Interroger des fichiers CSV
Cet article explique comment interroger un fichier CSV à l’aide d’un pool SQL serverless dans Azure Synapse Analytics. Les fichiers CSV peuvent avoir des formats différents :
- Avec ou sans ligne d’en-tête
- Valeurs délimitées par des virgules ou des tabulations
- Fins de ligne de style Windows ou Unix
- Valeurs sans guillemets ou entre guillemets, et caractères d’échappement
Toutes les variantes ci-dessus sont abordées ci-dessous.
Exemple de démarrage rapide
La fonction OPENROWSET vous permet de lire le contenu d’un fichier CSV en fournissant l’URL de votre fichier.
Lire un fichier .csv
Le moyen le plus simple d’afficher le contenu de votre fichier CSV consiste à fournir l’URL du fichier à la fonction OPENROWSET ainsi qu’à spécifier le FORMAT CSV et la PARSER_VERSION 2.0. Si le fichier est disponible publiquement ou si votre identité Microsoft Entra peut y accéder, vous devez voir le contenu du fichier en utilisant une requête comme celle affichée dans les exemples suivants :
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
L’option firstrow est utilisée pour ignorer la première ligne du fichier CSV qui est l’en-tête dans ce cas. Assurez-vous que vous pouvez accéder à ce fichier. Si votre fichier est protégé par une clé SAS ou une identité personnalisée, vous devez configurer les informations d’identification au niveau du serveur pour la connexion SQL.
Important
Si votre fichier CSV contient des caractères UTF-8, veillez à utiliser un classement de base de données UTF-8 (par exemple Latin1_General_100_CI_AS_SC_UTF8).
Une incompatibilité entre l’encodage de texte dans le fichier et le classement peut entraîner des erreurs de conversion inattendues.
Vous pouvez facilement modifier le classement par défaut de la base de données actuelle à l’aide de l’instruction T-SQL suivante : alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Utilisation d’une source de données
L’exemple précédent utilise le chemin complet du fichier. Vous pouvez également créer une source de données externe avec l’emplacement qui pointe vers le dossier racine du stockage :
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Après avoir créé une source de données, vous pouvez utiliser cette source de données et le chemin relatif du fichier dans la fonction OPENROWSET :
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Si une source de données est protégée par une clé SAS ou une identité personnalisée, vous pouvez configurer la source de données avec des informations d’identification dans l’étendue de la base de données.
Spécifier explicitement le schéma
OPENROWSET vous permet de spécifier explicitement les colonnes que vous souhaitez lire à partir du fichier à l’aide de la clause WITH :
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
Les nombres qui suivent un type de données dans la clause WITH représentent un index de colonne dans le fichier CSV.
Important
Si votre fichier CSV contient des caractères UTF-8, veillez à spécifier explicitement un classement UTF-8 (par exemple, Latin1_General_100_CI_AS_SC_UTF8) pour toutes les colonnes dans la clause WITH, ou définissez un classement UTF-8 au niveau de la base de données.
Une incompatibilité entre l’encodage de texte dans le fichier et le classement peut entraîner des erreurs de conversion inattendues.
Vous pouvez facilement modifier le classement par défaut de la base de données actuelle à l’aide de l’instruction T-SQL suivante :
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 Vous pouvez facilement définir le classement sur les types de colonnes à l’aide de la définition suivante : geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
Dans les sections suivantes, vous pouvez voir comment interroger différents types de fichiers CSV.
Prérequis
La première étape consiste à créer la base de données dans laquelle les tables seront créées. Ensuite, initialisez les objets en exécutant le script d’installation sur cette base de données. Ce script crée les sources de données, les informations d’identification étendues à la base de données et les formats de fichiers externes utilisés dans ces exemples.
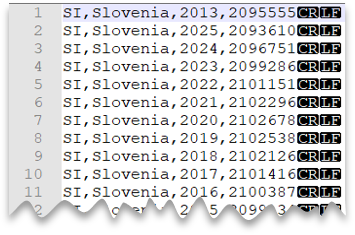
Nouvelle ligne de style Windows
La requête suivante montre comment lire un fichier CSV sans ligne d’en-tête qui comprend des caractères de nouvelle ligne de style Windows et des colonnes délimitées par des virgules.
