Bien démarrer avec les déploiements de type Traitement par lots global d’Azure OpenAI
L’API Azure OpenAI Batch est conçue pour gérer efficacement les tâches de traitement à grande échelle et à volume élevé. Traitez les groupes asynchrones de requêtes avec un quota distinct, avec un délai d’exécution cible de 24 heures, à un coût 50 % inférieur au type Standard global. Avec le traitement par lots, plutôt que d’envoyer une seule requête à la fois, vous envoyez un grand nombre de requêtes dans un seul fichier. Les requêtes de traitement par lots global ont un quota de jetons empilés distinct qui évite toute interruption de vos charges de travail en ligne.
Les principaux cas d’utilisation sont les suivants :
Traitement de données à grande échelle : analysez rapidement des jeux de données étendus en parallèle.
Génération de contenu : créez des volumes de texte importants, notamment des descriptions de produits ou des articles.
Révision et résumé de documents : automatisez la révision et le résumé de documents longs.
Automatisation du service clientèle : gérez simultanément de nombreuses requêtes pour obtenir des réponses plus rapides.
Extraction et analyse des données : extrayez et analysez des informations provenant de vastes quantités de données non structurées.
Tâches de traitement du langage naturel (NLP) : effectuez par exemple des tâches d’analyse des sentiments ou de traduction sur de grands jeux de données.
Marketing et personnalisation : générez du contenu et des suggestions personnalisés à grande échelle.
Important
Nous nous efforçons de traiter les requêtes de traitement par lots dans un délai de 24 heures (les travaux qui prennent plus de temps n’expirent pas). Vous pouvez annuler le travail à tout moment. Quand vous annulez le travail, tout travail restant est annulé et tout travail déjà terminé est retourné. Tout travail terminé vous est facturé.
Les données stockées au repos restent dans la géographie Azure désignée, mais le traitement des données pour inférence est possible dans n’importe quel emplacement Azure OpenAI. En savoir plus sur la résidence des données.
Prise en charge du traitement par lots global
Prise en charge des régions et des modèles
Le lot global est actuellement pris en charge dans les régions suivantes :
| Région | gpt-4o, 2024-05-13 | gpt-4o, 2024-08-06 | gpt-4o-mini, 2024-07-18 | gpt-4, 0613 | gpt-4, turbo-2024-04-09 | gpt-35-turbo, 0613 | gpt-35-turbo, 1106 | gpt-35-turbo, 0125 |
|---|---|---|---|---|---|---|---|---|
| australiaeast | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| canadaeast | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus2 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| francecentral | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| japaneast | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| KoreaCentral | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| northcentralus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| norwayeast | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southcentralus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southindia | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| centre de la suède | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| suisse nord | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| uksouth | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westeurope | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus3 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Les modèles suivants prennent en charge le lot global :
| Modèle | Version | Format d’entrée |
|---|---|---|
gpt-4o |
06-08-2024 | texte et image |
gpt-4o-mini |
2024-07-18 | texte et image |
gpt-4o |
2024-05-13 | texte et image |
gpt-4 |
turbo-2024-04-09 | texte |
gpt-4 |
0613 | texte |
gpt-35-turbo |
0125 | texte |
gpt-35-turbo |
1106 | texte |
gpt-35-turbo |
0613 | texte |
Pour obtenir les informations les plus récentes sur les régions/modèles où le traitement par lots global est actuellement pris en charge, reportez-vous à la page des modèles.
Prise en charge des API
| Version d'API | |
|---|---|
| Dernière version de l’API en disponibilité générale : | 2024-10-21 |
| Dernière préversion de l’API : | 2024-10-01-preview |
Prise en charge ajoutée pour la première fois dans : 2024-07-01-preview
Prise en charge des fonctionnalités
Voici ce qui n’est pas pris en charge :
- Intégration à l’API Assistants.
- Intégration à la fonctionnalité Azure OpenAI sur vos données.
Remarque
Les sorties structurées sont maintenant prises en charge avec le traitement par lots global.
Déploiement de type Traitement par lots global
Dans l’interface utilisateur de Studio, le type de déploiement apparaît comme ceci : Global-Batch.

Conseil
Pour tous les déploiements de modèles de traitement par lots globaux, nous vous recommandons d’activer le quota dynamique afin d’éviter les échecs de tâches dus à un quota insuffisant de jetons en file d’attente. Le quota dynamique permet à votre déploiement d’obtenir occasionnellement plus de quota lorsqu’une capacité supplémentaire est disponible. Lorsque le quota dynamique est désactivé, votre déploiement pourra uniquement traiter les demandes jusqu’à la limite de jetons en file d’attente définie lors de la création du déploiement.
Prérequis
- Un abonnement Azure : créez-en un gratuitement.
- Une ressource Azure OpenAI avec un modèle du type de déploiement
Global-Batchdéployé. Pour obtenir de l’aide sur ce processus, reportez-vous au guide de création de ressources et de déploiement de modèles.
