Small Basic: Jeu de Caractères - Unicode (fr-FR)
Introduction
Cet article explique le fonctionne des jeu de caractères en particulier dans le langage de programmation Microsoft Small Basic.
Qu'est-ce qu'un Jeu de Caractères ?
Un jeu de caractères est ensemble de codes pour l'encodage de caractères. Le code ASCII a été très populaire comme encodage de caractères sur 7 bits. Dans Small Basic, le jeu de caractère utilisé est l'Unicode.
Qu'est-ce qu'un Code Caractère ?
Un code caractère est un nombre qui représente chaque caractère. Vous pouvez obtenir le code de n'importe quel caractère avec l'opération Text.GetCharacterCode(). De même que vous pouvez obtenir le caractère correspondant à un code avec l'opération Text.GetCharacter().
Qu'est-ce que l'Unicode ?
Fondamentalement l'Unicode a été créé en tant que caractère sur 16 bits, incluant plusieurs codes DBCS (Double Byte Character Set - Jeu de Caractère à Double Octets) provenant de plusieurs pays. A ce jours, la plupart des Systèmes d'Exploitation, sites Web et applications utilisent l'Unicode. Habituellement l'Unicode s'écrit de la manière suivante U+0022. Ce code représente le caractère guillemet (") qui à le code caractère 34 (0x22). 0x22 est la représentation hexadécimale. Le programme "Table des caractères" dans les accessoires Windows permet d'afficher les valeurs Unicode de chaque caractère. Cet outil affiche uniquement la plage Unicode entre U+0000 et U+FFFF.
La table qui suit et obtenue depuis le programme "IME Pad" qui est inclus dans les versions Japonaises de Windows (nationalité de l'auteur de l'article originel). La plage de U+0000 à U+FFFF est appelée BMP ("Basic Multilingual Plane" ou Plan Multilingue de Base). La plage de U+10000 à U+1FFFF est appelée SMP ("Supplementary Multilingual Plane" ou Plan Multilingue Complémentaire). La table qui est contient la carte complète de BMP et une partie de SMP. Les autres plans de la plage U+20000 à U+10FFFF ne sont pas présentés.
| Unicode (BMP) | De | A |
| Latin de Base | U+0020 | U+007F |
| Supplément Latin-1 | U+0080 | U+00FF |
| Latin Etendu-A | U+0100 | U+017F |
| Latin Etendu-B | U+0180 | U+024F |
| Alphabet Phonétique International | U+0250 | U+02AF |
| Lettres Modificatives avec Chasse | U+02B0 | U+02FF |
| Diacritiques | U+0300 | U+036F |
| Grec et Copte | U+0370 | U+03FF |
| Cyrillique | U+0400 | U+04FF |
| Supplément Cyrillique | U+0500 | U+052F |
| Arménien | U+0530 | U+058F |
| Hébreu | U+0590 | U+05FF |
| Arabe | U+0600 | U+06FF |
| Syriaque | U+0700 | U+074F |
| Suplément Arabe | U+0750 | U+077F |
| Thâna | U+0780 | U+07BF |
| NKo | U+07C0 | U+07FF |
| Samaritan | U+0800 | U+083F |
| Mandiac | U+0840 | U+08FF |
| Dévanâgarî | U+0900 | U+097F |
| Bengali | U+0980 | U+09FF |
| Gourmoukhî | U+0A00 | U+0A7F |
| Goudjerate | U+0A80 | U+0AFF |
| Oriya | U+0B00 | U+0B7F |
| Tamoul | U+0B80 | U+0BFF |
| Télougou | U+0C00 | U+0C7F |
| Kannara | U+0C80 | U+0CFF |
| Malayalam | U+0D00 | U+0D7F |
| Singhalais | U+0D80 | U+0DFF |
| Thai | U+0E00 | U+0E7F |
| Lao | U+0E80 | U+0EFF |
| Tibétain | U+0F00 | U+0FFF |
