Démarrage rapide : Utiliser une détection de fondement (préversion)
Ce guide vous montre comment utiliser l’API de détection du fondement. Cette fonctionnalité détecte et corrige automatiquement le texte non fondé en fonction des documents sources fournis, garantissant ainsi que le contenu généré est aligné sur des références factuelles ou désignées. Ci-dessous, nous explorons plusieurs scénarios courants pour vous aider à comprendre quand et comment appliquer ces fonctionnalités en vue d’optimiser les résultats.
Prérequis
- Un abonnement Azure - En créer un gratuitement
- Une fois que vous avez votre abonnement Azure, créez une ressource Content Safety dans le portail Azure pour obtenir votre clé et votre point de terminaison. Entrez un nom unique pour votre ressource, sélectionnez votre abonnement, puis sélectionnez un groupe de ressources, une région prise en charge et un niveau tarifaire pris en charge. Sélectionnez ensuite Créer.
- Le déploiement de la ressource prend quelques minutes. Une fois terminé, accédez à la nouvelle ressource. Dans le volet de gauche, sous Gestion des ressources, sélectionnez Clés d’API et points de terminaison. Copiez une des valeurs de clé et le point de terminaison de l’abonnement dans un emplacement temporaire pour les utiliser par la suite.
- (Facultatif) Si vous voulez utiliser la fonctionnalité de raisonnement, créez une ressource Azure OpenAI Service avec un modèle GPT déployé.
- cURL ou Python installé.
Vérifier le fondement sans raisonnement
Dans un cas simple sans la fonctionnalité de raisonnement, l’API de détection de fondement classifie l’absence de fondement du contenu envoyé comme true ou false.
Cette section décrit en détail un exemple de demande avec cURL. Collez la commande ci-dessous dans un éditeur de texte et effectuez les modifications suivantes :
Remplacez
<endpoint>par l’URL de point de terminaison associée à votre ressource.Remplacez
<your_subscription_key>par l’une des clés de votre ressource.Si vous le souhaitez, remplacez les champs
"query"ou"text"dans le corps par votre propre texte à analyser.curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \ --header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \ --header 'Content-Type: application/json' \ --data-raw '{ "domain": "Generic", "task": "QnA", "qna": { "query": "How much does she currently get paid per hour at the bank?" }, "text": "12/hour", "groundingSources": [ "I'm 21 years old and I need to make a decision about the next two years of my life. Within a week. I currently work for a bank that requires strict sales goals to meet. IF they aren't met three times (three months) you're canned. They pay me 10/hour and it's not unheard of to get a raise in 6ish months. The issue is, **I'm not a salesperson**. That's not my personality. I'm amazing at customer service, I have the most positive customer service \"reports\" done about me in the short time I've worked here. A coworker asked \"do you ask for people to fill these out? you have a ton\". That being said, I have a job opportunity at Chase Bank as a part time teller. What makes this decision so hard is that at my current job, I get 40 hours and Chase could only offer me 20 hours/week. Drive time to my current job is also 21 miles **one way** while Chase is literally 1.8 miles from my house, allowing me to go home for lunch. I do have an apartment and an awesome roommate that I know wont be late on his portion of rent, so paying bills with 20hours a week isn't the issue. It's the spending money and being broke all the time.\n\nI previously worked at Wal-Mart and took home just about 400 dollars every other week. So I know i can survive on this income. I just don't know whether I should go for Chase as I could definitely see myself having a career there. I'm a math major likely going to become an actuary, so Chase could provide excellent opportunities for me **eventually**." ], "reasoning": false }'
Ouvrez une invite de commandes et exécutez la commande cURL.
Pour tester une tâche de résumé au lieu d’une tâche de réponse aux questions (QnA), utilisez l’exemple de corps JSON suivant :
{
"domain": "Medical",
"task": "Summarization",
"text": "Ms Johnson has been in the hospital after experiencing a stroke.",
"groundingSources": [
"Our patient, Ms. Johnson, presented with persistent fatigue, unexplained weight loss, and frequent night sweats. After a series of tests, she was diagnosed with Hodgkin’s lymphoma, a type of cancer that affects the lymphatic system. The diagnosis was confirmed through a lymph node biopsy revealing the presence of Reed-Sternberg cells, a characteristic of this disease. She was further staged using PET-CT scans. Her treatment plan includes chemotherapy and possibly radiation therapy, depending on her response to treatment. The medical team remains optimistic about her prognosis given the high cure rate of Hodgkin’s lymphoma."