Préparation de votre fichier de commandes
Comme l’ajustement, le traitement par lots global utilise des fichiers au format JSON Lines (.jsonl). Voici quelques exemples de fichiers avec différents types de contenu pris en charge :
Format d’entrée
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
Le custom_id est nécessaire pour vous permettre d’identifier la requête de traitement par lots individuelle correspondant à une réponse donnée. Les réponses ne sont pas retournées dans un ordre identique à celui défini dans le fichier de commandes .jsonl.
L’attribut model doit être défini pour correspondre au nom du déploiement de type Traitement par lots global que vous souhaitez cibler pour les réponses d’inférence.
Important
Vous devez définir l’attribut model pour qu’il corresponde au nom du déploiement de type Traitement par lots global que vous souhaitez cibler pour les réponses d’inférence. Le même nom de modèle de déploiement Traitement par lots global doit être présent sur chaque ligne du fichier par lots. Si vous souhaitez cibler un déploiement différent, vous devez le faire dans un travail/fichier de traitement par lots distinct.
Pour optimiser les performances, nous vous recommandons d’envoyer des fichiers volumineux pour le traitement par lots, plutôt qu’un nombre élevé de petits fichiers avec seulement quelques lignes par fichier.
Créer un fichier d'entrée
Pour les besoins de cet article, nous allons créer un fichier nommé test.jsonl et copier le contenu du bloc de code d’entrée standard ci-dessus dans le fichier. Vous devrez modifier et ajouter le nom de votre déploiement de type Traitement par lots global à chaque ligne du fichier.
Charger le fichier de commandes
Une fois votre fichier d’entrée préparé, vous devez d’abord charger le fichier pour pouvoir ensuite lancer un traitement par lots. Vous pouvez procéder au chargement du fichier par programmation ou via Studio.
Connectez-vous à AI Studio.
Sélectionnez la ressource Azure OpenAI dans laquelle vous disposez d’un déploiement de modèle Traitement par lots global.
Sélectionnez Travaux par lots>+ Créer des travaux par lots.
Dans la liste déroulante sous Données de traitement par lots>Charger des fichiers> sélectionnez Charger le fichier et indiquez le chemin d’accès au fichier
test.jsonlcréé à l’étape précédente >Suivant.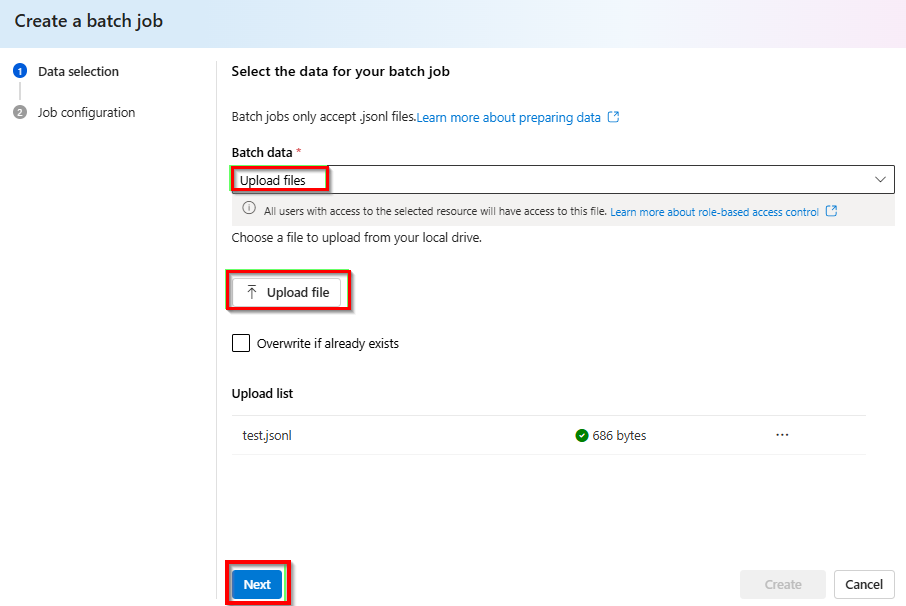


Créer un traitement par lots
Sélectionnez Créer pour démarrer votre traitement par lots.

Suivre la progression d’un traitement par lots
Une fois votre traitement par lots créé, vous pouvez surveiller sa progression en sélectionnant l’ID correspondant au traitement par lots le plus récemment créé. Vous serez dirigé par défaut vers la page d’état pour votre traitement par lots le plus récent.

Vous pouvez suivre l’état de votre traitement par lots dans le volet droit :

Récupérer le fichier de sortie d’un traitement par lots
Une fois votre travail terminé ou dans un état terminal, il génère un fichier d’erreur et un fichier de sortie que vous pouvez télécharger pour examen en sélectionnant le bouton respectif avec l’icône de flèche vers le bas.

