Redondance du service DHCP sous Windows Server 2008 R2 (fr-FR)
Pourquoi un cluster dhcp ?
La question peut légitimement se poser. En effet, un client ayant acquis son adresse la conserve un certain temps, ce temps est appelé bail ou lease in English :) (Chez Microsoft par défaut sur un LAN 8 jours). Au bout de ce délai le client voit son bail arrivé à terme, il demande au serveur s'il peut le prolonger. De même pour le serveur, lorsqu'un bail arrive à terme il envoie une demande au client pour savoir si celui-ci souhaite prolonger son bail.
Maintenant que se passe-t-il si entre le début et la fin du bail le service DHCP tombe ?
Et bien les clients ne seront tout simplement plus capable d'obtenir une adresse IP et ne pourront donc plus communiquer.
Jusqu'ici la méthode classique permettant de palier à la perte d'un service DHCP était d'avoir deux serveurs DHCP avec des scopes identiques. Le premier serveur était actif et le second avec le service non démarré. Lors d'une panne DHCP sur le premier serveur on démarrait le service DHCP sur le deuxième serveur et les clients retrouvaient la possibilité de communiquer.
Mis à part son côté archaïque cette méthode présuppose que l'on détecte la panne du premier serveur. Cette panne a moins d'avoir un système de monitoring n'était généralement détecter que lors de la perte du service sur le premier serveur générant au mieux quelques temps d'indisponibilité pour les clients, du stress pour les équipes («Heu quelqu'un a déjà tester le DHCP de backup ?») et au pire un remontage de serveur :D
Deuxième point sur le second serveur à moins de faire régulièrement un export de configuration on ne retrouvera pas les dernières options mises sans trop réfléchir (C'est mal), les leases actuels, les réservations, bref la configuration.
Une autre méthode est de diviser ses scopes DHCP. Ainsi si l'on prend l'exemple d'un parc de 50 clients. La coutume voudrait que l'on attribue un scope de 50 adresses plus une marge permettant l'expansion du parc. En fonction de l'activité on ajoutera 10 - 20 - 30% voire plus.
Pour suivre l'exemple avec des chiffres simples nous imaginerons un environnement dynamique et l'on attribuera un scope de 100 adresses soit le double de ce qui est nécessaire. Maintenant que la taille du scope est définie passons à la redondance.
La technique du "Split-DHCP" consiste donc à diviser sont scope sur des serveurs permettant ainsi si l'un tombe que l'autre puisse prendre la relève mais aussi d'équilibrer la charge car les serveurs sont actif-actif.
Pour ce faire il va falloir s'assurer qu'un seul et unique serveur puisse prendre en charge l’intégralité du service si le second tombe. Ainsi chaque scope présent sur chaque serveur doit être capable d'adresser l’intégralité du parc. Dans notre exemple nous devrons donc créer sur chaque serveur DHCP un scope de 100 adresses chacun (sur la même plage bien-sûr) avec les même options.
Ici aussi petit problème, afin d'assurer la redondance d'un service nous avons recourt à une forme de bricolage qui demande de doubler les scopes et aussi de maintenir de façon manuelle l'exactitude des configurations entre les deux serveurs.
Sous 2008R2 Microsoft permet d'utilise un wizard afin de procéder à cette manipulation.
Une troisième solutions existe donc c'est le cluster DHCP.
Pour commencer sur les cluster voici quelques éléments clés.
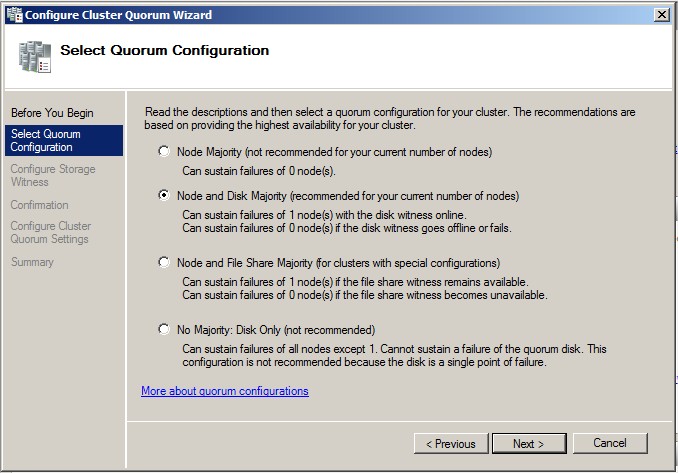
Qu'est-ce que le quorum ?
