Comment reconnaître les intentions avec des critères spéciaux de langage simples
Le Speech SDK Azure AI services possède une fonctionnalité intégrée afin d’offrir une reconnaissance de l’intention à l’aide des critères spéciaux de langage simple. Une intention est quelque chose que l’utilisateur souhaite faire : fermer une fenêtre, marquer une case à cocher, insérer du texte, etc.
Dans ce guide, vous utilisez le SDK Speech pour développer une application console C# qui dégage des intentions à partir des énoncés utilisateur obtenus par le microphone de votre appareil. Vous allez apprendre à effectuer les actions suivantes :
- Créer un projet Visual Studio faisant référence au package NuGet du kit SDK Speech
- Créer une configuration de reconnaissance vocale et obtenir un module de reconnaissance de l’intention
- Ajouter des intentions et des modèles via l’API du kit de développement logiciel (SDK) Speech
- Reconnaître la voix provenant d’un micro
- Utiliser la reconnaissance continue pilotée par événements, asynchrone
Quand utiliser des critères spéciaux
Utilisez une correspondance de modèle si :
- Vous êtes uniquement intéressé par la correspondance stricte avec ce qu’a dit l’utilisateur. Ces modèles correspondent de manière plus agressive qu’une compréhension du langage courant (CLU).
- Vous n’avez pas accès à un modèle CLU, mais vous souhaitez néanmoins des intentions.
Pour plus d’informations, consultez la vue d’ensemble des critères spéciaux.
Prérequis
Veillez à disposer des éléments suivants avant de commencer à suivre ce guide :
- Une ressource Azure AI Services ou une ressource Unified Speech
- Visual Studio 2019 (toute édition).
Modèles vocaux et simples
Les modèles simples sont une fonctionnalité du kit de développement logiciel (SDK) Speech et nécessitent une ressource de Azure AI services ou une ressource vocale unifiée.
Un modèle est une expression qui renferme une Entité. Une Entité est définie en encapsulant un mot entre guillemets. Cet exemple définit une Entité avec l’ID « floorName », qui respecte la casse :
Take me to the {floorName}
Tous les autres caractères spéciaux et la ponctuation sont ignorés.
Les intentions sont ajoutées à l’aide d’appels à l’API IntentRecognizer->AddIntent().
Création d’un projet
Créez un projet d’application console C# dans Visual Studio 2019 et installez le Kit de développement logiciel (SDK) Speech.
Commencer avec du code réutilisable
Nous allons ouvrir Program.cs et ajouter du code qui servira de squelette à notre projet.
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
static void Main(string[] args)
{
IntentPatternMatchingWithMicrophoneAsync().Wait();
}
private static async Task IntentPatternMatchingWithMicrophoneAsync()
{
var config = SpeechConfig.FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
}
}
}
Créer une configuration Speech
Avant de pouvoir initialiser un objet IntentRecognizer, vous devez créer une configuration qui utilise la clé et la localisation pour la ressource de prédiction de vos services Azure AI.
- Remplacez
"YOUR_SUBSCRIPTION_KEY"par la clé de prédiction de vos services Azure AI. - Remplacez
"YOUR_SUBSCRIPTION_REGION"par la région de ressource de vos services Azure AI.
Cet exemple utilise la méthode FromSubscription() pour générer la SpeechConfig. Pour obtenir la liste complète des méthodes disponibles, consultez la rubrique Classe SpeechConfig.
Initialiser IntentRecognizer
Créez maintenant un IntentRecognizer. Insérez ce code juste en dessous de votre configuration Speech.
using (var intentRecognizer = new IntentRecognizer(config))
{
}
Ajouter des intentions
Vous devez associer des modèles à IntentRecognizer en appelant AddIntent().
Nous allons ajouter 2 intentions avec le même ID pour changer d’étage et une autre intention avec un ID distinct pour ouvrir et fermer les portes.