| Birman | U+1000 | U+109F |
| Géorgien | U+10A0 | U+10FF |
| Jamos hangûl | U+1100 | U+11FF |
| Éthiopien | U+1200 | U+137F |
| Supplément Éthiopien | U+1380 | U+139F |
| Chérokî | U+13A0 | U+13FF |
| Syllabaires autochtones canadiens unifiés | U+1400 | U+167F |
| Ogam | U+1680 | U+169F |
| Runes | U+16A0 | U+16FF |
| Tagalog | U+1700 | U+171F |
| Hanounóo | U+1720 | U+173F |
| Bouhide | U+1740 | U+175F |
| Tagbanoua | U+1760 | U+177F |
| Khmer | U+1780 | U+17FF |
| Mongol | U+1800 | U+18AF |
| Syllabaires autochtones Arborigènes Etendus | U+18B0 | U+18FF |
| Limbou | U+1900 | U+194F |
| Taï-le | U+1950 | U+197F |
| Nouveau Taï-le | U+1980 | U+19DF |
| Symboles khmers | U+19E0 | U+19FF |
| Buginese | U+1A00 | U+1A1F |
| Tai Tham | U+1A20 | U+1AFF |
| Balinese | U+1B00 | U+1B7F |
| Sundanese | U+1B80 | U+1BBF |
| Batak | U+1BC0 | U+1BFF |
| Lepcha | U+1C00 | U+1C4F |
| Ol Chiki | U+1C50 | U+1CCF |
| Vedic Extensions | U+1CD0 | U+1CFF |
| Supplément phonétique | U+1D00 | U+1D7F |
| Extensions Supplément phonétique | U+1D80 | U+1DBF |
| Combining Diacritical Marks Supplement | U+1DC0 | U+1DFF |
| Latin étendu additionnel | U+1E00 | U+1EFF |
| Grec étendu | U+1F00 | U+1FFF |
| Ponctuation générale | U+2000 | U+206F |
| Exposants et indices | U+2070 | U+209F |
| Symboles monétaires | U+20A0 | U+20CF |
| Signes combinatoires pour symboles | U+20D0 | U+20FF |
| Symboles de type lettre | U+2100 | U+214F |
| Formes numérales | U+2150 | U+218F |
| Flèches | U+2190 | U+21FF |
| Opérateurs mathématiques | U+2200 | U+22FF |
| Signes techniques divers | U+2300 | U+23FF |
| Pictogrammes de commande | U+2400 | U+243F |
| Reconnaissance optique de caractères | U+2440 | U+245F |
| Alphanumériques cerclés | U+2460 | U+24FF |
| Filets | U+2500 | U+257F |
| Pavés | U+2580 | U+259F |
| Formes géométriques | U+25A0 | U+25FF |
| Symboles divers | U+2600 | U+26FF |
| Casseau | U+2700 | U+27BF |
| Divers symboles mathématiques - A | U+27C0 | U+27EF |
| Supplément A de flèches | U+27F0 | U+27FF |
| Combinaisons Braille | U+2800 | U+28FF |
| Supplément B de flèches | U+2900 | U+297F |
| Divers symboles mathématiques-B | U+2980 | U+29FF |
| Opérateurs mathématiques supplémentaires | U+2A00 | U+2AFF |
| Divers symboles et flèches | U+2B00 | U+2BFF |
| Glagolitic | U+2C00 | U+2C5F |
| Latin Extended-C | U+2C60 | U+2C7F |
| Coptic | U+2C80 | U+2CFF |
| Gergian Supplement | U+2D00 | U+2D2F |
| Alphabet Tifinagh et néo-Tifinagh | U+2D30 | U+2D7F |
| Ethiopic Extended | U+2D80 | U+2DDF |
| Cyrillic Extended-A | U+2DE0 | U+2DFF |
| Supplemental Punctuation | U+2E00 | U+2E7F |
| Formes supplémentaires des clés CJC | U+2E80 | U+2EFF |
| Clés chinoises (K'ang-hsi ou Kangxi) | U+2F00 | U+2FEF |
| Description idéophonographique | U+2FF0 | U+2FFF |
| Symboles et ponctuation CJC | U+3000 | U+303F |
| Hiragana | U+3040 | U+309F |
| Katakana | U+30A0 | U+30FF |
| Bopomofo | U+3100 | U+312F |
| Jamos de compatibilité hangûls | U+3130 | U+318F |
| Kanboun | U+3190 | U+319F |
| Bopomofo étendu | U+31A0 | U+31BF |
| CJK Strokes | U+31C0 | U+31EF |
