Créer une architecture et une stratégie haute disponibilité pour SharePoint Server
S’APPLIQUE À : 2013 2016 2019 Édition d’abonnement
2013 2016 2019 Édition d’abonnement  SharePoint dans Microsoft 365
SharePoint dans Microsoft 365
Une stratégie de haute disponibilité est importante pour un environnement SharePoint Server de production. Une stratégie de bout en bout inclut les processus opérationnels, la gouvernance de plateforme, l'architecture et les solutions techniques. Cet article se concentre sur les aspects techniques et architecturaux de la haute disponibilité. Les instructions décrivent les éléments de conception SharePoint spécifiques et les options techniques qui détermineront votre stratégie de haute disponibilité.
Notes
[!REMARQUE] La haute disponibilité et la récupération d'urgence ne sont pas identiques. Il existe bien un chevauchement en matière de planification et de solutions, mais celles-ci sont des sous-ensembles de la fonction de continuité des opérations. L'objectif de la haute disponibilité est d'apporter de la résilience dans le centre de données principal et des temps morts planifiés. Le but d'une récupération d'urgence est de permettre à une organisation de reprendre les opérations d'un ordinateur dans un centre de données secondaire lorsqu'une urgence au niveau du centre de données principal rend l'infrastructure inutilisable. Pour plus d'informations sur la récupération d'urgence pour SharePoint Server, voir Choisir une stratégie de récupération d'urgence pour SharePoint Server.
La haute disponibilité est généralement utilisée pour décrire la capacité d'un système à continuer à fonctionner et à fournir des ressources aux utilisateurs lorsqu'une défaillance se produit dans une ou plusieurs des catégories suivantes dans un domaine d'erreur : matériel, logiciel ou application. Le niveau de disponibilité est exprimé sous la forme d'une mesure du pourcentage de temps pendant lequel un système est opérationnel en continu pour prendre en charge les fonctions business. Le niveau de disponibilité requis varie selon les organisations. Si cette exigence peut également varier selon les divisions, un contrat de niveau de service s'applique à l'organisation dans son ensemble. Du point de vue des utilisateurs, une batterie de serveurs SharePoint est disponible lorsque les utilisateurs peuvent accéder à la batterie de serveurs et utiliser les fonctionnalités et services dont ils ont besoin pour effectuer leur travail.
Une batterie de serveurs SharePoint hautement disponible présente les objectifs et caractéristiques suivants :
La conception de la batterie de serveurs réduit les éventuels points de défaillance. Comme il est généralement impossible de supprimer tous les points de défaillance, la stratégie globale doit indiquer comment répondre à un événement de défaillance.
Les événements de basculement sont transparents et ont un impact minimal sur les activités de l’utilisateur.
La batterie de serveurs continue à fonctionner en capacité réduite au lieu d’échouer totalement.
La batterie de serveurs est résiliente. Les incidents qui affectent le service se produisent rarement et des mesures efficaces et appropriées sont mises en place le cas échéant.
Introduction
Pour pouvoir créer une architecture et une stratégie de haute disponibilité réalistes et économiques pour votre environnement SharePoint, vous devez définir et quantifier vos objectifs de disponibilité. Ceux-ci reflètent l'étendue de la dépendance de votre organisation à SharePoint Server et à quel point une perte de service peut se répercuter sur les opérations de l'organisation. L'impact de la perte de service dépend de la nature de la perte (complète ou partielle) et de sa durée.
Une stratégie de haute disponibilité efficace doit refléter les besoins spécifiques de votre organisation. Elle doit en outre fournir un équilibre parfait entre les exigences de l'entreprise, les contrats de niveau de service informatique, la disponibilité des solutions techniques, les capacités de prise en charge informatique et les coûts d'infrastructure.
Après avoir identifié les exigences de disponibilité de votre organisation, vous pouvez commencer à créer une conception de haute disponibilité et une stratégie qui réduit le risque de temps morts et de limitation des opérations. Les professionnels de l'informatique qui conçoivent et déploient des systèmes hautement disponibles utilisent les principes directeurs suivants pour atteindre leurs objectifs :
Éliminer les points de défaillance uniques pour chaque domaine d’erreur et l’intégralité du système à chaque couche possible (système d’exploitation, logiciel et application SharePoint)
Implémenter une détection, une isolation et une résolution des erreurs extrêmement rapides
Les solutions de haute disponibilité ont une grande étendue et fournissent un ensemble de ressources partagées à l'échelle du système qui sont intégrées afin de fournir les services requis prédéfinis. La solution utilise différentes associations de matériel et de logiciels afin de réduire les temps morts et de restaurer les services en cas de défaillance du système ou d'une partie du système.
