Évaluation Azure OpenAI (préversion)
L’évaluation des grands modèles de langage est une étape essentielle pour mesurer leurs performances sur différentes tâches et dimensions. Cela est particulièrement important pour les modèles affinés, où l’évaluation des gains de performance (ou pertes) de l’entraînement est cruciale. Des évaluations approfondies peuvent vous aider à comprendre comment différentes versions du modèle peuvent avoir un impact sur votre application ou votre scénario.
L’évaluation d’Azure OpenAI permet aux développeurs de créer des exécutions d’évaluation pour tester les paires d’entrée/sortie attendues, d’évaluer les performances du modèle sur les métriques clés telles que la précision, la fiabilité et les performances globales.
Prise en charge des évaluations
Disponibilité régionale
- USA Est 2
- Centre-Nord des États-Unis
- Suède Centre
- Suisse Ouest
Types de déploiement pris en charge
- Standard
- approvisionné
Pipeline d’évaluation
Données de test
Vous devez assembler un jeu de données de vérité de base sur lequel vous souhaitez effectuer des tests. La création de jeux de données est généralement un processus itératif qui garantit que vos évaluations restent pertinentes pour vos scénarios au fil du temps. Ce jeu de données de vérité de base est généralement fabriqué manuellement et représente le comportement attendu de votre modèle. L'ensemble de données est également étiqueté et comprend les réponses attendues.
Remarque
Certains tests d’évaluation tels que Sentiment et JSON ou XML valides ne nécessitent pas de données de vérité au sol.
Votre source de données doit être au format JSONL. Voici deux exemples de jeux de données d’évaluation JSONL :
Format des jeux d’évaluation
{"question": "Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.", "subject": "abstract_algebra", "A": "0", "B": "4", "C": "2", "D": "6", "answer": "B", "completion": "B"}
{"question": "Let p = (1, 2, 5, 4)(2, 3) in S_5 . Find the index of <p> in S_5.", "subject": "abstract_algebra", "A": "8", "B": "2", "C": "24", "D": "120", "answer": "C", "completion": "C"}
{"question": "Find all zeros in the indicated finite field of the given polynomial with coefficients in that field. x^5 + 3x^3 + x^2 + 2x in Z_5", "subject": "abstract_algebra", "A": "0", "B": "1", "C": "0,1", "D": "0,4", "answer": "D", "completion": "D"}
Lorsque vous téléchargez et sélectionnez votre fichier d'évaluation, vous obtenez un aperçu des trois premières lignes :


Vous pouvez choisir n'importe quel jeu de données déjà téléchargé ou télécharger un nouveau jeu de données.
Générer des réponses (facultatif)
L’invite que vous utilisez dans votre évaluation doit correspondre à l’invite que vous prévoyez d’utiliser en production. Ces invites fournissent les instructions pour que le modèle suive. Comme pour les expériences de terrain de jeu, vous pouvez créer plusieurs entrées pour inclure des exemples à quelques coups dans votre invite. Pour plus d’informations, consultez Techniques d’ingénierie rapide pour plus d’informations sur certaines techniques avancées dans la conception rapide et l’ingénierie rapide.
Vous pouvez référencer vos données d’entrée dans les invites à l’aide du format {{input.column_name}}, où column_name correspond aux noms des colonnes de votre fichier d’entrée.
Les sorties générées pendant l’évaluation seront référencées dans les étapes suivantes à l’aide du format {{sample.output_text}}.
Remarque
Vous devez utiliser des accolades doubles pour vous assurer que vous référencez correctement vos données.
Déploiement de modèle
Dans le cadre de la création d’évaluations, vous allez choisir les modèles à utiliser lors de la génération de réponses (facultatives) ainsi que les modèles à utiliser lors de la notation de modèles avec des critères de test spécifiques.
Dans Azure OpenAI, vous allez affecter des modèles de déploiement spécifiques à utiliser dans le cadre de vos évaluations. Vous pouvez comparer plusieurs déploiements en créant une configuration d’évaluation distincte pour chaque modèle. Cela vous permet de définir des invites spécifiques pour chaque évaluation, ce qui vous permet de mieux contrôler les variations requises par différents modèles.
Vous pouvez évaluer une base ou un modèle de déploiement affiné. Les déploiements disponibles dans votre liste dépendent de ceux que vous avez créés dans votre ressource Azure OpenAI. Si vous ne trouvez pas le déploiement souhaité, vous pouvez en créer un à partir de la page Évaluation Azure OpenAI.
