Démarrage rapide : flux de travail d’orchestration
Cet article explique comment commencer des projets de flux de travail d’orchestration à l’aide de Language Studio et de l’API REST. Pour essayer un exemple, procédez comme suit.
Prérequis
- Abonnement Azure : créez-en un gratuitement.
- Un projet de compréhension du langage courant.
Connexion à Language Studio
Accédez à Language Studio et connectez-vous avec votre compte Azure.
Dans la fenêtre Choose a language resource (Choisir une ressource de langue) qui s’affiche, recherchez votre abonnement Azure, puis choisissez votre ressource de langue. Si vous n’avez pas de ressource, vous pouvez en créer une nouvelle.
Détails de l’instance Valeur requise Abonnement Azure Votre abonnement Azure. Groupe de ressources Azure Votre groupe de ressources Azure. Nom de la ressource Azure Nom de votre ressource Azure. Emplacement Emplacement valide pour votre ressource Azure. Par exemple, « USA Ouest 2 ». Niveau tarifaire Niveau tarifaire pris en charge pour votre ressource Azure. Vous pouvez utiliser le niveau tarifaire gratuit (F0) pour tester le service. 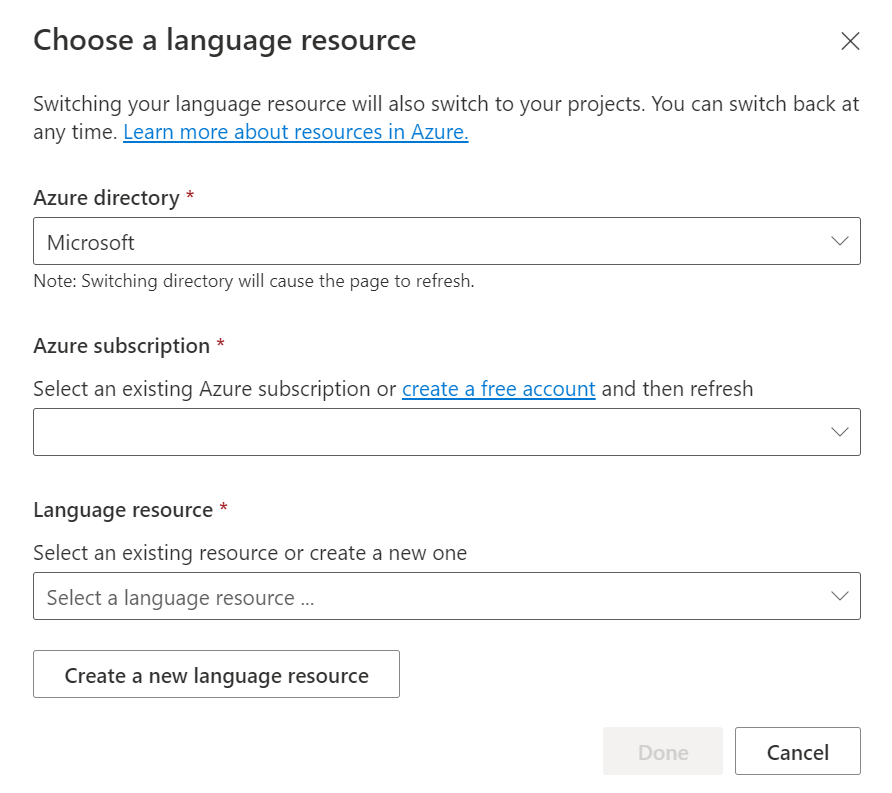

Création d’un projet de flux de travail d’orchestration
Une fois que vous avez créé une ressource Language, créez un projet de workflow d’orchestration. Un projet est une zone de travail qui vous permet de créer des modèles ML personnalisés en fonction de vos données. Seuls les utilisateurs qui disposent d’un accès à la ressource de langue utilisée peuvent accéder à votre projet.
Pour ce guide de démarrage rapide, suivez le guide de démarrage rapide de compréhension du langage conversationnel pour créer un projet de compréhension du langage conversationnel qui sera utilisé ultérieurement.
Dans Language Studio, recherchez la section intitulée Comprendre les questions et le langage courant, puis sélectionnez Flux de travail d’orchestration.

Cela vous conduit à la page Projet de flux de travail d’orchestration. Sélectionnez Create new project. Pour créer un projet, vous devez fournir les informations suivantes :

| Valeur | Description |
|---|---|
| Nom | Nom de votre projet |
| Description | Description facultative du projet. |
| Langue principale des énoncés | Langue principale de votre projet. Vos données de formation doivent être principalement dans cette langue. |
Une fois terminé, sélectionnez Suivant et passez en revue les détails. Sélectionnez Create project (Créer un projet) pour finaliser le processus. Vous devez maintenant voir l’écran Build Schema (Générer le schéma) dans votre projet.
Générer le schéma
Une fois que vous avez parcouru le guide de démarrage rapide CLU dans son intégralité et créé un projet d’orchestration, l’étape suivante consiste à ajouter des intentions.
Pour vous connecter au projet de compréhension du langage conversationnel précédemment créé :
- Dans la page créer un schéma de votre projet d’orchestration, sélectionnez Ajouter pour ajouter une intention.