],
"reasoning": false
}
Les champs ci-dessous doivent être inclus dans l’URL :
| Nom | Obligatoire | Description | Type |
|---|---|---|---|
| API Version | Requis | Il s’agit de la version d’API à utiliser. La version actuelle est : api-version=2024-09-15-preview. Exemple : <endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview |
String |
Les paramètres dans le corps de la requête sont définis dans ce tableau :
| Nom | Description | Type |
|---|---|---|
| domain | (Facultatif) MEDICAL ou GENERIC. Valeur par défaut : GENERIC. |
Enum |
| tâche | (Facultatif) Type de tâche : QnA, Summarization. Valeur par défaut : Summarization. |
Enum |
| qna | (Facultatif) Contient les données QnA quand le type de tâche est QnA. |
Chaîne |
- query |
(Facultatif) Représente la question dans une tâche QnA. Limite de caractères : 7 500. | Chaîne |
| texte | (Obligatoire) Texte de sortie du LLM à vérifier. Limite de caractères : 7 500. | Chaîne |
| groundingSources | (Obligatoire) Utilise un tableau de sources de fondement pour valider le texte généré par l’IA. Consultez les exigences d’entrée pour connaître les limites. | Tableau de chaîne |
| raisonnement | (Facultatif) Spécifie s’il faut utiliser la fonctionnalité de raisonnement. La valeur par défaut est false. Si true, vous devez apporter vos propres ressources Azure OpenAI GPT4o (version 0513, 0806) pour fournir une explication. Attention : l’utilisation du raisonnement augmente le temps de traitement. |
Boolean |
Interpréter la réponse de l’API
Après avoir envoyé votre demande, vous recevez une réponse JSON reflétant l’analyse de fondement effectuée. La sortie type ressemble à :
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "12/hour."
}
]
}
Les objets JSON dans la sortie sont définis ici :
| Nom | Description | Type |
|---|---|---|
| ungroundedDetected | Indique si le texte n’est pas fondé. | Boolean |
| ungroundedPercentage | Spécifie la proportion du texte identifié comme non fondé, exprimé par un nombre compris entre 0 et 1, où 0 indique qu’il n’y a pas de contenu non fondé et 1 indique un contenu pas du tout fondé. | Float |
| ungroundedDetails | Fournit des insights sur le contenu non fondé avec des exemples et des pourcentages spécifiques. | Tableau |
-text |
Texte spécifique qui n’est pas fondé. | Chaîne |
Vérifier le fondement avec le raisonnement
L’API de détection de fondement offre la possibilité d’inclure le raisonnement dans la réponse de l’API. Quand le raisonnement est activé, la réponse inclut un champ "reasoning" qui détaille des instances et des explications spécifiques pour le texte non fondé détecté.
Connecter votre propre déploiement GPT
Conseil
Nous prenons uniquement en charge les ressources **Azure OpenAI GPT4o (version 0513, 0806) ** et ne prenons pas en charge d’autres types de GPT. Vous avez la possibilité de déployer vos ressources Azure OpenAI GPT4o (version 0513, 0806) dans n’importe quelle région. Cependant, pour réduire la latence potentielle et éviter les problèmes de confidentialité et de risque pour les données liés aux frontières géographiques, nous vous recommandons de les placer dans la même région que vos ressources de sécurité du contenu. Pour obtenir des informations complètes sur la confidentialité des données, reportez-vous aux instructions relatives aux données, à la confidentialité et à la sécurité pour Azure OpenAI Service et à Données, confidentialité et sécurité pour Azure AI Sécurité du Contenu.
Afin d'utiliser votre ressource Azure OpenAI GPT4o (version 0513, 0806) pour activer la fonctionnalité de raisonnement, utilisez l'identité gérée pour permettre à votre ressource Content Safety d'accéder à la ressource Azure OpenAI :
Activez une identité managée pour Azure AI Sécurité du Contenu.
Accédez à votre instance Azure AI Sécurité du Contenu dans le portail Azure. Recherchez la section Identité sous la catégorie Paramètres. Activez l’identité managée affectée par le système. Cette action accorde à votre instance Azure AI Sécurité du Contenu une identité qui peut être reconnue et utilisée dans Azure pour accéder à d’autres ressources.