Critère de test
Les critères de test sont utilisés pour évaluer l’efficacité de chaque sortie générée par le modèle cible. Ces tests comparent les données d’entrée aux données de sortie pour garantir la cohérence. Vous avez la possibilité de configurer différents critères pour tester et mesurer la qualité et la pertinence de la sortie à différents niveaux.

Mise en route
Sélectionnez l’évaluation Azure OpenAI (PREVIEW) dans le portail Azure AI Foundry. Pour voir cette vue en tant qu’option, vous devrez peut-être d’abord sélectionner une ressource Azure OpenAI existante dans une région prise en charge.
Sélectionnez Nouvelle évaluation
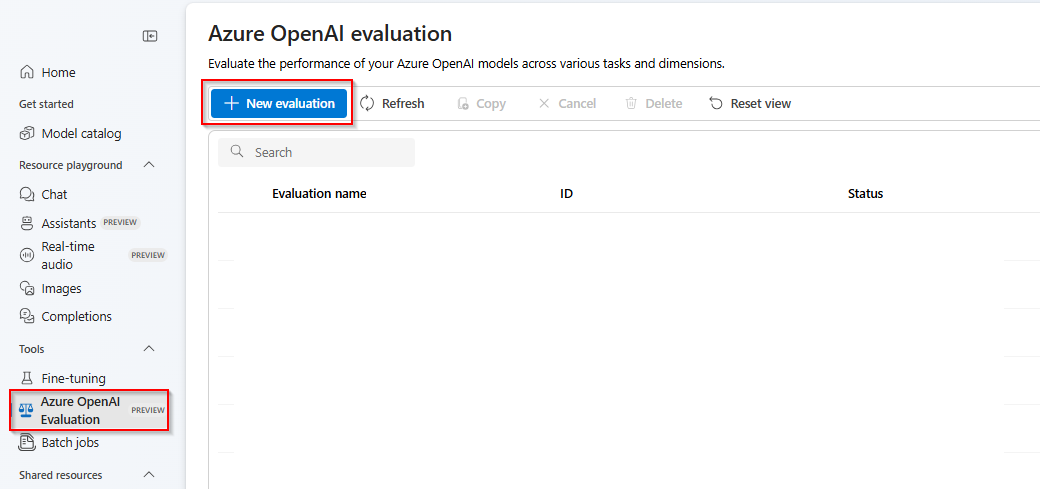
Entrez le nom de votre évaluation. Par défaut, un nom aléatoire est généré automatiquement, sauf si vous modifiez et remplacez-le. > sélectionnez Charger un nouveau jeu de données.
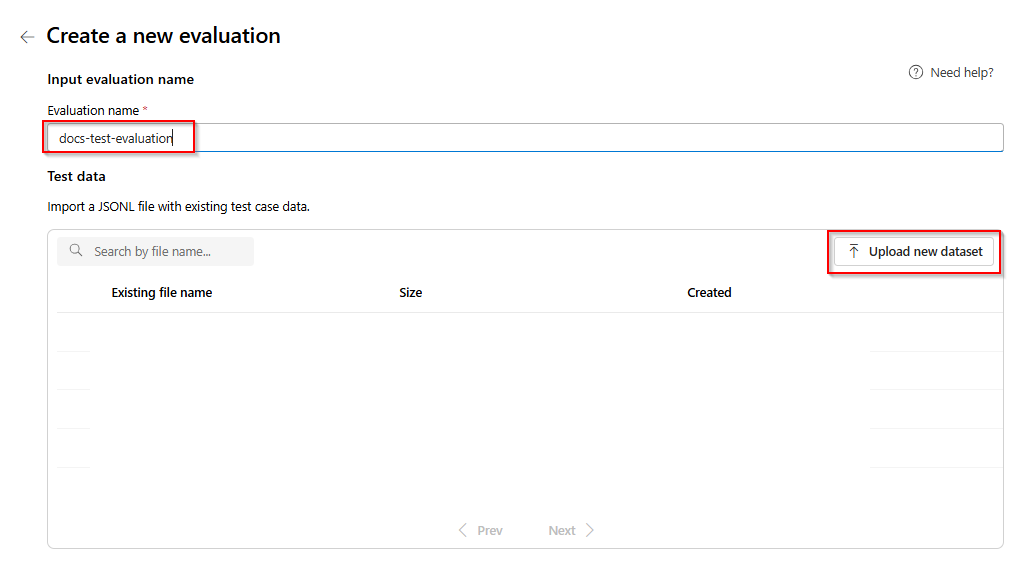
Sélectionnez votre évaluation qui sera au format
.jsonl. Si vous avez besoin d’un exemple de fichier de test, vous pouvez enregistrer ces 10 lignes dans un fichier appeléeval-test.jsonl:{"input": [{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."}, {"role": "user", "content": "Tokenization is a key step in preprocessing for natural language processing, involving the division of text into smaller components called tokens. These can be words, subwords, or characters, depending on the method chosen. Word tokenization divides text at word boundaries, while subword techniques like Byte Pair Encoding (BPE) or WordPiece can manage unknown words by breaking them into subunits. Character tokenization splits text into individual characters, useful for multiple languages and misspellings. The tokenization method chosen greatly affects model performance and its capacity to handle various languages and vocabularies."}], "output": "Tokenization divides text into smaller units (tokens) for NLP applications, using word, subword (e.g., BPE), or character methods. Each has unique benefits, impacting model performance and language processing capabilities."} {"input": [{"role": "system", "content": "Create a comprehensive yet concise summary that captures the essential technical details and significance of the topic."}, {"role": "user", "content": "Self-attention mechanisms are vital in modern transformer models, allowing them to evaluate the relevance of different parts of an input sequence when processing each element. In self-attention, each position in a sequence learns to focus on all other positions, forming a weighted sum of their values. Attention weights are derived using queries, keys, and values, with compatibility between a query and key determining attention to each value. This mechanism enables capturing long-range dependencies and relationships within a sequence, making it effective for tasks needing context understanding and inter-part relationships."}], "output": "Self-attention is crucial in transformers, enabling each sequence position to evaluate and collect data from all others. It uses queries, keys, and values for attention weights, effectively capturing long-range dependencies and contextual links."} {"input": [{"role": "system", "content": "Synthesize the technical information into a brief, accurate summary that maintains the core concepts and their significance."