Fonctionnalités du module complémentaire Document Intelligence
Article
Ce contenu s’applique à :v4.0 (GA) | Versions précédentes :v3.1 (GA) :::moniker-end
Ce contenu s’applique à :v3.1 (GA) | Dernière version :v4.0 (GA)
Remarque
Les fonctionnalités de module complémentaire sont disponibles dans tous les modèles, à l’exception du modèle Business carte.
Fonctionnalités
Intelligence documentaire prend en charge des fonctionnalités d’analyse plus sophistiquées et modulaires. Utilisez les fonctionnalités de modules complémentaires pour étendre les résultats afin d’inclure d’autres fonctionnalités extraites de vos documents. Certaines fonctionnalités de modules complémentaires entraînent un coût supplémentaire. Ces fonctionnalités facultatives peuvent être activées et désactivées selon le scénario d’extraction de documents. Pour activer une fonctionnalité, ajoutez le nom de fonctionnalité associé à la propriété features de la chaîne de requête. Vous pouvez activer plusieurs fonctionnalités du module complémentaire à la demande, en fournissant une liste séparée par des virgules de fonctionnalités. Les fonctionnalités du module complémentaire suivantes sont disponibles pour 2023-07-31 (GA) et les versions ultérieures.
Toutes les fonctionnalités de module complémentaire ne sont pas prises en charge par tous les modèles. Pour plus d’informations, consultezExtraction de données de modèle.
Les fonctionnalités de module complémentaire ne sont actuellement pas prises en charge pour les types de fichiers Microsoft Office.
✱ Module complémentaire : les champs de requête sont facturés différemment des autres fonctionnalités du module complémentaire. Pour en savoir plus, voir les tarifs. ** Module complémentaire - PDF pouvant faire l’objet d’une recherche est disponible uniquement avec le modèle de lecture en tant que fonctionnalité de module complémentaire.
Formats de fichiers pris en charge
PDF
Images : JPEG/JPG, PNG, BMP, TIFF, HEIF
✱ Les fichiers Microsoft Office ne sont pas pris en charge actuellement.
Extraction à haute résolution
La tâche de reconnaître de petits textes dans des documents de grande taille, comme les dessins d’ingénierie, est une difficulté. Le texte est parfois mélangé à d’autres éléments graphiques, avec différentes polices, tailles et orientations. De surcroît, le texte peut être scindé en parties distinctes ou relié à d’autres symboles. Document Intelligence prend désormais en charge l’extraction de contenu de ces types de documents avec la fonctionnalité ocr.highResolution. Vous obtenez une extraction de contenu de meilleure qualité à partir de documents A1/A2/A3 en activant cette fonctionnalité de module complémentaire.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.OCR_HIGH_RESOLUTION], # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_with_highres]
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
# Analyze a document at a URL:
url = "(https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.OCR_HIGH_RESOLUTION] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_with_highres]
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
La fonctionnalité ocr.formula extrait toutes les formules identifiées, dont les équations mathématiques, dans la collection formulas comme objet de niveau supérieur sous content. Dans content, les formules détectées sont représentées comme :formula:. Chaque entrée de cette collection représente une formule qui inclut le type de formule en tant que inline ou display et sa représentation LaTeX comme value avec ses coordonnées polygon. Les formules apparaissent en premier lieu à la fin de chaque page.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.FORMULAS], # Specify which add-on capabilities to enable
)
result: AnalyzeResult = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
if page.formulas:
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
# To learn the detailed concept of "polygon" in the following content, visit: https://aka.ms/bounding-region
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.FORMULAS] # Specify which add-on capabilities to enable
)
result = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
"content": ":formula:",
"pages": [
{
"pageNumber": 1,
"formulas": [
{
"kind": "inline",
"value": "\\frac { \\partial a } { \\partial b }",
"polygon": [...],
"span": {...},
"confidence": 0.99
},
{
"kind": "display",
"value": "y = a \\times b + a \\times c",
"polygon": [...],
"span": {...},
"confidence": 0.99
}
]
}
]
Extraction des propriétés de la police
La fonctionnalité ocr.font extrait toutes les propriétés de police de caractère récupéré de la collection styles comme objet de niveau supérieur sous content. Chaque objet de style indique une propriété de police unique, l’étendue du texte à laquelle il s’applique et son score de confiance correspondant. La propriété de style existante est étendue avec d’autres propriétés de police, telles que similarFontFamily pour la police de caractère, fontStyle pour les styles comme italique et normal, fontWeight pour gras ou normal, color pour la couleur du texte et backgroundColor pour la couleur du cadre englobant le texte.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
return
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
La capacité ocr.barcode extrait tous les codes-barres identifiés dans la collection barcodes en tant qu’objet de niveau supérieur sous content. Dans content, les code-barres détectés sont représentés sous la forme :barcode:. Chaque entrée de cette collection représente un code-barres et inclut le type de code-barres comme kind et le contenu du code-barres incorporé comme value, ainsi que ses coordonnées polygon. Les code-barres apparaissent en premier lieu à la fin de chaque page. Le confidence est codé en dur pour 1.