- Dans la fenêtre qui s’affiche, donnez un nom à votre intention.
- Sélectionnez Oui, je veux le connecter à un projet existant.
- Dans la liste déroulante des services connectés, sélectionnez Compréhension du langage courant.
- Dans la liste déroulante du nom de projet, sélectionnez votre CLU.
- Sélectionnez Ajouter une intention pour créer votre intention.
Entraîner votre modèle
Pour entraîner un modèle, vous devez démarrer un travail d’entraînement. La sortie d’un travail d’entraînement réussi est votre modèle formé.
Pour commencer à effectuer l’apprentissage de votre modèle à partir de Language Studio :
Dans le menu de gauche, sélectionnez Travaux d’entraînement.
Sélectionnez Démarrer un travail de formation dans le menu supérieur.
Sélectionnez Effectuer l’apprentissage d’un nouveau modèle, puis tapez le nom du modèle dans la zone de texte. Vous pouvez également remplacer un modèle existant en sélectionnant cette option et le modèle de votre choix dans le menu déroulant. La remplacement d’un modèle entraîné est irréversible. Toutefois, cela n’affecte pas vos modèles déployés tant que vous ne déployez pas le nouveau modèle.
Si vous avez autorisé votre projet à fractionner manuellement vos données pendant l’étiquetage de vos énoncés, deux options de fractionnement des données s’offrent à vous :
- Fractionnement automatique du jeu de test à partir des données d’entraînement : vos énoncés étiquetés sont fractionnés de façon aléatoire en jeux d’entraînement et de test, selon les pourcentages que vous avez choisis. Le pourcentage par défaut est de 80 % pour l’entraînement et de 20 % pour les tests. Pour changer ces valeurs, choisissez le jeu que vous voulez changer et tapez la nouvelle valeur.
Notes
Si vous choisissez l’option Fractionnement automatique du jeu de test à partir des données d’entraînement, seuls les énoncés présents dans votre jeu d’entraînement sont fractionnés selon les pourcentages indiqués.
- Utiliser un fractionnement manuel des données d’entraînement et de test : affectez chaque énoncé au jeu d’entraînement ou de test à l’étape d’étiquetage du projet.
Notes
L’option Utiliser un fractionnement manuel des données d’entraînement et de test est activée uniquement si vous ajoutez des énoncés au jeu de test dans la page d’étiquetage des données. Sinon, elle sera désactivée.
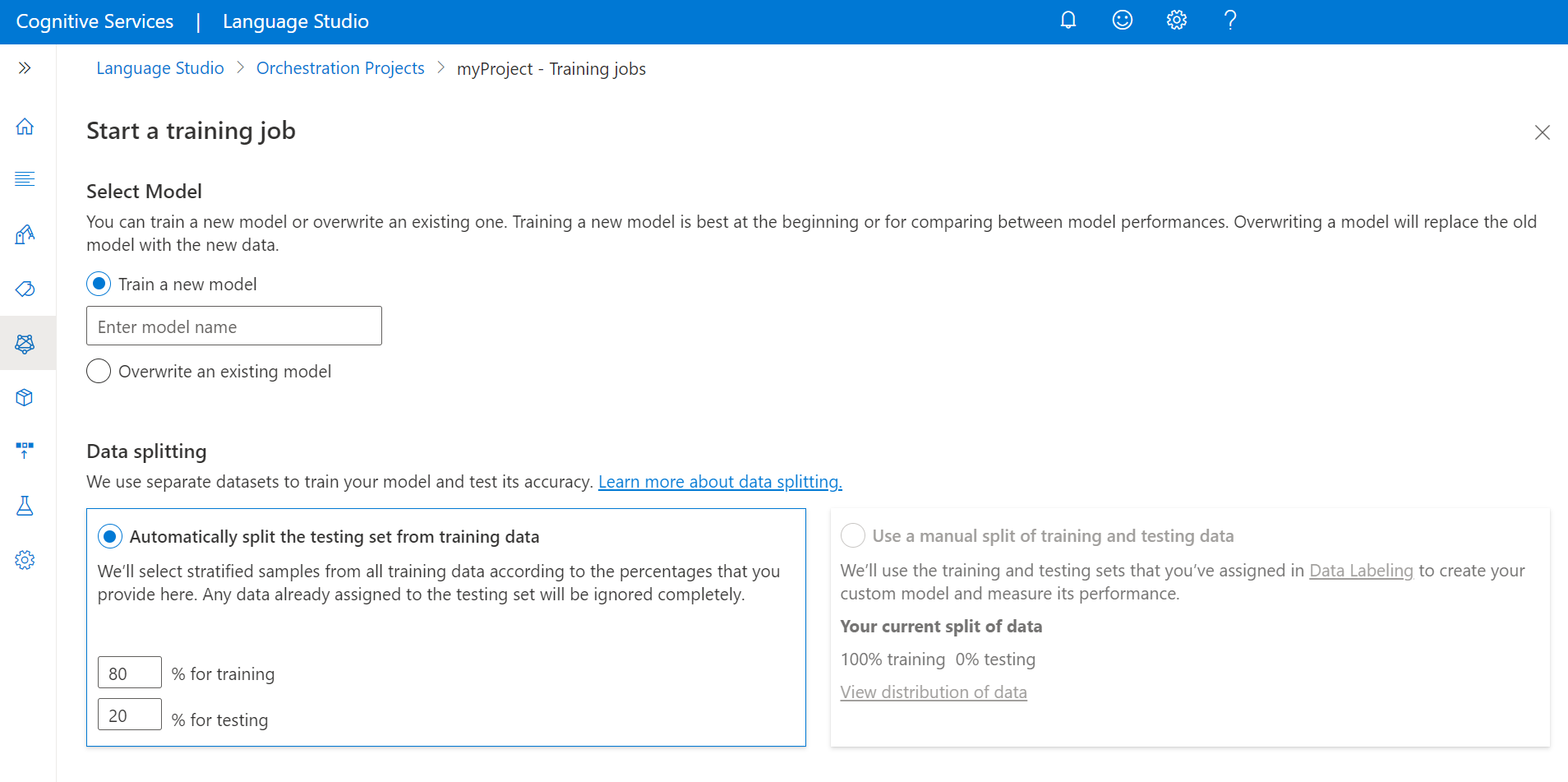
Sélectionner le bouton Train (Entraîner).