Insérez ce code dans le bloc using :
intentRecognizer.AddIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer.AddIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer.AddIntent("{action} the door.", "OpenCloseDoor");
Notes
Il n’existe aucune limite quant au nombre d’entités que vous pouvez déclarer, mais elles seront faiblement mises en correspondance. Si vous ajoutez une expression telle que « {action} porte », elle correspondra à chaque fois qu’il y a du texte avant le mot « porte ». Les intentions sont évaluées en fonction du nombre de leurs entités. Si deux modèles correspondent, celui avec des entités plus définies est retourné.
Reconnaître une intention
À partir de l’objet IntentRecognizer, vous devez appeler la méthode RecognizeOnceAsync(). Cette méthode demande au service Speech de reconnaître la parole en une seule phrase et d’arrêter la reconnaissance vocale une fois que l’expression est identifiée. Pour faire simple, nous attendons la fin des prochains retours.
Insérez ce code sous vos intentions :
Console.WriteLine("Say something...");
var result = await intentRecognizer.RecognizeOnceAsync();
Afficher les résultats de la reconnaissance (ou les erreurs)
Lorsque le résultat de la reconnaissance est retourné par le service Speech, nous allons imprimer le résultat.
Insérez ce code en dessous de var result = await recognizer.RecognizeOnceAsync(); :
string floorName;
switch (result.Reason)
{
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text= {result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text= {result.Text}");
Console.WriteLine($" Intent Id= {result.IntentId}.");
var entities = result.Entities;
if (entities.TryGetValue("floorName", out floorName))
{
Console.WriteLine($" FloorName= {floorName}");
}
if (entities.TryGetValue("action", out floorName))
{
Console.WriteLine($" Action= {floorName}");
}
break;
case ResultReason.NoMatch:
{
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
var noMatch = NoMatchDetails.FromResult(result);
switch (noMatch.Reason)
{
case NoMatchReason.NotRecognized:
Console.WriteLine($"NOMATCH: Speech was detected, but not recognized.");
break;
case NoMatchReason.InitialSilenceTimeout:
Console.WriteLine($"NOMATCH: The start of the audio stream contains only silence, and the service timed out waiting for speech.");
break;
case NoMatchReason.InitialBabbleTimeout:
Console.WriteLine($"NOMATCH: The start of the audio stream contains only noise, and the service timed out waiting for speech.");
break;
case NoMatchReason.KeywordNotRecognized:
Console.WriteLine($"NOMATCH: Keyword not recognized");
break;
}
break;
}
case ResultReason.Canceled:
{
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?");
}
break;
}
default:
break;
}
Vérifier votre code
À ce stade, votre code doit ressembler à ceci :
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
static void Main(string[] args)
{
IntentPatternMatchingWithMicrophoneAsync().Wait();
}
private static async Task IntentPatternMatchingWithMicrophoneAsync()
{
var config = SpeechConfig.FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
using (var intentRecognizer = new IntentRecognizer(config))
{
intentRecognizer.AddIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer.AddIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer.AddIntent("{action} the door.", "OpenCloseDoor");
Console.WriteLine("Say something...");
var result = await intentRecognizer.RecognizeOnceAsync();
string floorName;
switch (result.Reason)
{
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text= {result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text= {result.Text}");
Console.WriteLine($" Intent Id= {result.IntentId}.");
var entities = result.Entities;
if (entities.TryGetValue("floorName", out floorName))
{
Console.WriteLine($" FloorName= {floorName}");
}
if (entities.TryGetValue("action", out floorName))
{
Console.WriteLine($" Action= {floorName}");
}
break;
case ResultReason.NoMatch:
{
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
var noMatch = NoMatchDetails.FromResult(result);
switch (noMatch.Reason)
{
case NoMatchReason.NotRecognized:
Console.WriteLine($"NOMATCH: Speech was detected, but not recognized.");
break;
case NoMatchReason.InitialSilenceTimeout:
Console.WriteLine($"NOMATCH: The start of the audio stream contains only silence, and the service timed out waiting for speech.");
break;
case NoMatchReason.InitialBabbleTimeout:
Console.WriteLine($"NOMATCH: The start of the audio stream contains only noise, and the service timed out waiting for speech.");
break;
case NoMatchReason.KeywordNotRecognized:
Console.WriteLine($"NOMATCH: Keyword not recognized");
break;
}
break;
}
case ResultReason.Canceled:
{
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?");
}
break;
}
default:
break;
}
}
}
}
}
Générer et exécuter votre application
Vous êtes maintenant prêt à créer votre application et à tester la reconnaissance vocale à l’aide du service de reconnaissance vocale.