Une solution à tolérance de panne est centrée sur le matériel et utilise un matériel spécialisé pour détecter les pannes et basculer instantanément sur un composant matériel redondant. Il peut s'agir d'un processeur, d'une carte mémoire, d'une source d'alimentation, d'un sous-système d'E/S ou d'un sous-système de stockage. Le basculement vers un composant redondant fournit un niveau de service élevé.
Une analyse coûts-avantages des solutions à tolérance de panne et des solutions de haute disponibilité permet aux organisations de mettre au point une stratégie efficace pour atteindre les objectifs de disponibilité de leur batterie de serveurs SharePoint. En règle générale, des contreparties de coûts s'appliquent entre les deux solutions.
Un processus implémentant la haute disponibilité est l'un des investissements les plus onéreux pour une batterie de serveurs SharePoint. À mesure que le niveau de disponibilité et le nombre de systèmes que vous voulez rendre hautement disponibles augmentent, la complexité et le coût de la solution de disponibilité augmentent également.
Les progrès réalisés en matière de technologie de virtualisation permettent aux organisations d'utiliser des ordinateurs virtuels comme disques d'échange à chaud ou à froid. Les ordinateurs virtuels peuvent fournir la même fonctionnalité. La virtualisation peut fournir souplesse et rentabilité. Toutefois, vous devez vous assurer qu’un ordinateur virtuel est capable de gérer la charge de l’ordinateur physique qu’il remplace.
Créer une architecture de batterie de serveurs prenant en charge la haute disponibilité
L’illustration suivante indique comment distribuer et configurer différentes parties d’un environnement SharePoint pour augmenter la disponibilité dans une batterie. Cet exemple montre également comment la redondance peut résoudre les domaines d'erreur.
Notes
[!REMARQUE] Notre exemple n'est pas exhaustif. Il ne présente pas tous les domaines d'erreur ni l'ensemble du matériel à tolérance de panne.
Exemples de redondance dans une topologie de batterie de serveurs pour résoudre les points de défaillance
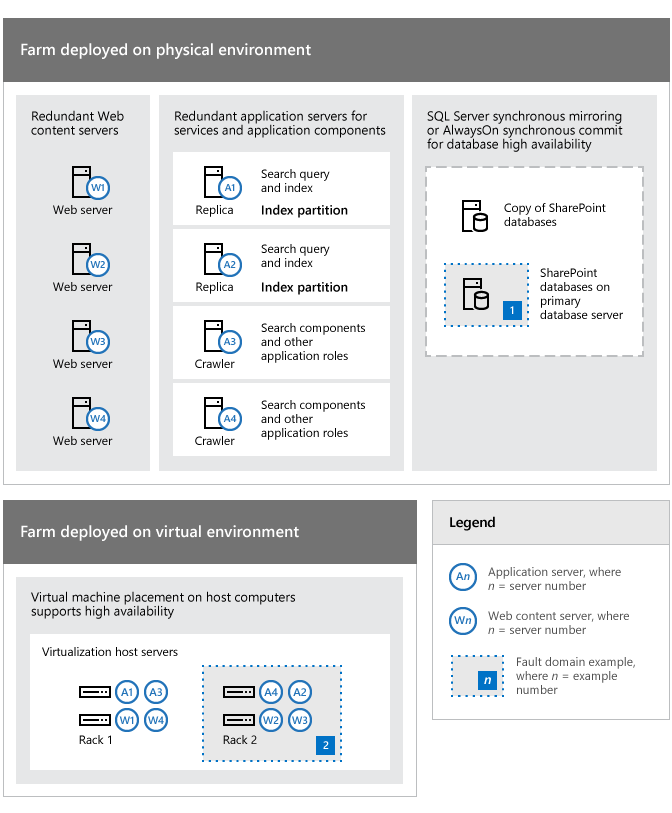
En ce qui concerne la topologie figurant dans l’illustration précédente, notez les points suivants :
La batterie de serveurs figurant dans cet exemple peut correspondre à des ordinateurs physiques ou virtuels déployés sur des serveurs hôtes Hyper-V. Le principe d'identification et de réponse aux points de défaillance s'applique aux deux types d'environnement.
