Stream Analytics ジョブをスケールアウトさせるためのポイント
Microsoft Japan Data Platform Tech Sales Team
Azure の Stream Analytics は Event Hubs と併せて使用することにより、IoT や リアルタイムログ収集をスケーラブルでありつつ容易に実現することができる CEP エンジンに該当するサービスとなります。データが増え、処理が複雑になった際にはスケール変更 (Streaming Unit というパラメータ) することにより対応可能ですが、スケーラブルなジョブにするためには実装時に抑えておくべきポイントがあります。今回はそのポイントについて触れます。
Stream Analytics では、データの入力元、出力先、および処理 ( Stream Analytics クエリ言語というSQLライクな言語で定義) をジョブとして作成し実行します。そのジョブをスケールさせるためのパラメータとして前述の Streaming Unit (以降 SU) という単位を使用しますが、ジョブの定義によってはスケールしない可能性があります。処理をスケールさせるためには並列化がポイントとなりますが、Stream Analytics では処理の定義によって複数ノードへの処理の並列化 (以降、並列化) が行われるものと行われないものがありますので以下で整理します。
先ず、入力元、クエリ(処理)、出力先のそれぞれで並列化が可能かを確認する必要があります。
入力
入力元が以下の場合には並列化が可能です。
- EventHub (パーティション キーを明示的に設定する必要があります)
- IoT Hub (パーティション キーを明示的に設定する必要があります)
- BLOB ストレージ
出力
出力先が以下の場合には並列化が可能です。
- Azure Data Lake Storage
- Azure Functions
- Azure テーブル
- BLOB ストレージ
- CosmosDB (パーティション キーを明示的に設定する必要があります)
- EventHub (パーティション キーを明示的に設定する必要があります)
- IoT Hub (パーティション キーを明示的に設定する必要があります)
- Service Bus
出力先が Power BI、SQL Database、SQL Data Warehouse の場合には、出力部分の並列化は行われません。
クエリ(処理)
partition by を指定したクエリの場合には並列化が可能です。但し、入力元や出力先が並列化不可の場合や、入力元と出力先のパーティションキーが異なっている場合には一部の処理しか並列化されません。
以下に、いくつかパターンを記載します。
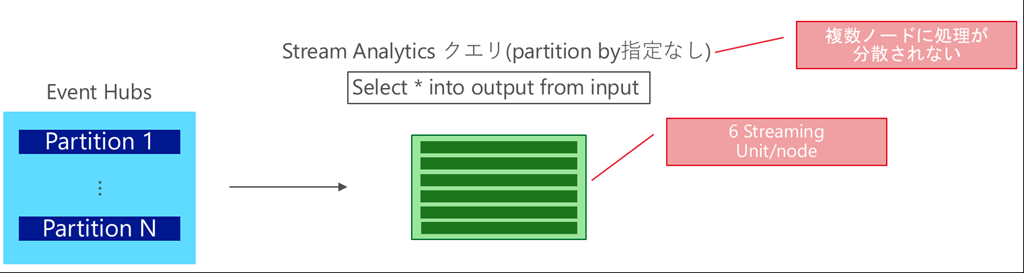
partition by を指定していないクエリの場合
この場合、Stream Analytics のジョブは並列化されないため、SU は 6 (現時点では Max 6SU/node) より大きく設定できません。
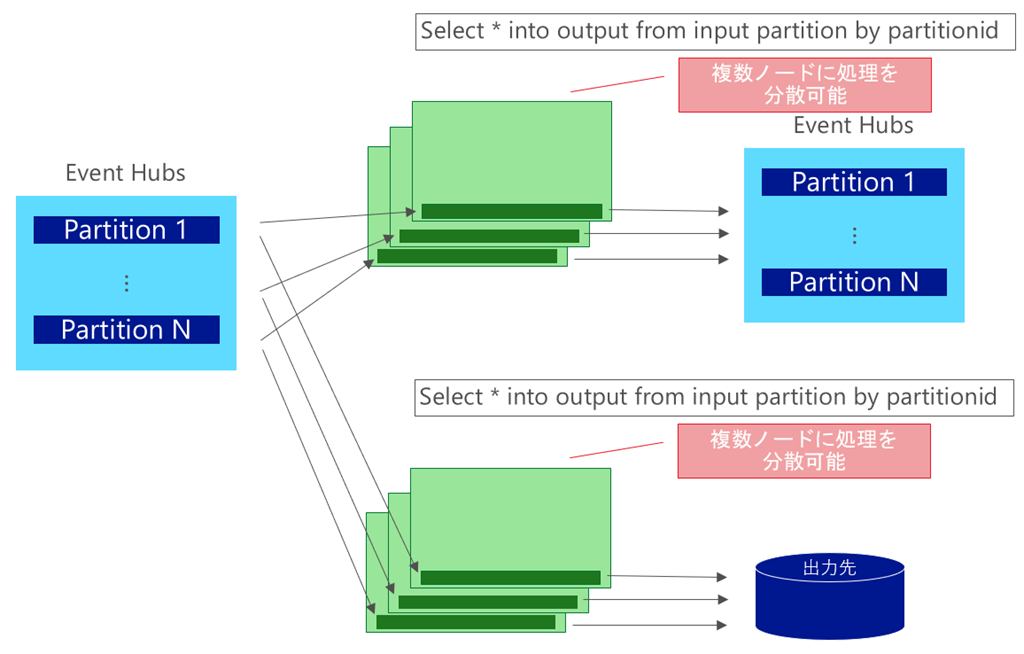
入力元、出力先共に並列化可能で、クエリにて Partition by を指定している場合
入力元と出力先のパーティションキーが一致していたり、出力先が Blob ストレージで複数ファイル出力が問題なければ クエリに Partiton by を指定するとジョブがきれいに並列化されます。なお、この際には 6SU x パーティション数 まで SU を設定することができます。
入力元、あるいは出力先が並列化可能で、クエリにて Partition by を指定している場合
例えば入力元が Event Hubs、出力先が SQL Database でクエリにて Partition by をしている場合には、入力元からの Read は並列化されますが、出力は並列化されないため 1 node での書き込みとなります。この場合、6 SU x パーティション数 + 6 SU まで SU を設定することができます。
以上、全てのパターンを提示できてはおりませんが、いくつかのパターンにおける並列化可否についてご紹介しました。



{kind=link}
{kind=link}
以上のように、Stream Analytics のジョブのスケールアウトは入力元、クエリ、出力先の並列化がポイントとなります。Stream Analytics のジョブ開発時、チューニング時のご参考にしていただければと思います。