connecteurs Microsoft Graph Azure SQL et Microsoft SQL Server
Les connecteurs Microsoft SQL Server ou Azure SQL Microsoft Graph permettent à vos organization de découvrir et d’indexer des données à partir d’une base de données SQL Server locale ou d’une base de données hébergée dans votre Azure SQL instance dans le cloud. Le connecteur indexe le contenu spécifié dans Recherche microsoft et Microsoft 365 Copilot. Pour maintenir l’index à jour avec les données sources, il prend en charge les analyses complètes et incrémentielles périodiques. Avec ces connecteurs SQL, vous pouvez également restreindre l’accès aux résultats de recherche pour certains utilisateurs.
Cet article est destiné aux administrateurs Microsoft 365 ou à toute personne qui configure, exécute et surveille un Azure SQL ou un connecteur Microsoft SQL Server Microsoft Graph.
Fonctionnalités
- Indexez les enregistrements de votre serveur MS SQL ou de votre base de données Azure SQL à l’aide d’une requête SQL.
- Spécifiez les autorisations d’accès pour chaque enregistrement avec une liste d’utilisateurs ou de groupes ajoutés dans la requête SQL.
- Permettre à vos utilisateurs finaux de poser des questions relatives aux enregistrements indexés dans Copilot.
- Utilisez la recherche sémantique dans Copilot pour permettre aux utilisateurs de trouver du contenu pertinent en fonction des mots clés, des préférences personnelles et des connexions sociales.
Limitations
- Connecteur Microsoft SQL Server : la base de données locale doit s’exécuter SQL Server version 2008 ou ultérieure.
- connecteur Azure SQL : l’abonnement Microsoft 365 et l’abonnement Azure (hébergeant Azure SQL base de données) doivent se trouver dans la même Microsoft Entra ID. Le flux de données interlocataire n’est pas pris en charge.
- Pour prendre en charge une vitesse d’analyse élevée et de meilleures performances, le connecteur est conçu pour prendre en charge uniquement les charges de travail OLTP (Online Transaction Processing). Charges de travail OLAP (Online Analytical Processing) qui n’exécutent pas la requête SQL fournie dans un délai d’expiration de 40 secondes et ne sont pas prises en charge.
- Les listes de contrôle d’accès sont uniquement prises en charge à l’aide d’un nom d’utilisateur principal (UPN), d’un Microsoft Entra ID ou d’une sécurité Active Directory.
- L’indexation de contenu enrichi à l’intérieur des colonnes de base de données n’est pas prise en charge. Des exemples de ce contenu sont HTML, JSON, XML, objets blob et analyses de documents qui existent sous forme de liens à l’intérieur des colonnes de base de données.
Configuration requise
- Vous devez être l’administrateur de recherche du locataire Microsoft 365 de votre organization.
- Installer l’agent de connecteur Microsoft Graph (applicable uniquement pour le connecteur MS SQL) : pour accéder à votre SQL Server Microsoft, vous devez installer et configurer l’agent de connecteur. Pour en savoir plus , consultez Installer l’agent de connecteur Microsoft Graph .
- Compte de service : pour vous connecter à votre base de données SQL et permettre au connecteur Microsoft Graph de mettre à jour régulièrement les enregistrements, vous avez besoin d’un compte de service avec des autorisations de lecture accordées au compte de service.
Remarque
Si vous utilisez Authentification Windows lors de la configuration du connecteur Microsoft SQL Server, l’utilisateur avec lequel vous essayez de vous connecter doit disposer de droits de connexion interactifs sur l’ordinateur sur lequel l’agent de connecteur est installé. Pour plus d’informations, consultez Gestion des stratégies de connexion.
Prise en main de l’installation
1. Nom d’affichage
Un nom d’affichage est utilisé pour identifier chaque citation dans Copilot, ce qui permet aux utilisateurs de reconnaître facilement le fichier ou l’élément associé. Le nom d’affichage indique également le contenu approuvé. Le nom d’affichage est également utilisé comme filtre de source de contenu. Une valeur par défaut est présente pour ce champ, mais vous pouvez la personnaliser avec un nom que les utilisateurs de votre organization reconnaître.
serveur 2. SQL
Pour vous connecter à vos données SQL, vous avez besoin de l’adresse de votre serveur SQL et du nom de votre base de données.