- Compiler le code : à partir de la barre de menus de Visual Studio, choisissez Générer>Générer la solution.
- Démarrer votre application : dans la barre de menus, choisissez Déboguer>Démarrer le débogage, ou appuyez sur F5.
- Démarrer la reconnaissance : vous êtes invité à prononcer une phrase. La langue par défaut est l'anglais. Celle-ci est envoyée au service de reconnaissance vocale, transcrite sous forme de texte, puis affichée sur la console.
Par exemple, si vous dites « me faire passer à l’étage 7 », il doit s’agir de la sortie suivante :
Say something ...
RECOGNIZED: Text= Take me to floor 7.
Intent Id= ChangeFloors
FloorName= 7
Création d’un projet
Créez un projet d’application console C++ dans Visual Studio 2019 et installez le Kit de développement logiciel (SDK) Speech.
Commencer avec du code réutilisable
Nous allons ouvrir helloworld.cpp et ajouter du code qui servira de squelette à notre projet.
#include <iostream>
#include <speechapi_cxx.h>
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
int main()
{
std::cout << "Hello World!\n";
auto config = SpeechConfig::FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
}
Créer une configuration Speech
Avant de pouvoir initialiser un objet IntentRecognizer, vous devez créer une configuration qui utilise la clé et la localisation pour la ressource de prédiction de vos services Azure AI.
- Remplacez
"YOUR_SUBSCRIPTION_KEY"par la clé de prédiction de vos services Azure AI. - Remplacez
"YOUR_SUBSCRIPTION_REGION"par la région de ressource de vos services Azure AI.
Cet exemple utilise la méthode FromSubscription() pour générer la SpeechConfig. Pour obtenir la liste complète des méthodes disponibles, consultez la rubrique Classe SpeechConfig.
Initialiser IntentRecognizer
Créez maintenant un IntentRecognizer. Insérez ce code juste en dessous de votre configuration Speech.
auto intentRecognizer = IntentRecognizer::FromConfig(config);
Ajouter des intentions
Vous devez associer des modèles à IntentRecognizer en appelant AddIntent().
Nous allons ajouter 2 intentions avec le même ID pour changer d’étage et une autre intention avec un ID distinct pour ouvrir et fermer les portes.
intentRecognizer->AddIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer->AddIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer->AddIntent("{action} the door.", "OpenCloseDoor");
Notes
Il n’existe aucune limite quant au nombre d’entités que vous pouvez déclarer, mais elles seront faiblement mises en correspondance. Si vous ajoutez une expression telle que « {action} porte », elle correspondra à chaque fois qu’il y a du texte avant le mot « porte ». Les intentions sont évaluées en fonction du nombre de leurs entités. Si deux modèles correspondent, celui avec des entités plus définies est retourné.
Reconnaître une intention
À partir de l’objet IntentRecognizer, vous devez appeler la méthode RecognizeOnceAsync(). Cette méthode demande au service Speech de reconnaître la parole en une seule phrase et d’arrêter la reconnaissance vocale une fois que l’expression est identifiée. Pour faire simple, nous attendons la fin des prochains retours.
Insérez ce code sous vos intentions :
std::cout << "Say something ..." << std::endl;
auto result = intentRecognizer->RecognizeOnceAsync().get();
Afficher les résultats de la reconnaissance (ou les erreurs)
Lorsque le résultat de la reconnaissance est retourné par le service Speech, nous allons imprimer le résultat.