Quatre serveurs (W1-W4) sont dédiés à la fourniture de contenu et cette redondance augmente la disponibilité en cas de défaillance dans un ou plusieurs serveurs. Ce niveau de redondance permet également à la batterie de continuer à fonctionner lors de l'application des mises à jour logicielles.
Quatre serveurs d'applications (A1-A4) augmentent la disponibilité des services de batterie et des composants d'application spécifiques tels que la recherche. Les rôles et composants de recherche sont redondants.
Les serveurs de base de données de batterie sont redondants et la haute disponibilité de base de données peut être atteinte à l’aide de la mise en miroir ou du clustering de base de données.
Dans un environnement virtuel, les ordinateurs virtuels sont placés sur des serveurs hôtes Hyper-V distincts pour éliminer un point de défaillance unique. Cette approche en matière de sélection élective des ordinateurs virtuels suit les instructions relatives aux meilleures pratiques en matière de disponibilité et de performances.
Le premier serveur de base de données (numéroté 1) et le rack 2 (numéroté 2), qui contient deux des ordinateurs hôtes de virtualisation, sont identifiés comme les domaines d'erreur pour afficher la façon dont votre batterie et votre infrastructure peuvent être visualisées en tant que collection de domaines d'erreur. Cette illustration indique comment effectuer une analyse approfondie de votre environnement pour développer une stratégie globale et une analyse coûts-avantages.
Autres rôles et services de batterie
Notre exemple n’inclut pas tous les rôles, services et applications de service qui peuvent s’exécuter dans une batterie de serveurs SharePoint spécifique. Vous ne pouvez pas utiliser une approche générique de la haute disponibilité pour tout ce qui se trouve dans une batterie de serveurs SharePoint. Voici quelques exclusions importantes de l’utilisation d’une approche standard de la haute disponibilité :
Des éléments particuliers doivent être pris en compte en matière de cache distribué lors d'un basculement. Pour plus d'informations, consultez l'article relatif à la Planifier le service de cache distribué et la rubrique Gérer le service de cache distribué dans SharePoint Server.
Le flux de travail SharePoint nécessite l'installation de la mise à jour cumulative 3 de Workflow Manager 1.0. La configuration d'un flux de travail pour SharePoint Server 2016 est identique à celle pour SharePoint Server 2013. Pour plus d'informations, consultez la description de la mise à jour cumulative 3 pour Workflow Manager 1.0 et Configuration d'un flux de travail hautement disponible dans Workflow Manager 1.0.
Notes
[!REMARQUE] La configuration de Workflow pour SharePoint Server 2016 n'a pas changé depuis SharePoint Server 2013. Vous devez installer la mise à jour cumulative 3 de Workflow Manager 1.0.
Si les applications de service peuvent être exécutées sur plusieurs ordinateurs, ce qui est recommandé, certaines d'entre elles ont des exigences d'installation et de configuration uniques en matière de haute disponibilité. L’application de profil utilisateur est un exemple bien connu.
Utiliser la tolérance de panne dans votre solution de haute disponibilité
Une fois que vous avez conçu une architecture prenant en charge les rôles et les charges de travail hautement disponibles, vous pouvez utiliser des composants à tolérance de panne pour optimiser la disponibilité. Les solutions à tolérance de panne sont disponibles dans toute l’infrastructure, bases de données incluses.
Infrastructure à tolérance de panne
La tolérance de panne est disponible pour la quasi-totalité des composants matériels dans l’infrastructure d’une batterie SharePoint. Dans le cadre de votre conception de haute disponibilité, déterminez les parties de l'infrastructure devant être à tolérance de panne d'un point de vue opérationnel et financier. La possibilité de rendre chaque partie de l’infrastructure à tolérance de panne ne vous y oblige pas pour autant.
