Designing for CAS and Site Resilience...
One of the challenges that Exchange 2007 and the CAS role introduces is how to design for site resilience. Companies are going to want a solution that makes the most efficient use of the WAN, provides as seamless as possible a return to normal\full operation in the event of the loss of a single data centre, both for the administrators responsible for the support of the infrastructure, and for the user community who are attempting to access their mailboxes. There are going to be a lot of different approaches to this and it may be that a lot of the decisions are made for you due to the underlying network for example, but as far as I can see it there are 3 obvious options...
The first is the 3 site topology which I've tried to illustrate below...
DESIGN 1
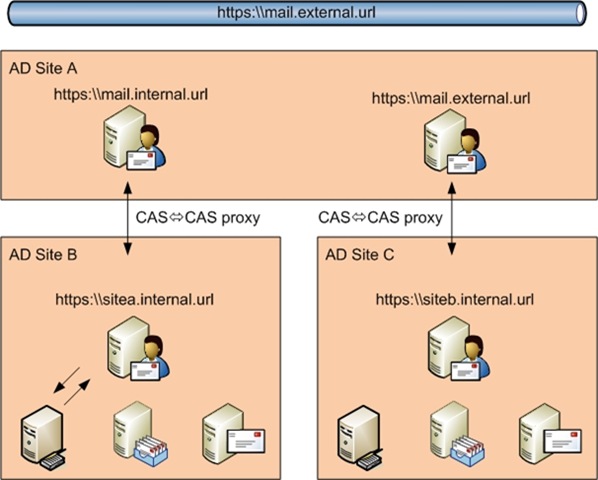
The main advantage of this is the unified namespace that is advertised by a layer of CAS servers sitting in both data centres. This means that in the event of a site failure, and providing there are sufficient CAS in each location to handle the increase in traffic, there will always be a CAS in Site A available to proxy traffic to and from CAS servers in the remaining site. The advertised external url will not change for any clients even after the loss of a site. This design has other advantages in that internal message transport is logically controlled via your AD site topology. (Of course a message from outside may cross the WAN twice to reach its destination. --> 1st mail relay [data centre B] --> HT [data centre A] --> HT [data centre B])
Their are of course a number of obvious disadvantages, not least the fact that you will probably need to deploy more CAS role servers. Another disadvantage is the fact that all CAS access from the outside is CAS <=> CAS proxy ..and the fact that this proxying could occur across your WAN link. I cannot find a great deal of information about the impact of this design on performance. For example would it take longer in this scenario to download an attachment? It is an extra step so logic says it will. There are some internal discussions going on at the moment about this issue and I would expect to see some more information about the sort of hit you can expect to be published soon.
DESIGN 2
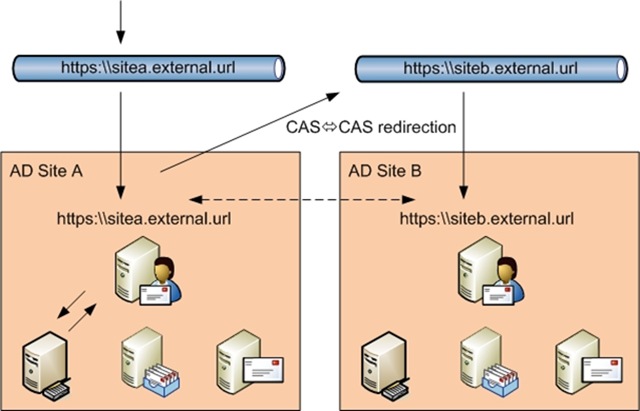
With this second design I could advertise two url's to my user community. If the users are pretty savvy they will remember their url, connect directly to the correct data centre and CAS role server and access their mailbox successfully. If they enter the second url for site A when their mailbox is in Site B they will be redirected to the 'best CAS' i.e. a CAS in the same site to their mailbox. If this CAS has an external url they will be directed back out to the Internet and to this new url. ..a bit clunky because this necessitates logging on twice. ..the first time to determine that they are in another site. But again if the user community are pretty savvy they will remember this new url and use it from then on.
The problem comes, as I see it, when Site A is unavailable because at least 50% of your users will need to enter a different url to that which they know and are used to, in order to get access to their mailboxes. This might be ok to live with as you are in the middle of DR, but I think a lot of customers won't want to go for this approach. Depends on your SLA I guess.
The advantage to this design is that transport is always controlled logically via your AD site topology making most efficient use of your WAN connection. This design also ensures that you don't need to worry too much about CAS <=> CAS proxy.
DESIGN 3
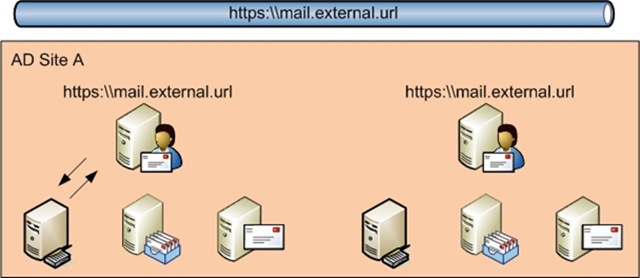
This 3rd design appears the simplest and might actually be the most preferential for a lot of companies designing for site resilience. In particular those companies who can guarantee their Exchange team a dedicated high bandwidth, low latency WAN link between data centres because the main disadvantage of this design is the inefficient use of the WAN. On the face of it any transport decisions, or decisions about which CAS role servers to use by clients, will not be made based on site topology.
However that being said there are ways to limit this traffic. The first is to control transport decisions via the SubmissionServerOverrideList (See a previous blog here). This does increase administrative complexity and reduces fault tolerance to some extent but does mean that a mailbox role server will only use a local Hub Transport server.
You might also be able to control the use of the CAS server by internal clients to some extent by changing the site affinity on the ServiceConnectionPoint objects for autodiscover. If clients with a mailbox in data centre A always join AD sites 1-6, for example, you can alter the default SCP objects so that clients querying AD for their SCP are referred to a list of CAS role servers in Site A. You could use a DNS record on the SCP which resolves to a DNS round-robin of all CAS servers in data centre A to load balance CAS access, and your DR documentation would need to include suitable procedures for updating DNS in the event of the loss of a site.
I think like any design it is very important that you have a good understanding of what can and can't be achieved by the infrastructure which surrounds your messaging infrastructure. I haven't made any mention of ISA, hardware and software load balancing, stretch subnets, certificates etc, etc... This may dictate first and foremost how we design Exchange 2007 for CAS and site resilience...
Comments
- Anonymous
May 29, 2009
PingBack from http://paidsurveyshub.info/story.php?title=dougs-blog-exchange-server-daily-designing-for-cas-and-site-resilience