Notes
- Seuls les emplois de formation achevés avec succès génèrent des modèles.
- L’entraînement peut durer de quelques minutes à quelques heures en fonction de la taille de vos données étiquetées.
- Vous ne pouvez avoir qu’un seul travail d’entraînement en cours d’exécution à la fois. Vous ne pouvez pas lancer un autre travail d’entraînement dans le même projet tant que le travail en cours d’exécution n’est pas terminé.
Déployer votre modèle
En général, après avoir formé un modèle, vous examinez les détails de son évaluation. Dans ce guide de démarrage rapide, vous allez simplement déployer votre modèle et le rendre disponible pour pouvoir l’essayer dans Language Studio. Vous pouvez également appeler l’API de prévision.
Pour déployer votre modèle à partir de Language Studio :
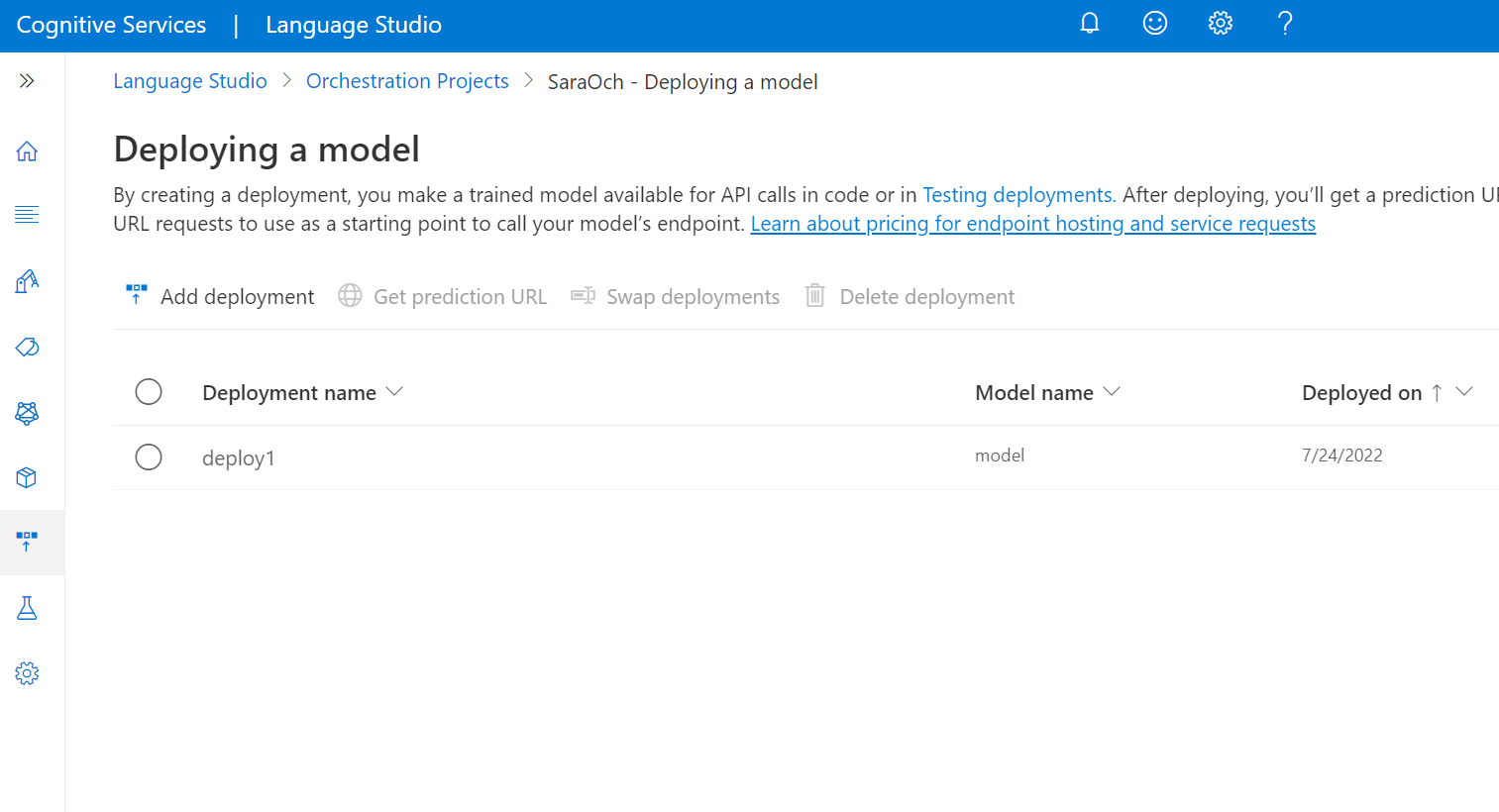
Dans le menu de gauche, sélectionnez Déploiement d’un modèle.