Serveurs de base de données et bases de données à tolérance de panne
Étant donné que la plateforme SharePoint et ses charges de travail d’application dépendent de la disponibilité et de la fiabilité de toutes les bases de données SharePoint, les bases de données hautement disponibles constituent un aspect essentiel de votre stratégie de haute disponibilité. Vous pouvez utiliser les fonctionnalités suivantes en tant que solutions à tolérance de panne pour les serveurs de base de données et bases de données SharePoint :
Clustering de basculement SQL Server (instances de cluster de basculement Always On dans SQL Server 2014 avec Service Pack 1 (SP1)) et SQL Server 2012
Groupes de disponibilité Always On
Mise en miroir de bases de données SQL Server de haute disponibilité
À propos des instances de cluster de basculement Always On et des groupes de disponibilité Always On
Un cluster de basculement nécessite un stockage sur disque partagé entre deux ordinateurs. Dans une configuration à deux nœuds, les ordinateurs sont configurés comme actifs/passifs, fournissant ainsi une instance entièrement redondante du nœud principal. Le nœud passif est uniquement mis en ligne lorsque le nœud principal échoue. Le disque partagé n'est présenté qu'à un ordinateur à la fois. Cette configuration est celle qui nécessite généralement le plus de matériel supplémentaire. Dans SQL Server 2014 (SP1) et SQL Server 2012, ce type de configuration de cluster est une instance de cluster de basculement Always On et il s’agit d’un moyen spécifique d’installer SQL Server. En raison de la configuration requise, vous ne pouvez pas procéder à une installation standard de SQL Server, puis passer facilement à une instance de cluster de basculement.
Un groupe de disponibilité Always On est une technologie différente dans SQL Server 2014 (SP1) et SQL Server 2012 (considérez-le comme un descendant de la mise en miroir de bases de données) qui utilise certaines fonctionnalités exposées par le clustering Windows. Toutefois, un groupe de disponibilité ne nécessite pas de stockage sur disque partagé, et les ordinateurs d'un groupe de disponibilité ne nécessitent pas l'installation d'une configuration spécialisée de SQL Server. Une fois qu’un serveur de base de données est ajouté à un cluster Windows, il est assez facile d’activer les groupes de disponibilité Always On, puis de configurer le groupe de disponibilité souhaité.
En résumé, tout serveur exécutant SQL Server 2014 (SP1) et SQL Server 2012 Enterprise Edition peut utiliser des groupes de disponibilité Always On en rejoignant un cluster et en configurant le groupe de disponibilité. Les clusters de basculement Always On nécessitent des étapes matérielles et de configuration spéciales pour configurer les instances de cluster de basculement. Chacune de ces technologies est utilisée pour des environnements spécifiques, et les deux sont des concurrents complémentaires. Pour plus d'informations sur ces fonctionnalités, consultez la rubrique Solutions haute disponibilité (SQL Server). Pour obtenir de l’aide sur la technologie de disponibilité SQL Server à utiliser, consultez Continuité d’activité et récupération de base de données - SQL Server.
Importante
Étant donné que chaque option de haute disponibilité SQL Server a ses propres fonctionnalités, forces et faiblesses, une option n'est pas nécessairement meilleure qu'une autre. Par exemple, dans un scénario donné qui utilise des groupes de disponibilité Always On, la réduction de la perte de données peut être préférable à tout gain de performances réalisé par les instances de cluster de basculement Always On. Vous devez choisir une solution de haute disponibilité basée sur vos besoins professionnels et exigences d'infrastructure informatique.
Les bases de données SharePoint constituent un facteur déterminant dans la sélection d'une option SQL Server. Vous devez comprendre les caractéristiques des bases de données SharePoint Server. Chaque base de données peut impliquer des exigences ou des contraintes spécifiques qui déterminent la solution à tolérance de panne SQL Server appropriée et entièrement prise en charge dans votre environnement de production. Nous vous recommandons de consulter les articles suivants :
Clustering de basculement SQL Server
Le clustering de basculement permet une prise en charge de la disponibilité pour une instance de SQL Server sur SQL Server 2014 (SP1) ou SQL Server 2012.