Aperçu du fichier :
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
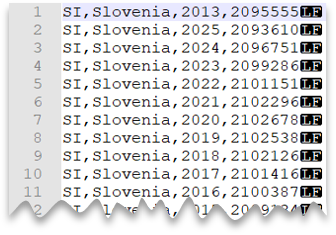
Nouvelle ligne de style Unix
La requête suivante montre comment lire un fichier sans ligne d’en-tête, avec une nouvelle ligne de style Unix et des colonnes délimitées par des virgules. Notez l’emplacement différent du fichier par rapport aux autres exemples.
Aperçu du fichier :
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
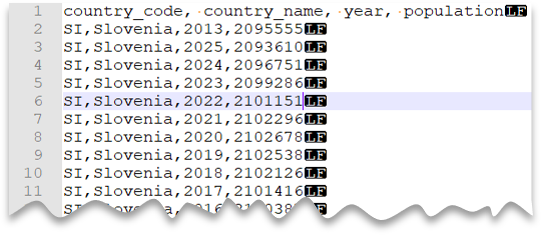
Ligne d’en-tête
La requête suivante montre comment lire un fichier avec une ligne d’en-tête, une nouvelle ligne de style Unix et des colonnes délimitées par des virgules. Notez l’emplacement différent du fichier par rapport aux autres exemples.
Aperçu du fichier :
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
L’option HEADER_ROW = TRUE entraîne la lecture des noms de colonne à partir de la ligne d’en-tête du fichier. C’est très utile à des fins d’exploration lorsque vous ne connaissez pas le contenu des fichiers. Pour des performances optimales, consultez la section Types de données appropriés dans Meilleures pratiques. Pour plus d’informations, consultez également Syntaxe OPENROWSET.
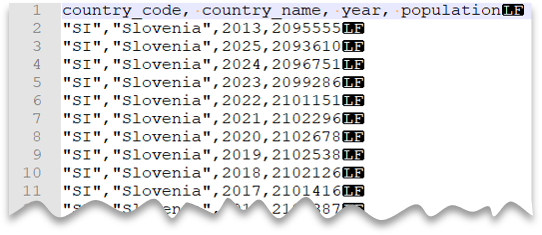
Guillemet personnalisé
La requête suivante montre comment lire un fichier avec une ligne d’en-tête, une nouvelle ligne de style Unix, des colonnes délimitées par des virgules et des valeurs entre guillemets. Notez l’emplacement différent du fichier par rapport aux autres exemples.
Aperçu du fichier :
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Notes
Cette requête retourne les mêmes résultats si vous omettez le paramètre FIELDQUOTE, car la valeur par défaut de FIELDQUOTE est un guillemet double.
Caractères d'échappement
La requête suivante montre comment lire un fichier avec une ligne d’en-tête, une nouvelle ligne de style Unix, des colonnes délimitées par des virgules et un caractère d’échappement utilisé pour le délimiteur de champ (virgule) à l’intérieur des valeurs. Notez l’emplacement différent du fichier par rapport aux autres exemples.
Aperçu du fichier :
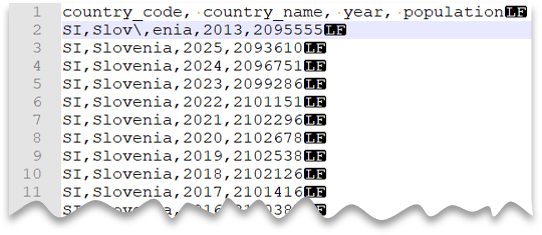
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Notes
Cette requête échouerait si ESCAPECHAR n’était pas spécifié, car la virgule dans « Slov,enia » serait traitée comme un délimiteur de champ plutôt que comme une partie du nom de pays/région. « Slov, enia » serait alors traité comme deux colonnes. Par conséquent, cette ligne aurait une colonne plus que les autres lignes et que ce que vous avez défini dans la clause WITH.
Caractères de délimitation d’échappement
La requête suivante montre comment lire un fichier avec une ligne d’en-tête, avec une nouvelle ligne de style UNIX, des colonnes délimitées par des virgules et un guillemet double placé dans une séquence d’échappement dans les valeurs. Notez l’emplacement différent du fichier par rapport aux autres exemples.