Insérez ce code en dessous de auto result = intentRecognizer->RecognizeOnceAsync().get(); :
switch (result->Reason)
{
case ResultReason::RecognizedSpeech:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << "NO INTENT RECOGNIZED!" << std::endl;
break;
case ResultReason::RecognizedIntent:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << " Intent Id = " << result->IntentId.c_str() << std::endl;
auto entities = result->GetEntities();
if (entities.find("floorName") != entities.end())
{
std::cout << " Floor name: = " << entities["floorName"].c_str() << std::endl;
}
if (entities.find("action") != entities.end())
{
std::cout << " Action: = " << entities["action"].c_str() << std::endl;
}
break;
case ResultReason::NoMatch:
{
auto noMatch = NoMatchDetails::FromResult(result);
switch (noMatch->Reason)
{
case NoMatchReason::NotRecognized:
std::cout << "NOMATCH: Speech was detected, but not recognized." << std::endl;
break;
case NoMatchReason::InitialSilenceTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only silence, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::InitialBabbleTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only noise, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::KeywordNotRecognized:
std::cout << "NOMATCH: Keyword not recognized" << std::endl;
break;
}
break;
}
case ResultReason::Canceled:
{
auto cancellation = CancellationDetails::FromResult(result);
if (!cancellation->ErrorDetails.empty())
{
std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails.c_str() << std::endl;
std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl;
}
}
default:
break;
}
Vérifier votre code
À ce stade, votre code doit ressembler à ceci :
#include <iostream>
#include <speechapi_cxx.h>
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
int main()
{
auto config = SpeechConfig::FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
auto intentRecognizer = IntentRecognizer::FromConfig(config);
intentRecognizer->AddIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer->AddIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer->AddIntent("{action} the door.", "OpenCloseDoor");
std::cout << "Say something ..." << std::endl;
auto result = intentRecognizer->RecognizeOnceAsync().get();
switch (result->Reason)
{
case ResultReason::RecognizedSpeech:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << "NO INTENT RECOGNIZED!" << std::endl;
break;
case ResultReason::RecognizedIntent:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << " Intent Id = " << result->IntentId.c_str() << std::endl;
auto entities = result->GetEntities();
if (entities.find("floorName") != entities.end())
{
std::cout << " Floor name: = " << entities["floorName"].c_str() << std::endl;
}
if (entities.find("action") != entities.end())
{
std::cout << " Action: = " << entities["action"].c_str() << std::endl;
}
break;
case ResultReason::NoMatch:
{
auto noMatch = NoMatchDetails::FromResult(result);
switch (noMatch->Reason)
{
case NoMatchReason::NotRecognized:
std::cout << "NOMATCH: Speech was detected, but not recognized." << std::endl;
break;
case NoMatchReason::InitialSilenceTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only silence, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::InitialBabbleTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only noise, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::KeywordNotRecognized:
std::cout << "NOMATCH: Keyword not recognized." << std::endl;
break;
}
break;
}
case ResultReason::Canceled:
{
auto cancellation = CancellationDetails::FromResult(result);
if (!cancellation->ErrorDetails.empty())
{
std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails.c_str() << std::endl;
std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl;
}
}
default:
break;
}
}
Générer et exécuter votre application
Vous êtes maintenant prêt à créer votre application et à tester la reconnaissance vocale à l’aide du service de reconnaissance vocale.
- Compiler le code : à partir de la barre de menus de Visual Studio, choisissez Générer>Générer la solution.
- Démarrer votre application : dans la barre de menus, choisissez Déboguer>Démarrer le débogage, ou appuyez sur F5.
- Démarrer la reconnaissance : vous êtes invité à prononcer une phrase. La langue par défaut est l'anglais. Celle-ci est envoyée au service de reconnaissance vocale, transcrite sous forme de texte, puis affichée sur la console.