Annuler le traitement par lots
Annule un traitement par lots en cours. Le traitement par lots est dans l’état cancelling pendant 10 minutes maximum, avant de passer à cancelled. Des résultats partiels (le cas échéant) sont alors disponibles dans le fichier de sortie.

Prérequis
- Un abonnement Azure : créez-en un gratuitement.
- Python 3.8 ou version ultérieure
- La bibliothèque Python suivante :
openai - Blocs-notes Jupyter
- Une ressource Azure OpenAI avec un modèle du type de déploiement
Global-Batchdéployé. Pour obtenir de l’aide sur ce processus, reportez-vous au guide de création de ressources et de déploiement de modèles.
Les étapes décrites dans cet article sont destinées à être exécutées de manière séquentielle dans Jupyter Notebook. Pour cette raison, nous n’instancierons le client Azure OpenAI qu’une seule fois au début des exemples. Si vous souhaitez exécuter une étape hors séquence, vous devrez souvent configurer un client Azure OpenAI dans le cadre de cet appel.
Même si vous avez déjà installé la bibliothèque Python OpenAI, vous devrez peut-être mettre à niveau votre installation vers la dernière version :
!pip install openai --upgrade
Préparation de votre fichier de commandes
Comme l’ajustement, le traitement par lots global utilise des fichiers au format JSON Lines (.jsonl). Voici quelques exemples de fichiers avec différents types de contenu pris en charge :
Format d’entrée
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
Le custom_id est nécessaire pour vous permettre d’identifier la requête de traitement par lots individuelle correspondant à une réponse donnée. Les réponses ne sont pas retournées dans un ordre identique à celui défini dans le fichier de commandes .jsonl.
L’attribut model doit être défini pour correspondre au nom du déploiement de type Traitement par lots global que vous souhaitez cibler pour les réponses d’inférence.
Important
Vous devez définir l’attribut model pour qu’il corresponde au nom du déploiement de type Traitement par lots global que vous souhaitez cibler pour les réponses d’inférence. Le même nom de modèle de déploiement Traitement par lots global doit être présent sur chaque ligne du fichier par lots. Si vous souhaitez cibler un déploiement différent, vous devez le faire dans un travail/fichier de traitement par lots distinct.
Pour optimiser les performances, nous vous recommandons d’envoyer des fichiers volumineux pour le traitement par lots, plutôt qu’un nombre élevé de petits fichiers avec seulement quelques lignes par fichier.
Créer un fichier d'entrée
Pour les besoins de cet article, nous allons créer un fichier nommé test.jsonl et copier le contenu du bloc de code d’entrée standard ci-dessus dans le fichier. Vous devrez modifier et ajouter le nom de votre déploiement de type Traitement par lots global à chaque ligne du fichier. Enregistrez ce fichier dans le même répertoire que celui dans lequel vous exécutez votre notebook Jupyter.
Charger le fichier de commandes
Une fois votre fichier d’entrée préparé, vous devez d’abord charger le fichier pour pouvoir ensuite lancer un traitement par lots. Vous pouvez procéder au chargement du fichier par programmation ou via Studio. Cet exemple utilise des variables d’environnement à la place des valeurs de clé et de point de terminaison. Si vous n’avez jamais utilisé de variables d’environnement avec Python, reportez-vous à l’un de nos guides de démarrage rapide pour obtenir une explication pas à pas de la configuration des variables d’environnement.
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-21"
)
# Upload a file with a purpose of "batch"
file = client.files.create(
file=open("test.jsonl", "rb"),
purpose="batch"
)
print(file.model_dump_json(indent=2))
file_id = file.id
Sortie :
{
"id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"bytes": 815,
"created_at": 1722476551,
"filename": "test.jsonl",
"object": "file",
"purpose": "batch",
"status": null,
"status_details": null
}
Créer un traitement par lots
Une fois que votre fichier aura été chargé, vous pourrez l’envoyer pour un traitement par lots.
# Submit a batch job with the file
batch_response = client.batches.create(
input_file_id=file_id,
endpoint="/chat/completions",
completion_window="24h",
)
# Save batch ID for later use
batch_id = batch_response.id
print(batch_response.model_dump_json(indent=2))
Remarque
Actuellement, la fenêtre d’achèvement doit être définie sur 24 h. Si vous définissez une valeur autre que 24 h, votre travail échouera. Les tâches prenant plus de 24 heures continueront à s’exécuter jusqu’à leur annulation.