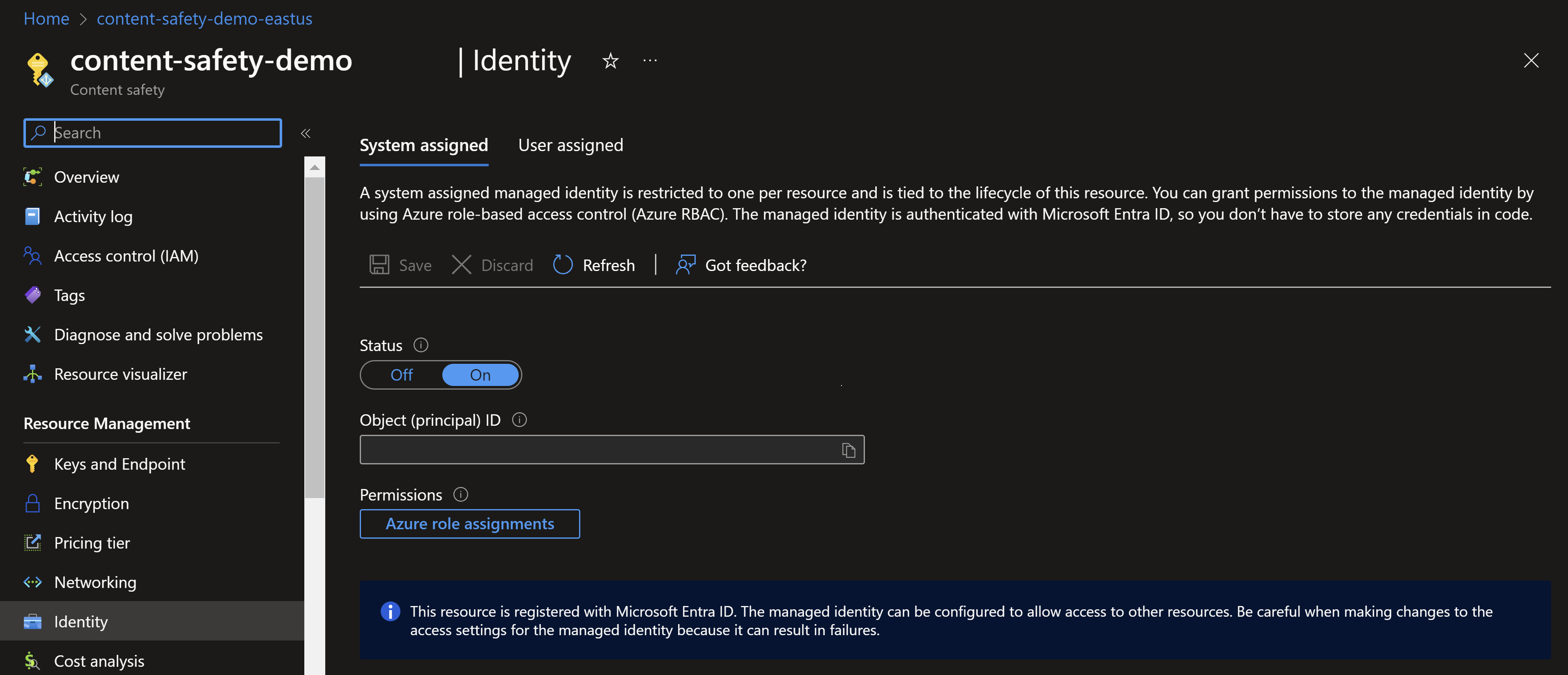
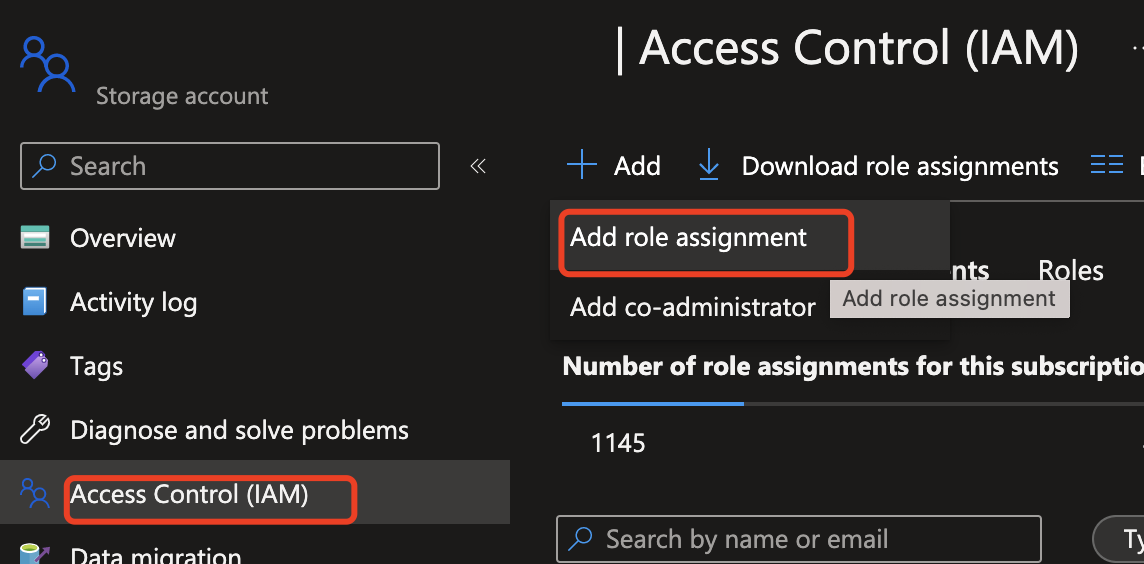
Attribuez un rôle à l’identité managée.
Accédez à votre instance Azure OpenAI, sélectionnez Ajouter une attribution de rôle pour démarrer le processus d’attribution d’un rôle Azure OpenAI à l’identité Azure AI Sécurité du Contenu.
Choisissez le rôle Utilisateur ou Contributeur.
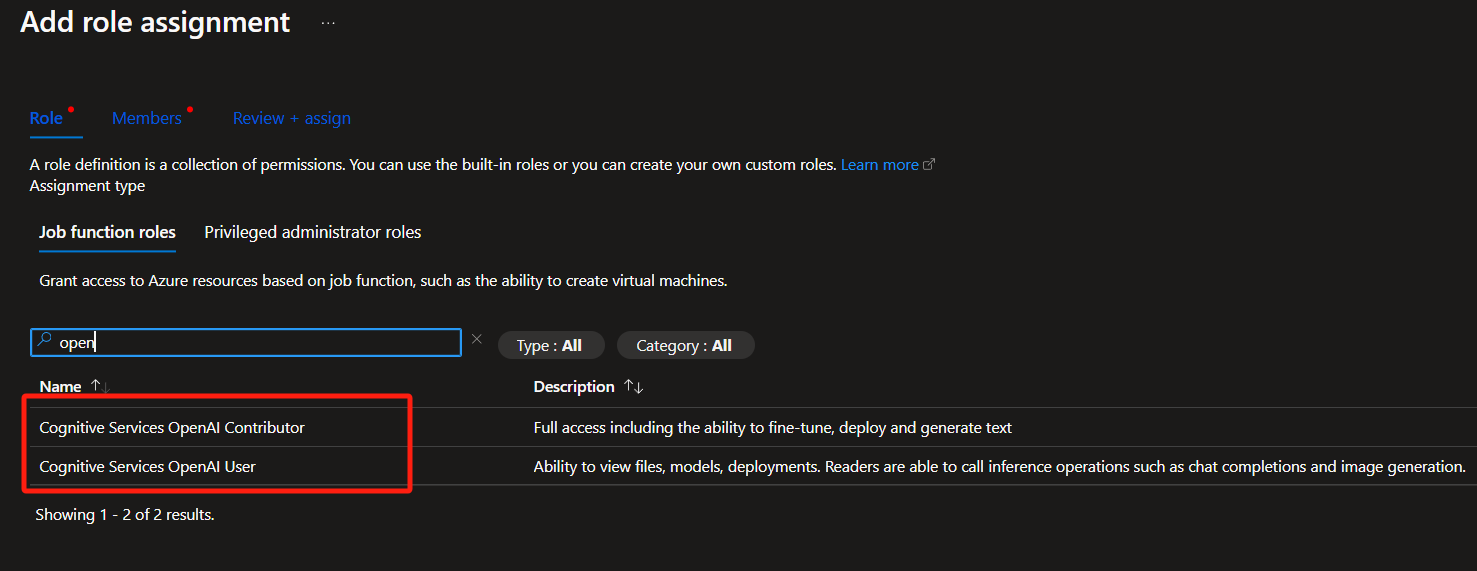


Effectuer la demande d’API
Dans votre demande à l’API de détection de fondement, définissez le paramètre de corps "reasoning" sur true et fournissez les autres paramètres nécessaires :
{
"domain": "Medical",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"reasoning": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}
Cette section décrit en détail un exemple de demande avec cURL. Collez la commande ci-dessous dans un éditeur de texte et effectuez les modifications suivantes :
Remplacez
<endpoint>par l’URL de point de terminaison associée à votre ressource Azure AI Sécurité du Contenu.Remplacez
<your_subscription_key>par l’une des clés de votre ressource.Remplacez
<your_OpenAI_endpoint>par l’URL de point de terminaison associée à votre ressource Azure OpenAI.Remplacez
<your_deployment_name>par le nom de votre déploiement Azure OpenAI.Si vous le souhaitez, remplacez les champs
"query"ou"text"dans le corps par votre propre texte à analyser.curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \ --header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \ --header 'Content-Type: application/json' \ --data-raw '{ "domain": "Generic", "task": "QnA", "qna": { "query": "How much does she currently get paid per hour at the bank?" }, "text": "12/hour", "groundingSources": [ "I'm 21 years old and I need to make a decision about the next two years of my life. Within a week. I currently work for a bank that requires strict sales goals to meet. If they aren't met three times (three months) you're canned. They pay me 10/hour and it's not unheard of to get a raise in 6ish months. The issue is, **I'm not a salesperson**. That's not my personality. I'm amazing at customer service, I have