[Dongclee 2011년 3월 첫 번째 포스팅] SQL 차기 버전 "DENALI"의 HADR은 기존 SQL의 Database Mirroring과 뭐가 다를까요?
이동철입니다.
3월인데 아직도 날씨가 만만치 않네요,,,, 다들 환절기에 감기 조심하세요.
이번 포스팅의 주제는 다름이 아니라, SQL 차기 버전인 "Denali"의 "HADR(High Availability Disaster Recovery)"에 대한 내용입니다. 제가 어플케이션이나 서비스의 고가용성에 대해서 관심이 많은데, Denali의 HADR은 SQL 자체만으로도 상당한 수준의 Disaster Recovery 역할을 수행할 수 있어서 계속 관심을 갖던 기능이었습니다.
Denali 의 CTP 1 버전이 출시되어, 제가 아래와 같이 데모 환경을 구축하고 간단한 설치 및 테스트를 진행해 보았습니다.

위 그림에서도 확인하실 수 있듯이, Denali의 HADR을 구현하기 위해서는 Windows Server Failover Clustering이 선행되어서 구축되어야 하고, Denali는 단일 인스턴스로 설치되어도 무방합니다.
그럼, 이제 HADR은 도대체 어떤 좋은 기능이 있을까요? 제가 HADR의 기본적인 개요를 아래와 같이 소개드려 보겠습니다.
HADR은 SQL Code Name “Denali” 제품에서 소개된 기능입니다. HADR은 Microsoft 사에서 소개할 때, “AlwaysOn 또는 Hadron” 기술이라고 합니다. HADR은 Denali 이전의 SQL 서버 제품들이 제공했던, 데이터베이스 미러링 기술을 계승했을 뿐만 아니라, 좀 더 많은 기술적인 진전이 있는 기능입니다. 일단 기본적으로, HADR은 데이터베이스 미러링과 유사하게 트랜잭션 로그를 전달함으로써 데이터베이스의 물리적인 복제을 기반으로 제공되는 기술입니다. 실제로는, HADR은 “데이터베이스 미러링(Database Mirroring)”과 유사할 뿐만 아니라, 실제적으로 데이터베이스를 복제하기 위해 데이터베이스 미러링에서 사용했던 기술을 동일하게 사용합니다. 즉, HADR을 설정 단계는 “미러링 세션(Mirroring Session)”을 설정하는 단계를 포함하고 있습니다. 또한, HADR을 모니터링 및 설정 단계에 “미러링 엔드포인트(Mirroring Endpoint)”, “카탈로그 뷰(Catalog View)” 및 DMV가 실제 사용됩니다. 이런 점을 고려하면, HADR 과 기존 “데이터베이스 미러링(Database Mirroring)”과의 차이점을 확인할 수 없습니다. 그러나, 아래 3가지 HADR의 구성 요소로 인해 “데이터베이스 미러링(Database Mirroring)”과는 비교할 수 없는 기능을 제공하게 됩니다.
· Availability Groups : Databases with dependencies on one another fail over together, as a group.
· Multiple Secondaries : AlwaysOn will allow for multiple standby replicas for each availability group.
· Readable Secondaries : The standby replicas are accessible for read-only operations.
