Apache Kafka for HDInsight (public preview) (2)
Microsoft Japan Data Platform Tech Sales Team
高木 英朗
前回は Kafka for HDInsight の概要についてご紹介いたしました。今回は実際に Kafka for HDInsight のデプロイからサンプルコードの実行する方法をご紹介いたします。
今回の手順は以下の Get started with Apache Kafka (preview) on HDInsight の記事をもとにしています。
/en-us/azure/hdinsight/hdinsight-apache-kafka-get-started
Kafka for HDInsight のデプロイ
HDInsight のデプロイ方法については過去の記事「Microsoft Azure の Hadoop ディストリビューション HDInsight を使ってみよう! (1)」をご参照ください。Kafka for HDInsight の異なる部分は「クラスターの構成」において、クラスターの種類を「Kafka (プレビュー)」を選択する部分です。
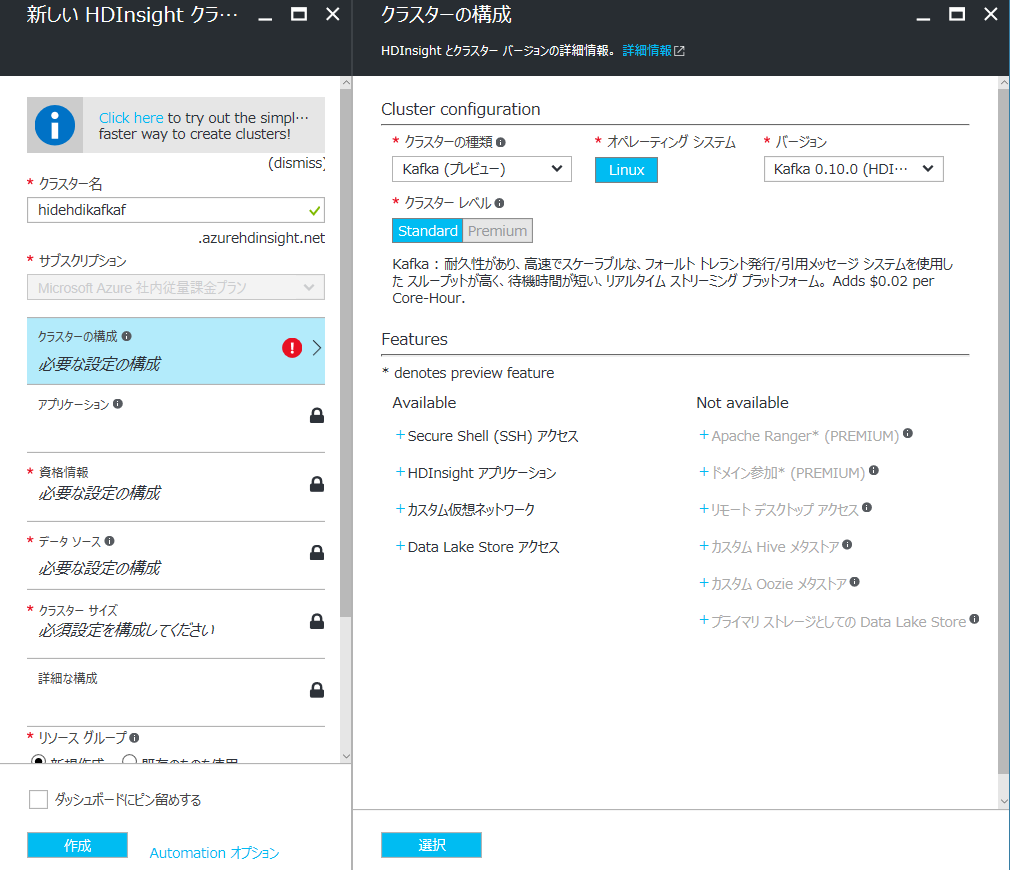
デプロイが完了したら、SSH でヘッドノードにアクセスして実際に動かしてみましょう。
準備
ZooKeeper と Broker のホスト名を取得
ストリームの読み書きの作業において、ZooKeeper と Broker のホスト名が必要になるため、環境変数にセットしておきます。
まずは、Ambari API からのレスポンスをきれいに取得するために jq を利用します。
sudo apt -y install jq
jq が使えるようになったら以下の様にして各ホスト名を環境変数にセットします。{Ambari 管理ユーザー}, {Ambari パスワード}, {HDInsight クラスタ名} は実際にデプロイした環境のものに置き換えてください。
ZooKeeper ホスト名取得
export KAFKAZKHOSTS=`curl --silent -u '{Ambari 管理ユーザー}:{Ambari パスワード}' -G https://{Ambari ホスト名}:8080/api/v1/clusters/{HDInsight クラスタ名}/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")'`
Broker ホスト名取得
export KAFKABROKERS=`curl --silent -u '{Ambari 管理ユーザー}:{Ambari パスワード}' -G https://{Ambari ホスト名}:8080/api/v1/clusters/{HDInsight クラスタ名}/services/HDFS/components/DATANODE | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")'`
以下のコマンドを実行してホスト名が出力されれば OK です。
echo '$KAFKAZKHOSTS='$KAFKAZKHOSTS
echo '$KAFKABROKERS='$KAFKABROKERS
※ Broker は HDInsight の各ワーカーノードに配置される形になります。
トピックの作成とレコードの読み書き
トピックの作成
Kafka は「トピック」というカテゴリにストリームデータを保存するため、まずはトピックを作成します。ここでは test という名前のトピックを作成します。
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic test --zookeeper $KAFKAZKHOSTS
以下を実行すると作成されたトピックを確認することができます。
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $KAFKAZKHOSTS
レコードの読み書き
トピックを作成したのでレコードを書き込んでみます。
以下を実行するとデータ入力の待機状態になります。
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic test
待機状態でテキストを入力して、終わったら Ctrl + C を押すと終了します。以下は例です。
Hello
Konnichiwa
Bye
Sayonara
今度は書き込んだレコードを読んでみます。