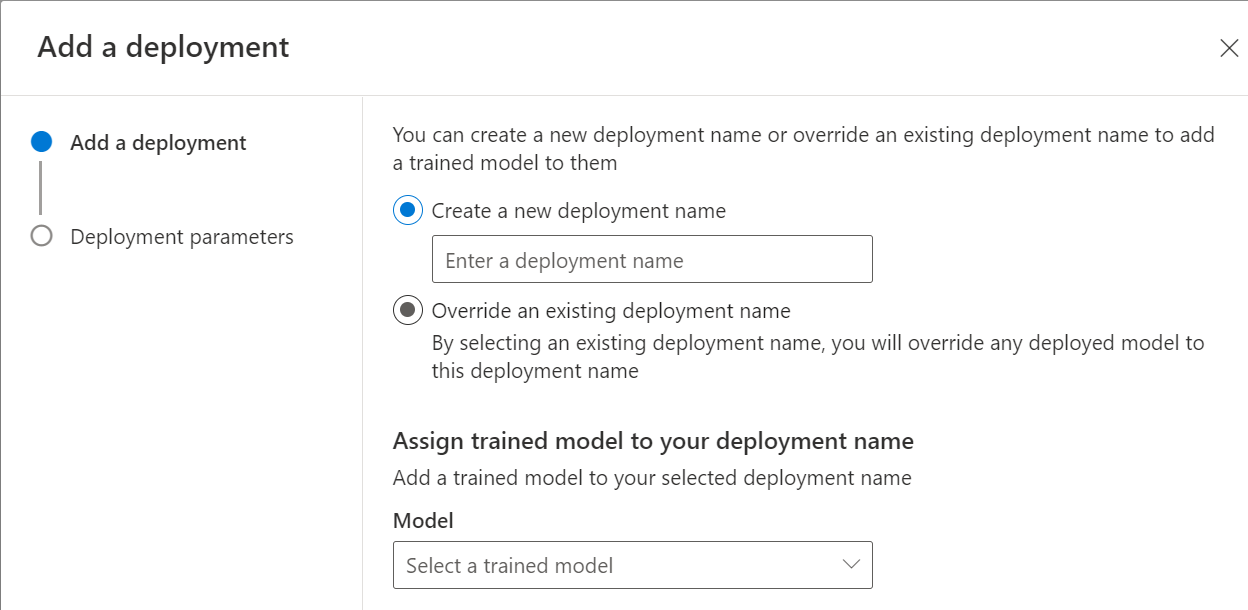
Sélectionnez Ajouter un déploiement pour démarrer un nouveau travail de déploiement.
Sélectionnez Créer un déploiement pour créer un déploiement et attribuer un modèle entraîné dans la liste déroulante ci-dessous. Vous pouvez également Remplacer un déploiement existant en sélectionnant cette option et en sélectionnant le modèle entraîné que vous souhaitez attribuer dans la liste déroulante ci-dessous.
Notes
Le remplacement d’un déploiement existant ne nécessite pas de modifier votre appel de l’API de prédiction. Toutefois, les résultats obtenus sont basés sur le modèle nouvellement attribué.
Si vous connectez une ou plusieurs applications LUIS ou des projets de compréhension du langage courant, vous devez spécifier le nom du déploiement.
Aucune configuration n’est nécessaire pour la réponse personnalisée aux questions ou pour les intentions non liées.
Les projets LUIS doivent être publiés sur l’emplacement configuré lors du déploiement de l’orchestration, et les bases de connaissances de réponses aux questions personnalisées doivent également être publiés sur leurs emplacements de production.
Sélectionnez Déployer pour envoyer votre travail de déploiement
Une fois le déploiement réussi, une date d’expiration s’affiche à côté de celui-ci. L’expiration du déploiement correspond au moment où votre modèle déployé n’est plus disponible pour la prédiction. Cela se produit généralement douze mois après l’expiration d’une configuration de l’apprentissage.


