SharePoint 2013 - Recherche - Le Continuous Crawl (fr-FR)
Introduction
Cet article présente un nouveau type de crawl apparu dans SharePoint 2013 : le "Continuous Crawl".
Il fait partie d’une série concernant la recherche de SharePoint 2013 :
- SharePoint 2013 - Recherche - Création et configuration d’une application de service de recherche
- SharePoint 2013 - Recherche - Création d’un centre de recherche
- SharePoint 2013 - Recherche - Le Continuous Crawl (Cet article)
- SharePoint 2013 - Recherche - Gérer les synonymes grâce au thésaurus
- SharePoint 2013 - Recherche - Présentation des Query Rules
- SharePoint 2013 - Recherche - Présentation des Query Suggestions
- SharePoint 2013 - Recherche - Présentation du contexte utilisateur (User Segmentation)
- SharePoint 2013 : Recherche - Gérer l'extraction des noms de société (Publication à venir)
Rappels sur les types de crawls sous SharePoint 2010 /2007
Dans ces versions de SharePoint, vous avez à votre disposition 2 types de crawl, configurables par source de contenu :
- Full : Crawle tout le contenu,
- Incrémental : Crawle le contenu ayant été modifié depuis le dernier crawl.
http://spasipe.files.wordpress.com/2012/09/162.png?w=595
{kind=link}
L’inconvénient de ces crawls, c’est qu’une fois lancé, il ne vous est pas possible d’en lancer un second en parallèle (sur la même source de contenu), et donc du contenu modifié entre temps aura besoin d’attendre la fin du crawl en cours (et d’un autre crawl) pour être intégré à l’index, et donc pour pouvoir être trouvé via la recherche.
Par exemple :
- Un crawl A "Incrémental" est lancé et va durer 30 mn,
- Au bout de 5 mn de crawl un item déjà crawlé est modifé, et a besoin qu’un crawl "B" soit lancé,
- Cet item devra encore attendre au minimum 25 mn pour être intégré à l’index.
Du coup, on ne peut pas garder un index à jour des dernières modifications, car un temps de latence s’invite dans le processus.
Il est possible que dans la plupart des cas ce fonctionnement convienne à vos clients, mais pour ceux qui veulent pouvoir rechercher leur contenu immédiatement ou presque après leur intégration dans SharePoint il existe désormais une solution nouvelle dans SharePoint 2013 : le "Continuous Crawl".
Le Continuous Crawl
Le "Continuous Crawl" est donc un type de crawl qui a pour but de maintenir l’index aussi à jour que possible.
Son fonctionnement est simple : une fois activé, il va lancer des crawls à intervalles réguliers. La différence majeure avec des crawls incrémentaux, c’est qu’ici les crawls peuvent s’exécuteren parallèle, et n’attendent donc pas que le crawl précédent soit terminé pour se lancer.
Les points à noter :
- Le "Continuous Crawl" n’est disponible que pour les sources de contenu de type "Sites SharePoint",
- Par défaut, un nouveau crawl est lancé toutes les 15 mn, mais l’administrateur SharePoint peut modifier cet intervalle via le cmdlet PowerShell Set-SPEnterpriseSearchCrawlContentSource,
- Une fois lancé, un "Continuous Crawl" ne peut être mis en pause ou arrêté; on peut par contre le désactiver.
Si nous reprenons notre exemple plus haut avec des "Continuous Crawl" :
- Un crawl A se lance et va durer 30 mn,
- Au bout de 5 mn de crawl un item déjà crawlé est modifé, et a besoin qu’un crawl "B" soit lancé,
- Le crawl "B" se lance dans (15 – 5) mn,
- Du coup cet item devra ne devra alors attendre au minimum que 10 mn (au lieu de 25 mn) pour être intégré à l’index.
Comment l’activer
1. Dans l’administration centrale, cliquez sur votre application de service de recherche, puis dans le menu sur "Content Sources"
http://spasipe.files.wordpress.com/2012/09/54.png?w=595
{kind=link}
2. Cliquez sur "New Content Source" dans le menu
http://spasipe.files.wordpress.com/2012/09/49.png?w=595
{kind=link}
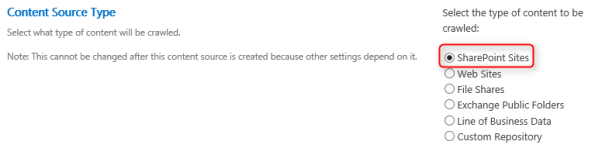
3. Choisissez "SharePoint Sites" comme type
http://spasipe.files.wordpress.com/2012/09/37.png?w=595
{kind=link}
4. Sélectionnez "Enable Continuous Crawls"
http://spasipe.files.wordpress.com/2012/09/29.png?w=595
{kind=link}
5. La source est créée, son statut est alors "Crawling Continuous"
http://spasipe.files.wordpress.com/2012/09/65.png?w=595
{kind=link}
Via l’administration centrale
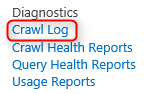
1. Cliquez sur votre application de service de recherche puis sur "Crawl Log" dans la section "Diagnostics".
http://spasipe.files.wordpress.com/2012/09/75.png?w=595
{kind=link}
2. Sélectionnez votre source de contenu dans la liste et cliquez sur "View crawl history"
http://spasipe.files.wordpress.com/2012/09/85.png?w=595
{kind=link}
3. Les données relatives au(x) crawls s’affiche(nt) – Il y a 11 autres colonnes à droite de "Duration" non affichées sur cette copie d’écran
http://spasipe.files.wordpress.com/2012/09/102.png?w=595
{kind=link}
Via PowerShell
1. Lancez la commande suivante :
$SearchSA = "Search Service Application"
Get-SPEnterpriseSearchCrawlContentSource -SearchApplication $SearchSA | select *
http://spasipe.files.wordpress.com/2012/09/251.png
{kind=link}
Impact sur les performances du serveur
L"impact d’un "Continuous Crawl" sera le même que celui d’un crawl incrémental.
Au niveau de l’exécution en parallèle des crawls, les "Continuous Crawl" respectent les paramètres définis au niveau du "Crawler Impact Rule" qui contrôle le nombre maximum de requêtes pouvant être exécutées par le serveur (8 par défaut).
http://spasipe.files.wordpress.com/2012/09/241.png?w=600&h=165
{kind=link}