Pour faire simple, le quorum est un terme bien mystérieux pour décrire un concept assez simple. C'est donc le nombre minimum de nœud nécessaire au fonctionnement du cluster. Le fonctionnement est simple, les membres du cluster votes, si le nombre de votes tombe sous la valeur du quorum, le cluster s’arrête.
Il existe quatre types de quorum :
- **Node Majority **: Chaque nœud vote, le cluster fonctionne uniquement si la majorité absolue est atteinte (plus de 50%).
- Node and Disk Majority : Le fonctionnement est le même que le "Node Majority" néanmoins une partie supplémentaire interviens dans le vote, c'est le witness disk (disque témoin)
- Node and File Share Majority : ici le principe est le même que pour le "Node and Disk Majority" mais le disk witness est remplacer par un partage réseau classique
- No Majority, Disk Only: Dans ce fonctionnement seul les nœuds en communication avec le witness disk peuvent continuer à faire fonctionner le service. Ici il n'est pas nécessaire d'avoir une majorité de nœud en fonctionnement.
Witness disk et File Share Majority
Afin de palier au problème des clusters avec un nombre de nœud paire Microsoft permet d'ajouter aux partie du cluster (ou chacun vote) un tiers. Ce dernier peut être un disque accessible par chacun (LUN, Volume iScsi) ou un partage réseau. Ce volume partagé doit bien-sûr être accessible par tous. Un problème sur ce volume est considéré comme la perte d'un nœud. Il permet également comme tous les membres d'un cluster de stocker une copie de la configuration du cluster.
Un petit exemple :
Le cluster est composé de quatre serveurs.
- Node Majority : Si deux nœud tombe (quorum = 2), le service proposé s’arrête.
- **Node and disk majority : **Le cluster comporte un membre de plus (le witness disk) on a donc 5 nœuds. Ainsi Si deux nœud tombe (quorum = 3), le service continue. En revanche si trois tombe, le quorum passe à 2 ce qui est sous la majorité et le service s'arrête.
- Node and file share majority : fonctionnement identique à "Node and disk majority" avec un partage réseau.
- **No Majority, Disk Only: **La condition de fonctionnement est l'accès au witness disk. Trois des quatre membres du cluster peuvent tomber, si le dernier est toujours en liaison avec le witness disk, le service continue. En revanche, si tous les membres du cluster fonctionnent mais que le witness disk tombe, le cluster complet tombe.
Les best practices
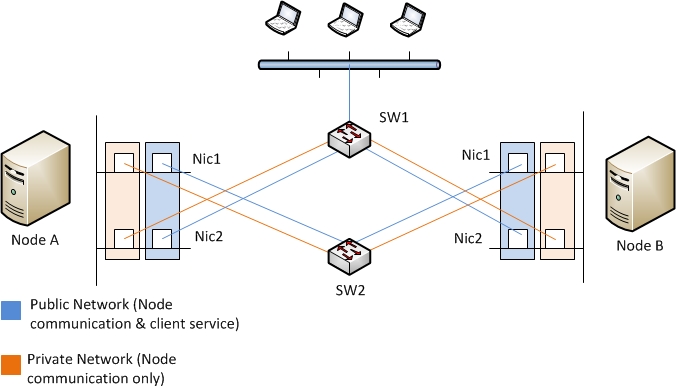
Le but d’un cluster est bien évidemment d’offrir une résistance élevé aux différentes pannes qu’il est possible de rencontrer. Ainsi même si il est possible de créer un cluster avec des nœuds n utilisant qu’une unique interface réseau pour communiquer entre eux, accéder au quorum et offrir le service aux clients il est préférable de séparer ces trois services.
De plus d’un point de vue physique il sera bien évidemment préférable d’avoir des interfaces physiques sur différentes cartes utilisant différents bus.