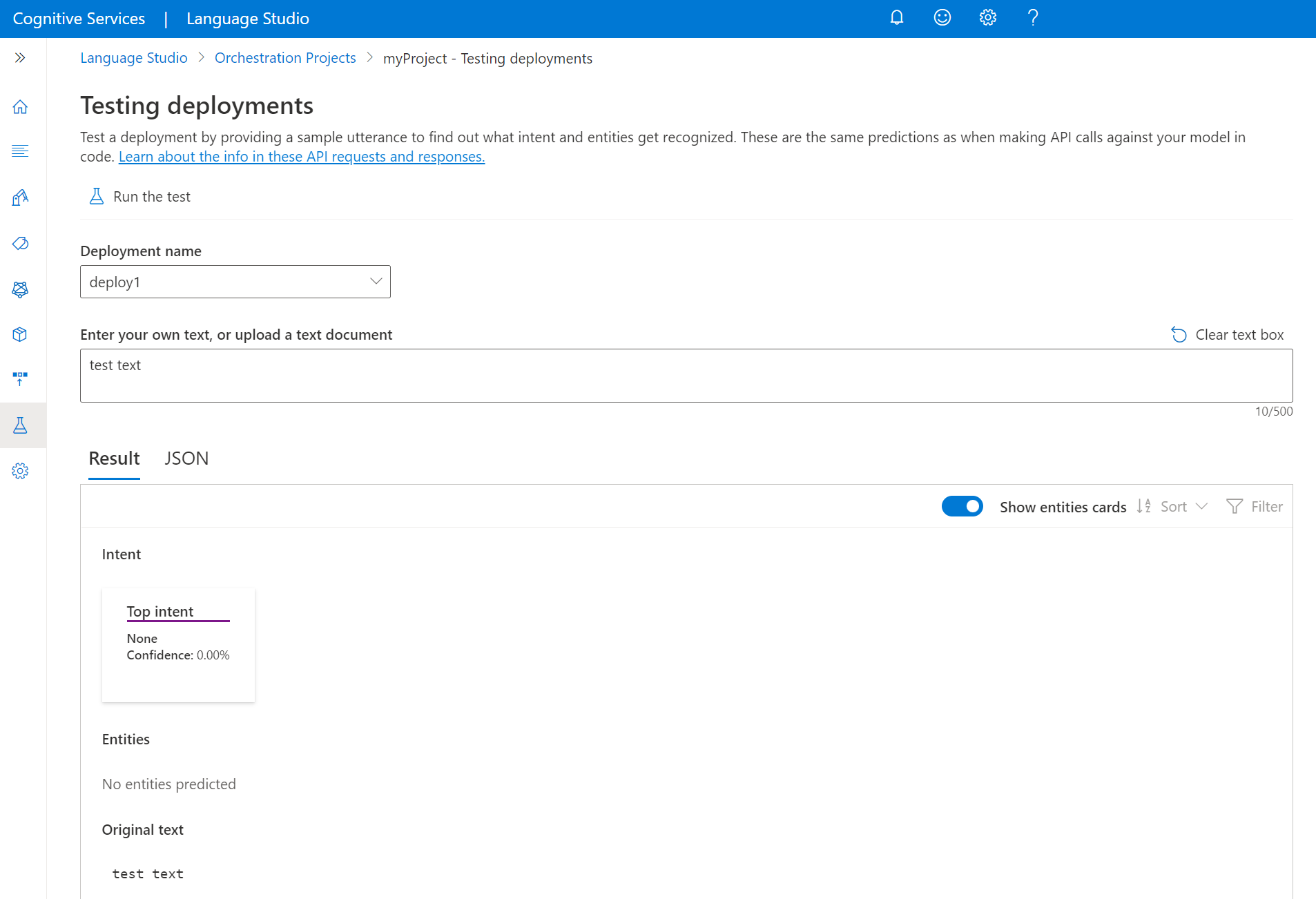
Tester le modèle
Une fois votre modèle déployé, vous pouvez commencer à l’utiliser pour faire des prédictions via l’API de prédiction. Pour ce démarrage rapide, vous pouvez utiliser Language Studio pour envoyer un énoncé, obtenir des prédictions et visualiser les résultats.
Pour tester votre modèle à partir de Language Studio
Sélectionnez Test des déploiements dans le menu de gauche.
Sélectionnez le modèle à tester. Vous pouvez uniquement tester les modèles qui sont attribués aux déploiements.
Dans la liste déroulante nom du déploiement, sélectionnez le nom de votre déploiement.
Dans la zone de texte, entrez un énoncé à tester.
Dans le menu supérieur, sélectionnez Exécuter le test.
Après avoir exécuté le test, vous devriez voir la réponse du modèle dans le résultat. Vous pouvez afficher les résultats en mode cartes d’entités ou au format JSON.

Nettoyer les ressources
Une fois que vous n’avez plus besoin de votre projet, vous pouvez le supprimer à l’aide de Language Studio. Sélectionnez Projets dans le menu de navigation de gauche, sélectionnez le projet que vous voulez supprimer, puis cliquez sur Supprimer dans le menu du haut.
Prérequis
- Abonnement Azure : créez-en un gratuitement.
Créer une ressource Language à partir du portail Azure
Créer une ressource à partir du portail Azure
Accédez au Portail Azure pour créer une ressource Azure AI Language.
Sélectionnez Continuer pour créer votre ressource
Créez une ressource de langue avec les détails suivants.
Détails de l’instance Valeur requise Région Une des régions prises en charge. Nom Nom de votre ressource de langue. Niveau tarifaire Un des niveaux tarifaires pris en charge.