the most positive customer service \"reports\" done about me in the short time I've worked here. A coworker asked \"do you ask for people to fill these out? you have a ton\". That being said, I have a job opportunity at Chase Bank as a part time teller. What makes this decision so hard is that at my current job, I get 40 hours and Chase could only offer me 20 hours/week. Drive time to my current job is also 21 miles **one way** while Chase is literally 1.8 miles from my house, allowing me to go home for lunch. I do have an apartment and an awesome roommate that I know wont be late on his portion of rent, so paying bills with 20hours a week isn't the issue. It's the spending money and being broke all the time.\n\nI previously worked at Wal-Mart and took home just about 400 dollars every other week. So I know i can survive on this income. I just don't know whether I should go for Chase as I could definitely see myself having a career there. I'm a math major likely going to become an actuary, so Chase could provide excellent opportunities for me **eventually**." ], "reasoning": true, "llmResource": { "resourceType": "AzureOpenAI", "azureOpenAIEndpoint": "<your_OpenAI_endpoint>", "azureOpenAIDeploymentName": "<your_deployment_name>" }'Ouvrez une invite de commandes et exécutez la commande cURL.
Les paramètres dans le corps de la requête sont définis dans ce tableau :
| Nom | Description | Type |
|---|---|---|
| domain | (Facultatif) MEDICAL ou GENERIC. Valeur par défaut : GENERIC. |
Enum |
| tâche | (Facultatif) Type de tâche : QnA, Summarization. Valeur par défaut : Summarization. |
Enum |
| qna | (Facultatif) Contient les données QnA quand le type de tâche est QnA. |
Chaîne |
- query |
(Facultatif) Représente la question dans une tâche QnA. Limite de caractères : 7 500. | Chaîne |
| texte | (Obligatoire) Texte de sortie du LLM à vérifier. Limite de caractères : 7 500. | Chaîne |
| groundingSources | (Obligatoire) Utilise un tableau de sources de fondement pour valider le texte généré par l’IA. Consultez les exigences d’entrée pour connaître les limites, | Tableau de chaîne |
