes of audio data.
Contenu connexe
- Découvrez-en plus sur Utilisation de l'API en temps réel
- Consulter la référence API Realtime
- En savoir plus sur les quotas et limites Azure OpenAI