Un cluster de basculement est une combinaison d'un ou plusieurs nœuds ou serveurs et d'au moins deux disques partagés. Bien qu'une instance de cluster de basculement apparaisse comme un seul ordinateur, elle permet un basculement d'un nœud vers un autre si le nœud actuel devient indisponible. SharePoint Server peut être exécuté sur toute combinaison de nœuds actifs et passifs dans un cluster pris en charge par SQL Server.
SharePoint Server fait référence au cluster dans son ensemble. Par conséquent, le basculement est automatique et transparent du point de vue de SharePoint Server.
Notes
Lorsqu’un basculement planifié ou non planifié se produit, les connexions sont abandonnées et doivent être établies à nouveau lors de la transition d’un nœud de cluster à un autre.
Pour plus d’informations sur le clustering de basculement SQL Server, consultez Instances de cluster de basculement Always On (SQL Server).
Groupes de disponibilité SQL Server Always On et mise en miroir de bases de données SQL Server
Le principal avantage des groupes de disponibilité SQL Server Always On et de la mise en miroir de bases de données SQL Server est que les deux fournissent une redondance de données complète ou presque complète selon la façon dont vous les configurez pour le traitement des transactions. Outre la minimisation de la perte de données, le basculement automatique permet de diminuer les temps morts pour les bases de données de production.
Importante
[!REMARQUE] Même si SQL Server 2016, SQL Server 2014 (SP1) et SQL Server 2012 prennent en charge la mise en miroir de bases de données, cette fonctionnalité sera bientôt déconseillée. Nous vous recommandons d'éviter de l'utiliser dans tout nouveau développement. Pensez à modifier les applications qui utilisent actuellement cette fonctionnalité. Utilisez plutôt des groupes de disponibilité Always On.
Groupes de disponibilité Always On
La fonctionnalité Groupes de disponibilité SQL Server Always On est à la fois une solution de haute disponibilité et de récupération d’urgence qui offre une alternative au niveau de l’entreprise à la mise en miroir de bases de données. Les groupes de disponibilité Always On prennent en charge un environnement de basculement pour une ou plusieurs bases de données utilisateur contenues dans une collection définie par l’utilisateur. Un groupe de disponibilité est constitué des éléments suivants :
des réplicas, qui sont un ensemble distinct de bases de données utilisateur appelées bases de données de disponibilité et traitées comme une seule unité. Chaque groupe de disponibilité prend en charge un réplica principal et jusqu'à quatre réplicas secondaires ;
une instance spécifique de SQL Server pour héberger chaque réplica et tenir à jour une copie locale de chaque base de données qui appartient au groupe de disponibilité.
Lorsqu'un groupe de disponibilité bascule vers une instance cible ou un serveur cible, toutes les bases de données du groupe basculent également. Étant donné que SQL Server 2014 (SP1) et SQL Server 2012 peuvent héberger plusieurs groupes de disponibilité sur un même serveur, vous pouvez configurer Always On pour basculer vers des instances SQL Server sur différents serveurs. Cela évite que des serveurs de secours à hautes performances inactifs soient contraints de gérer la charge complète du serveur principal, ce qui constitue l'un des principaux avantages offerts par les groupes de disponibilité.
Notes
Les problèmes liés aux bases de données (tels que la perte d’un fichier de données, la suppression d’une base de données ou l’endommagement d’un journal des transactions) ne provoquent pas de basculement.
Pour plus d’informations sur les avantages des groupes de disponibilité Always On et une vue d’ensemble de la terminologie des groupes de disponibilité Always On, consultez Groupes de disponibilité Always On (SQL Server) .
Mise en miroir de bases de données
Notes
[!REMARQUE] Même si SQL Server 2016, SQL Server 2014 (SP1) et SQL Server 2012 prennent en charge la mise en miroir de bases de données, cette fonctionnalité sera bientôt déconseillée. Nous vous recommandons d'éviter de l'utiliser dans tout nouveau développement. Pensez à modifier les applications qui utilisent actuellement cette fonctionnalité. Utilisez plutôt des groupes de disponibilité Always On.
La mise en miroir de bases de données fournit une redondance de base de données en conservant une copie en miroir des bases de données sur le serveur de base de données principal. La mise en miroir est implémentée pour chaque base de données et fonctionne uniquement avec les bases de données qui utilisent le mode de récupération complète.