}, {"role": "user", "content": "The transformer architecture significantly changed natural language processing by introducing a new method for sequence processing. Unlike recurrent neural networks, transformers process whole sequences at once using self-attention. The architecture consists of an encoder and decoder, each with multiple layers of multi-head attention, feed-forward networks, and normalization layers. The encoder processes the input sequence, and the decoder produces the output sequence. Positional encodings are added to retain sequence order information since the model lacks inherent sequence position awareness. This architecture underlies many leading language models like BERT and GPT."}], "output": "Transformers are a transformative neural architecture processing sequences with self-attention instead of recurrence. Their encoder-decoder design, with multi-head attention and position encodings, is fundamental to modern language models like BERT and GPT."} {"input": [{"role": "system", "content": "Distill the technical content into a clear, concise summary that preserves the most important concepts and their practical applications."}, {"role": "user", "content": "Cosine similarity is a metric for measuring similarity between vectors by calculating the cosine of the angle between them. The outcome ranges from -1 to 1, with 1 indicating identical orientation, 0 orthogonality, and -1 opposite orientation. In machine learning and NLP, cosine similarity is useful for comparing document vectors, word embeddings, or any high-dimensional representations. It's often preferred over Euclidean distance because it's invariant to vector magnitude, focusing instead on orientation. This makes it particularly useful for comparing documents or embeddings of various lengths or scales."}], "output": "Cosine similarity evaluates vector similarity by computing their angle's cosine, with values from -1 to 1. It's widely used in ML and NLP for comparing document vectors and embeddings due to its magnitude-invariant nature."} {"input": [{"role": "system", "content": "Provide a succinct summary that captures the key technical concepts and their relationships while maintaining clarity and accuracy."}, {"role": "user", "content": "Neural network activation functions are crucial for introducing non-linearity to deep learning models. Commonly used activation functions include ReLU (Rectified Linear Unit), which outputs the input directly if positive and zero otherwise, sigmoid, which compresses values between 0 and 1, and tanh, which normalizes values between -1 and 1. Each function has specific benefits and applications: ReLU avoids vanishing gradients and enables sparse activation, sigmoid is useful for binary classification, and tanh is often used in hidden layers for its zero-centered output. The activation function choice greatly affects model training dynamics and ultimate performance."}], "output": "Activation functions introduce non-linearity to neural networks, with ReLU, sigmoid, and tanh being the most common. Each serves distinct purposes: ReLU prevents vanishing gradients, sigmoid is suitable for binary classification, and tanh offers zero-centered output, all affecting model performance differently."} {"input": [{"role": "system", "content": "Create a focused summary that emphasizes the main technical concepts and their practical implications while maintaining accuracy."