Sobrecarga de email: Utilizar aprendizaje automático para manejar mensajes y compromisos

Por: Editor de Microsoft blog
Mientras el email continua no sólo como un importante medio de comunicación sino también como un registro oficial de información y una herramienta para manejar tareas, citas, y colaboraciones, encontrar el sentido de todo lo que se mueve dentro y fuera de nuestras bandejas de entrada se hará más complicado. La buena noticia es que hay un método para la locura que significa mantenerse al día de su email, y los investigadores de Microsoft trazan sobre este comportamiento para crear herramientas que apoyen a los usuarios. Dos equipos que trabajan en el espacio presentaron algunos documentos en la Conferencia Internacional de Búsqueda Web y Minería de Datos ACM, del 11 al 15 de febrero de 2019 en Melbourne, Australia.
“Identificar los emails que necesitas para prestar atención es una tarea desafiante”, comentó Ryen White, investigador asociado y gerente de investigación de Microsoft Research, que maneja un equipo de alrededor de una docena de científicos e ingenieros y por lo general recibe a diario entre 100 y 200 emails. “En la actualidad, hacemos mucho de eso por nuestra cuenta”.
De acuerdo con McKinsey Global Institute, los profesionales pasan 28 por ciento de su tiempo en el email, así que herramientas meditadas de soporte tienen el potencial de hacer una diferencia tangible.
“Intentamos traer aprendizaje automático para dar sentido a la enorme cantidad de datos para hacerte más productivo y eficiente en tu trabajo”, comentó Ahmed Hassan Awadallah, investigador senior y gerente de investigación. “La eficiencia podría venir de una mejor capacidad de manejar el email, responder más rápido a la gente, no perderse cosas que de otro modo te podrías perder. Si fuéramos capaces de ahorrar algo de ese tiempo para que lo pudieran utilizar para su función actual de trabajo, eso sería increíble”.
Aplazamiento de email: Decidir ahora o más tarde
Awadallah ha estudiado la relación entre los individuos y su email por años, ha explorado cómo el aprendizaje automático puede apoyar mejor a los usuarios en sus respuestas de email y ayudar a hacer más accesible la información en las bandejas de entrada. Durante esos estudios, él y sus compañeros investigadores comenzaron a notar un comportamiento variante entre los usuarios. Algunos abordaban las tareas relacionadas con un email de manera inmediata, mientras que otros regresaban a los mensajes varias veces antes de actuar. Las observaciones los llevaron a preguntarse: ¿Cómo manejan sus mensajes los usuarios, y cómo podemos ayudarlos a hacer el proceso más eficiente?
“Existe este término llamado ‘sobrecarga de email’, donde tienes una gran cantidad de información que fluye hacia tu bandeja de entrada e intentas mantenerte al día con todos los mensajes entrantes”, explicó Awadallah, “y las personas usan estrategias diferentes para lograrlo”.
En “Characterizing and Predicting Email Deferral Behavior” (Calificar y Predecir el Comportamiento de Aplazamiento de Email), Awadallah y sus coautores revelan los trabajos internos en esa estrategia común: el aplazamiento de email, el cual definen como ver un email pero esperar un tiempo para abordarlo.
La meta del equipo se dividió en dos partes: obtener un profundo entendimiento del comportamiento de aplazamiento y construir un modelo predictivo que pudiera ayudar a los usuarios en sus decisiones de aplazamiento y en sus respuestas de seguimiento. El equipo, una colaboración entre Awadallah, Susan Dumais, y Bahareh Sarrafzadeh, de Microsoft Research, creó el documento y un pasante en ese entonces, y Christopher Lin, Chia-Jung Lee, y Milad Shokouhi del grupo de asistente e inteligencia de Microsoft Search, dedicaron una importante cantidad de recursos a este.
“IA y aprendizaje automático deberían estar inspirados por el comportamiento que la gente realiza en el momento”, comentó Awadallah.