Sortie :
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "validating",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"error_file_id": null,
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": null,
"in_progress_at": null,
"metadata": null,
"output_file_id": null,
"request_counts": {
"completed": 0,
"failed": 0,
"total": 0
}
}
Suivre la progression d’un traitement par lots
Après avoir créé un traitement par lots, vous pouvez surveiller sa progression dans Studio ou par programmation. Lorsque vous vérifiez la progression d’un traitement par lots, nous vous recommandons d’attendre au moins 60 secondes entre chaque appel d’état.
import time
import datetime
status = "validating"
while status not in ("completed", "failed", "canceled"):
time.sleep(60)
batch_response = client.batches.retrieve(batch_id)
status = batch_response.status
print(f"{datetime.datetime.now()} Batch Id: {batch_id}, Status: {status}")
if batch_response.status == "failed":
for error in batch_response.errors.data:
print(f"Error code {error.code} Message {error.message}")
Sortie :
2024-07-31 21:48:32.556488 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: validating
2024-07-31 21:49:39.221560 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:50:53.383138 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:52:07.274570 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:53:21.149501 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:54:34.572508 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:55:35.304713 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:56:36.531816 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:57:37.414105 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: completed
Les valeurs d’état suivantes sont possibles :
| État | Description |
|---|---|
validating |
Le fichier d’entrée est en cours de validation avant que le traitement par lots ne puisse commencer. |
failed |
Le processus de validation du fichier d’entrée a échoué. |
in_progress |
Le fichier d’entrée a été validé et le traitement par lots est en cours d’exécution. |
finalizing |
Le traitement par lots est terminé et les résultats sont en cours de préparation. |
completed |
Le traitement par lots est terminé et les résultats sont prêts. |
expired |
Le traitement par lots n’a pas pu être terminé dans la fenêtre de temps de 24 heures. |
cancelling |
Le traitement par lots est sur le point d’être cancelled, ce qui peut prendre jusqu’à 10 minutes pour entrer en vigueur. |
cancelled |
Le traitement par lots a été cancelled. |
Pour examiner les détails de l’état du travail, vous pouvez exécuter :
print(batch_response.model_dump_json(indent=2))
Sortie :
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "completed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1722477429,
"error_file_id": "file-c795ae52-3ba7-417d-86ec-07eebca57d0b",
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": 1722477177,
"in_progress_at": null,
"metadata": null,
"output_file_id": "file-3304e310-3b39-4e34-9f1c-e1c1504b2b2a",
"request_counts": {
"completed": 3,
"failed": 0,
"total": 3
}
}
Notez la présence d’un error_file_id et d’un output_file_iddistinct. Utilisez error_file_id pour faciliter le débogage des problèmes qui se produisent avec votre traitement par lots.
Récupérer le fichier de sortie d’un traitement par lots
import json
output_file_id = batch_response.output_file_id
if not output_file_id:
output_file_id = batch_response.error_file_id
if output_file_id:
file_response = client.files.content(output_file_id)
raw_responses = file_response.text.strip().split('\n')
for raw_response in raw_responses:
json_response = json.loads(raw_response)
formatted_json = json.dumps(json_response, indent=2)
print(formatted_json)
Sortie :
Par souci de concision, nous n’incluons qu’une seule réponse d’achèvement de conversation de sortie. Si vous suivez les étapes de cet article, vous devriez avoir trois réponses similaires à celle ci-dessous :
{
"custom_id": "task-0",
"response": {
"body": {
"choices": [
{
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
},
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "Microsoft was founded on April 4, 1975, by Bill Gates and Paul Allen in Albuquerque, New Mexico.",
"role": "assistant"
}
}
],
"created": 1722477079,
"id": "chatcmpl-9rFGJ9dh08Tw9WRKqaEHwrkqRa4DJ",
"model": "gpt-4o-2024-05-13",
"object": "chat.completion",
"prompt_filter_results": [
{
"prompt_index": 0,
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"jailbreak": {
"filtered": false,
"detected": false
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"system_fingerprint": "fp_a9bfe9d51d",
"usage": {
"completion_tokens": 24,
"prompt_tokens": 27,
"total_tokens": 51
}
},
"request_id": "660b7424-b648-4b67-addc-862ba067d442",
"status_code": 200
},
"error": null
}
Commandes de traitement par lots supplémentaires
Annuler le traitement par lots
Annule un traitement par lots en cours. Le traitement par lots est dans l’état cancelling pendant 10 minutes maximum, avant de passer à cancelled. Des résultats partiels (le cas échéant) sont alors disponibles dans le fichier de sortie.
client.batches.cancel("batch_abc123") # set to your batch_id for the job you want to cancel
Lister les traitements par lots
Répertorier les traitements par lots pour une ressource Azure OpenAI particulière.
client.batches.list()
Les méthodes de liste de la bibliothèque Python sont paginés.
Pour répertorier tous les travaux :
all_jobs = []
# Automatically fetches more pages as needed.
for job in client.batches.list(
limit=20,
):
# Do something with job here
all_jobs.append(job)
print(all_jobs)
Répertorier les traitements par lots (préversion)
Utilisez l’API REST pour répertorier tous les travaux de traitement par lots avec des options de tri/filtrage supplémentaires.