}, {"role": "user", "content": "Batch normalization is a technique that stabilizes and accelerates deep neural network training by normalizing each layer's inputs. It normalizes activations using the mean and variance computed over the current data batch. This normalization reduces internal covariate shift, where the input distribution changes during training. Batch normalization includes learnable parameters (gamma and beta) allowing the network to reverse normalization if necessary. Benefits include enabling higher learning rates, lessening the importance of precise parameter initialization, and serving as a regularizer, potentially removing the need for dropout."}], "output": "Batch normalization stabilizes neural network training by normalizing layer inputs using batch statistics. It addresses internal covariate shift with learnable parameters, allowing higher learning rates and improved training dynamics, while offering regularization benefits."} {"input": [{"role": "system", "content": "Summarize the technical content while preserving the essential concepts and their interconnections, ensuring clarity and precision."}, {"role": "user", "content": "Gradient descent optimization algorithms are foundational to training machine learning models. The basic version updates parameters in the steepest descent direction of the loss function. Variants like Stochastic Gradient Descent (SGD) use random samples to estimate gradients, enhancing computational efficiency. Advanced optimizers like Adam combine momentum (helping overcome local minima) and RMSprop (adapting learning rates for each parameter). These optimizers maintain running averages of gradients and their squares, enabling adaptive learning rates and more efficient training. The optimizer choice can significantly influence model convergence speed and final performance."}], "output": "Gradient descent algorithms optimize ML models by updating parameters based on loss gradients. Variants like SGD use sampling for efficiency, while advanced optimizers like Adam combine momentum with adaptive learning rates for improved training performance."} {"input": [{"role": "system", "content": "Deliver a concise yet comprehensive summary that highlights the key technical aspects and their practical significance."}, {"role": "user", "content": "Cross-validation is a resampling method used to evaluate machine learning models on limited data. The most common form, k-fold cross-validation, involves dividing the dataset into k equal parts, training the model on k-1 folds while validating on the remaining fold, and rotating through all combinations. This provides a more robust model performance assessment than a single train-test split, helping detect overfitting and estimate model generalization to unseen data. Variations include stratified k-fold (maintaining class distribution), leave-one-out (k equals dataset size), and time series cross-validation for temporal data."}], "output": "Cross-validation evaluates ML models by training and testing on different data splits, typically using k-fold methodology. This approach offers better performance assessment than single splits, with variations for different data types and requirements."} {"input": [{"role": "system", "content": "Generate a clear and focused summary that captures the essential technical details while maintaining their relationships and significance."