Par exemple, si vous dites « me faire passer à l’étage 7 », il doit s’agir de la sortie suivante :
Say something ...
RECOGNIZED: Text = Take me to floor 7.
Intent Id = ChangeFloors
Floor name: = 7
Documentation de référence | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous installez le SDK Speech pour Java.
Plateforme requise
Choisissez votre environnement cible :
Le Kit de développement logiciel (SDK) Speech pour Java est compatible avec Windows, Linux et macOS.
Sur Windows, vous devez utiliser l’architecture cible 64 bits. Vous avez besoin de Windows 10 ou une version ultérieure.
Installez le Redistribuable Microsoft Visual C++ pour Visual Studio 2015, 2017, 2019 et 2022 pour votre plateforme. La toute première installation de ce package peut nécessiter un redémarrage.
Le SDK Speech pour Java ne prend pas en charge Windows sur ARM64.
Installez un kit de développement Java tel que Azul Zulu OpenJDK. La build Microsoft d’OpenJDK ou le JDK de votre choix doivent également fonctionner.
Installer le Kit de développement logiciel (SDK) Speech pour Java
Certaines instructions utilisent une version spécifique du Kit de développement logiciel (SDK) comme 1.24.2. Pour vérifier la dernière version, recherchez dans notre dépôt GitHub.
Choisissez votre environnement cible :
Ce guide explique comment installer le Kit de développement logiciel (SDK) Speech pour Java sur le runtime Java.
Systèmes d’exploitation pris en charge
Le Kit de développement logiciel (SDK) Speech pour le package Java est disponible pour les systèmes d’exploitation suivants :
- Windows : 64 bits uniquement.
- Mac : macOS X version 10.14 ou ultérieure.
- Linux : consultez les architectures cibles et distributions Linux prises en charge.
Procédez comme suit pour installer le Kit de développement logiciel (SDK) Speech pour Java à l’aide d’Apache Maven :
Installez Apache Maven.
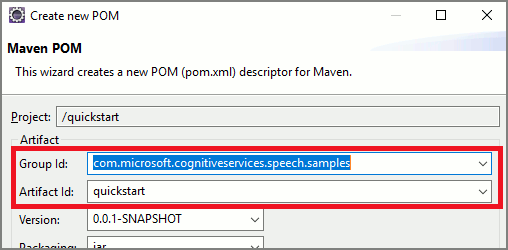
Ouvrez une invite de commandes à l’emplacement où vous souhaitez placer le nouveau projet, puis créez un fichier pom.xml.