以下を実行するとトピックに書き込まれているレコードが画面に出力されて、すべて読み込むと待機状態に入ります。
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --zookeeper $KAFKAZKHOSTS --topic test --from-beginning
以下は出力の例です。
{metadata.broker.list=Broker のリストが表示されます, request.timeout.ms=30000, client.id=console-consumer-22338, security.protocol=PLAINTEXT}
Hello
Konnichiwa
Bye
Sayonara
Consumer は読み込んだ位置を保存して、以降の書き込みを読むためにポーリング状態になっています。Ctrl + C で終了させます。
サンプルコードの実行
ビルド
次はサンプルコードを試してみます。サンプルコードは GitHub にありますので、こちらから取得してビルドしてください。ビルド方法は README.md に書かれていますが、JDK7 以降と Maven が必要です。
この例ではすべてヘッドノード上で作業していますが、実際の環境に読み替えてお試しいただければと思います。
Maven のインストール (本記事投稿時点の最新版である 3.3.9 を使用します)
wget https://www-eu.apache.org/dist/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz
cd /usr/local/
sudo tar xzvf /path/to/apache-maven-3.3.9-bin.tar.gz
sudo ln -s apache-maven-3.3.9 maven
Maven の PATH を設定します。/home/ユーザー名/.profile の PATH に /usr/local/maven/bin を追記します。
PATH="$HOME/bin:$HOME/.local/bin:$PATH:/usr/local/maven/bin"
読み込みます。
source /home/username/.profile
準備ができたら、サンプルを取得してビルドします。
GitHub から取得します。
git clone https://github.com/Azure-Samples/hdinsight-kafka-java-get-started.git
ビルドします。
cd hdinsight-kafka-java-get-started/Producer-Consumer/
mvn clean package
ビルドが完了すると jar ができてますので、実行権限を与えておきます。
cd target
chmod u+x kafka-producer-consumer-1.0-SNAPSHOT.jar
サンプルの実行
ビルドしたサンプルの Producer を実行します。以下の様に実行すると Kafka にレコードが書き込まれてレコード数のカウンターが表示されます(全部で 100 万レコード書き込まれます)
./kafka-producer-consumer-1.0-SNAPSHOT.jar producer $KAFKABROKERS
このサンプルでは Producer API を使ってトピック名とデータを非同期に送信しています。
*Producer.java の 39 行目あたり
// Send the sentence to the test topic
producer.send(new ProducerRecord("test", sentence));
Consumer を実行して書き込まれたレコードを読み取ります。(Producer で書き込みしながら実行するとほぼリアルタイムに読み取れます)
./kafka-producer-consumer.jar consumer $KAFKABROKERS
このサンプルでは Consumer API を使ってトピックを subscribe してレコードをポーリングします。
*Consumer.java の 27 行目あたりから
// Subscribe to the 'test' topic
consumer.subscribe(Arrays.asList("test"));
// Loop until ctrl + c
int count = 0;
while(true) {
// Poll for records
ConsumerRecords records = consumer.poll(200);
// Did we get any?