}, {"role": "user", "content": "Transfer learning is a machine learning method where a model developed for one task is reused as the starting point for a model on a second task. This approach is powerful in deep learning, where pre-trained models on large datasets (like ImageNet for computer vision or BERT for NLP) are fine-tuned on specific downstream tasks. Transfer learning reduces the need for large amounts of task-specific training data and computational resources, as the model has already learned useful features from the source domain. Common strategies include feature extraction (freezing pre-trained layers) and fine-tuning (updating all or some pre-trained weights)."}], "output": "Transfer learning reuses models trained on one task for different tasks, particularly effective in deep learning. It leverages pre-trained models through feature extraction or fine-tuning, reducing data and computational needs for new tasks."} {"input": [{"role": "system", "content": "Provide a precise and informative summary that distills the key technical concepts while maintaining their relationships and practical importance."}, {"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random data subsets), boosting (sequentially training models to correct earlier errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree correcting the errors of previous ones. These methods often outperform single models by reducing overfitting and variance while capturing different data aspects."}], "output": "Ensemble methods enhance prediction accuracy by combining multiple models through techniques like bagging, boosting, and stacking. Popular implementations include Random Forests (using multiple trees with random features) and Gradient Boosting (sequential error correction), offering better performance than single models."}Vous verrez les trois premières lignes du fichier en préversion :
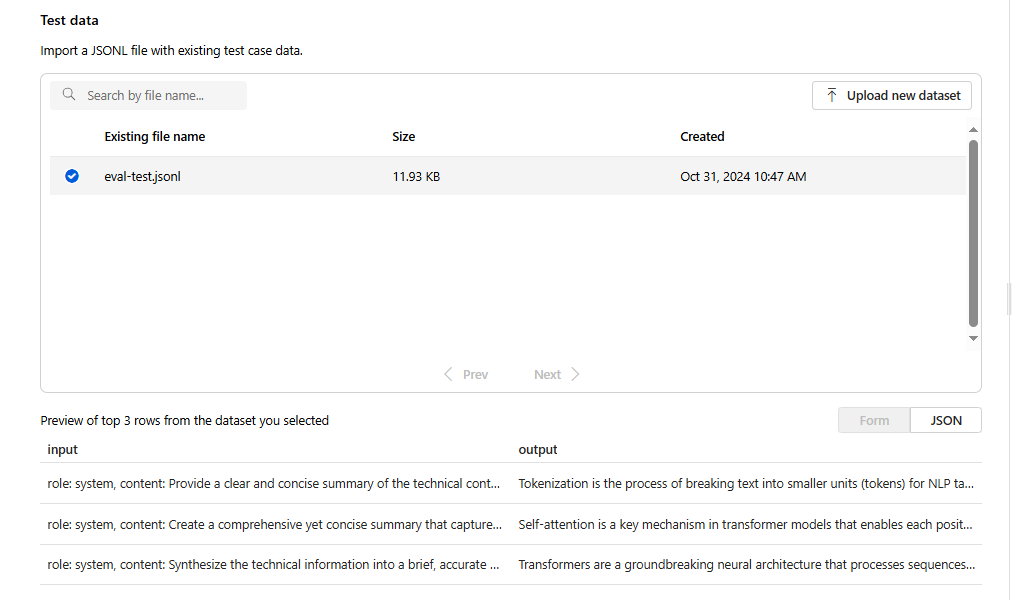
Sélectionnez le bouton bascule pour Générer des réponses. Sélectionnez
{{item.input}}de la liste déroulante. Cela injectera les champs d’entrée de notre fichier d’évaluation dans des invites individuelles pour une nouvelle exécution de modèle que nous voulons comparer à notre jeu de données d’évaluation. Le modèle prend cette entrée et génère ses propres sorties uniques qui, dans ce cas, seront stockées dans une variable appelée{{sample.output_text}}. Nous allons ensuite utiliser cet exemple de texte de sortie ultérieurement dans le cadre de nos critères de test. Vous pouvez également fournir manuellement votre propre message système personnalisé et des exemples de messages individuels.Sélectionnez le modèle que vous souhaitez générer des réponses en fonction de votre évaluation. Si vous n’avez pas de modèles, vous pouvez en créer un. Dans le cadre de cet exemple, nous utilisons un déploiement standard de
gpt-4o-mini.
Le symbole paramètres/sprocket contrôle les paramètres de base passés au modèle. Seuls les paramètres suivants sont pris en charge à l'heure actuelle :




- Température
- Longueur maximale
- Meilleur P
La longueur maximale est actuellement limitée à 2048, quel que soit le modèle que vous sélectionnez.
Sélectionnez Ajouter des critères de test sélectionnez Ajouter.
Sélectionnez similarité sémantique> sous Comparer ajouter
{{item.output}}sous Avec ajoutez{{sample.output_text}}. Cela prend la sortie de référence d’origine de votre fichier d’évaluation.jsonlet la compare à la sortie qui sera générée en donnant aux invites de modèle en fonction de votre{{item.input}}.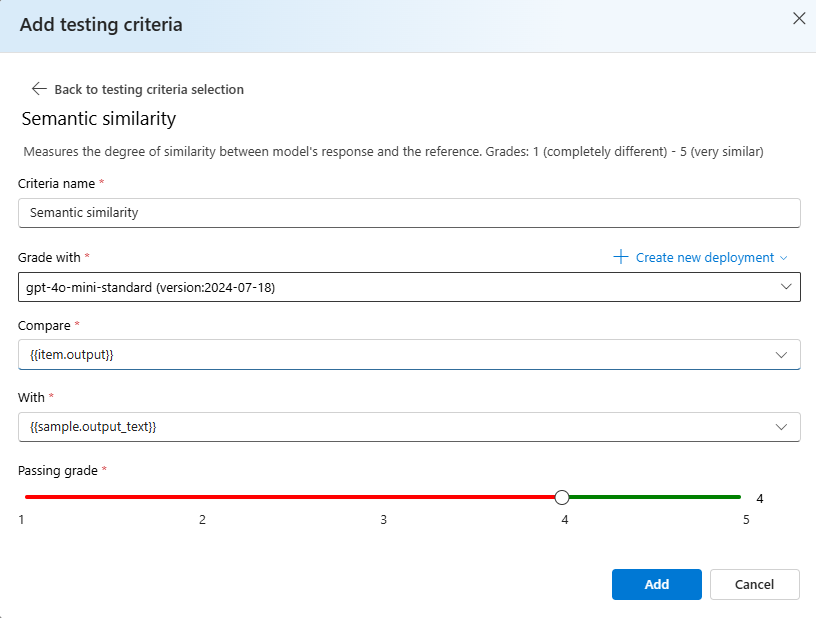
Sélectionnez Ajouter> à ce stade, vous pouvez ajouter des critères de test supplémentaires ou vous sélectionnez Créer pour lancer l’exécution du travail d’évaluation.