Ensuite viens la redondance réseau, ce point n’entre pas dans ce sujet mais il sera bien évidemment préférables d’avoir des chemins divers utilisant différents switch.
Ainsi la meilleure solution est bien d’utiliser deux cartes multi port utilisant des bus différents. Ces interfaces étant câblé sur différent switch et ayant eux même une solution de teaming offrant une solution de fault tolérance.
Node and disk majority :
- La taille du witness disk doit être d’au moins 512 Mo
- Utiliser une LUN uniquement dédié à ca
- Configurer la LUN pour utiliser du RAID
- Exclure le witness disk des scan antivirus
- Formater la LUN en NTFS
Node and File Share Majority :
- Utiliser un partage SMB
- Le partage doit avoir au moins 5Mo de disponible
- Utilisez le share uniquement pour cet usage
- Utilisez un share présenté par un serveur dans le même domaine et la même foret
- Ne pas utiliser de DFS
**Tutorial **
Pour faire simple nous allons monter un cluster DHCP avec deux nœuds sur un lab.
Pré requis :
- Etre dans un Domain active directory
- Au moins deux serveur pour le rôle DHCP
- Un client
- Deux volumes
- Et nom et une adresse IP pour le cluster
- Un nom et une adresse IP pour le service DHCP
Environnement
Nœud 1 : powerhouse2008a
Nœud 2 : powerhouse2008b
Ces deux serveurs sont les deux AD de mon Lab.
Les deux volumes sont présentés par un serveur FreeNas. @IP : 192.168.0.248
Nom du cluster : ClusterDHCP
@IP du cluster : 192.168.0.250
Attention :
Avant de commencer : Si les serveurs DHCP que vous souhaitez utiliser pour monter ce cluster comportent déjà une configuration cette dernière sera perdue lors de la mise en place du cluster. Penser à faire un backup ou utiliser des serveurs "neufs".