if (records.count() == 0) {
// timeout/nothing to read
} else {
// Yes, loop over records
for(ConsumerRecord record: records) {
// Display record and count
count += 1;
System.out.println( count + ": " + record.value());
}
}
}
以下のように出力されれば OK です。
999591: i am at two with nature
999592: snow white and the seven dwarfs
999593: i am at two with nature
999594: i am at two with nature
999595: the cow jumped over the moon
999596: snow white and the seven dwarfs
999597: snow white and the seven dwarfs
999598: snow white and the seven dwarfs
999599: i am at two with nature
読み取りが終わると待機状態になりますので、Ctrl + C で終了します。
Consumer の負荷分散を試す場合
ビルドした Consumer のサンプルから Consumer Group を指定できますので、複数の SSH 端末から Consumer Group を指定して起動してみてください。複数の Consumer で分担してデータを読み取ることができるようになります。
./kafka-producer-consumer.jar consumer $KAFKABROKERS mygroup
Kafka Streams のサンプル実行
Kafka Streams を使うと、Storm, Spark Streaming, Samza 等に頼らずに Kafka でストリーム処理をすることができます。Streaming API は Kafka 0.10.0 で追加されました。HDInsight ではそのまま利用することができます。
ビルド
GitHub から落としてきたサンプルの中に Streaming のサンプルも含まれていますので、今度はこちらをビルドします。
cd /path/to/hdinsight-kafka-java-get-started/Streaming
mvn clean package
cd target
chmod u+x kafka-streaming-1.0-SNAPSHOT.jar
サンプルの実行
ビルドできたらストリーミングプロセスをバックグラウンドで実行します。
./kafka-streaming-1.0-SNAPSHOT.jar $KAFKABROKERS $KAFKAZKHOSTS 2>/dev/null &
このサンプルコードでは test トピックのデータを取得し、単語をカウントして wordcounts トピックに送っています。
*Stream.java の 33 行目あたりから
KStream sentences = builder.stream(stringSerde, stringSerde, "test");
KStream wordCounts = sentences
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.map((key, word) -> new KeyValue(word, word))
.through("RekeyedIntermediateTopic")
.countByKey("Counts")
.toStream();
wordCounts.to(stringSerde, longSerde, "wordcounts");
Producer のサンプルを使ってメッセージを test トピックに送ります。test トピックに送られると、先ほど実行したバックグラウンド起動させたストリーミングプロセスが処理を実行して wordcounts トピックに送ります。
/path/to/kafka-producer-consumer-1.0-SNAPSHOT.jar producer $KAFKABROKERS &>/dev/null &
Consumer スクリプトを使って、集計後のデータが入っている wordcounts トピックからデータを読み取ります。
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --zookeeper $KAFKAZKHOSTS --topic wordcount --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.key=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
単語がカウントされてこんな感じの出力になります。Ctrl + C で終了できます。
and 10096
seven 10096
years 5062
ago 5062
four 5063
score 5063
and 10097
seven 10097
years 5063
このようにして、HDInsight 上ですぐに Kafka を使い始めることができますので、是非お試しいただければと思います。
関連記事