Une fois que vous avez sélectionné Créer vous êtes redirigé vers une page d’état de votre travail d’évaluation.
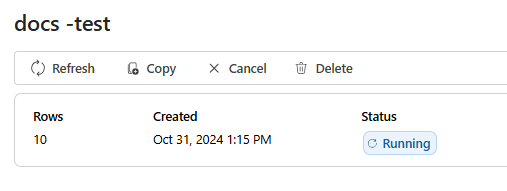
Une fois votre travail d’évaluation créé, vous pouvez sélectionner le travail pour afficher les détails complets du travail :
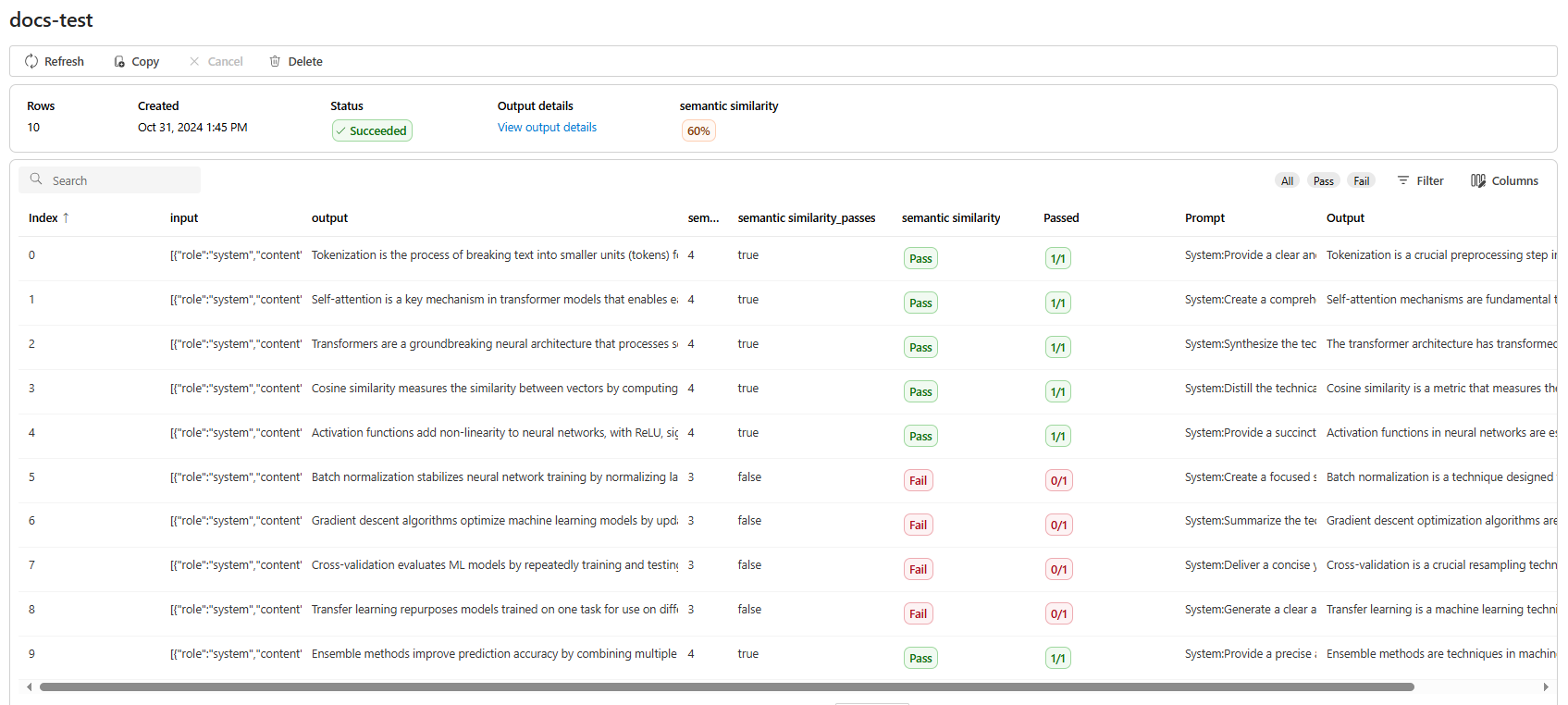
Pour la similarité sémantique Afficher les détails de sortie contient une représentation JSON que vous pouvez copier/coller de vos tests réussis.