3. Type d’authentification
Azure SQL connecteur prend uniquement en charge Microsoft Entra ID’authentification OpenID Connect (OIDC) pour se connecter à la base de données.
Inscrire une application (pour Azure SQL connecteur Microsoft Graph uniquement)
Pour Azure SQL connecteur, vous devez inscrire une application dans Microsoft Entra ID pour permettre à l’application Recherche Microsoft et aux Microsoft 365 Copilot d’accéder aux données à des fins d’indexation. Pour en savoir plus sur l’inscription d’une application, reportez-vous à la documentation Microsoft Graph sur l’inscription d’une application.
Après avoir terminé l’inscription de l’application et pris note du nom de l’application, de l’ID d’application (client) et de l’ID de locataire, vous devez générer une nouvelle clé secrète client. Le client n’est affiché qu’une seule fois. N’oubliez pas de noter & stocker la clé secrète client en toute sécurité. Utilisez l’ID client et la clé secrète client lors de la configuration d’une nouvelle connexion dans Recherche et Microsoft 365 Copilot Microsoft.
Pour ajouter l’application inscrite à votre base de données Azure SQL, vous devez :
- Connectez-vous à votre base de données Azure SQL.
- Ouvrez une nouvelle fenêtre de requête.
- Créez un utilisateur en exécutant la commande « CREATE USER [app name] FROM EXTERNAL PROVIDER ».
- Ajoutez l’utilisateur au rôle en exécutant la commande « exec sp_addrolemember 'db_datareader', [nom de l’application] » ou « ALTER ROLE db_datareader ADD MEMBER [nom de l’application] ».
Pour en savoir plus sur la révocation de l’accès à une application inscrite dans Microsoft Entra ID, consultez Suppression d’une application inscrite.
Paramètres de pare-feu (pour Azure SQL connecteur Microsoft Graph uniquement)
Pour renforcer la sécurité, vous pouvez configurer des règles de pare-feu IP pour votre serveur ou base de données Azure SQL. Pour en savoir plus sur la configuration des règles de pare-feu IP, consultez la documentation sur les règles de pare-feu IP. Ajoutez les plages d’adresses IP clientes suivantes dans les paramètres de pare-feu.
| Région | Microsoft 365 Entreprise | Microsoft 365 Secteur public |
|---|---|---|
| NAM | 52.250.92.252/30, 52.224.250.216/30 | 52.245.230.216/30, 20.141.117.64/30 |
| EUR | 20.54.41.208/30, 51.105.159.88/30 | N/A |
| APC | 52.139.188.212/30, 20.43.146.44/30 | N/A |
4. Déployer pour un public limité
Déployez cette connexion sur une base d’utilisateurs limitée si vous souhaitez la valider dans Copilot et d’autres surfaces de recherche avant d’étendre le déploiement à un public plus large. Pour en savoir plus sur le déploiement limité, cliquez ici.
Contenu
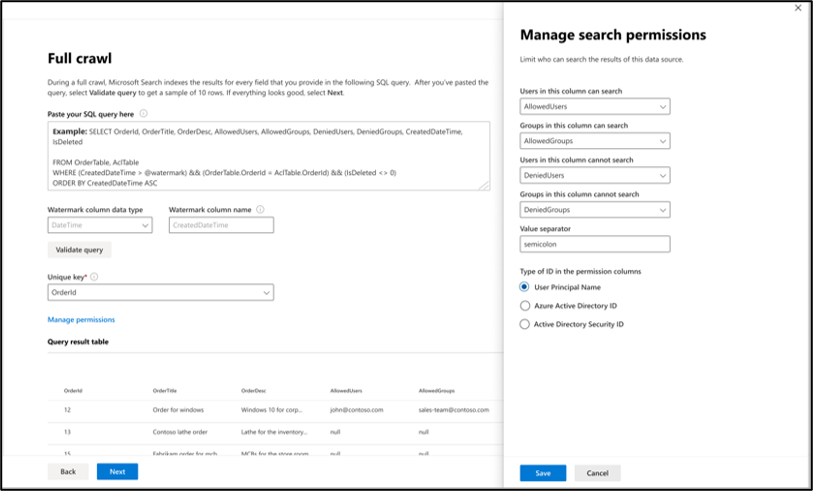
Pour rechercher le contenu de votre base de données, vous devez spécifier des requêtes SQL lorsque vous configurez le connecteur. Ces requêtes SQL doivent nommer toutes les colonnes de base de données que vous souhaitez indexer (propriétés sources). Cela inclut toutes les jointures SQL qui doivent être effectuées pour obtenir toutes les colonnes. Pour restreindre l’accès aux résultats de la recherche, vous devez spécifier Access Control Listes (ACL) dans les requêtes SQL lorsque vous configurez le connecteur.