Notes
[!REMARQUE] Il existe deux modes de fonctionnement de la mise en miroir. L'un des deux, le mode haute sécurité, prend en charge les opérations synchrones. En mode haute sécurité, lorsqu'une session démarre, le serveur miroir synchronise la base de données miroir et la base de données principale aussi rapidement que possible. Une fois les bases de données synchronisées, une transaction est écrite dans le journal sur le serveur secondaire, puis relue. (Le serveur principal reprend le contrôle dès que la transaction est renforcée.) L'autre mode de mise en miroir est le mode haute performance, c'est-à-dire qu'il utilise des opérations asynchrones pour réduire la latence des transactions, au prix d'une augmentation de la perte de données.
Pour la mise en miroir haute disponibilité dans une batterie de serveurs SharePoint, vous devez utiliser le mode haute sécurité avec basculement automatique. La mise en miroir haute sécurité de bases de données nécessite trois instances de serveur : un serveur principal, un serveur miroir et un serveur témoin. Le serveur témoin permet à SQL Server de basculer automatiquement du serveur principal sur le serveur miroir. Le basculement de la base de données principale sur la base de données miroir prend généralement plusieurs secondes.
Pour obtenir des informations générales sur la mise en miroir de bases de données, voir Mise en miroir de bases de données.
Importante
Les bases de données configurées pour utiliser le fournisseur du magasin d'objets BLOB distant FILESTREAM SQL Server ne peuvent pas être mises en miroir.
Comparaison de la disponibilité de base de données et des stratégies de récupération pour une batterie de serveurs unique
Le choix d'une technologie SQL Server pour la haute disponibilité et la récupération d'urgence doit être basé sur les buts professionnels de votre entreprise en ce qui concerne l'objectif de point de récupération (RPO) et l'objectif de temps de récupération (RTO). Si le RPO et le RTO sont généralement associés à la récupération d'urgence, certains événements de défaillance sont hors de l'étendue d'urgence, mais nécessitent une récupération à partir du support de sauvegarde local dans le centre de données principal.
Importante
En fonction de la base de données particulière, les différentes bases de données SharePoint Server ne prennent en charge que des options de haute disponibilité SQL Server spécifiques. Pour plus d'informations, voir Options de haute disponibilité et de récupération d'urgence prises en charge pour les bases de données SharePoint.
Le tableau suivant propose une comparaison générale des résultats de RPO et de RTO obtenus par les solutions SQL Server disponibles.
Notes
[!REMARQUE] Les durées du tableau suivant permettent de comparer les options de base de données. En pratique, les durées dépendent de la charge de travail, du volume de données et des procédures de basculement.
Comparaison du RPO et du RTO en fonction de la technologie de base de données
| Solution SQL Server | Perte de données potentielle (RPO) | Temps de récupération potentiel (RTO) | Basculement automatique |
Secondaires accessibles en lecture Note: SharePoint Server prend en charge les réplicas secondaires lisibles pour l’utilisation du runtime. Pour plus d’informations, voir Mise à jour cumulative Office 2013 pour avril 2014 et Exécuter une batterie de serveurs qui utilise des bases de données en lecture seule dans SharePoint Server. |
|---|---|---|---|---|
| Groupe de disponibilité Always On (validation synchrone) |
Zéro |
Secondes |
Oui |
0-2 |
| Groupe de disponibilité Always On (validation asynchrone) |
Secondes |
Minutes |
Non |
0-4 |
| Instance de cluster de basculement Always On |
Non applicable Une instance de cluster de basculement ne fournit pas de protection des données. Le volume de perte de données dépend de l'implémentation du système de stockage. |
Secondes voire minutes |
Oui |
Non applicable |
| Mise en miroir de bases de données - Haute sécurité (mode synchrone + serveur témoin) |
Zéro |
Secondes |
Oui |