Détails du critère de test
Azure OpenAI Evaluation propose plusieurs options de critères de test. La section ci-dessous fournit des détails supplémentaires sur chaque option.
Caractère factuel
Évalue l’exactitude factuelle d’une réponse soumise en la comparant à une réponse d’expert.
La factualité évalue l'exactitude factuelle d'une réponse soumise en la comparant à la réponse d'un expert. À l'aide d'une chaîne de pensée détaillée, le correcteur détermine si la réponse soumise est cohérente avec la réponse de l'expert, si elle en est un sous-ensemble, un surensemble ou si elle est en conflit avec elle. Il ignore les différences de style, de grammaire ou de ponctuation, en se concentrant uniquement sur le contenu factuel. Les faits peuvent être utiles dans de nombreux scénarios, notamment la vérification du contenu et les outils pédagogiques qui garantissent la précision des réponses fournies par l’IA.

Vous pouvez afficher le texte d’invite utilisé dans le cadre de ces critères de test en sélectionnant la liste déroulante en regard de l’invite. Le texte de l’invite actuelle est le suivant :
Prompt
You are comparing a submitted answer to an expert answer on a given question.
Here is the data:
[BEGIN DATA]
************
[Question]: {input}
************
[Expert]: {ideal}
************
[Submission]: {completion}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.
The submitted answer may either be a subset or superset of the expert answer, or it may conflict with it. Determine which case applies. Answer the question by selecting one of the following options:
(A) The submitted answer is a subset of the expert answer and is fully consistent with it.
(B) The submitted answer is a superset of the expert answer and is fully consistent with it.
(C) The submitted answer contains all the same details as the expert answer.
(D) There is a disagreement between the submitted answer and the expert answer.
(E) The answers differ, but these differences don't matter from the perspective of factuality.
Similarité sémantique
Mesure le degré de similarité entre la réponse du modèle et la référence. Grades: 1 (completely different) - 5 (very similar).

Sentiment
Tente d’identifier le ton émotionnel de la sortie.

Vous pouvez afficher le texte d’invite utilisé dans le cadre de ces critères de test en sélectionnant la liste déroulante en regard de l’invite. Le texte de l’invite actuelle est le suivant :
Prompt
You will be presented with a text generated by a large language model. Your job is to rate the sentiment of the text. Your options are:
A) Positive
B) Neutral
C) Negative
D) Unsure
[BEGIN TEXT]
***
[{text}]
***
[END TEXT]
First, write out in a step by step manner your reasoning about the answer to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character (without quotes or punctuation) on its own line corresponding to the correct answer. At the end, repeat just the letter again by itself on a new line
Vérification de chaîne
Vérifie si la sortie correspond exactement à la chaîne attendue.

La vérification de chaîne effectue différentes opérations binaires sur deux variables de chaîne, ce qui permet d’obtenir différents critères d’évaluation. Il permet de vérifier différentes relations de chaîne, notamment l’égalité, l’isolement et des modèles spécifiques. Cet évaluateur permet des comparaisons respectant la casse ou sans respect de la casse. Il fournit également des notes spécifiées pour les résultats vrais ou faux, ce qui permet d’obtenir des résultats d’évaluation personnalisés en fonction du résultat de comparaison. Voici le type d’opérations pris en charge :
equals: vérifie si la chaîne de sortie est exactement égale à la chaîne d’évaluation.contains: vérifie si la chaîne d’évaluation est une sous-chaîne de chaîne de sortie.starts-with: Vérifie si la chaîne de sortie commence par la chaîne d'évaluation.ends-with: Vérifie si la chaîne de sortie se termine par la chaîne d'évaluation.