Présenter les volumes : Windows 2008 R2 intègre une gestion des Target et initiator iScsi. Pour joindre mes volumes je renseigne l'adresse de mon serveur FreeNas |
|
Monter et initialiser les disques : |
|
|
|
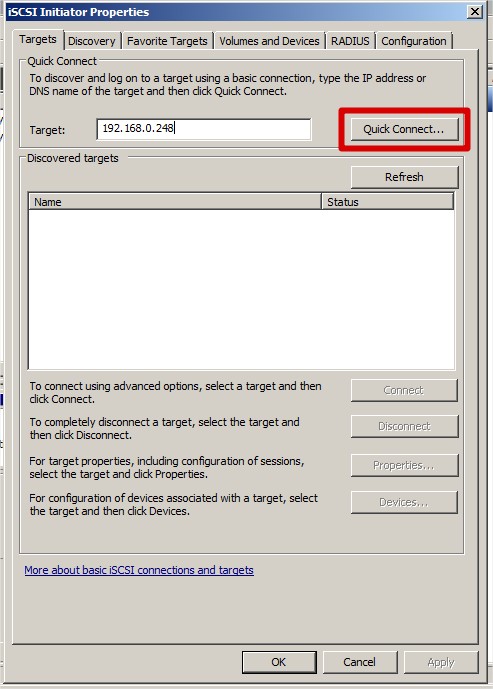
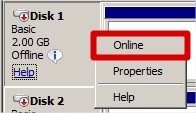
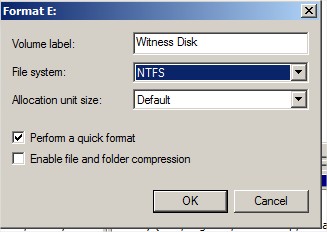
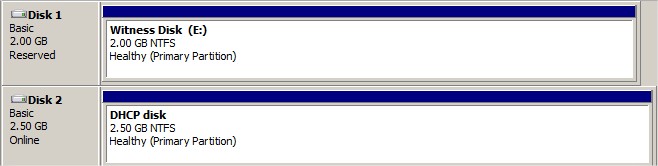
Idem avec le volume permettant de stocker la configuration DHCP. Le resultat doit etre deux volumes visibles par les deux serveurs :
Ensuite nous ajoutons les features Failover Cluster :
|
|
Choisir Failover Cluster :
|
|
Nous allons maintenant créer le cluster :
|
|
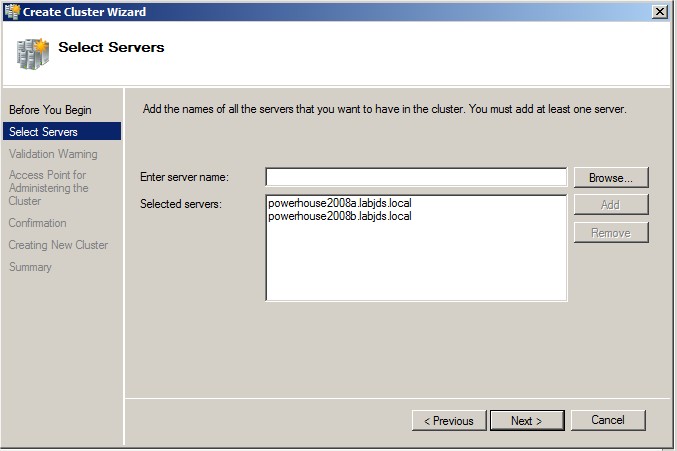
Ajouter les nœuds :
|
|
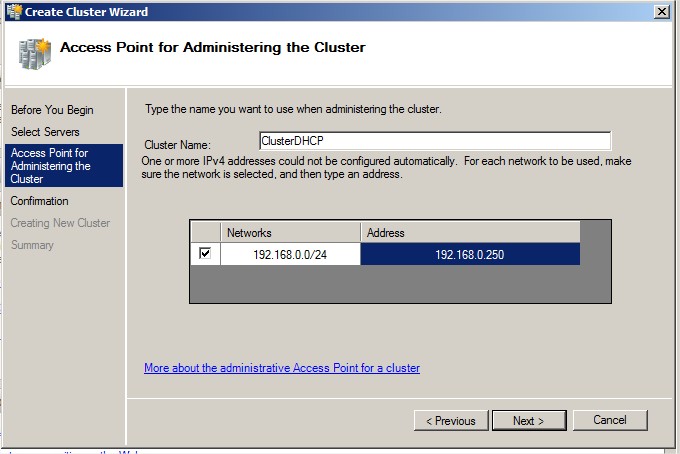
Renseignez le nom du cluster ainsi que son adresse :