[caption id="attachment_20915" align="aligncenter" width="597"] La probabilidad de aplazar un email basado en la carga de trabajo del usuario es medida por el número de emails no manejados. El número de emails no manejados es una de las muchas funciones que Awadallah y sus coautores usaron para entrenar a su modelo de predicción de aplazamiento.[/caption]
La probabilidad de aplazar un email basado en la carga de trabajo del usuario es medida por el número de emails no manejados. El número de emails no manejados es una de las muchas funciones que Awadallah y sus coautores usaron para entrenar a su modelo de predicción de aplazamiento.[/caption]
El equipo entrevistó a 15 sujetos y analizó los registros de email de 40 mil usuarios anónimos, para descubrir que la gente aplaza por varias razones: Necesitan más tiempo y recursos para responder de los que tienen en ese momento, o se encuentran atrapados en tareas más inmediatas. También factorizaron quién es el remitente y cuántos otros han sido copiados. Encontraron que algunas de las razones más interesantes se encuentran alrededor de la percepción y los límites, retrasar o no para establecer expectativas sobre qué tan rápido responden a los mensajes.
Los investigadores utilizaron esta información para crear un conjunto de funciones, como longitud del mensaje, número de emails sin responder en una bandeja de entrada, y si un mensaje fue generado por una persona o una máquina, para entrenar un modelo que predijera si un mensaje es aplazado. El modelo tiene el potencial de mejorar de manera significativa la experiencia de email, comentó Awadallah. Por ejemplo, los clientes de email podrían utilizar este modelo para recordar a los usuarios sobre los mails que han aplazado o que han olvidado, para ahorrarles el esfuerzo que tendrían que pasar en búsqueda de esos email y reducir la probabilidad de perderse los importantes.
“Si has decidido dejar un email para después, en muchos casos, sólo confías en tu memoria o en controles más primitivas que tu cliente de email brinda como marcar tu mensaje o marcarlo como no leído, y aunque estas estrategias son útiles, hemos encontrado que no brindan el soporte suficiente para los usuarios”, mencionó Awadallah.
Detección de compromiso: Una promesa es una promesa
Entre la avalancha de los emails entrantes se encuentran mensajes salientes que contienen promesas que hacemos, promesas de brindar información, crear reuniones, o dar seguimiento con colegas, y perder la pista de estas tiene sus ramificaciones.
“Cumplir con tus compromisos es muy importante en los ambientes colaborativos y ayuda a construir tu reputación y establecer confianza”, comentó Ryen White.
Las herramientas actuales de detección de compromisos, como las que están disponibles con Cortana, son muy efectivas, pero hay espacio para más progreso. White, el autor líder Hosein Azarbonyad, que era pasante en Microsoft al momento que se realizaba esta labor, y Robert Sim, coautor y director de ciencias aplicadas de Microsoft Research, busca enfrentar este obstáculo en particular en su documento “Domain Adaptation for Commitment Detection in Email” (Adaptación de Dominio para Detección de Compromisos en Email): prejuicios en los conjuntos de datos disponibles para entrenar modelos de detección de compromisos.
El acceso para los investigadores está por lo general limitado por los cuerpos públicos, que tienden a ser específicos de la industria a la que pertenecen. En este caso, el equipo utilizó conjuntos públicos de datos de email de la compañía de energía Enron y una startup de tecnología no específica a la que se nombró “Avocado”. Encontraron una disparidad significativa entre los modelos entrenados y evaluados en la misma colección de emails y modelos entrenados en una colección y aplicados a otra; el modelo más reciente también falló en su labor.
“Queremos aprender modelos transferibles”, explicó White. “Esa es la meta, aprender algoritmos que puedan ser aplicados a problemas, escenarios, y cuerpos que estén relacionados pero que son diferentes a aquellos utilizados durante el entrenamiento”.
Para conseguir esto, el grupo volteó hacia la transferencia de aprendizaje, que ha sido efectiva en otros escenarios donde los conjuntos de datos no son representativos de los ambientes en los cuales han sido implementados al final. En su documento, los investigadores entrenan sus modelos para remover sesgos al identificar y devaluar cierta información a través de tres enfoques: adaptación a nivel de característica, adaptación a nivel de muestra, y un enfoque de aprendizaje profundo adverso que utiliza un codificador automático.
Los emails contienen una variedad y número de palabras y frases, algunas con probabilidad de estar más relacionadas con un compromiso que otras, como “Haré”, “Voy a hacer”, “Te confirmo”. En el cuerpo de Enron, las palabras específicas al dominio como “Enron”, “gas”, y “energía” podrían tener un sobrepeso en cualquier modelo entrenado a partir de estas. La adaptación a nivel función busca reemplazar o transformar estos términos específicos de dominio, o funciones, con similitud en funciones específicas de dominio en el dominio objetivo, explica Sim. Por ejemplo, “Enron” podría ser reemplazada con “Avocado”, y “pronóstico de energía” podría ser reemplazado con un término relevante para la industria tecnológica. Mientras tanto, el nivel de muestra busca elevar emails en el conjunto de datos entrenado que se asemeje a emails en el dominio objetivo, y degrada aquellos que no son muy similares. Así que si un email de Enron es “parecido a Avocado”, los investigadores le darán más peso durante el entrenamiento.