Remarque
Lorsque vous définissez certains paramètres dans vos critères de test, vous avez la possibilité de choisir entre la variable et le modèle. Sélectionnez variable si vous souhaitez faire référence à une colonne dans vos données d’entrée. Choisissez modèle si vous souhaitez fournir une chaîne fixe.
JSON ou XML valides
Vérifie si la sortie est valide JSON ou XML.

Correspond au schéma
Garantit que la sortie suit la structure spécifiée.

Correspondance des critères
Évaluez si la réponse du modèle correspond à vos critères. Grade : réussite ou échec.

Vous pouvez afficher le texte d’invite utilisé dans le cadre de ces critères de test en sélectionnant la liste déroulante en regard de l’invite. Le texte de l’invite actuelle est le suivant :
Prompt
Your job is to assess the final response of an assistant based on conversation history and provided criteria for what makes a good response from the assistant. Here is the data:
[BEGIN DATA]
***
[Conversation]: {conversation}
***
[Response]: {response}
***
[Criteria]: {criteria}
***
[END DATA]
Does the response meet the criteria? First, write out in a step by step manner your reasoning about the criteria to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer. "Y" for yes if the response meets the criteria, and "N" for no if it does not. At the end, repeat just the letter again by itself on a new line.
Reasoning:
Qualité texte
Évaluez la qualité du texte en comparant au texte de référence.

Résumé :
- Score BLEU : évalue la qualité du texte généré en le comparant à une ou plusieurs traductions de référence de haute qualité à l’aide du score BLEU.
- Score ROUGE : évalue la qualité du texte généré en le comparant aux résumés de référence à l’aide des scores ROUGE.
- Cosinus : Également appelé similarité cosinus, mesure la précision de deux incorporations de texte telles que les—sorties de modèle et les textes—de référence s’alignent dans la signification, ce qui permet d’évaluer la similarité sémantique entre eux. Pour ce faire, mesurez leur distance dans l’espace vectoriel.
Détails :
Le score BLEU (BiLingual Evaluation Understudy) est couramment utilisé dans le traitement du langage naturel (NLP) et la traduction automatique. Il est largement utilisé dans les cas d’usage de synthèse de texte et de génération de texte. Il évalue la correspondance étroite entre le texte généré et le texte de référence. Le score BLEU est compris entre 0 et 1, avec des scores plus élevés indiquant une meilleure qualité.
ROUGE (Understudy orienté rappel pour l’évaluation Gisting) est un ensemble de métriques utilisées pour évaluer la synthèse automatique et la traduction automatique. Elle mesure le chevauchement entre le texte généré et les résumés de référence. ROUGE se concentre sur les mesures orientées rappel pour évaluer la façon dont le texte généré couvre le texte de référence. Le score ROUGE fournit différentes métriques, notamment : • ROUGE-1 : Chevauchement des unigrammes (mots uniques) entre le texte généré et le texte de référence. • ROUGE-2 : Chevauchement de bigrams (deux mots consécutifs) entre le texte généré et le texte de référence. • ROUGE-3 : Chevauchement des trigrammes (trois mots consécutifs) entre le texte généré et le texte de référence. - ROUGE-4 : chevauchement de quatre grammes (quatre mots consécutifs) entre le texte généré et le texte de référence. - ROUGE-5 : chevauchement de cinq grammes (cinq mots consécutifs) entre le texte généré et le texte de référence. - ROUGE-L : Chevauchement des L-grammes (L mots consécutifs) entre le texte généré et le texte de référence. La synthèse de texte et la comparaison de documents sont parmi les cas d’usage optimaux pour ROUGE, en particulier dans les scénarios où la cohérence et la pertinence du texte sont critiques.
Cosinus : il mesure la précision de deux incorporations de texte telles que les—sorties de modèle et les textes—de référence s’alignent dans la signification, ce qui permet d’évaluer la similarité sémantique entre eux. Identique à d’autres évaluateurs basés sur des modèles, vous devez fournir un modèle de déploiement à l’aide de l’évaluation.
Important
Seuls les modèles incorporés sont pris en charge pour cet évaluateur :
text-embedding-3-smalltext-embedding-3-largetext-embedding-ada-002
Invite personnalisée
Utilise le modèle pour classifier la sortie dans un ensemble d’étiquettes spécifiées. Cet évaluateur utilise une invite personnalisée que vous devez définir.