1. Analyse complète (obligatoire)
a.
Sélectionner des colonnes de données (Obligatoire) et des colonnes ACL (Facultatif)
[Cliquez pour développer] Sélection de colonnes de données pour la requête d’analyse complète.
Dans cette étape, vous allez configurer la requête SQL qui exécute une analyse complète de la base de données. L’analyse complète sélectionne toutes les colonnes ou propriétés qui doivent être présentées dans Microsoft Copilot ou la recherche. Vous pouvez également spécifier des colonnes ACL pour restreindre l’accès aux résultats de la recherche à des utilisateurs ou des groupes spécifiques.
Conseil
Pour obtenir toutes les colonnes dont vous avez besoin, vous pouvez joindre plusieurs tables.

L’exemple illustre une sélection de cinq colonnes de données qui contiennent les données pour la recherche : OrderId, OrderTitle, OrderDesc, CreatedDateTime et IsDeleted. Pour définir les autorisations d’affichage pour chaque ligne de données, vous pouvez éventuellement sélectionner les colonnes ACL suivantes : AllowedUsers, AllowedGroups, DeniedUsers et DeniedGroups. Toutes ces colonnes de données ont également des options d’interrogation, de recherche, de récupération ou d’affinement.
Sélectionnez des colonnes de données comme indiqué dans cet exemple de requête : SELECT orderId, orderTitle, orderDesc, allowedUsers, allowedGroups, deniedUsers, deniedGroups, createdDateTime, isDeleted
Les connecteurs SQL n’autorisent pas les noms de colonnes avec des caractères non alphabétiques dans la clause SELECT. Supprimez tous les caractères nonphanumériques des noms de colonnes à l’aide d’un alias. Exemple : SELECT column_name AS columnName
Pour gérer l’accès aux résultats de la recherche, vous pouvez spécifier une ou plusieurs colonnes ACL dans la requête. Le connecteur SQL vous permet de contrôler l’accès par niveau d’enregistrement. Vous pouvez choisir d’avoir le même contrôle d’accès pour tous les enregistrements d’une table. Si les informations de liste de contrôle d’accès sont stockées dans une table distincte, vous devrez peut-être effectuer une jointure avec ces tables dans votre requête.
L’utilisation de chacune des colonnes de liste de contrôle d’accès dans la requête ci-dessus est décrite ci-dessous. La liste suivante décrit les quatre mécanismes de contrôle d’accès.
- AllowedUsers : cette colonne spécifie la liste des ID d’utilisateur qui peuvent accéder aux résultats de la recherche. Dans l’exemple suivant, une liste d’utilisateurs : john@contoso.com, keith@contoso.comet lisa@contoso.com n’ont accès qu’à un enregistrement avec OrderId = 12.
- AllowedGroups : cette colonne spécifie le groupe d’utilisateurs qui pourront accéder aux résultats de la recherche. Dans l’exemple suivant, le groupe sales-team@contoso.com a uniquement accès à l’enregistrement avec OrderId = 12.
- DeniedUsers : cette colonne spécifie la liste des utilisateurs qui n’ont pas accès aux résultats de la recherche. Dans l’exemple suivant, les utilisateurs john@contoso.com et keith@contoso.com n’ont pas accès à l’enregistrement avec OrderId = 13, tandis que tout le monde a accès à cet enregistrement.
- DeniedGroups : cette colonne spécifie le groupe d’utilisateurs qui n’ont pas accès aux résultats de la recherche. Dans l’exemple suivant, regroupe engg-team@contoso.com et pm-team@contoso.com n’ont pas accès à un enregistrement avec OrderId = 15, alors que tout le monde a accès à cet enregistrement.

b.