| Extension phonétique katakana | U+31F0 | U+31FF |
| Lettres et mois CJC cerclés | U+3200 | U+32FF |
| Compatibilité CJC | U+3300 | U+33FF |
| Supplément A aux idéophonogrammes unifiés CJC | U+3400 | U+4DBF |
| Hexagrammes du Classique des mutations ou Yi Jing | U+4DC0 | U+4DFF |
| Idéophonogrammes unifiés CJC | U+4E00 | U+9FFF |
| Syllabaire yi des Monts frais | U+A000 | U+A48F |
| Clés yi | U+A490 | U+A4CF |
| Lisu | U+A4D0 | U+A4FF |
| Vai | U+A500 | U+A63F |
| Cyrillic Extended-B | U+A640 | U+A69F |
| Bamum | U+A6A0 | U+A6FF |
| Modifier Tone Letters | U+A700 | U+A71F |
| Latin Extended-D | U+A720 | U+A7FF |
| Syloti Nagri | U+A800 | U+A82F |
| Common Indic Number Forms | U+A830 | U+A83F |
| Phags-pa | U+A840 | U+A87F |
| Saurashtra | U+A880 | U+A8DF |
| Devanagari Extended | U+A8E0 | U+A8FF |
| Kayah Li | U+A900 | U+A92F |
| Rejang | U+A930 | U+A95F |
| Hangul Jamo Extended-A | U+A960 | U+A97F |
| Javanese | U+A980 | U+A9FF |
| Cham | U+AA00 | U+AA5F |
| Myammar Extended-A | U+AA60 | U+AA7F |
| Tai Viet | U+AA80 | U+AAFF |
| Ethiopic Extended-A | U+AB00 | U+ABBF |
| Meetei Mayek | U+ABC0 | U+ABFF |
| Hangûl | U+AC00 | U+D7AF |
| Hangul Jamo Extended-B | U+D7B0 | U+D7FF |
| Demi-zone haute points de code invalides isolément | U+D800 | U+DB7F |
| High Private Use Surrogates | U+DB80 | U+DBFF |
| Low Surrogates | U+DC00 | U+DFFF |
| Zone à usage privé | U+E000 | U+F8FF |
| Idéogrammes de compatibilité CJC | U+F900 | U+FAFF |
| Formes de présentation alphabétiques | U+FB00 | U+FB4F |
| Formes A de présentation arabes voir alphabet arabe | U+FB50 | U+FDFF |
| Sélecteurs de variante | U+FE00 | U+FE0F |
| Vertical Forms | U+FE10 | U+FE1F |
| Demi-signes combinatoires | U+FE20 | U+FE2F |
| Formes de compatibilité CJC | U+FE30 | U+FE4F |
| Petites variantes de forme | U+FE50 | U+FE6F |
| Formes B de présentation arabes | U+FE70 | U+FEFF |
| Formes de demi et pleine chasse | U+FF00 | U+FFAF |
| Caractères spéciaux | U+FFB0 | U+FFFF |
| Partie de l'Unicode (SMP) | De | A |
| Pièces de mah-jong | U+1F000 | U+1F02F |
| Dominos | U+1F030 | U+1F09F |
| Cartes à jouer | U+1F0A0 | U+1F2FF |
| Divers symboles et pictogrammes | U+1F300 | U+1F5FF |
| Emoticônes | U+1F600 | U+1F67F |
| Symboles du transport et cartographiques | U+1F680 | U+1FFFF |
Qu'est-ce que l'UTF-8 ?
Les fichiers sources Small Basic et les fichiers créés et lus avec l'objet File son encodés avec l'UTF-8. L'UTF-8 est le synonyme de UCS ("Universal Character Set" ou JUC Jeu Universel de Caractères codés) transformé au format 8 bits. L'UTF-8 l'un des formats utilisé pour encoder l'Unicode. L'alphabet est situé entre U+0041 et U+007A. Ces caractères tiennent dans un octet (8 bits) dans le code ASCII. Pour réduire la tailles des caractères courants, l'encodage UTF-8 permet de définir les caractères entre U+0000 et U+007F dans un seul octet. Mais vous n'avez pas à vous soucier de l'UTF-8 dans les programmes Small Basic. Les opérations comme Text.GetLength, Text.GetSubText, Text.GetSubTextToEnd, et Text.GetIndexOf converti le texte UTF-8 pour chaque caractère Unicode.
