Run your own Exchange Server Health Check.... Part 6
Active Directory
Generally our main concern here is if the Global Catalog servers are responding quickly to LDAP queries from the Exchange Servers. There are obviously other issues to do with security for example but these are rare and you are likely to already be aware of them. Therefore the first bit of information to find out is the number of GC's compared to the number of Exchange Servers. More specifically we are talking about the number of Exchange Server physical processors and the number of GC physical processors. The recommended practise is to maintain a 4:1 ratio between Exchange server processors and global catalog server processors of similar speed. (This information is gathered and recorded by ExBPA.)
Presuming that you meet this best practise the next thing to consider is the AD site topology. I like to use diagnostics logging to determine how each Domain Controller has been classified by DSAccess. If you increase diagnostics logging as described in this article; 'Event ID 2080 from MSExchangeDSAccess', you will see an event logged every 15 minutes on each server which logs the results from the topology discovery process. Look at the 'In-site:' section in each event to see which domain controllers are available in the AD site which the Exchange server belongs to.
The second column (roles) shows whether or not the particular server in the list can be used as a configuration domain controller (column value C), a domain controller (column value D), or a global catalog server (column value G) for this particular Exchange server. We want to see CDG in this column for all servers 'In-site:' if possible.
Once we have determined which servers are using which DC's and that we have enough DC's we can use Performance Monitor to see the response time from the 'In-site:' GC's. The screenshot below is typical. This shows the response time for all DC's available to the Exchange Servers including those that are 'Out-of-site:'. The regular peaks are a result of the 15 minute topology discovery process. The high peaks should due to slow response times from domain controllers which are 'Out-of-site:'.
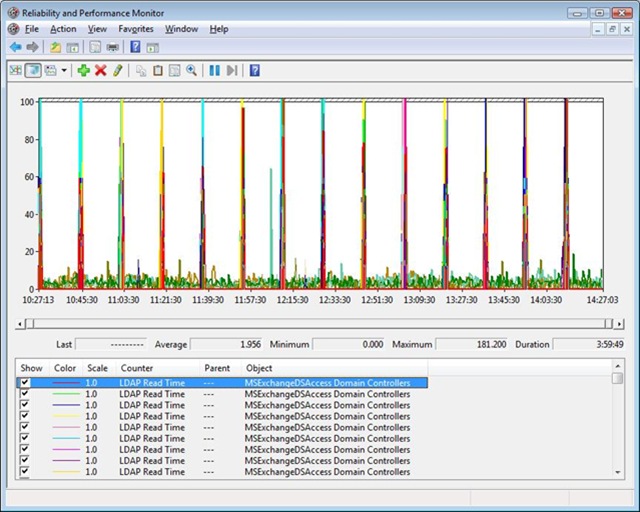
If we remove the 'Out-of-site:' DC's the picture looks like this:
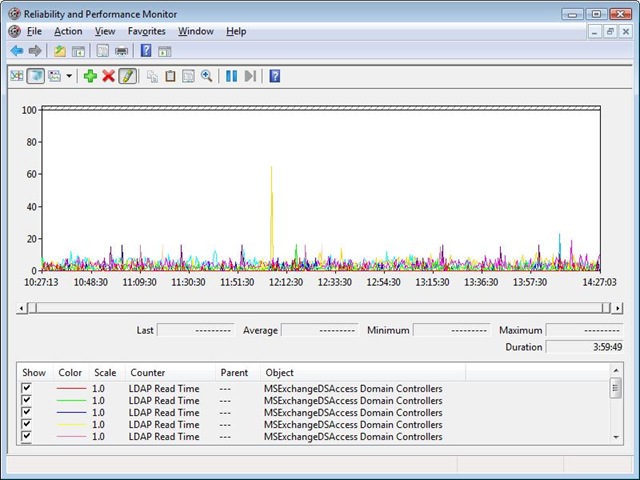
I would also use this information and compare it with any warnings triggered by ExBPA including (Round-trip times to global catalog server are taking more than 100 ms & Round-trip times to global catalog server are taking more than 10 ms). I would want to verify that any warnings match what we are seeing above i.e. that they are for remote servers. If there are any issues with the performance of the DC's then there are some tips in the ExBPA article and in the 'Troubleshooting Microsoft Exchange Server Performance' whitepaper.
The other issue that I come across all the time is when DSAccess has been hard-coded to use specific Domain Controllers. It is recommended that you use the default setting of automatic topology discovery to take advantage of global catalog failover. In 99% of cases the Exchange Servers will only use 'Out-of-site:' DC's if the 'In-site:' DC's are all unavailable. If you overwrite this then this automatic failover will not take place. If you lose all DC's that you have specified in the manual override Exchange will fail. This issue is highlighted by ExBPA with the rule 'DSAccess has been hard-coded'.
Quick Summary
If you have followed all the steps in this series of blogs then I hope you now have a list of issues and a lot of new information about your environment. I would recommend getting all relevant parties together to build and prioritize the list of issues that were identified in this process. Using your change control procedures where appropriate work through the list of issues and meet with the team on a regular basis to report on where you've got to on the list and the impact, if any, that your changes have made.
If you are tracking incidents and Exchange downtime it should ultimately be possible to prove that this work has improved the stability and performance of the messaging service. ..well you never know.
Comments
Anonymous
June 12, 2007
PingBack from http://msdnrss.thecoderblogs.com/2007/06/12/run-your-own-exchange-server-health-check-part-6-2/Anonymous
June 12, 2007
PingBack from http://msdnrss.thecoderblogs.com/2007/06/12/run-your-own-exchange-server-health-check-part-6-2/Anonymous
June 12, 2007
PingBack from http://msdnrss.thecoderblogs.com/2007/06/12/run-your-own-exchange-server-health-check-part-6/Anonymous
June 12, 2007
PingBack from http://msdnrss.thecoderblogs.com/2007/06/12/run-your-own-exchange-server-health-check-part-6-3/Anonymous
June 12, 2007
PingBack from http://msdnrss.thecoderblogs.com/2007/06/12/run-your-own-exchange-server-health-check-part-6-3/