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-barcodes.jpg?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.BARCODES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_barcodes]
# Iterate over extracted barcodes on each page.
for page in result.pages:
print(f"----Barcodes detected from page #{page.page_number}----")
print(f"Detected {len(page.barcodes)} barcodes:")
for barcode_idx, barcode in enumerate(page.barcodes):
print(f"- Barcode #{barcode_idx}: {barcode.value}")
print(f" Kind: {barcode.kind}")
print(f" Confidence: {barcode.confidence}")
print(f" Bounding regions: {format_polygon(barcode.polygon)}")
L’ajout de la fonctionnalité languages à la requête analyzeResult prédit le langage primaire détectée pour chaque ligne de texte, ainsi que la confidence dans la collection languages sous analyzeResult.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
if result.languages:
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(
f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'"
)
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'")
La fonctionnalité PDF pouvant faire l’objet d’une recherche vous permet de convertir un fichier PDF analogique, tel que des fichiers PDF d’images numérisées, en PDF avec du texte incorporé. Le texte incorporé permet une recherche en texte profond dans le contenu extrait du PDF en superposant les entités de texte détectées au-dessus des fichiers image.
Important
Actuellement, la fonctionnalité PDF pouvant faire l’objet d’une recherche n’est prise en charge que par le modèle OCR en lecture prebuilt-read. Lorsque vous utilisez cette fonctionnalité, définissez modelId comme prebuilt-read.
Le fichier PDF pouvant faire l’objet d’une recherche est inclus dans le modèle prebuilt-read 2024-11-30 (GA) sans coût d’utilisation pour la consommation PDF générale.
Utiliser PDF pouvant faire l’objet d’une recherche
Pour utiliser un fichier PDF pouvant faire l’objet d’une recherche, effectuez une requête POST à l’aide de l’opération Analyze et spécifiez le format de sortie comme pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Une fois l’opération Analyze terminée, effectuez une demande de GET pour récupérer les résultats de l’opération Analyze.
Une fois l’opération terminée, le fichier PDF peut être récupéré et téléchargé en tant que application/pdf. Cette opération permet le téléchargement direct de la forme de texte incorporée au format PDF au lieu de JSON encodé en Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Paires clé-valeur
Dans les versions antérieures de l’API, le modèle prebuilt-document extrayait des paires clé-valeur à partir de formulaires et de documents. Avec l’ajout de la fonctionnalité keyValuePairs à la disposition prédéfinie, le modèle de disposition produit désormais les mêmes résultats.
Les paires clé-valeur sont des portions spécifiques dans le document qui identifient une étiquette ou une clé, ainsi que la réponse ou la valeur associée. Dans un formulaire structuré, ces paires pourraient être l’étiquette et la valeur saisie par l’utilisateur pour ce champ. Dans un document non structuré, il pourrait s’agir de la date d’exécution d’un contrat en fonction du texte d’un paragraphe. Le modèle d’IA est formé à l’extraction des clés et des valeurs identifiables à partir d’une grande variété de types, de formats et de structures de documents.
Les clés peuvent également exister de manière isolée lorsque le modèle détecte qu’une clé existe sans valeur associée ou lors du traitement de champs facultatifs. Par exemple, le champ du second prénom peut être laissé vide sur un formulaire dans certains cas. Les paires clé-valeur sont des étendues de texte contenues dans le document. Si, dans certains documents, la même valeur est décrite de plusieurs manières, par exemple client/utilisateur, la clé associée est soit client, soit utilisateur (en fonction du contexte).
Les champs de requête sont une capacité du module complémentaire permettant d’étendre le schéma extrait de n’importe quel modèle prédéfini ou de définir un nom de clé spécifique lorsque le nom de la clé est variable. Pour utiliser des champs de requête, définissez les fonctionnalités sur queryFields et fournissez une liste (séparée par des virgules) des noms de champs dans la propriété queryFields.