Availability Groups
“데이터베이스 미러링(Database Mirroring)” 은 각 미러된 데이터베이스가 각각의 개체로 아래와 같이 운영됩니다. 그러나, 실제 어플리케이션들은 종종 하나의 SQL 인스턴스의 여러 갸의 데이터베이스를 사용하도록 개발된 경우가 많습니다. 즉, 이러한 경우에 “데이터베이스 미러링(Database Mirroring)” 기술로 가용성을 높이기 위해서는, 실제 어플리케이션이 사용하는 데이터베이스 모두를 하나의 개체로 운영할 수 있는 방안이 제공되어야 합니다. 그러나, “데이터베이스 미러링(Database Mirroring)” 기술을 사용하면, 하나의 데이터베이스에 “장애 조치(failover)” 가 발생하면, 연관된 다른 데이터베이스들도“장애 조치(failover)” 되도록 복잡한 로직을 별도로 작성해야 합니다.<o:p></o:p>
<o:p></o:p>

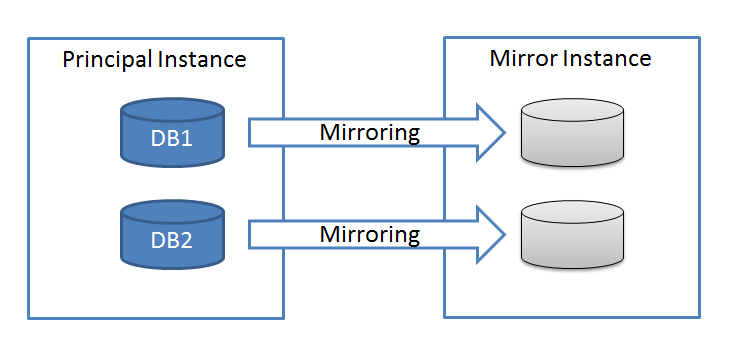{kind=link}
그러나, “HADR”의 Availability Groups 기능을 사용하면, 이러한 고민을 해결할 수 있습니다. 즉, 아래와 같이 특정 어플리케이션에 연관된 모든 데이터베이스를 하나의 그룹으로 묶어서, 특정 하나의 데이터베이스에서 “장애 조치(failover)”가 발생하게 되면, 같은 그룹 내의 데이터베이스도 자동으로 “장애 조치(failover)” 되도록 할 수 있습니다.

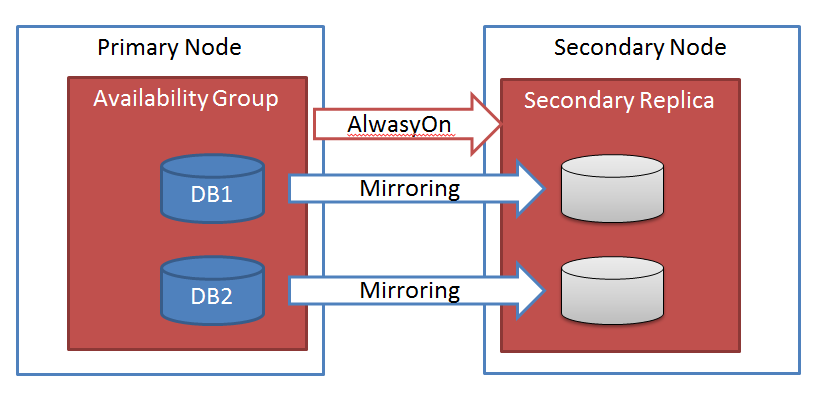{kind=link}
그러나, 여전히Availability Groups 내의 모든 데이터베이스의 복제는 “데이터베이스 미러링(Database Mirroring)” 기술을 사용합니다.
Multiple Secondaries
“데이터베이스 미러링(Database Mirroring)” 기술은 오로지 2개의 SQL 호스트 사이에서만 구성할 수 있습니다. 그러나, 이러한 상황은 실제 운영 환경에서 2개의 SQL 호스트가 동시에 문제가 발생할 경우에는 어플리케이션은 작동할 수 없습니다. 그러나, HADR은 “데이터베이스 미러링(Database Mirroring)” 과는 달리 secondary replica를 여러 개의 호스트에 구성할 수 있습니다. 아래는 multiple secondaries를 구성한 예입니다. 총 4대의 SQL 호스트를 사용하여 여러 개의 Availability Groups에 대해서 다중 호스트에 secondary replica를 구성한 예입니다.