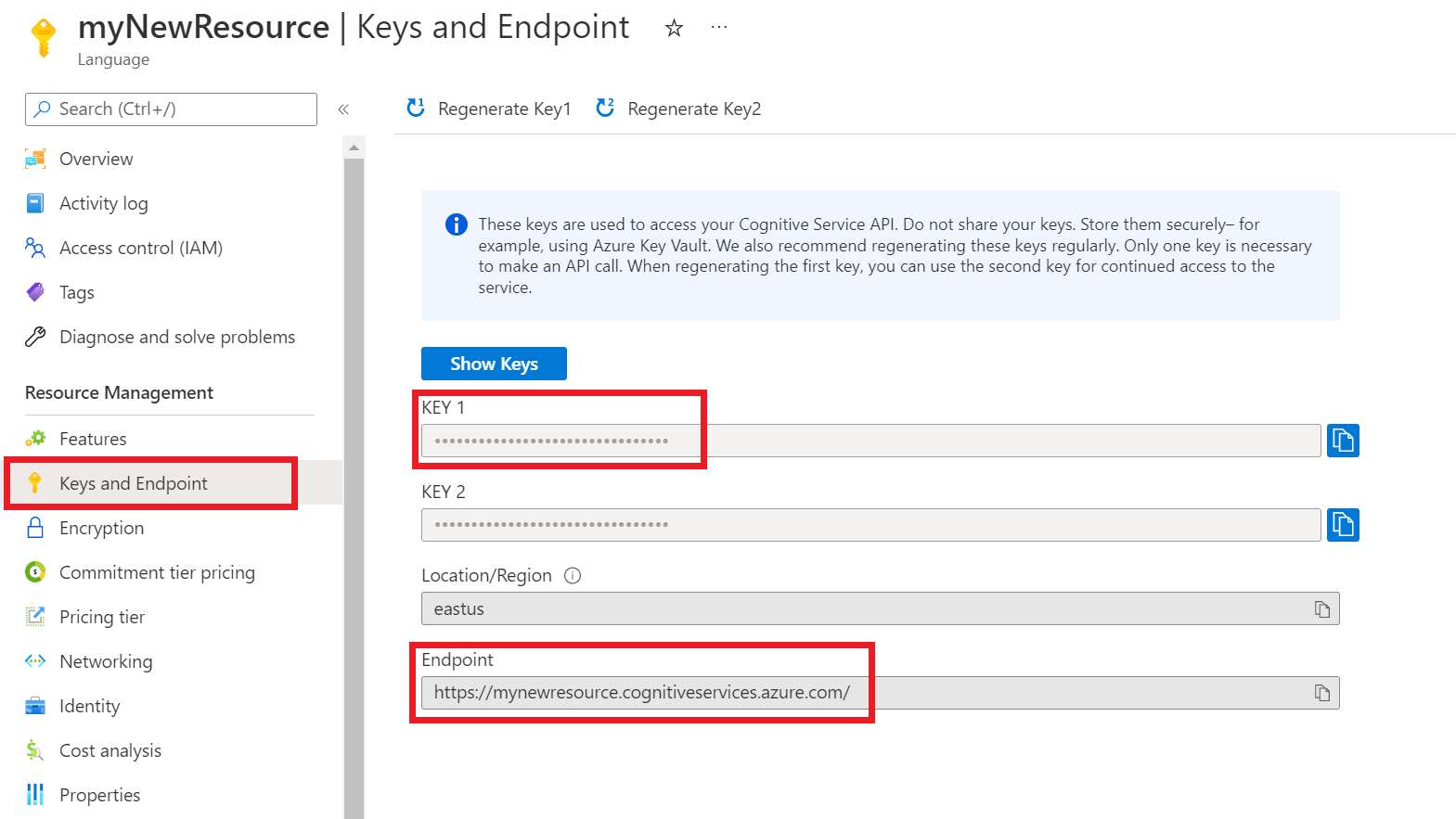
Récupération des clés et du point de terminaison de la ressource
Accédez à la page de présentation de votre ressource sur le Portail Azure.
Dans le menu de gauche, sélectionnez Clés et point de terminaison. Vous utilisez le point de terminaison et la clé pour les demandes d’API

Création d’un projet de flux de travail d’orchestration
Une fois que vous avez créé une ressource Language, créez un projet de workflow d’orchestration. Un projet est une zone de travail qui vous permet de créer des modèles ML personnalisés en fonction de vos données. Seuls les utilisateurs qui disposent d’un accès à la ressource de langue utilisée peuvent accéder à votre projet.
Pour ce guide de démarrage rapide, suivez le guide de démarrage rapide CLU pour créer un projet CLU à utiliser dans le workflow d’orchestration.
Envoyez une requête PATCH en utilisant l’URL, les en-têtes et le corps JSON suivants pour créer un projet.
URL de la demande
Utilisez l’URL suivante quand vous créez votre demande d’API. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{API-VERSION} |
Version de l’API que vous appelez. | 2023-04-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
body
Utilisez l’exemple JSON suivant comme corps.