Intelligence documentaire prend désormais en charge les extractions de champs de requête. Avec l’extraction de champ de requête, vous pouvez ajouter des champs au processus d’extraction au moyen d’une requête sans besoin de formation supplémentaire.
Utilisez des champs de requête lorsque vous devez étendre le schéma d’un modèle prédéfini ou personnalisé ou extraire quelques champs avec la sortie de la disposition.
Les champs de requête sont une fonctionnalité de module complémentaire Premium. Pour de meilleurs résultats, définissez les champs que vous souhaitez extraire en utilisant des noms de champs en casse mixte (camel) ou en casse Pascal pour les noms de champs à plusieurs mots.
Les champs de requêtes prennent en charge un maximum de 20 champs par requête. Si le document contient une valeur pour le champ, le champ et la valeur sont retournés.
Cette version comporte une nouvelle implémentation de la capacité des champs de requête, dont le prix est inférieur à celui de l’implémentation précédente et qui doit être validée.
Remarque
L’extraction de champs de requête Studio Intelligence documentaire est actuellement disponible avec des modèles prédéfinis et de disposition 2024-11-30 (GA) API with the exception of the modèles de taxe américaine (modèles W2, 1098 et 1099).
Extraction du champ de requête
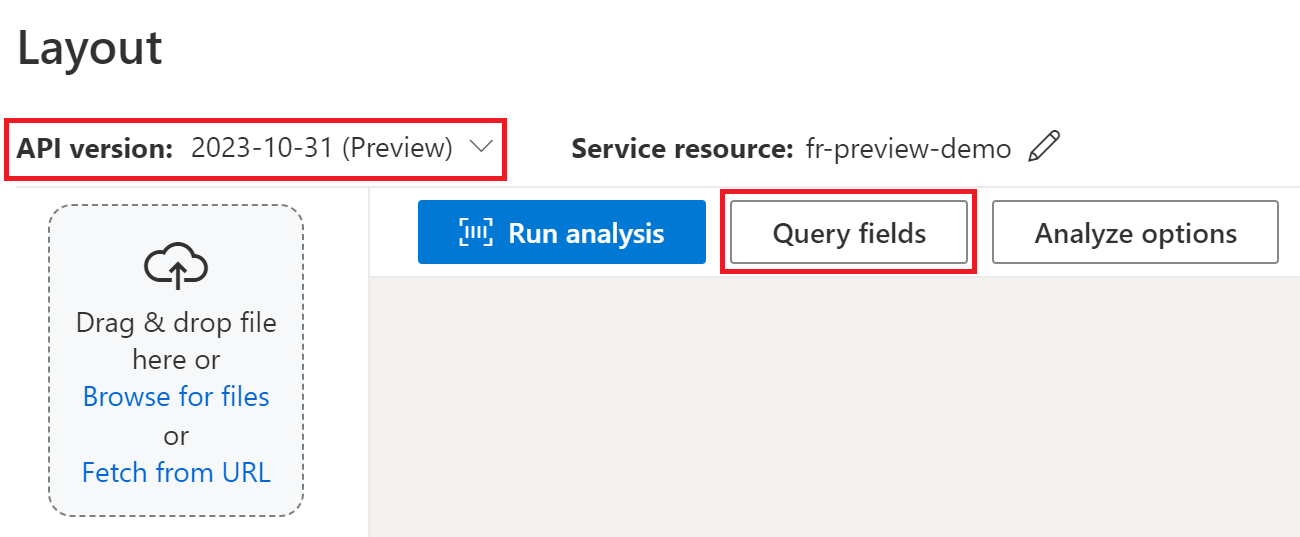
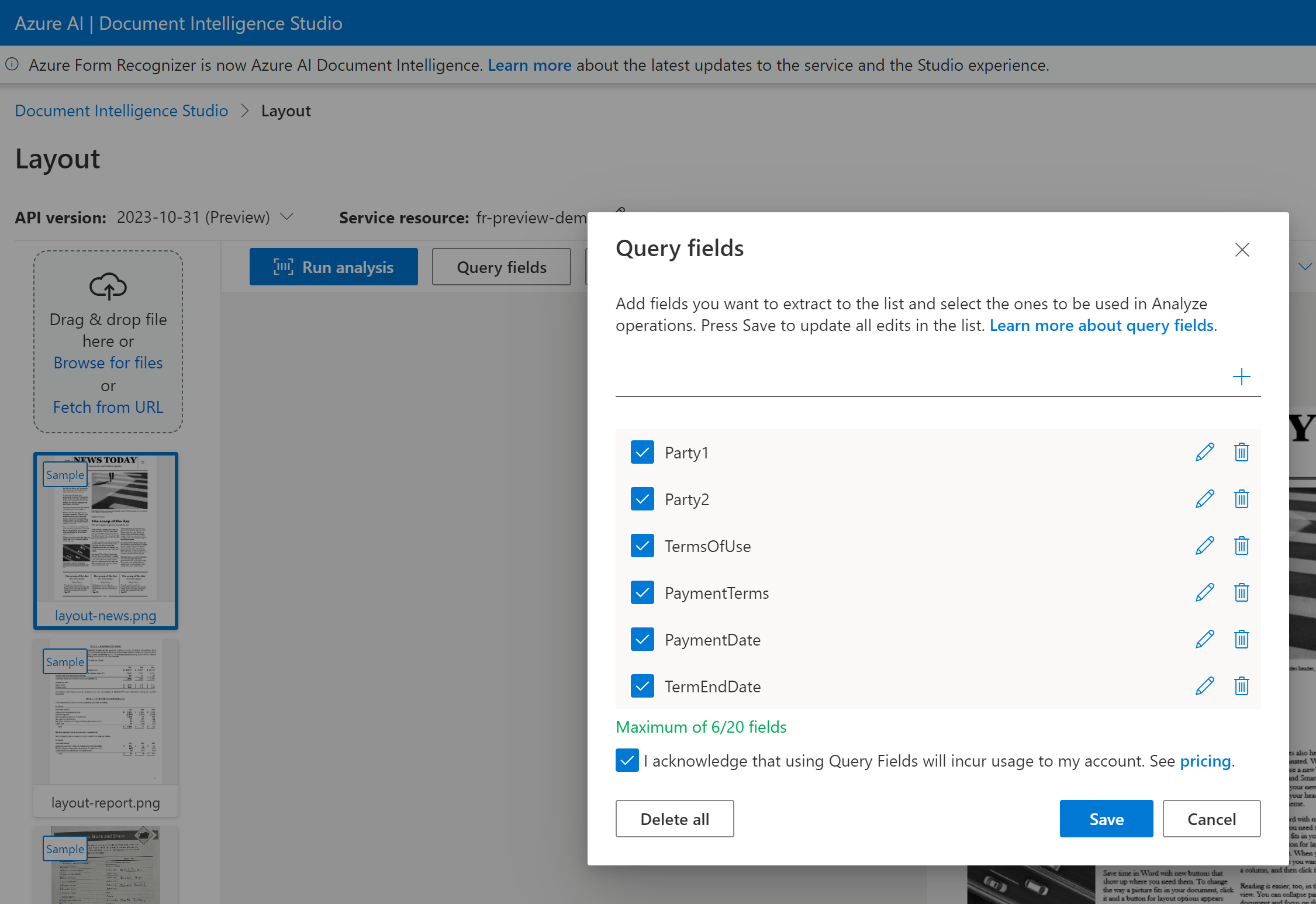
Pour l’extraction de champ de requête, indiquez les champs à extraire et Intelligence documentaire analyse le document en conséquence. Voici un exemple :
Vous pouvez transmettre une liste d’étiquettes de champ comme Party1, Party2, TermsOfUse, PaymentTerms, PaymentDate et TermEndDate dans le cadre de la requête analyze document.
Intelligence documentaire est en mesure d’analyser et d’extraire les données de champ et de retourner les valeurs dans une sortie JSON structurée.
Outre les champs de requête, la réponse inclut du texte, des tableaux, des marques de sélection et d’autres données pertinentes.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/invoice/simple-invoice.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.QUERY_FIELDS], # Specify which add-on capabilities to enable.
query_fields=["Address", "InvoiceNumber"], # Set the features and provide a comma-separated list of field names.
)
result: AnalyzeResult = poller.result()
print("Here are extra fields in result:\n")
if result.documents:
for doc in result.documents:
if doc.fields and doc.fields["Address"]:
print(f"Address: {doc.fields['Address'].value_string}")
if doc.fields and doc.fields["InvoiceNumber"]:
print(f"Invoice number: {doc.fields['InvoiceNumber'].value_string}")