Non applicable |
| Mise en miroir de bases de données - Haute performance (mode asynchrone) |
Secondes |
Minutes |
Non |
Non applicable |
| Sauvegarde, copie, restauration |
Heures ou zéro si le processus du journal est accessible après la défaillance |
Heures voire jours |
Non |
Pas lors d’une restauration |
Comparaison du cluster SQL Server, du groupe de disponibilité Always On et du miroir de base de données
| Processus | Cluster de basculement SQL Server | GROUPE de disponibilité Always On SQL Server 2014 (SP1) et SQL Server 2012 | Miroir haute disponibilité SQL Server |
|---|---|---|---|
| Temps nécessaire au basculement |
Le membre de cluster prend le relais quasi immédiatement après la défaillance. Un décalage se produit lorsque le nœud du cluster subit une rotation vers le haut. |
Le réplica prend le relais quasi immédiatement après la défaillance. Un décalage se produit lorsque le réplica secondaire subit une rotation vers le haut. |
Le miroir prend le relais dès que la file d’attente de restauration par progression est traitée. |
| Cohérence transactionnelle |
Oui |
Oui |
Oui |
| Simultanéité transactionnelle |
Oui |
Oui |
Oui |
| Temps jusqu’à la récupération |
Temps de récupération inférieur à celui d’un groupe de disponibilité |
Temps de récupération inférieur à celui d’un cluster de basculement, mais récupération plus rapide qu’avec une solution mise en miroir |
Temps de récupération légèrement supérieur à celui d’un cluster ou groupe de disponibilité |
| Étapes nécessaires pour le basculement |
Les nœuds de base de données détectent automatiquement une défaillance. SharePoint Server fait référence au cluster de sorte que le basculement soit transparent et automatique. |
L’écouteur de groupe de disponibilité détecte automatiquement une défaillance et le basculement est transparent et automatique. |
La base de données détecte automatiquement une défaillance. SharePoint Server connaît l'emplacement du miroir, si celui-ci a été configuré correctement de sorte que le basculement soit automatique. |
| Protection contre les défaillances de stockage |
Le cluster de basculement ne fournit pas de protection des données. Le volume de perte de données dépend de l'implémentation du système de stockage. Par exemple, un environnement SAN a des composants redondants comme plusieurs chemins de fichiers, RAID et disques d'échange à chaud. |
Protège contre les défaillances de stockage car le réplica principal écrit sur les disques locaux des réplicas secondaires. |
Protège contre les défaillances de stockage car les serveurs de base de données principal et miroir écrivent sur des disques locaux. |
| Types de stockage pris en charge |
Nécessite un stockage partagé, qui est plus onéreux que le stockage dédié. |
Peut utiliser des solutions de stockage directement attachées et moins onéreuses. |
Peut utiliser un stockage directement attaché et moins onéreux. |
| Exigences en matière d’emplacement |
Les membres du cluster doivent se trouver sur le même sous-réseau. Note: Ce n'est pas le cas avec SQL Server 2014 (SP1) et SQL Server 2012. |
Les réplicas peuvent se trouver sur différents sous-réseaux tant que la latence n’entraîne pas de problèmes de performances. |
Le serveur principal, le serveur miroir et le serveur témoin doivent se trouver sur le même réseau local (boucle de latence allant jusqu’à 1 milliseconde). |
| Mode de récupération |
Mode de récupération complète SQL Server recommandé. Vous pouvez utiliser le mode de récupération simple SQL Server. Toutefois, en cas de perte du cluster, le seul point de récupération disponible sera la dernière sauvegarde complète. |
Nécessite le mode de récupération complète SQL Server 2014 (SP1) et SQL Server 2012. |
Nécessite le mode de récupération complète SQL Server. |
| Dégradation des performances |
Une diminution des performances peut se produire lors d'un basculement. Le serveur peut être indisponible lors du basculement et les connexions sont abandonnées, puis rétablies sur le nouveau nœud actif. |