|
|
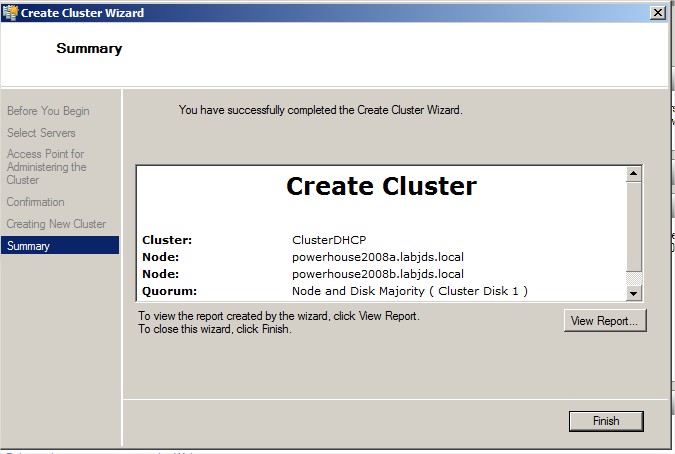
Fin de la création du cluster :
|
|
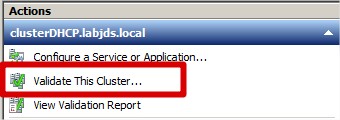
Valider la configuration du cluster :
|
|
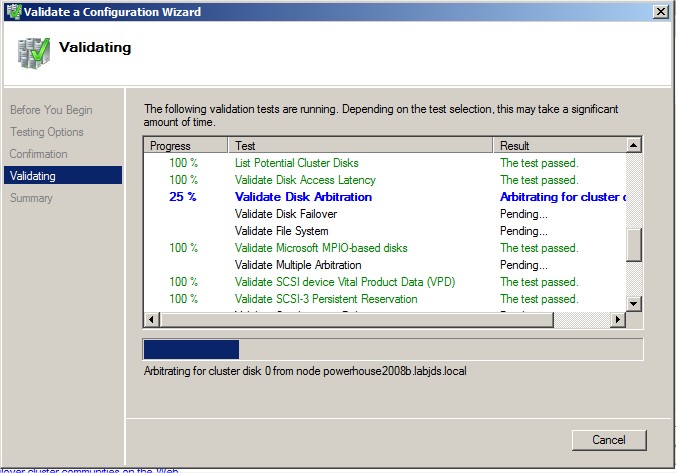
Lancer le test :
|
|
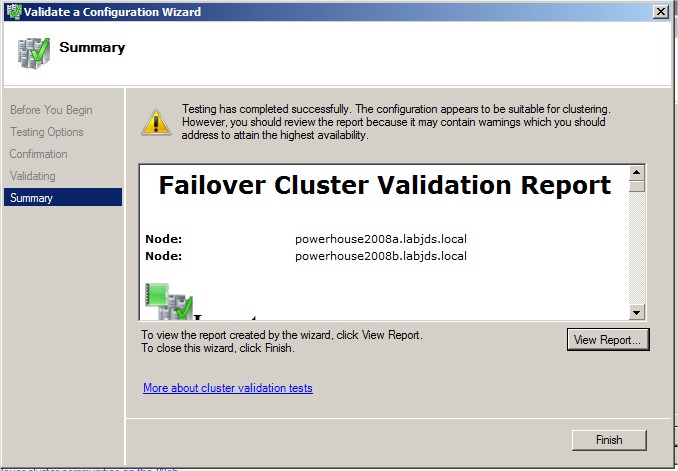
Vérifiez le résultat des tests. Dans mon cas le warning viens du fait que pour mon lab je n'utilise qu'une seul carte réseau ce qui présente un "single point of failure". Si des warning sont présent prenez en conscience si vous maitriser la cause pas de soucis. En revanche il vous faudra toujours corriger les Error.
|
|
Configuration du mode de fonctionnement du cluster : |
|
C'est ici que l'on sélectionne le mode de fonctionnement comme décrit au début de cette page :
|
|
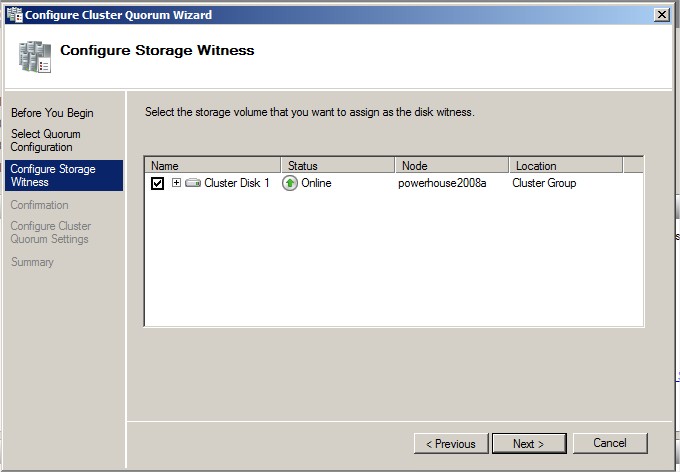
Sélectionnez le Witness Disk |
|