Types de données pris en charge
[Cliquez pour développer] Liste des types de données pris en charge.
Le tableau récapitule les types de données SQL pris en charge dans les connecteurs MS SQL et Azure SQL. Le tableau récapitule également le type de données d’indexation pour le type de données SQL pris en charge. Pour en savoir plus sur les types de données pris en charge par les connecteurs Microsoft Graph pour l’indexation, reportez-vous à la documentation sur les types de ressources de propriété.
| Catégorie | Type de données source | Type de données d’indexation |
|---|---|---|
| Date et heure | date DateHeure datetime2 smalldatetime |
DateHeure |
| Numérique exact | bigint int smallint tinyint |
int64 |
| Numérique exact | mors | valeur booléenne |
| Nombre approximatif | float réel |
double |
| Chaîne de caractères | carboniser varchar text |
string |
| Chaînes de caractères Unicode | nchar nvarchar ntext |
string |
| String collection | carboniser varchar text |
stringcollection* |
| Autres types de données | uniqueidentifier | string |
*Pour indexer une colonne en tant que StringCollection, vous devez convertir une chaîne en type de collection de chaînes. Pour ce faire, cliquez sur le lien « Modifier les types de données » dans paramètres d’analyse complète et sélectionnez les colonnes appropriées comme StringCollection et spécifiez un délimiteur pour fractionner la chaîne.
Pour tout autre type de données actuellement non pris en charge directement, la colonne doit être explicitement convertie en type de données pris en charge.
c.
Filigrane (obligatoire)
[Cliquez pour développer] Spécification de la colonne de filigrane dans la requête d’analyse complète
Pour éviter la surcharge de la base de données, le connecteur traite et reprend les requêtes d’analyse complète avec une colonne de filigrane d’analyse complète. À l’aide de la valeur de la colonne de filigrane, chaque lot suivant est extrait et l’interrogation reprend à partir du dernier point de contrôle. Essentiellement, ce mécanisme contrôle l’actualisation des données pour les analyses complètes.
Créez des extraits de requête pour les filigranes, comme indiqué dans les exemples suivants :
-
WHERE (CreatedDateTime > @watermark). Citez le nom de colonne de filigrane avec le mot clé@watermarkréservé. Si l’ordre de tri de la colonne de filigrane est croissant, utilisez>; sinon, utilisez<. -
ORDER BY CreatedDateTime ASC. Triez sur la colonne de filigrane dans l’ordre croissant ou décroissant.
Dans la configuration illustrée dans l’image suivante, CreatedDateTime est la colonne de filigrane sélectionnée. Pour extraire le premier lot de lignes, spécifiez le type de données de la colonne de filigrane. Dans ce cas, le type de données est DateTime.

La première requête extrait le premier N nombre de lignes en utilisant : « CreatedDateTime > 1er janvier 1753 00:00:00 » (valeur minimale du type de données DateTime). Une fois le premier lot récupéré, la valeur la plus élevée retournée CreatedDateTime dans le lot est enregistrée en tant que point de contrôle si les lignes sont triées dans l’ordre croissant. Par exemple, le 1er mars 2019 03:00:00. Ensuite, le lot suivant de N lignes est extrait à l’aide de « CreatedDateTime > 1er mars 2019 03:00:00 » dans la requête.
2. Gérer les propriétés
Le connecteur SQL récupère toutes les colonnes spécifiées dans la requête SQL d’analyse complète en tant que propriétés sources pour l’ingestion. Dans cette étape, vous pouvez définir le schéma de recherche pour votre contenu. Cela implique la définition des annotations de recherche telles que la recherche, la récupération, l’interrogation et l’affinement pour les propriétés sources sélectionnées. Cela inclut également l’attribution d’étiquettes sémantiques et d’alias pour améliorer la pertinence de la recherche. Pour en savoir plus sur le schéma de recherche, reportez-vous à la documentation sur les instructions pour « gérer les propriétés ».
3. Analyse incrémentielle (facultatif)
a.