Les groupes de disponibilité Always On introduisent une latence transactionnelle en raison de la validation synchrone sur les réplicas secondaires. Le volume de latence dépend du nombre de réplicas secondaires devant être synchronisés. La surcharge de mémoire et de processeur est supérieure à celle du clustering, mais inférieure à celle de la mise en miroir. |
La mise en miroir de haute disponibilité introduit une latence transactionnelle car elle est synchrone. Elle implique également une surcharge de mémoire et de processeur supplémentaire. |
| Surcharge opérationnelle |
Configurée et maintenue au niveau du serveur. |
La surcharge opérationnelle est supérieure à celle du clustering et de la mise en miroir. Always On nécessite une surcharge au niveau du serveur de base de données SQL Server en plus du niveau Windows Server. Remarque : les objets de niveau serveur, tels que les ouvertures de session et les travaux d’agent, doivent être mis à jour manuellement. Si vous ajoutez des bases de données de contenu, vous devez les ajouter à un groupe de disponibilité, puis synchroniser le réplica principal avec les réplicas secondaires. Un environnement de batterie de serveurs SharePoint nécessite plusieurs étapes de configuration pour que la chaîne de connexion SharePoint Server soit correctement associée au nom d'écouteur de groupe de disponibilité. |
La surcharge opérationnelle est supérieure à celle du clustering. Elle doit être configurée et maintenue pour toutes les bases de données. La reconfiguration après basculement est manuelle. Remarque : les objets de niveau serveur, tels que les ouvertures de session et les travaux d’agent, doivent être mis à jour manuellement. Si vous ajoutez des bases de données de contenu, vous devez les ajouter au serveur principal, puis synchroniser le serveur principal avec le serveur miroir. |
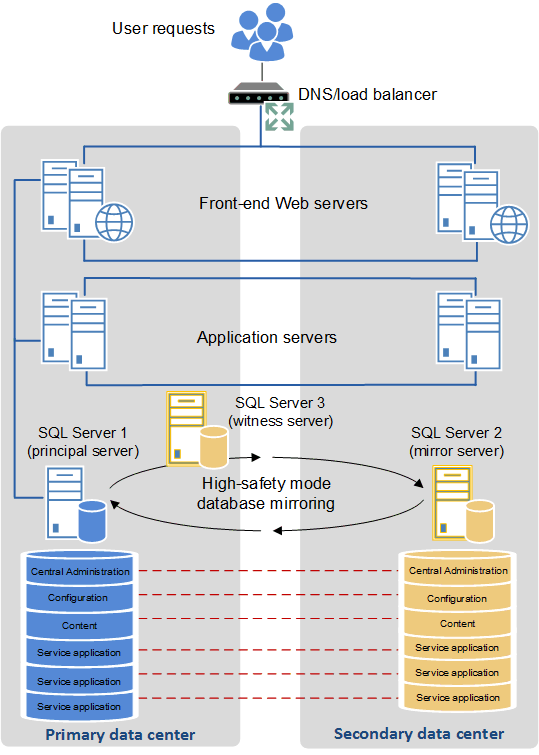
Configurer deux centres de données en tant que batterie unique (batterie « étendue ») pour fournir la haute disponibilité
Certaines entreprises possèdent des centres de données qui sont proches les uns des autres et connectés par des liens de fibre optique à large bande passante. Lorsque cet environnement est disponible, il est possible de configurer les deux centres de données en tant que batterie de serveurs unique. Cette topologie de batterie de serveurs distribuée est appelée batterie de serveurs « étendue ».
Pour qu’une architecture de batterie de serveurs étendue fonctionne en tant que solution de haute disponibilité prise en charge, les conditions préalables suivantes doivent être remplies :
There is a highly consistent intra-farm latency of <1ms (one way), 99.9% of the time over a period of ten minutes. (Intra-farm latency is commonly defined as the latency between the front-end web servers and the database servers.)
La vitesse de la bande passante doit atteindre au moins un gigabit par seconde.
Pour autoriser la tolérance de panne dans une batterie étendue, consultez les instructions des meilleures pratiques standard pour configurer les applications de service et les bases de données redondantes.
L’illustration suivante présente une batterie étendue.
Batterie de serveurs étendue
Intégrer les opérations de sauvegarde et de restauration dans une stratégie de haute disponibilité
Votre stratégie de haute disponibilité doit inclure les opérations de sauvegarde et de restauration appropriées pour vous assurer que la batterie de serveurs est résiliente. En cas d'incident, comme une défaillance de support ou une erreur utilisateur, vous devez être capable de restaurer la partie de l'environnement de la batterie de serveurs ou des données de batterie de serveurs touchée au moment opportun. Une solution de sauvegarde et de restauration efficace doit vous permettre d'atteindre les objectifs de temps de récupération (RTO) et de point de récupération (RPO) que vous avez définis.
Voir aussi
Concepts
Concepts relatifs à la haute disponibilité et à la récupération d’urgence dans SharePoint Server
Choisir une stratégie de récupération d'urgence pour SharePoint Server