{
"projectName": "{PROJECT-NAME}",
"language": "{LANGUAGE-CODE}",
"projectKind": "Orchestration",
"description": "Project description"
}
| Clé | Espace réservé | Valeur | Exemple |
|---|---|---|---|
projectName |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | EmailApp |
language |
{LANGUAGE-CODE} |
Chaîne spécifiant le code de langue des énoncés utilisés dans votre projet. Si votre projet est multilingue, choisissez le code de langue de la majorité des énoncés. | en-us |
Générer le schéma
Après avoir parcouru le guide de démarrage rapide CLU dans son intégralité et créé un projet d’orchestration, l’étape suivante consiste à ajouter des intentions.
Envoyez une requête POST en utilisant l’URL, les en-têtes et le corps JSON suivants pour importer votre projet.
URL de la demande
Utilisez l’URL suivante quand vous créez votre demande d’API. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:import?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{API-VERSION} |
Version de l’API que vous appelez. | 2023-04-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
body
Notes
Chaque intention doit être d’un type uniquement (CLU, LUIS ou qna)
Utilisez l’exemple JSON suivant comme corps.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "Orchestration",
"settings": {
"confidenceThreshold": 0
},
"projectName": "{PROJECT-NAME}",
"description": "Project description",
"language": "{LANGUAGE-CODE}"
},
"assets": {
"projectKind": "Orchestration",
"intents": [
{
"category": "string",
"orchestration": {
"kind": "luis",
"luisOrchestration": {
"appId": "00001111-aaaa-2222-bbbb-3333cccc4444",
"appVersion": "string",
"slotName": "string"
},
"cluOrchestration": {
"projectName": "string",
"deploymentName": "string"
},
"qnaOrchestration": {
"projectName": "string"
}
}
}
],
"utterances": [
{
"text": "Trying orchestration",
"language": "{LANGUAGE-CODE}",
"intent": "string"
}
]
}
}
| Clé | Espace réservé | Valeur | Exemple |
|---|---|---|---|
api-version |
{API-VERSION} |
Version de l’API que vous appelez. La version utilisée ici doit être la même version d’API dans l’URL. | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | EmailApp |
language |
{LANGUAGE-CODE} |
Chaîne spécifiant le code de langue des énoncés utilisés dans votre projet. Si votre projet est multilingue, choisissez le code de langue de la majorité des énoncés. | en-us |
Entraîner votre modèle
Pour entraîner un modèle, vous devez démarrer un travail d’entraînement. La sortie d’un travail d’entraînement réussi est votre modèle formé.
Créez une requête POST en utilisant l’URL, les en-têtes et le corps JSON suivants pour envoyer un travail d’apprentissage.
URL de la demande
Utilisez l’URL suivante quand vous créez votre demande d’API. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | EmailApp |
{API-VERSION} |
Version de l’API que vous appelez. | 2023-04-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Corps de la demande
Utilisez l’objet suivant dans votre demande. Le modèle est nommé MyModel une fois l’apprentissage effectué.
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "standard",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| Clé | Espace réservé | Valeur | Exemple |
|---|---|---|---|
modelLabel |
{MODEL-NAME} |
Nom de votre modèle. | Model1 |
trainingMode |
standard |
Mode d'apprentissage. Un seul mode pour l’entraînement est disponible dans l’orchestration, qui est standard. |
standard |
trainingConfigVersion |
{CONFIG-VERSION} |
Version du modèle de configuration de formation. Par défaut, la dernière version du modèle est utilisée. | 2022-05-01 |
kind |
percentage |
Méthodes de fractionnement. Les valeurs possibles sont percentage ou manual. Pour plus d’informations, consultez Comment entraîner un modèle. |
percentage |
trainingSplitPercentage |
80 |
Pourcentage de vos données étiquetées à inclure dans le jeu d’apprentissage. La valeur recommandée est 80. |
80 |
testingSplitPercentage |
20 |
Pourcentage de vos données étiquetées à inclure dans le jeu de test. La valeur recommandée est 20. |
20 |
Notes
Les trainingSplitPercentage et testingSplitPercentage sont nécessaires uniquement si Kind est défini sur percentage. La somme des deux pourcentages doit être égale à 100.
Une fois que vous avez envoyé votre demande d’API, vous recevez une réponse 202 indiquant la réussite. Dans les en-têtes de réponse, extrayez la valeur operation-location. Elle est au format suivant :
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
Vous pouvez utiliser cette URL pour obtenir l’état du travail d’apprentissage.
Obtenir l’état de l’entraînement
La formation peut prendre entre 10 et 30 minutes. Vous pouvez utiliser la requête suivante pour continuer à interroger l’état du travail d’apprentissage jusqu’à ce qu’il soit effectué avec succès.
Utilisez la requête GET suivante pour obtenir l’état de progression du processus d’apprentissage de votre modèle. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
URL de la demande
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{YOUR-ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | EmailApp |
{JOB-ID} |
ID de localisation de l’état d’entraînement de votre modèle. Il s’agit de la valeur d’en-tête location que vous avez reçue lors de l’envoi de votre travail de formation. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Version de l’API que vous appelez. | 2023-04-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Corps de la réponse
Une fois que vous avez envoyé la demande, vous recevez la réponse suivante. Continuez à interroger ce point de terminaison jusqu’à ce que le paramètre status passe à « réussi ».
