SQL Server 2005 High-Availability Options (Distilled)
Have you ever been asked by a high-level architect or CIO what Microsoft's approach is to a given scenario? If you have, then you know the challenges faced because as you read through MSDN and TechNet and even at the Microsoft.com site level, you find a lot of material which is very large and complex. Trying to distill things, particularly multiple things into a short executive-type summary is difficult. It's not to say that the information isn't there, it's just that there is so much of it and it is scattered around.
I was asked earlier this week to provide Microsoft's options for SQL Server high-availability. Below is what I cobbled together from MSDN - there's not much original material in here, but hopefully you'll find this helpful, if you need to provide the same type of information in a distilled format. I wrote this for SQL 2005. I confess I haven't gotten up to speed enough on SQL 2008 to know if there are any significant modifications needed, but I suspect that most of this should be application for 2008 as well.
Microsoft SQL Server High Availability Architecture
Microsoft provides an architectural framework to support a high availability (HA) environment known as the Windows Server System Reference Architecture. It is a framework of best practices that leverage the high availability technologies built into the Microsoft line of products including SQL Server as well as Microsoft .NET Application Servers. It encompasses the following products and technologies:
- Database Engine
- SQL Server Database – Failover Clustering, Mirroring, Log Shipping, Replication
- SQL Server Analysis Services – Failover Clustering
- SQL Server Notification Services – Failover Clustering
- .NET Application Servers - Network Load Balancing Farm, Application Pooling approach with High-Availability Back-end SQL Database.
- SQL Server Reporting Services
- Microsoft .NET Framework Web Services (IIS/Component Enterprise Services)
- Microsoft Office SharePoint Server (MOSS) and Windows SharePoint Services
- BizTalk
There are several options available with SQL Server in regards to high availability. The relevant technologies are:
SQL Server Failover Clustering
- Failover clustering provides high-availability support for an entire instance of SQL Server. A failover cluster is a combination of one or more nodes, or servers, with two or more shared disks. Applications such as SQL Server and Notification Services are each installed into a Microsoft Cluster Service (MSCS) cluster group, known as a resource group. At any time, each resource group is owned by only one node in the cluster. The application service has a virtual name that is independent of the node names, and is referred to as the failover cluster instance name. An application can connect to the failover cluster instance by referencing the failover cluster instance name. The application does not have to know which node hosts the failover cluster instance.
- A SQL Server failover cluster instance appears on the network as a single computer, but has functionality that provides failover from one node to another if the current node becomes unavailable. For example, during a non-disk hardware failure, operating system failure, or planned operating system upgrade, you can configure an instance of SQL Server on one node of a failover cluster to fail over to any other node in the disk group.
- A failover cluster protects against server failure, but does not protect against disk failure. Use failover clustering to reduce system downtime and provide higher application availability.
- Failover clustering does not protect against a geographic disaster and is intended for high availability within a data center. SQL Mirroring, SQL Replication or Log Shipping can be used to augment Failover Clustering for geographic fault tolerance.
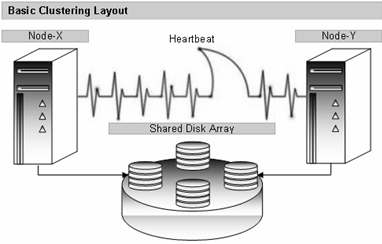
Figure 1 - SQL Clustering
SQL Server Database Mirroring
- Database mirroring is primarily a software solution to increase database availability by supporting almost instantaneous failover. Database mirroring can be used to maintain a single standby database, or mirror database, for a corresponding production database that is referred to as the principal database. Database mirroring provides geographic failover, since the mirrored database may be in an entirely different geographic location.
- The mirror database is created by restoring a database backup of the principal database with no recovery. This makes the mirror database is inaccessible to clients. However, it is possible to use it indirectly for reporting purposes by creating a database snapshot on the mirror database. The database snapshot provides clients with read-only access to the data in the database as it existed when the snapshot was created.
- Each database mirroring configuration involves a principal server that contains the principal database, and a mirror server that contains the mirror database. The mirror server continuously brings the mirror database up to date with the principal database.
- Database mirroring runs with either synchronous operation in high-safety mode, or asynchronous operation in high-performance mode. In high-performance mode, the transactions commit without waiting for the mirror server to write the log to disk, which maximizes performance. In high-safety mode, a committed transaction is committed on both partners, but at the risk of increased transaction latency.
- In its simplest configuration, database mirroring involves only the principal and mirror servers. In this configuration, if the principal server is lost, the mirror server can be used as a warm standby server, with possible data loss. High-safety mode supports an alternative configuration, high-safety mode with automatic failover. This configuration involves a third server instance, known as a witness, which enables the mirror server to act as a hot standby server. Failover from the principal database to the mirror database typically takes a few seconds.
- Database Mirroring can be integrated with Failover cluster to provide a geographic failover layer on top of a local failover approach. Typically, when mirroring is used with clustering, the principal server and mirror server both reside on clusters, with the principal server running on the failover clustered instance of one cluster and the mirror server running on the failover clustered instance of a different cluster. If a cluster failover makes a principal server temporarily unavailable, client connections are disconnected from the database. After the cluster failover completes, clients can reconnect to the principal server on the same cluster, or on a different cluster or an unclustered computer, depending on the operating mode