Copiez le contenu XML suivant dans pom.xml :
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>Exécutez la commande Maven suivante pour installer le kit de développement logiciel (SDK) Speech et les dépendances.
mvn clean dependency:copy-dependencies
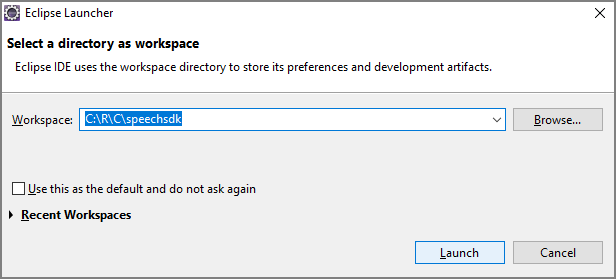
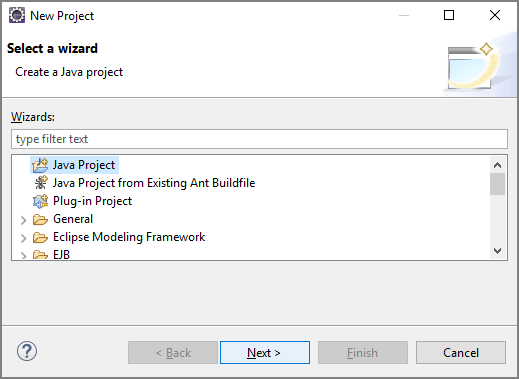
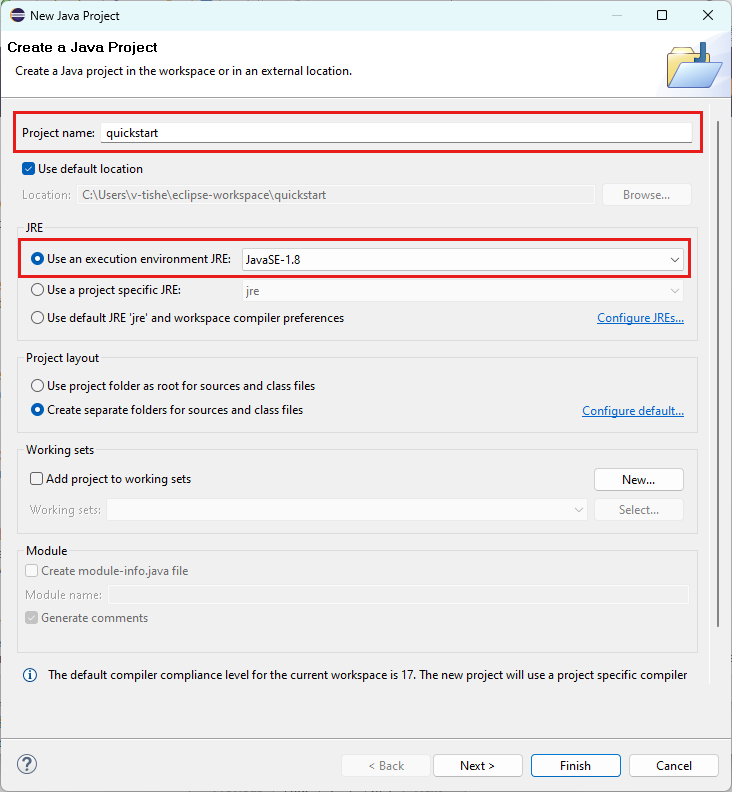
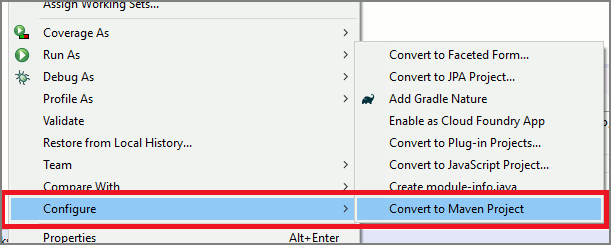

Commencer avec du code réutilisable
Ouvrez
Main.javaà partir du dir src.Remplacez le contenu du fichier par ce qui suit :
package quickstart;
import java.util.Dictionary;
import java.util.concurrent.ExecutionException;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
public class Program {
public static void main(String[] args) throws InterruptedException, ExecutionException {
IntentPatternMatchingWithMicrophone();
}
public static void IntentPatternMatchingWithMicrophone() throws InterruptedException, ExecutionException {
SpeechConfig config = SpeechConfig.fromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
}
}
Créer une configuration Speech
Avant de pouvoir initialiser un objet IntentRecognizer, vous devez créer une configuration qui utilise la clé et la localisation pour la ressource de prédiction de vos services Azure AI.
- Remplacez
"YOUR_SUBSCRIPTION_KEY"par la clé de prédiction de vos services Azure AI. - Remplacez
"YOUR_SUBSCRIPTION_REGION"par la région de ressource de vos services Azure AI.
Cet exemple utilise la méthode FromSubscription() pour générer la SpeechConfig. Pour obtenir la liste complète des méthodes disponibles, consultez la rubrique Classe SpeechConfig.
Initialiser IntentRecognizer
Créez maintenant un IntentRecognizer. Insérez ce code juste en dessous de votre configuration Speech.
try (IntentRecognizer intentRecognizer = new IntentRecognizer(config)) {
}
Ajouter des intentions
Vous devez associer des modèles à IntentRecognizer en appelant addIntent().