Dans les exemples ci-dessous, nous fournissons la fonction generate_time_filter pour faciliter la construction du filtre. Si vous ne souhaitez pas utiliser cette fonction, le format de la chaîne de filtre ressemble à created_at gt 1728860560 and status eq 'Completed'.
import requests
import json
from datetime import datetime, timedelta
from azure.identity import DefaultAzureCredential
token_credential = DefaultAzureCredential()
token = token_credential.get_token('https://cognitiveservices.azure.com/.default')
endpoint = "https://{YOUR_RESOURCE_NAME}.openai.azure.com/"
api_version = "2024-10-01-preview"
url = f"{endpoint}openai/batches"
order = "created_at asc"
time_filter = lambda: generate_time_filter("past 8 hours")
# Additional filter examples:
#time_filter = lambda: generate_time_filter("past 1 day")
#time_filter = lambda: generate_time_filter("past 3 days", status="Completed")
def generate_time_filter(time_range, status=None):
now = datetime.now()
if 'day' in time_range:
days = int(time_range.split()[1])
start_time = now - timedelta(days=days)
elif 'hour' in time_range:
hours = int(time_range.split()[1])
start_time = now - timedelta(hours=hours)
else:
raise ValueError("Invalid time range format. Use 'past X day(s)' or 'past X hour(s)'")
start_timestamp = int(start_time.timestamp())
filter_string = f"created_at gt {start_timestamp}"
if status:
filter_string += f" and status eq '{status}'"
return filter_string
filter = time_filter()
headers = {'Authorization': 'Bearer ' + token.token}
params = {
"api-version": api_version,
"$filter": filter,
"$orderby": order
}
response = requests.get(url, headers=headers, params=params)
json_data = response.json()
if response.status_code == 200:
print(json.dumps(json_data, indent=2))
else:
print(f"Request failed with status code: {response.status_code}")
print(response.text)
Sortie :
{
"data": [
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729011896,
"completion_window": "24h",
"created_at": 1729011128,
"error_file_id": "file-472c0626-4561-4327-9e4e-f41afbfb30e6",
"expired_at": null,
"expires_at": 1729097528,
"failed_at": null,
"finalizing_at": 1729011805,
"id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"in_progress_at": 1729011493,
"input_file_id": "file-f89384af0082485da43cb26b49dc25ce",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-62bebde8-e767-4cd3-a0a1-28b214dc8974",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
},
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729016366,
"completion_window": "24h",
"created_at": 1729015829,
"error_file_id": "file-85ae1971-9957-4511-9eb4-4cc9f708b904",
"expired_at": null,
"expires_at": 1729102229,
"failed_at": null,
"finalizing_at": 1729016272,
"id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43",
"in_progress_at": 1729016126,
"input_file_id": "file-686746fcb6bc47f495250191ffa8a28e",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-04399828-ae0b-4825-9b49-8976778918cb",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
}
],
"first_id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"has_more": false,
"last_id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43"
}
Prérequis
- Un abonnement Azure : créez-en un gratuitement.
- Une ressource Azure OpenAI avec un modèle du type de déploiement
Global-Batchdéployé. Pour obtenir de l’aide sur ce processus, reportez-vous au guide de création de ressources et de déploiement de modèles.
Préparation de votre fichier de commandes
Comme l’ajustement, le traitement par lots global utilise des fichiers au format JSON Lines (.jsonl). Voici quelques exemples de fichiers avec différents types de contenu pris en charge :
Format d’entrée
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
Le custom_id est nécessaire pour vous permettre d’identifier la requête de traitement par lots individuelle correspondant à une réponse donnée. Les réponses ne sont pas retournées dans un ordre identique à celui défini dans le fichier de commandes .jsonl.
L’attribut model doit être défini pour correspondre au nom du déploiement de type Traitement par lots global que vous souhaitez cibler pour les réponses d’inférence.
Important
Vous devez définir l’attribut model pour qu’il corresponde au nom du déploiement de type Traitement par lots global que vous souhaitez cibler pour les réponses d’inférence. Le même nom de modèle de déploiement Traitement par lots global doit être présent sur chaque ligne du fichier par lots. Si vous souhaitez cibler un déploiement différent, vous devez le faire dans un travail/fichier de traitement par lots distinct.
Pour optimiser les performances, nous vous recommandons d’envoyer des fichiers volumineux pour le traitement par lots, plutôt qu’un nombre élevé de petits fichiers avec seulement quelques lignes par fichier.
Créer un fichier d'entrée
Pour les besoins de cet article, nous allons créer un fichier nommé test.jsonl et copier le contenu du bloc de code d’entrée standard ci-dessus dans le fichier. Vous devrez modifier et ajouter le nom de votre déploiement de type Traitement par lots global à chaque ligne du fichier.