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxxx-xxxxx-xxxxxx-xxxxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| Clé | Valeur | Exemple |
|---|---|---|
modelLabel |
Le nom du modèle | Model1 |
trainingConfigVersion |
Version de configuration de formation. Par défaut, la dernière version est utilisée. | 2022-05-01 |
startDateTime |
Le moment où la formation a commencé | 2022-04-14T10:23:04.2598544Z |
status |
L’état du travail de formation | running |
estimatedEndDateTime |
Durée estimée pour l’achèvement du travail de formation | 2022-04-14T10:29:38.2598544Z |
jobId |
Votre ID de travail de formation | xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
Date et heure de création d’un travail de formation | 2022-04-14T10:22:42Z |
lastUpdatedDateTime |
Date et heure de la dernière mise à jour du travail de formation | 2022-04-14T10:23:45Z |
expirationDateTime |
Date et heure d’expiration du travail de formation | 2022-04-14T10:22:42Z |
Déployer votre modèle
En général, après avoir formé un modèle, vous examinez les détails de son évaluation. Dans ce guide de démarrage rapide, vous allez simplement déployer votre modèle et appeler l’API de prédiction pour interroger les résultats.
Envoyer un travail de déploiement
Créez une demande PUT en utilisant l’URL, les en-têtes et le corps JSON suivants pour commencer le déploiement d’un modèle de flux de travail d’orchestration.
URL de la demande
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{DEPLOYMENT-NAME} |
Le nom de votre déploiement. Cette valeur respecte la casse. | staging |
{API-VERSION} |
Version de l’API que vous appelez. | 2023-04-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Corps de la demande
{
"trainedModelLabel": "{MODEL-NAME}",
}
| Clé | Espace réservé | Valeur | Exemple |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Nom du modèle qui est attribué à votre déploiement. Vous pouvez uniquement attribuer des modèles entraînés avec succès. Cette valeur respecte la casse. | myModel |
Une fois que vous avez envoyé votre demande d’API, vous recevez une réponse 202 indiquant la réussite. Dans les en-têtes de réponse, extrayez la valeur operation-location. Elle est au format suivant :
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
Vous pouvez utiliser cette URL pour obtenir l’état du travail de déploiement.
Obtenir l’état du travail de déploiement
Utilisez la requête GET suivante pour obtenir l’état de votre travail de déploiement. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
URL de la demande
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{DEPLOYMENT-NAME} |
Le nom de votre déploiement. Cette valeur respecte la casse. | staging |
{JOB-ID} |
ID de localisation de l’état d’entraînement de votre modèle. Il s’agit de la valeur d’en-tête location que vous avez reçue de l’API en réponse à votre demande de déploiement de modèle. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Version de l’API que vous appelez. | 2023-04-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Corps de la réponse
Une fois que vous avez envoyé la demande, vous recevez la réponse suivante. Continuez à interroger ce point de terminaison jusqu’à ce que le paramètre status passe à « réussi ».
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Interrogation du modèle
Une fois votre modèle déployé, vous pouvez commencer à l’utiliser pour faire des prédictions via l’API de prédiction.
Une fois le déploiement terminé, vous pouvez commencer à interroger votre modèle déployé pour effectuer des prédictions.
Créez une demande POST en utilisant l’URL, les en-têtes et le corps JSON suivants pour commencer le test d’un modèle de flux de travail d’orchestration.
URL de la demande
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
La version de l’API que vous appelez. | 2023-04-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Corps de la demande
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"text": "Text1",
"participantId": "1",
"id": "1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"directTarget": "qnaProject",
"targetProjectParameters": {
"qnaProject": {
"targetProjectKind": "QuestionAnswering",
"callingOptions": {
"context": {
"previousUserQuery": "Meet Surface Pro 4",
"previousQnaId": 4
},
"top": 1,
"question": "App Service overview"
}
}
}
}
}
Corps de la réponse
Une fois que vous avez envoyé la demande, vous recevez la réponse suivante comme prédiction.
{
"kind": "ConversationResult",
"result": {
"query": "App Service overview",
"prediction": {
"projectKind": "Orchestration",
"topIntent": "qnaTargetApp",
"intents": {
"qnaTargetApp": {
"targetProjectKind": "QuestionAnswering",
"confidenceScore": 1,
"result": {
"answers": [
{
"questions": [
"App Service overview"
],
"answer": "The compute resources you use are determined by the *App Service plan* that you run your apps on.",
"confidenceScore": 0.7384000000000001,
"id": 1,
"source": "https://learn.microsoft.com/azure/app-service/overview",
"metadata": {},
"dialog": {
"isContextOnly": false,
"prompts": []
}
}
]
}
}
}
}
}
}
Nettoyer les ressources
Une fois que vous n’avez plus besoin de votre projet, vous pouvez le supprimer à l’aide des API.
Créez une requête DELETE en utilisant l’URL, les en-têtes et le corps JSON suivants pour supprimer un projet de compréhension du langage courant.
URL de la demande
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{API-VERSION} |
Version de l’API que vous appelez. | 2023-04-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Une fois que vous avez envoyé votre requête API, vous recevez une réponse 202 indiquant la réussite, ce qui signifie que votre projet a été supprimé.