| raisonnement | (Facultatif) Défini sur true, le service utilise des ressources Azure OpenAI pour fournir une explication. Attention : l’utilisation du raisonnement augmente le temps de traitement et entraîne des frais supplémentaires. |
Boolean |
| llmResource | (Obligatoire) Si vous souhaitez utiliser votre propre ressource Azure OpenAI GPT4o (version 0513, 0806) pour activer le raisonnement, ajoutez ce champ et incluez les sous-champs des ressources utilisées. | Chaîne |
- resourceType |
Spécifie le type de ressource utilisé. Actuellement, autorise uniquement AzureOpenAI. Nous prenons uniquement en charge les ressources Azure OpenAI GPT4o (version 0513, 0806) et ne prenons pas en charge d’autres types de GPT. |
Enum |
- azureOpenAIEndpoint |
URL de votre point de terminaison pour le service Azure OpenAI. | Chaîne |
- azureOpenAIDeploymentName |
Nom du déploiement GPT spécifique à utiliser. | Chaîne |
Interpréter la réponse de l’API
Après avoir envoyé votre demande, vous recevez une réponse JSON reflétant l’analyse de fondement effectuée. La sortie type ressemble à :
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "12/hour.",
"offset": {
"utf8": 0,
"utf16": 0,
"codePoint": 0
},
"length": {
"utf8": 8,
"utf16": 8,
"codePoint": 8
},
"reason": "None. The premise mentions a pay of \"10/hour\" but does not mention \"12/hour.\" It's neutral. "
}
]
}
Les objets JSON dans la sortie sont définis ici :
| Nom | Description | Type |
|---|---|---|
| ungroundedDetected | Indique si le texte n’est pas fondé. | Boolean |
| ungroundedPercentage | Spécifie la proportion du texte identifié comme non fondé, exprimé par un nombre compris entre 0 et 1, où 0 indique qu’il n’y a pas de contenu non fondé et 1 indique un contenu pas du tout fondé. | Float |
| ungroundedDetails | Fournit des insights sur le contenu non fondé avec des exemples et des pourcentages spécifiques. | Tableau |
-text |
Texte spécifique qui n’est pas fondé. | Chaîne |
-offset |
Objet décrivant la position du texte non fondé dans différents encodages. | Chaîne |
- offset > utf8 |
Position de décalage du texte non fondé en encodage UTF-8. | Entier |