Charger le fichier de commandes
Une fois votre fichier d’entrée préparé, vous devez d’abord charger le fichier pour pouvoir ensuite lancer un traitement par lots. Vous pouvez procéder au chargement du fichier par programmation ou via Studio. Cet exemple utilise des variables d’environnement à la place des valeurs de clé et de point de terminaison. Si vous n’avez jamais utilisé de variables d’environnement avec Python, reportez-vous à l’un de nos guides de démarrage rapide pour obtenir une explication pas à pas de la configuration des variables d’environnement.
Important
Si vous utilisez une clé API, stockez-la en toute sécurité dans un autre emplacement, par exemple dans Azure Key Vault. N'incluez pas la clé API directement dans votre code et ne la diffusez jamais publiquement.
Pour plus d’informations sur la sécurité des services IA, consultez Authentifier les demandes auprès d’Azure AI services.
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files?api-version=2024-10-21 \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=batch" \
-F "file=@C:\\batch\\test.jsonl;type=application/json"
Le code ci-dessus suppose un chemin d’accès de fichier particulier pour votre fichier test.jsonl. Si nécessaire, ajustez ce chemin d’accès de fichier pour votre système local.
Sortie :
{
"status": "pending",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
Suivre l’état du chargement du fichier
En fonction de la taille de votre fichier de chargement, le processus de chargement et de traitement peut prendre un certain temps. Pour vérifier l’état du chargement de votre fichier, exécutez :
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{file-id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
Sortie :
{
"status": "processed",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
Créer un traitement par lots
Une fois que votre fichier aura été chargé, vous pourrez l’envoyer pour un traitement par lots.
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"input_file_id": "file-abc123",
"endpoint": "/chat/completions",
"completion_window": "24h"
}'
Remarque
Actuellement, la fenêtre d’achèvement doit être définie sur 24 h. Si vous définissez une valeur autre que 24 h, votre travail échouera. Les tâches prenant plus de 24 heures continueront à s’exécuter jusqu’à leur annulation.
Sortie :
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:13:57.2491382+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:13:57.1918498+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_fe3f047a-de39-4068-9008-346795bfc1db",
"in_progress_at": null,
"input_file_id": "file-21006e70789246658b86a1fc205899a4",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
Suivre la progression d’un traitement par lots
Après avoir créé un traitement par lots, vous pouvez surveiller sa progression dans Studio ou par programmation. Lorsque vous vérifiez la progression d’un traitement par lots, nous vous recommandons d’attendre au moins 60 secondes entre chaque appel d’état.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
Sortie :
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:33:29.1619286+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:33:29.1578141+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_e0a7ee28-82c4-46a2-a3a0-c13b3c4e390b",
"in_progress_at": null,
"input_file_id": "file-c55ec4e859d54738a313d767718a2ac5",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
Les valeurs d’état suivantes sont possibles :
| État | Description |
|---|---|
validating |
Le fichier d’entrée est en cours de validation avant que le traitement par lots ne puisse commencer. |
failed |
Le processus de validation du fichier d’entrée a échoué. |
in_progress |
Le fichier d’entrée a été validé et le traitement par lots est en cours d’exécution. |
finalizing |
Le traitement par lots est terminé et les résultats sont en cours de préparation. |
completed |
Le traitement par lots est terminé et les résultats sont prêts. |
expired |
Le traitement par lots n’a pas pu être terminé dans la fenêtre de temps de 24 heures. |
cancelling |
Le traitement par lots est sur le point d’être cancelled, ce qui peut prendre jusqu’à 10 minutes pour entrer en vigueur. |
cancelled |
Le traitement par lots a été cancelled. |
Récupérer le fichier de sortie d’un traitement par lots
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{output_file_id}/content?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" > batch_output.jsonl
Commandes de traitement par lots supplémentaires
Annuler le traitement par lots
Annule un traitement par lots en cours. Le traitement par lots est dans l’état cancelling pendant 10 minutes maximum, avant de passer à cancelled. Des résultats partiels (le cas échéant) sont alors disponibles dans le fichier de sortie.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}/cancel?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
Lister les traitements par lots
Répertorier les traitements par lots existants pour une ressource Azure OpenAI donnée.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
L’appel d’API de liste est paginé. La réponse contient une has_more booléenne pour indiquer lorsqu’il y a plus de résultats à parcourir.
Répertorier les traitements par lots (préversion)
Utilisez l’API REST pour répertorier tous les travaux de traitement par lots avec des options de tri/filtrage supplémentaires.
curl "YOUR_RESOURCE_NAME.openai.azure.com/batches?api-version=2024-10-01-preview&$filter=created_at%20gt%201728773533%20and%20created_at%20lt%201729032733%20and%20status%20eq%20'Completed'&$orderby=created_at%20asc" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Pour éviter l’erreur URL rejected: Malformed input to a URL function, les espaces sont remplacés par %20.