Requête de synchronisation incrémentielle
Dans cette étape facultative, fournissez une requête SQL pour exécuter une analyse incrémentielle de la base de données. Avec cette requête, le connecteur SQL détermine les modifications apportées aux données depuis la dernière analyse incrémentielle. Comme dans l’analyse complète, sélectionnez toutes les colonnes dans lesquelles vous souhaitez sélectionner les options Interroger, Rechercher, Récupérer ou Affiner. Spécifiez le même ensemble de colonnes de liste de contrôle d’accès que celui que vous avez spécifié dans la requête d’analyse complète.
Les composants de l’image suivante ressemblent aux composants d’analyse complets, à une exception près. Dans ce cas, « ModifiedDateTime » est la colonne de filigrane sélectionnée. Passez en revue les étapes d’analyse complètes pour savoir comment écrire votre requête d’analyse incrémentielle et voir l’image suivante comme exemple.

b. Instructions de suppression réversible (facultatif)
Dans un système d’enregistrements SQL, une suppression réversible est une technique dans laquelle, au lieu de supprimer physiquement un enregistrement d’une base de données, vous le marquez comme « supprimé » en définissant un indicateur ou une colonne spécifique. Cela permet à l’enregistrement de rester dans la base de données, mais il est logiquement exclu de la plupart des opérations. Pour supprimer des lignes supprimées de manière réversible dans votre base de données pendant l’analyse incrémentielle, spécifiez le nom et la valeur de la colonne de suppression réversible qui indiquent que la ligne est supprimée.

Utilisateurs
Vous pouvez choisir d’utiliser uniquement les personnes ayant accès à cette source de données pour restreindre l’accès aux utilisateurs ou aux groupes comme sélectionné dans la requête d’analyse complète, ou vous pouvez les remplacer pour rendre votre contenu visible par tout le monde.
1. Mapper des colonnes contenant des informations d’autorisations d’accès
Choisissez les différentes colonnes de contrôle d’accès (ACL) qui spécifient le mécanisme de contrôle d’accès. Sélectionnez le nom de colonne que vous avez spécifié dans la requête SQL d’analyse complète. Notez que « refuser » est prioritaire sur les autorisations « autoriser ».
Chacune des colonnes de liste de contrôle d’accès doit être une colonne à valeurs multiples. Ces valeurs d’ID multiples peuvent être séparées par des séparateurs tels que des points-virgules (;), virgule (,), etc. Vous devez spécifier ce séparateur dans le champ séparateur de valeur .
Les types d’ID suivants sont pris en charge pour une utilisation en tant que listes de contrôle d’accès :
- Nom d’utilisateur principal (UPN) : un nom d’utilisateur principal (UPN) est le nom d’un utilisateur système au format d’adresse e-mail. Un UPN (par exemple : john.doe@domain.com) se compose du nom d’utilisateur (nom de connexion), du séparateur (symbole @) et du nom de domaine (suffixe UPN).
- Microsoft Entra ID : dans Microsoft Entra ID, chaque utilisateur ou groupe a un ID d’objet qui ressemble à « e0d3ad3d-0000-1111-2222-3c5f5c52ab9b ».
- ID de sécurité Active Directory (AD) : dans une configuration AD locale, chaque utilisateur et groupe ont un identificateur de sécurité unique immuable qui ressemble à « S-1-5-21-3878594291-2115959936-132693609-65242 ».
Synchronisation
L’intervalle d’actualisation détermine la fréquence à laquelle vos données sont synchronisées entre la source de données et l’index du connecteur Graph.
Vous pouvez configurer des analyses complètes et incrémentielles en fonction des options de planification présentes ici. Par défaut, l’analyse incrémentielle (si elle est configurée) est définie toutes les 15 minutes, et l’analyse complète est définie pour chaque jour. Si nécessaire, vous pouvez ajuster ces planifications en fonction de vos besoins d’actualisation des données.
À ce stade, vous êtes prêt à créer la connexion pour Azure SQL ou MS SQL. Vous pouvez cliquer sur le bouton « Créer » pour publier votre connexion et indexer les données de votre base de données.
Résolution des problèmes
Après avoir publié votre connexion, vous pouvez consulter la status sous l’onglet Sources de données dans le Centre d’administration. Pour savoir comment effectuer des mises à jour et des suppressions, consultez Gérer votre connecteur. Vous trouverez les étapes de résolution des problèmes courants ici.
Si vous rencontrez des problèmes ou si vous souhaitez fournir des commentaires, contactez Microsoft Graph | Support.