Caractères pour les Jeux
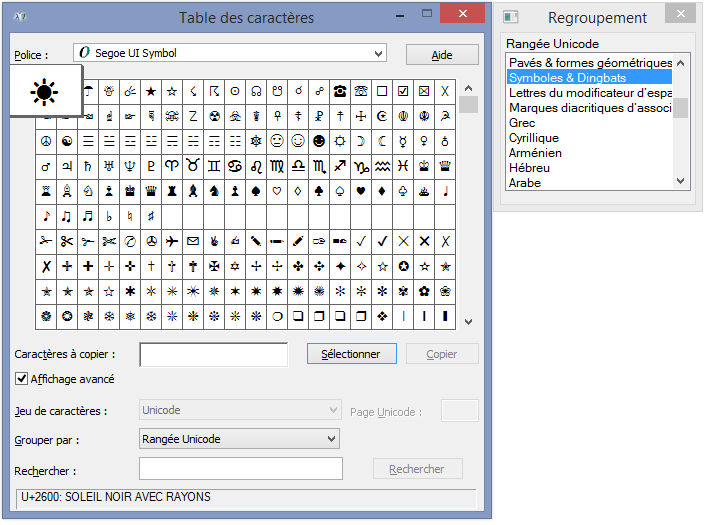
La police "Lucida Sans Unicode" et quelques autres polices contiennent les caractères emoji qui sont adaptés aux programmes de type jeu. L'image de la table de caractères montrée plus haut affichent ces caractères. Vous pouvez les voir en suivant la procédure suivante. Vous pourrez y trouver les autres caractères disponibles pour votre jeu.
- Lancer le programme "Table des caractères".
- Sélectionner la police "Lucida Sans Unicode".
- Cocher la case "Affichage avancé".
- Sélectionner "Rangée Unicode" dans "Grouper par".
- Sélectionner "Symboles & Dingbats" dans la fenêtre de "Regroupement".
Conseils concernant les Jeux de Caractères
Faîtes attention aux polices. L'Unicode possède énormément de caractères mais la plupart des polices ne les possèdent pas tous. Certaines polices affichent un glyphe différent pour un même caractère. Et certaines polices ne sont pas installées dans le système Windows, toutefois elles peuvent l'être avec des applications. Les programmes Small Basic peuvent publiés, par conséquent ils peuvent être exécutés dans différents environnements, certains avec les polices Office d'installées, d'autres pas, ou encore certains ne possèdent que les polices Mac. Vous avez plus de détail sur les polices dans cet article.
Dans la fenêtre TextWindow, le jeu de caractères n'est pas l'Unicode. Tout dépend de la langue en cours de Windows, par exemple code ASCII aux Etats-Unis, code Shift-JIS au Japon.
Sample Code
Table Code ASCII
ID Programme VQX212. Ce programme affiche les caractères entre U+0000 et U+007F.
Hexadecimal Dump
ID Programme XWT217. Ce programme lit un fichier texte UTF-8 et simule l'encodage UTF-8 de ce fichier. Avant d'exécuter ce programme, retirer les commentaires automatiques au niveau des appels à l'objet File.
Exemple de Symbole
ID Programme QZS270. Ce programme affiche les symboles dans les polices Webdings, Wingdings et Unicode.
Obtenir le Caractère depuis l'Unicode
ID Programme RPZ143-2. Ce programme affiche un caractère dans un champ texte pour un Unicode spécifique. Vous pouvez ainsi obtenir (en le copiant)le caractère. Ce programme détermine si la table SMP n'est pas pas supportée par Small Basic. Seuls les derniers 16 bits du code est utilisé.
Voir Aussi
Autres Langues
- Article original : Small Basic: Character Set - Unicode (en-US)