Limites du traitement par lots global
| Nom de la limite | Limite de la valeur |
|---|---|
| Nombre maximal de fichiers par ressource | 500 |
| Taille maximale de fichier d’entrée | 200 Mo |
| Nombre maximal de requêtes par fichier | 100 000 |
Quota du traitement par lots global
Le tableau indique la limite de quota du traitement par lots. Les valeurs de quota pour le traitement par lots global sont représentées en termes de jetons empilés. Quand vous envoyez un fichier pour le traitement par lots, les jetons présents dans le fichier sont comptabilisés. Tant que le traitement par lots n’atteint pas un état terminal, ces jetons sont comptabilisés dans votre limite totale de jetons empilés.
| Modèle | Contrat Entreprise | Par défaut | Abonnements mensuels basés sur une carte de crédit | Abonnements MSDN | Microsoft Azure for Students, essais gratuits |
|---|---|---|---|---|---|
gpt-4o |
5 B | 200 M | 50 M | 90 K | S/O |
gpt-4o-mini |
15 o | 1 o | 50 M | 90 K | S/O |
gpt-4-turbo |
300 M | 80 M | 40 M | 90 K | S/O |
gpt-4 |
150 M | 30 M | 5 M | 100 K | S/O |
gpt-35-turbo |
10 B | 1 o | 100 M | 2 m | 50 K |
B = milliard | M = million | K = mille
Objet Batch
| Propriété | Type | Définition |
|---|---|---|
id |
string | |
object |
string | batch |
endpoint |
string | Point de terminaison d’API utilisé par le traitement par lots |
errors |
object | |
input_file_id |
string | ID du fichier d’entrée du traitement par lots |
completion_window |
string | Délai d’exécution dans lequel le traitement par lots doit avoir lieu |
status |
string | État actuel du lot. Valeurs possibles : validating, failed, in_progress, finalizing, completed, expired, cancelling, cancelled. |
output_file_id |
string | ID du fichier contenant les sorties des requêtes exécutées avec succès. |
error_file_id |
string | ID du fichier contenant les sorties des requêtes avec des erreurs. |
created_at |
entier | Horodatage indiquant quand ce traitement par lots a été créé (en époques Unix). |
in_progress_at |
entier | Horodatage indiquant quand ce traitement par lots a démarré (en époques Unix). |
expires_at |
entier | Horodatage indiquant quand ce traitement par lots expirera (en époques Unix). |
finalizing_at |
entier | Horodatage indiquant quand ce traitement par lots est entré en phase de finalisation (en époques Unix). |
completed_at |
entier | Horodatage indiquant quand ce traitement par lots est entré en phase de finalisation (en époques Unix). |
failed_at |
entier | Horodatage indiquant quand ce traitement par lots a échoué (en époques Unix). |
expired_at |
entier | Horodatage indiquant quand ce traitement par lots a expiré (en époques Unix). |
cancelling_at |
entier | Horodatage indiquant quand ce traitement par lots est entré en phase cancelling (en époques Unix). |
cancelled_at |
entier | Horodatage indiquant quand ce traitement par lots a été cancelled (en époques Unix). |
request_counts |
object | Structure d’objet :total entier Nombre total de requêtes dans le traitement par lots. completed entier Nombre de requêtes dans le traitement par lots qui ont été exécutées avec succès. failed entier Nombre de requêtes dans le traitement par lots qui ont échoué. |
metadata |
map | Ensemble de paires clé-valeur pouvant être attachées au traitement par lots. Cette propriété peut être utile pour stocker des informations supplémentaires sur le traitement par lots dans un format structuré. |
Forum aux questions (FAQ)
Des images peuvent-elles être utilisées avec l’API Batch ?
Cette fonctionnalité est limitée à certains modèles multimodaux. Actuellement, seul GPT-4o prend en charge les images dans le cadre de requêtes de traitement par lots. Les images peuvent être fournies en entrée via l’URL d’image ou une représentation codée en base64 de l’image. Les images pour le traitement par lots ne sont actuellement pas prises en charge avec GPT-4 Turbo.
Puis-je utiliser l’API Batch avec des modèles ajustés ?
Non pris en charge actuellement.
Puis-je utiliser l’API Batch avec des modèles d’incorporations ?
Non pris en charge actuellement.
Le filtrage de contenu fonctionne-t-il avec le déploiement de type Traitement par lots global ?
Oui. Comme pour d’autres types de déploiement, vous pouvez créer des filtres de contenu et les associer au déploiement de type Traitement par lots global.
Puis-je demander un quota supplémentaire ?
Oui, à partir de la page de quota dans l’interface utilisateur de Studio. Vous trouverez l’allocation de quota par défaut dans l’article sur les quotas et les limites.
Que se passe-t-il si l’API ne termine pas ma requête dans le délai d’exécution de 24 heures ?
Nous nous efforçons de traiter ces requêtes de traitement par lots dans un délai de 24 heures (les travaux qui prennent plus de temps n’expirent pas). Vous pouvez annuler le travail à tout moment. Quand vous annulez le travail, tout travail restant est annulé et tout travail déjà terminé est retourné. Tout travail terminé vous est facturé.