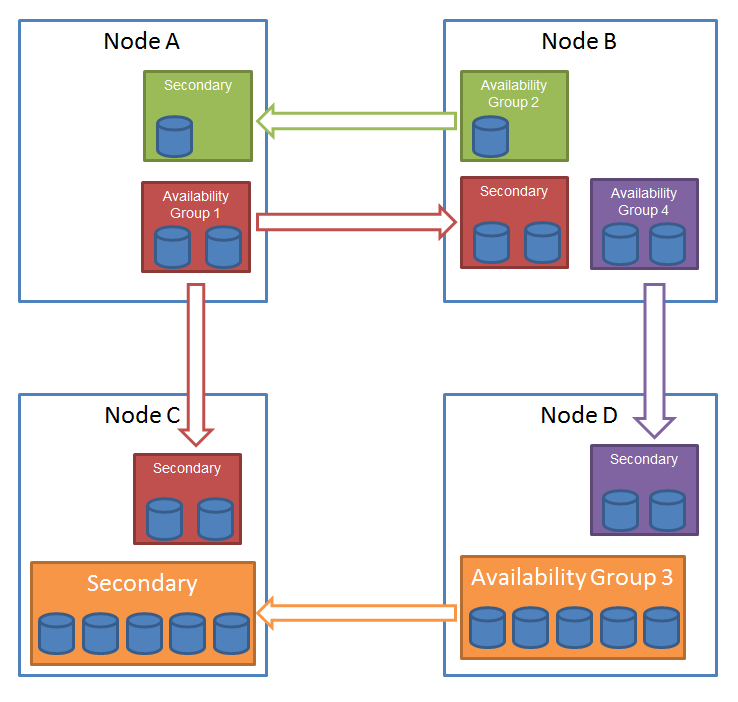{kind=link}
· Availability Group 1 contains 2 databases and 3 nodes of the cluster have joined this availability group. The SQL Server instance on node A is the the primary replica and the ones nodes B and C each host an availability replica.
· Availability Group 2 contains one database, it has the primary availability group running on the SQL Server instance on node B of the cluster and an availability secondary replica on the instance on node A of the cluster.
· Availability Group 3 contains five databases, it has the primary availability group running on the SQL Server instance on node D of the cluster and an availability secondary replica on the instance on node C of the cluster.
· Availability Group 4 contains two databases, it has the primary availability group running on the SQL Server instance on node B of the cluster and an availability secondary replica on the instance on node D of the cluster.
위 4대의 SQL 호스트는 동일 Windows Failover Clustering 내에 구성된 것을 가정합니다.
Readable Secondaries
HADR는 secondary replica에 대해서 실시간 읽기 전용으로 구성할 수 있습니다. 두 번째 Availability Groups 내의 모든 데이터베이스에 대해서 읽기 전용 동작이 가능합니다. 이러한 기능을 잘 활용하면, 읽기 전용 어플리케이션에 대해서 HADR은 Scale-Out 이 가능하도록 할 수 있습니다. “데이터베이스 미러링(Database Mirroring)” 스냅-샷 솔루션과는 달리, HADR은 데이터베이스의 point-in-time 스냅-샷 뷰를 제공함으로써, 읽기 전용secondary replica는 실시간 읽기 쿼리를 수행할 수 있습니다. HADR의 데이터베이스 point-in-time 스냅-샷 뷰 기능은 데이터베이스의 데이터 변경 사항을 실시간으로 반영할 수 있습니다. Secondary replica에 대한 접근은 오로지 읽기만 가능하고, 어떠한 변경도 허용되지 않고, 모든 쿼리는 자동적으로 “snapshot isolation model” 방식으로 수행됩니다 (당연히, lock hint 및 explicitly set isolation level은 무시됩니다). 이러한 방식으로 쿼리가secondary replica에 대해서 수행되기 때문에, 데이터의 일관성이 유지될 수 있습니다.
다음은 HADR의 Scale-Out 읽기 전용 기능을 이용하여 웹 팜의 웹 서버들에게 확장성을 제공해 주는 하나의 예입니다.