- offset > utf16 |
Position de décalage du texte non fondé en encodage UTF-16. | Entier |
- offset > codePoint |
Position de décalage du texte non fondé en termes de points de code Unicode. | Entier |
-length |
Objet décrivant la longueur du texte non fondé dans différents encodages. (utf8, utf16, codePoint), similaire au décalage. | Object |
- length > utf8 |
Longueur du texte non fondé en encodage UTF-8. | Entier |
- length > utf16 |
Longueur du texte non fondé en encodage UTF-16. | Entier |
- length > codePoint |
Longueur du texte non fondé en termes de points de code Unicode. | Entier |
-reason |
Offre des explications pour la détection d’absence de fondement. | Chaîne |
Vérifier le fondement avec la fonctionnalité de correction
L’API de détection du fondement inclut une fonctionnalité de correction qui corrige automatiquement toute information non fondée détectée dans le texte en fonction des sources de fondement fournies. Lorsque la fonctionnalité de correction est activée, la réponse inclut un champ "correction Text" qui présente le texte corrigé, aligné sur les sources de fondement.
Connecter votre propre déploiement GPT
Conseil
Actuellement, la fonctionnalité de correction ne prend en charge que les ressources **Azure OpenAI GPT4o (version 0513, 0806) **. Pour minimiser la latence et respecter les instructions de confidentialité des données, nous vous recommandons de déployer vos ressources Azure OpenAI GPT4o (version 0513, 0806) dans la même région que vos ressources de sécurité du contenu. Pour plus d’informations sur la confidentialité des données, reportez-vous aux instructions relatives aux données, à la confidentialité et à la sécurité pour Azure OpenAI Service et à Données, confidentialité et sécurité pour Azure AI Sécurité du Contenu.
Pour utiliser votre ressource Azure OpenAI GPT4o (version 0513, 0806) pour activer la fonctionnalité de correction, utilisez l’identité gérée pour permettre à votre ressource Content Safety d’accéder à la ressource Azure OpenAI. Suivez les étapes de la section précédente pour configurer l’identité managée.