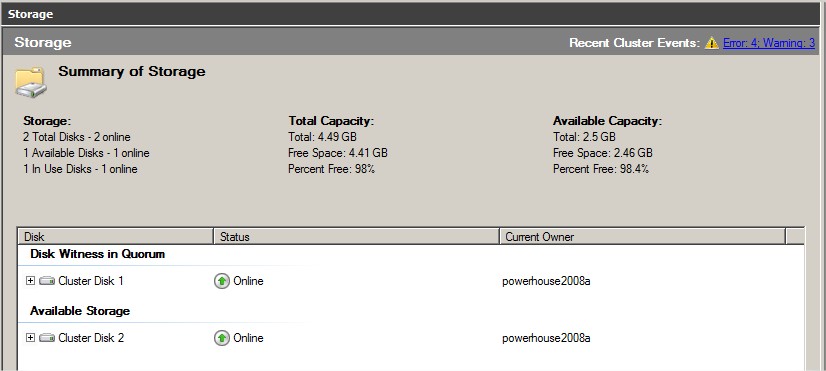
Dans la rubrique Storage vous devriez avoir cela : |
|
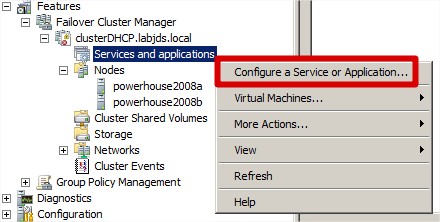
Configuration du service DHCP |
|
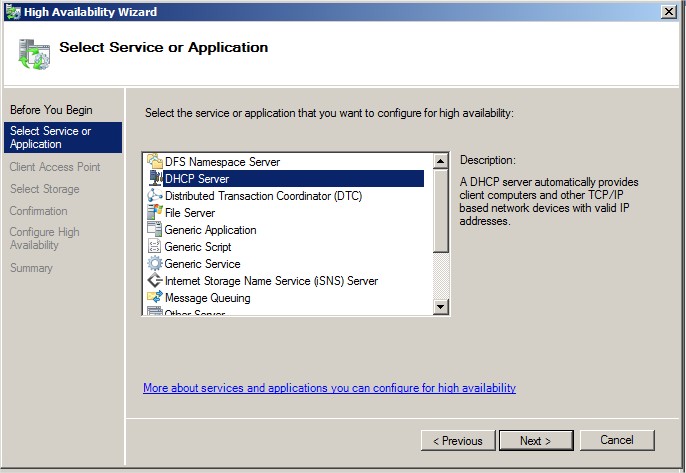
Sélectionnez le service DHCP |
|
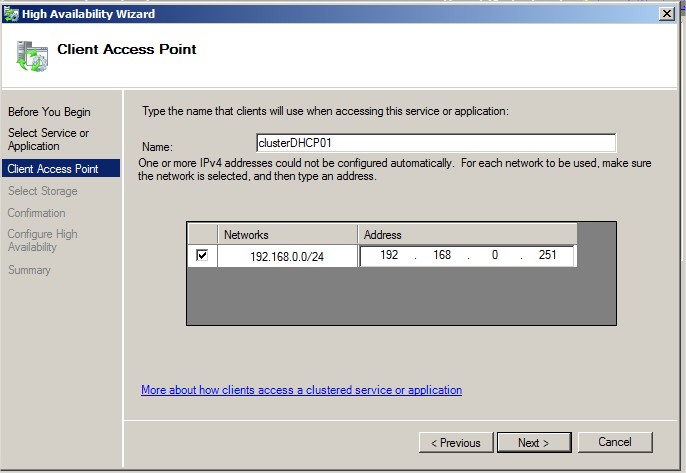
Donner un nom et une IP au service DHCP |
|
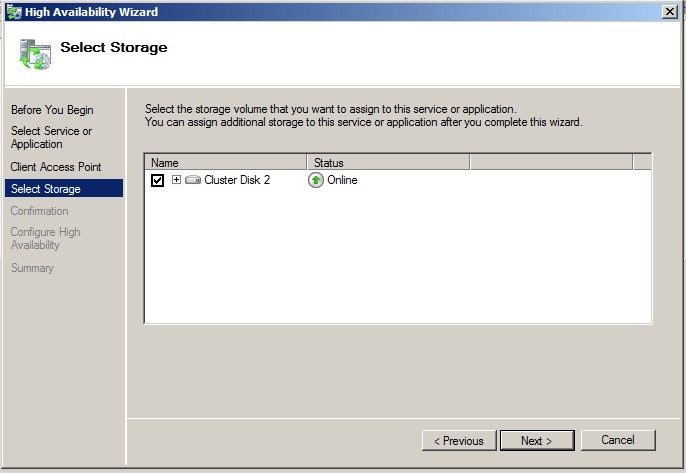
Sélectionnez le disque qui va permettre aux nœuds de partager leur configuration. Ce disque doit être accessible par tous les nœuds :
|
|
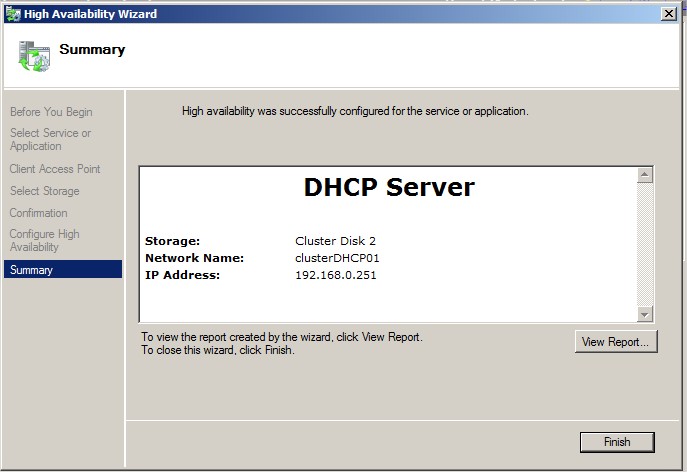
Fin de la configuration :
|
|
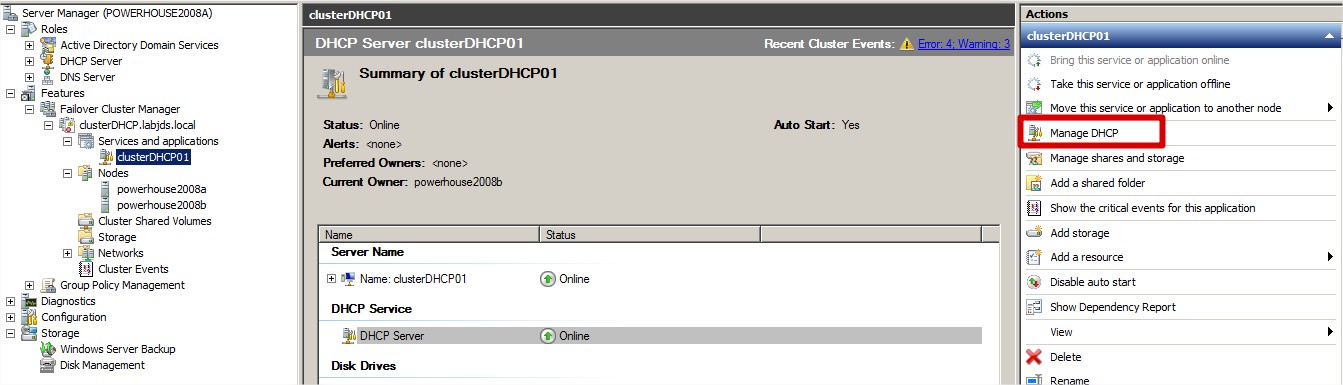
Gestion du serveur DHCP :
|
|
Ajouter un scope comme sur un serveur DHCP normal :
|
|
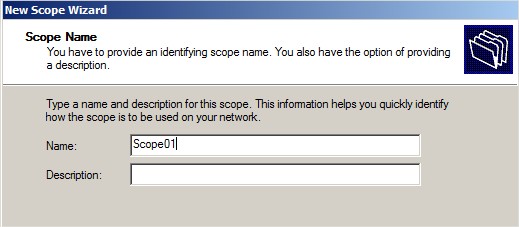
Nommer le scope :
|
|
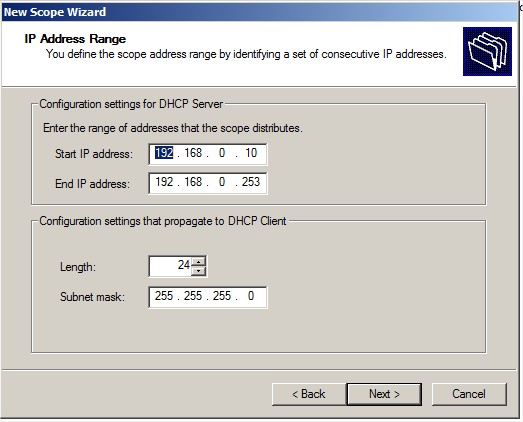
Ajouter une plage :
|
|