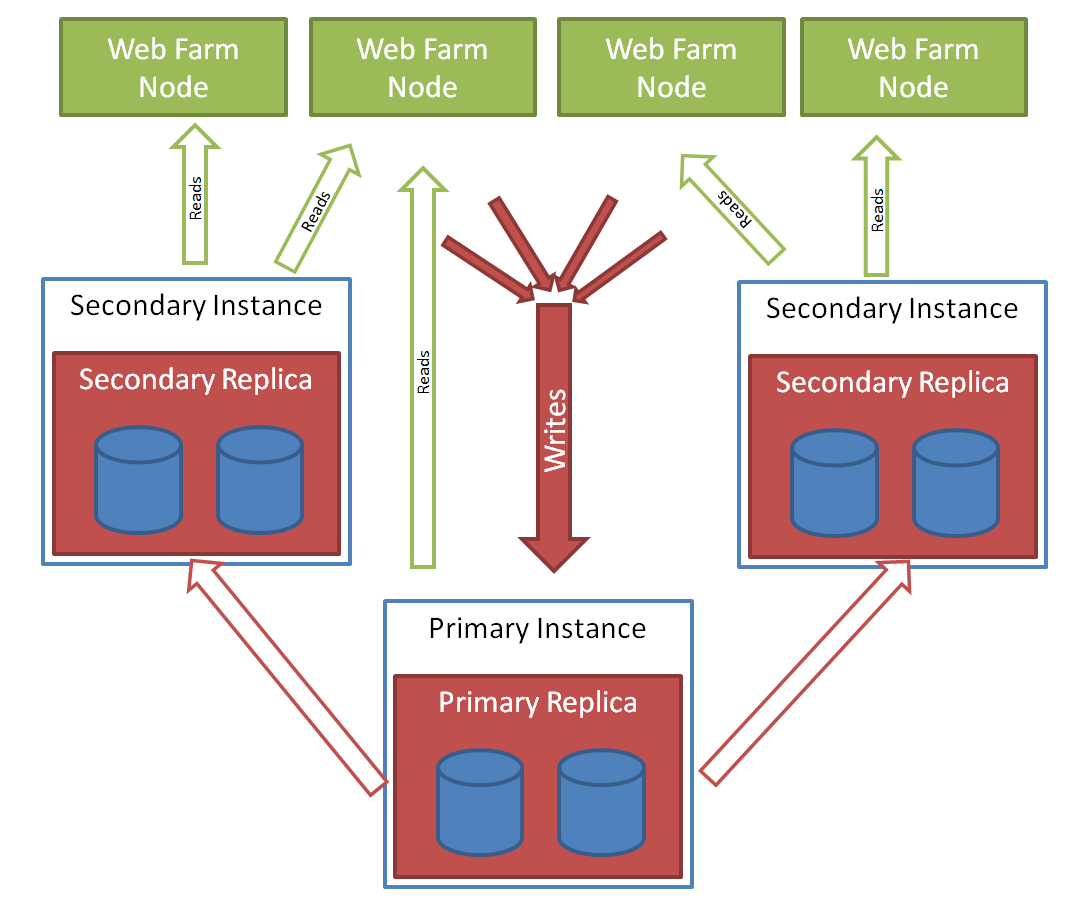{kind=link}

이상과 같이 HADR의 “데이터베이스 미러링(Database Mirroring)”과는 다른 기능에 대해서 살펴 보았습니다. HADR은 “데이터베이스 미러링(Database Mirroring)”과는 완전히 다른 차원의 high availability를 제공합니다. 이제 “데이터베이스 미러링(Database Mirroring)”은 소규모 비즈니스에 적합한 것이고, HADR은 대규모 비즈니스의high availability에 적합합니다. 물론, HADR은 구성하기 위해서는 Availability Groups에 참여하는 모든 모드가 WSFC(Windows Server Failover Clustering)에 참여해야 하는 제약이 있습니다. 이 점을 감안하더라도, HADR은 새로운 차원의high availability를 제공합니다.
이상과 같이 Denali의 HADR 의 기능 및 기본적인 개요에 대해서 살펴 보았습니다.
아직 CTP 1 상태라서 몇 가지 제약점도 있고, 가끔 Failover 테스트도 잘 진행되지 않는 경우도 있습니다. 애교로 봐 줄 수 있죠 ^-^
그럼 이상 이번 포스팅을 마칩니다. 다들 건강하세요