Effectuer la demande d’API
Dans votre requête à l’API de détection du fondement, définissez le paramètre de corps "correction" sur true et fournissez les autres paramètres nécessaires :
{
"domain": "Medical",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"correction": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}
Cette section illustre un exemple de requête à l’aide de cURL. Remplacez les espaces réservés selon les besoins :
- Remplacez
<endpoint>par l’URL de point de terminaison de votre ressource. - Remplacez
<your_subscription_key>par votre clé d’abonnement. - Si vous le souhaitez, remplacez le champ « text » par le texte à analyser.
curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \
--header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"domain": "Generic",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"correction": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}'
Les paramètres dans le corps de la requête sont définis dans ce tableau :
| Nom | Description | Type |
|---|---|---|
| domain | (Facultatif) MEDICAL ou GENERIC. Valeur par défaut : GENERIC. |
Enum |
| tâche | (Facultatif) Type de tâche : QnA, Summarization. Valeur par défaut : Summarization. |
Enum |
| qna | (Facultatif) Contient les données QnA quand le type de tâche est QnA. |
Chaîne |
- query |
(Facultatif) Représente la question dans une tâche QnA. Limite de caractères : 7 500. | Chaîne |
| texte | (Obligatoire) Texte de sortie du LLM à vérifier. Limite de caractères : 7 500. | Chaîne |
| groundingSources | (Obligatoire) Utilise un tableau de sources de fondement pour valider le texte généré par l’IA. Consultez les exigences d’entrée pour connaître les limites. | Tableau de chaînes |
| correction | (Facultatif) Si ce paramètre est défini sur true, le service utilise les ressources Azure OpenAI pour fournir le texte corrigé, garantissant ainsi la cohérence avec les sources de fondement. Attention : l’utilisation de la correction augmente le temps de traitement et entraîne des frais supplémentaires. |
Boolean |
| llmResource | (Obligatoire) Si vous souhaitez utiliser votre propre ressource Azure OpenAI GPT4o (version 0513, 0806) pour activer le raisonnement, ajoutez ce champ et incluez les sous-champs des ressources utilisées. | Chaîne |
- resourceType |
Spécifie le type de ressource utilisé. Actuellement, autorise uniquement AzureOpenAI. Nous prenons uniquement en charge les ressources Azure OpenAI GPT4o (version 0513, 0806) et ne prenons pas en charge d’autres types de GPT. |
Enum |
- azureOpenAIEndpoint |
URL de votre point de terminaison pour le service Azure OpenAI. | Chaîne |
- azureOpenAIDeploymentName |
Nom du déploiement GPT spécifique à utiliser. | Chaîne |
Interpréter la réponse de l’API
La réponse inclut un champ "correction Text" contenant le texte corrigé, garantissant ainsi la cohérence avec les sources de fondement fournies.
La fonctionnalité de correction détecte que Kevin n’est pas fondé, car il est en conflit avec la source de fondement Jane. L’API retourne le texte corrigé suivant : "The patient name is Jane."
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "The patient name is Kevin"
}
],
"correction Text": "The patient name is Jane"
}
Les objets JSON dans la sortie sont définis ici :
| Nom | Description | Type |
|---|---|---|
| ungroundedDetected | Indique si du contenu non fondé a été détecté. | Boolean |
| ungroundedPercentage | Proportion de contenu non fondé dans le texte. | Float |
| ungroundedDetails | Détails du contenu non fondé, y compris des segments de texte spécifiques. | Tableau |
-text |
Texte spécifique qui n’est pas fondé. | Chaîne |
-offset |
Objet décrivant la position du texte non fondé dans différents encodages. | Chaîne |
- offset > utf8 |
Position de décalage du texte non fondé en encodage UTF-8. | Entier |
- offset > utf16 |
Position de décalage du texte non fondé en encodage UTF-16. | Integer |
-length |
Objet décrivant la longueur du texte non fondé dans différents encodages. (utf8, utf16, codePoint), similaire au décalage. | Object |
- length > utf8 |
Longueur du texte non fondé en encodage UTF-8. | Entier |
- length > utf16 |
Longueur du texte non fondé en encodage UTF-16. | Entier |
- length > codePoint |
Longueur du texte non fondé en termes de points de code Unicode. | Integer |
-correction Text |
Texte corrigé, garantissant ainsi la cohérence avec les sources de fondement. | Chaîne |
Nettoyer les ressources
Si vous souhaitez nettoyer et supprimer un abonnement Azure AI services, vous pouvez supprimer la ressource ou le groupe de ressources. La suppression du groupe de ressources efface également les autres ressources qui y sont associées.
Contenu connexe
- Concepts de détection de fondement
- Combinez la détection de fondement avec d’autres fonctionnalités de sécurité LLM comme les boucliers d’invite.