Figure 2 - SQL Mirroring

Figure 3 - SQL Mirroring integrated with Clustering
SQL Server Mirroring/Clustering Integration Solution
SQL Server Log Shipping
- Like database mirroring, log shipping operates at the database level. Log shipping can be used to maintain one or more warm standby databases, referred to as secondary databases, for a corresponding production database that is referred to as the primary database. Each secondary database is created by restoring a database backup of the primary database with no recovery, or with standby. Restoring with standby permits the resulting secondary database to be used for limited reporting purposes.
- A log shipping configuration includes a single primary server that contains the primary database, one or more secondary servers that each have a secondary database, and a monitor server. Each secondary server updates its secondary database at regular intervals from log backups of the primary database. Log shipping involves a user-modifiable delay between when the primary server creates a log backup of the primary database and when the secondary server restores the log backup. Before a failover can occur, a secondary database must be brought fully up-to-date by manually applying any unrestored log backups.
- Log shipping provides the flexibility of supporting multiple standby databases. If you require multiple standby databases, you can use log shipping alone or as a supplement to database mirroring. When these solutions are used together, the current principal database of the database mirroring configuration is also the current primary database of the log shipping configuration.
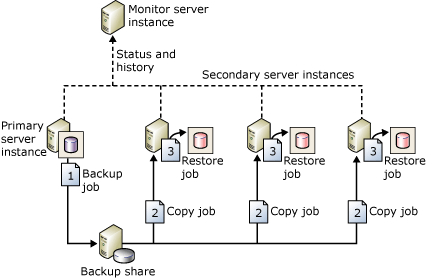
Figure 4 - SQL Log Shipping
SQL Server Replication
- Replication uses a publish-subscribe model, allowing a primary server, referred to as the Publisher, to distribute data to one or more secondary servers, or Subscribers. Replication allows real-time availability and scalability across these servers. It supports filtering to provide a subset of data at Subscribers, and also allows partitioned updates. Subscribers are online and available for reporting or other functions, without query recovery. SQL Server offers three types of replication: snapshot, transactional, and merge. Transactional replication provides the lowest latency and is most commonly used for high availability.

Technorati Tags: SQL Server,High Availabilty,Database Mirroring,Clustering,Log Shipping,Replication
Figure 5 - SQL Server Transactional Replication
References
· https://www.microsoft.com/windowsserver2003/wssra/default.mspx - Microsoft Windows Server System Reference Architecture
· https://msdn.microsoft.com/en-us/library/ms190202.aspx - SQL Server 2005 Books Online: Configuring High Availability