Aperçu du fichier :
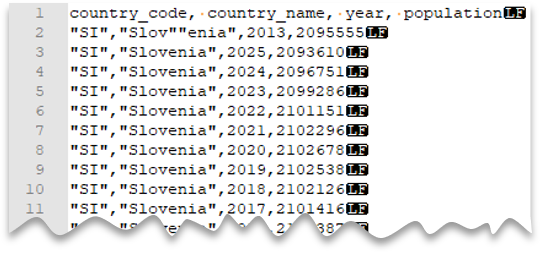
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Notes
Le caractère de délimitation doit être placé dans une séquence d’échappement avec un autre caractère de délimitation. Le caractère de délimitation peut apparaître dans la valeur de colonne seulement si la valeur est encapsulée avec des caractères de délimitation.
Fichiers délimités par des tabulations
La requête suivante montre comment lire un fichier avec une ligne d’en-tête, une nouvelle ligne de style Unix et des colonnes délimitées par des tabulations. Notez l’emplacement différent du fichier par rapport aux autres exemples.
Aperçu du fichier :
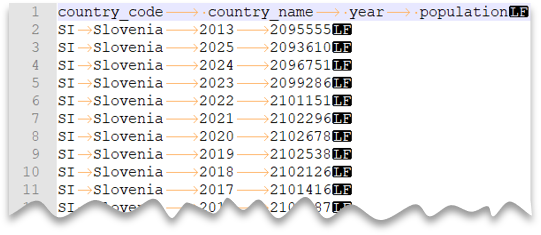
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Retourner un sous-ensemble de colonnes
Jusqu’à présent, vous avez spécifié le schéma de fichier CSV en utilisant la clause WITH et en répertoriant toutes les colonnes. Vous pouvez spécifier uniquement les colonnes dont vous avez réellement besoin dans votre requête en utilisant un nombre ordinal pour chaque colonne nécessaire. Vous allez également omettre les colonnes qui ne vous intéressent pas.
La requête suivante retourne le nombre de noms de pays/région distincts dans un fichier, en spécifiant uniquement les colonnes nécessaires :
Notes
Jetez un coup d’œil à la clause WITH dans la requête ci-dessous, et notez la présence du chiffre « 2 » (sans guillemets) à la fin de la ligne dans laquelle vous définissez la colonne [country_name] . Cela signifie que la colonne [country_name] est la deuxième dans le fichier. La requête ignore toutes les colonnes du fichier, à l’exception de la deuxième.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Interrogation de fichiers annexes
Les fichiers CSV utilisés dans la requête ne doivent pas être modifiés pendant l'exécution de la requête. Dans la requête de longue durée, le pool SQL peut retenter des lectures, lire des parties de fichiers ou même lire un fichier plusieurs fois. La modification du contenu du fichier pourrait entraîner des résultats incorrects. Par conséquent, le pool SQL fait échouer la requête s’il détecte que l’heure de modification d’un fichier a changé pendant l’exécution de la requête.
Dans certains scénarios, vous souhaiterez peut-être créer une table dans des fichiers auxquels des données sont constamment ajoutées. Pour éviter les échecs de requêtes dus à des fichiers constamment ajoutés, vous pouvez permettre à la OPENROWSETfonction d'ignorer les lectures potentiellement incohérentes en utilisant le ROWSET_OPTIONS paramètre.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
L'ALLOW_INCONSISTENT_READSoption de lecture désactive la vérification du temps de modification du fichier pendant le cycle de vie de la requête et lit tout ce qui est disponible dans le fichier. Dans les fichiers annexes, le contenu existant n'est pas mis à jour, et seules de nouvelles lignes sont ajoutées. Par conséquent, la probabilité de résultats incorrects est réduite par rapport aux fichiers avec modification des données. Cette option peut vous permettre de lire les fichiers auxquels des données sont fréquemment ajoutées sans gérer les erreurs. Dans la plupart des scénarios, le pool SQL ignorera simplement certaines lignes qui sont ajoutées aux fichiers pendant l'exécution de la requête.
Étapes suivantes
Les articles suivants décrivent les opérations ci-dessous :