[caption id="attachment_20925" align="alignleft" width="733"]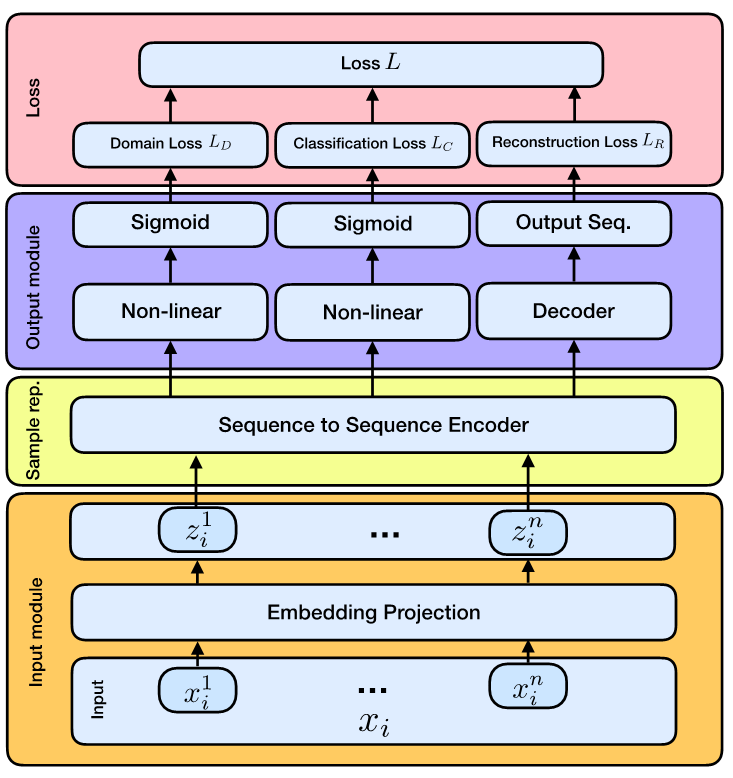 Esquema general del modelo propuesto de auto codificación neural utilizado para detección de compromiso[/caption]
Esquema general del modelo propuesto de auto codificación neural utilizado para detección de compromiso[/caption]
La más reciente, y exitosa, de las tres técnicas es el enfoque de aprendizaje profundo adverso, el cual en adición a entrenar el modelo para reconocer compromisos, también lo entrena para desempeñarse de manera deficiente al distinguir entre los emails en los que es entrenado y los emails que va a evaluar; este es el aspecto adverso. En esencia, la red recibe retroalimentación negativa cuando indica una fuente de email, y la entrena para que sea mala para reconocer de qué dominio particular viene el email. Esto tiene el efecto de minimizar o remover funciones específicas de dominio por parte del modelo.
“Hay algo contrario a la lógica en tratar de entrenar la red para que sea muy mala en un problema de clasificación, pero en realidad ese es el impulso que ayuda a dirigir la red para que haga lo correcto para nuestra tarea principal de clasificación, que es, este es un compromiso o no”, comentó Sim.
Impulsar a los usuarios a que consigan más
Los dos documentos están alineados con la meta mayor de Microsoft de impulsar a los individuos a que consigan más, a través de aprovechar una capacidad de ser más productivos en un espacio lleno de oportunidad para una mayor eficiencia.
White, que reflexiona en su propio uso de email, el cual lo encuentra en interacción frecuente con su correo durante el día, cuestiona el costo-beneficio de este comportamiento.
“Si lo piensas de manera racional, es como, ‘Vaya, esto es algo que ocupa mucho de nuestro tiempo y atención. ¿En verdad recibimos el retorno de esa inversión?’”, comenta.
Él y otros investigadores de Microsoft están confiados en que pueden ayudar a los usuarios a sentirse mejor con la respuesta a esa pregunta con la exploración continua de las herramientas necesarias para apoyarlos.