Nous allons ajouter 2 intentions avec le même ID pour changer d’étage et une autre intention avec un ID distinct pour ouvrir et fermer les portes.
Insérez ce code dans le bloc try :
intentRecognizer.addIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer.addIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer.addIntent("{action} the door.", "OpenCloseDoor");
Notes
Il n’existe aucune limite quant au nombre d’entités que vous pouvez déclarer, mais elles seront faiblement mises en correspondance. Si vous ajoutez une expression telle que « {action} porte », elle correspondra à chaque fois qu’il y a du texte avant le mot « porte ». Les intentions sont évaluées en fonction du nombre de leurs entités. Si deux modèles correspondent, celui avec des entités plus définies est retourné.
Reconnaître une intention
À partir de l’objet IntentRecognizer, vous devez appeler la méthode recognizeOnceAsync(). Cette méthode demande au service Speech de reconnaître la parole en une seule phrase et d’arrêter la reconnaissance vocale une fois que l’expression est identifiée. Pour faire simple, nous attendons la fin des prochains retours.
Insérez ce code sous vos intentions :
System.out.println("Say something...");
IntentRecognitionResult result = intentRecognizer.recognizeOnceAsync().get();
Afficher les résultats de la reconnaissance (ou les erreurs)
Lorsque le résultat de la reconnaissance est retourné par le service Speech, nous allons imprimer le résultat.
Insérez ce code en dessous de IntentRecognitionResult result = recognizer.recognizeOnceAsync().get(); :
if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s", "Intent not recognized."));
}
else if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s %s", "Intent Id=", result.getIntentId() + "."));
Dictionary<String, String> entities = result.getEntities();
if (entities.get("floorName") != null) {
System.out.println(String.format("%17s %s", "FloorName=", entities.get("floorName")));
}
if (entities.get("action") != null) {
System.out.println(String.format("%17s %s", "Action=", entities.get("action")));
}
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error)
{
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
Vérifier votre code
À ce stade, votre code doit ressembler à ceci :
package quickstart;
import java.util.Dictionary;
import java.util.concurrent.ExecutionException;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
public class Main {
public static void main(String[] args) throws InterruptedException, ExecutionException {
IntentPatternMatchingWithMicrophone();
}
public static void IntentPatternMatchingWithMicrophone() throws InterruptedException, ExecutionException {
SpeechConfig config = SpeechConfig.fromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
try (IntentRecognizer intentRecognizer = new IntentRecognizer(config)) {
intentRecognizer.addIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer.addIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer.addIntent("{action} the door.", "OpenCloseDoor");
System.out.println("Say something...");
IntentRecognitionResult result = intentRecognizer.recognizeOnceAsync().get();
if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s", "Intent not recognized."));
}
else if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s %s", "Intent Id=", result.getIntentId() + "."));
Dictionary<String, String> entities = result.getEntities();
if (entities.get("floorName") != null) {
System.out.println(String.format("%17s %s", "FloorName=", entities.get("floorName")));
}
if (entities.get("action") != null) {
System.out.println(String.format("%17s %s", "Action=", entities.get("action")));
}
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error)
{
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
}
}
}
Générer et exécuter votre application
Vous êtes maintenant prêt à créer votre application et à tester notre reconnaissance d’intention à l’aide du service speech et de la correspondance de modèle incorporé.
Sélectionnez le bouton exécuter dans Eclipse ou appuyez sur Ctrl+F11, puis attendez la sortie pour l’invite « Dire quelque chose... » . Une fois qu’elle apparaît, prononcez votre énoncé et attendez la sortie.
Par exemple, si vous dites « me faire passer à l’étage 7 », il doit s’agir de la sortie suivante :
Say something ...
RECOGNIZED: Text= Take me to floor 7.
Intent Id= ChangeFloors
FloorName= 7
Étapes suivantes
Améliorez vos critères spéciaux à l’aide d’entités personnalisées.