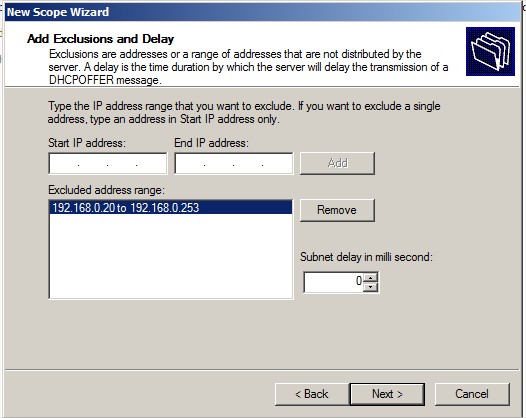
Une exclusion si necessaire :
|
|
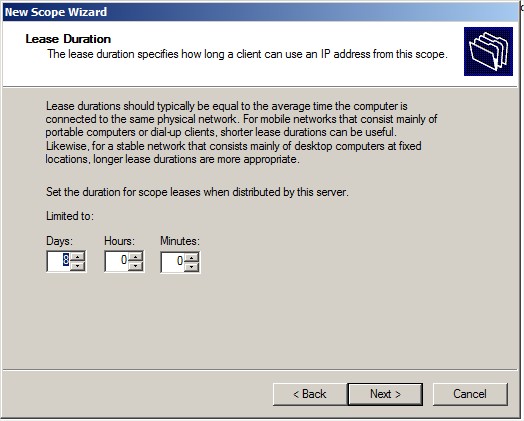
Spécifier la durée du lease :
|
|
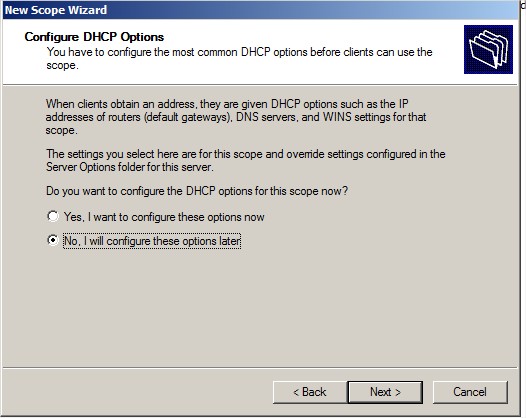
Configuration des options :
|
|
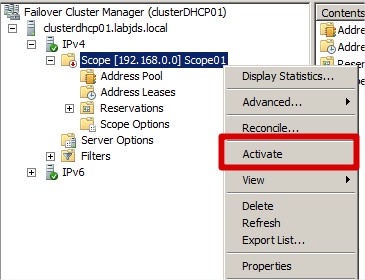
Activer le scope :
|
|
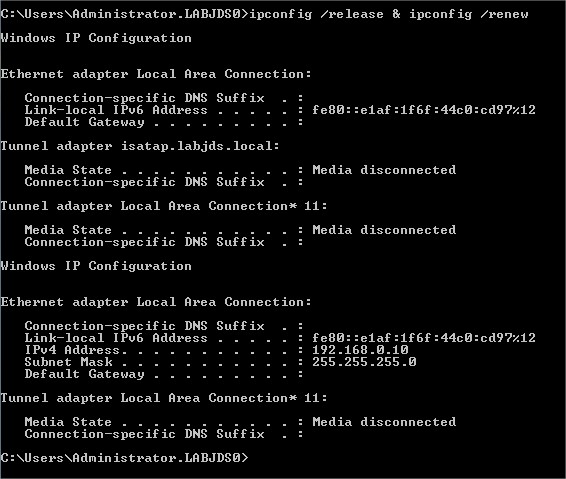
Test sur un client
|
|
Ensuite libre à vous de tester le tout en coupant une carte réseau, le serveur iScsi, un serveur etc et voir le fonctionnement.
A noter que vous pouvez aussi ajouter une interface réseau dédié à la communication entre les noeuds.
Si vous avez des questions, des commentaires, des retours d’expériences je suis preneur :D
A bon entendeur,
Julien
Sources :
http://technet.microsoft.com/en-us/library/ee405263(v=ws.10).aspx
http://technet.microsoft.com/en-us/library/cc770620(v=ws.10).aspx