Combien de requêtes puis-je mettre en file d’attente à l’aide du traitement par lots ?
Il n’y a aucune limite fixe quant au nombre de requêtes que vous pouvez traiter par lots. Toutefois, cela dépend de votre quota de jetons empilés. Votre quota de jetons empilés inclut le nombre maximal de jetons d’entrée que vous pouvez empiler à la fois.
Une fois votre requête de traitement par lots terminée, la limite de débit du traitement par lots est réinitialisée à mesure que vos jetons d’entrée sont effacés. La limite dépend du nombre de requêtes globales dans la file d’attente. Si la file d’attente de l’API Batch traite rapidement vos lots, la limite de débit du traitement par lots est réinitialisée plus rapidement.
Dépannage
Un travail est réussi lorsque status est Completed. Les tâches réussies génèrent toujours un error_file_id, mais il est associé à un fichier vide avec zéro octet.
En cas d’échec d’un travail, vous trouverez des détails sur l’échec dans la propriété errors :
"value": [
{
"id": "batch_80f5ad38-e05b-49bf-b2d6-a799db8466da",
"completion_window": "24h",
"created_at": 1725419394,
"endpoint": "/chat/completions",
"input_file_id": "file-c2d9a7881c8a466285e6f76f6321a681",
"object": "batch",
"status": "failed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1725419955,
"error_file_id": "file-3b0f9beb-11ce-4796-bc31-d54e675f28fb",
"errors": {
"object": “list”,
"data": [
{
“code”: “empty_file”,
“message”: “The input file is empty. Please ensure that the batch contains at least one request.”
}
]
},
"expired_at": null,
"expires_at": 1725505794,
"failed_at": null,
"finalizing_at": 1725419710,
"in_progress_at": 1725419572,
"metadata": null,
"output_file_id": "file-ef12af98-dbbc-4d27-8309-2df57feed572",
"request_counts": {
"total": 10,
"completed": null,
"failed": null
},
}
Codes d’erreur
| Code d'erreur | Définition |
|---|---|
invalid_json_line |
Une ou plusieurs lignes dans votre fichier d’entrée n’ont pas pu être analysées en raison d’un format JSON non valide. Assurez-vous qu’il n’y a pas de fautes de frappe, que vous utilisez des crochets ouvrants et fermants appropriés et que les guillemets sont conformes à la norme JSON, puis renvoyez la requête. |
too_many_tasks |
Le nombre de requêtes dans le fichier d’entrée dépasse la valeur maximale autorisée de 100 000 requêtes. Vérifiez que le nombre total de vos requêtes est inférieur à 100 000, puis renvoyez le travail. |
url_mismatch |
Une ligne de votre fichier d’entrée a une URL qui ne correspond pas au reste des lignes ou l’URL spécifiée dans le fichier d’entrée ne correspond pas à l’URL de point de terminaison attendue. Vérifiez que toutes les URL de requête sont identiques et qu’elles correspondent à l’URL du point de terminaison associée à votre déploiement Azure OpenAI. |
model_not_found |
Le nom du modèle de déploiement Azure OpenAI spécifié dans la propriété model du fichier d’entrée est introuvable.Vérifiez que ce nom pointe vers un modèle de déploiement Azure OpenAI valide. |
duplicate_custom_id |
L’ID personnalisé de cette requête est un doublon de l’ID personnalisé dans une autre requête. |
empty_batch |
Vérifiez votre fichier d’entrée pour vous assurer que le paramètre d’ID personnalisé est unique pour chaque requête dans le traitement par lots. |
model_mismatch |
Le nom du modèle de déploiement Azure OpenAI spécifié dans la propriété model de cette requête dans le fichier d’entrée ne correspond pas au reste du fichier.Vérifiez que toutes les requêtes du traitement par lots pointent vers le même modèle de déploiement AOAI dans la propriété model de la requête. |
invalid_request |
Le schéma de la ligne d’entrée n’est pas valide ou la référence SKU de déploiement n’est pas valide. Vérifiez que les propriétés de la requête dans votre fichier d’entrée correspondent aux propriétés d’entrée attendues et que la référence SKU de déploiement Azure OpenAI est globalbatch pour les requêtes d’API Batch. |
Problèmes connus
- Les ressources déployées avec Azure CLI ne fonctionnent pas avec le traitement par lots global Azure OpenAI. Le problème vient du fait que les ressources déployées à l’aide de cette méthode ont des sous-domaines de point de terminaison qui ne respectent pas le modèle
https://your-resource-name.openai.azure.com. Une solution de contournement consiste à déployer une nouvelle ressource Azure OpenAI à l’aide de l’une des autres méthodes de déploiement courantes afin de gérer correctement la configuration du sous-domaine dans le cadre du processus de déploiement.
Voir aussi
- En savoir plus sur les types de déploiement Azure OpenAI
- En savoir plus sur les quotas et limites Azure OpenAI