Guide pratique : Modifier une base de données de lac
Cet article explique comment modifier une base de données de lac existante dans Azure Synapse à l’aide du concepteur de base de données. Le concepteur de bases de données vous permet de créer et déployer facilement une base de données sans écrire de code.
Prérequis
- Des autorisations d’administrateur ou de contributeur Synapse sont requises sur l’espace de travail Synapse pour créer une base de données de lac.
- Les autorisations Contributeur aux données Blob du stockage sont requises sur le lac de données lors de l’utilisation de l’option de création d’une table À partir du lac de données.
Modifier les propriétés de la base de données
Dans le hub Accueil de l’espace de travail Azure Synapse Analytics, sélectionnez l’onglet Données à gauche. L’onglet Données s’ouvre, affichant la liste des bases de données figurant dans votre espace de travail.
Pointez sur la section Bases de données, puis sélectionnez les points de suspension (...) en regard de la base de données que vous souhaitez modifier, puis choisissez Ouvrir.
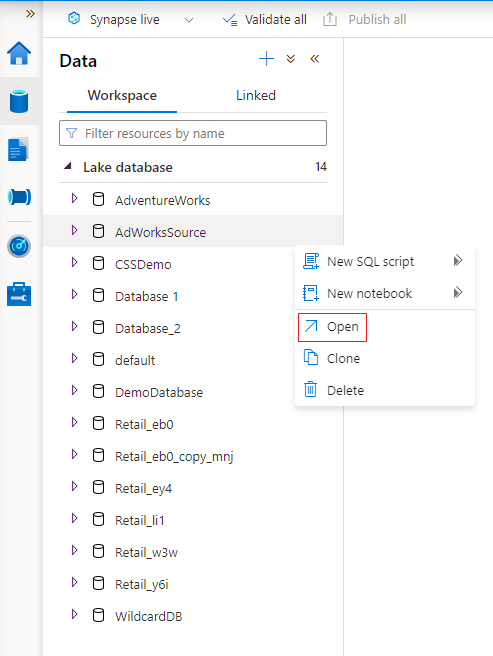
L’onglet du concepteur de bases de données s’ouvre, affichant la base de données sélectionnée chargée sur le canevas.
Le concepteur de base de données dispose d’un volet Propriétés que vous pouvez ouvrir en sélectionnant l’icône Propriétés en haut à droite.
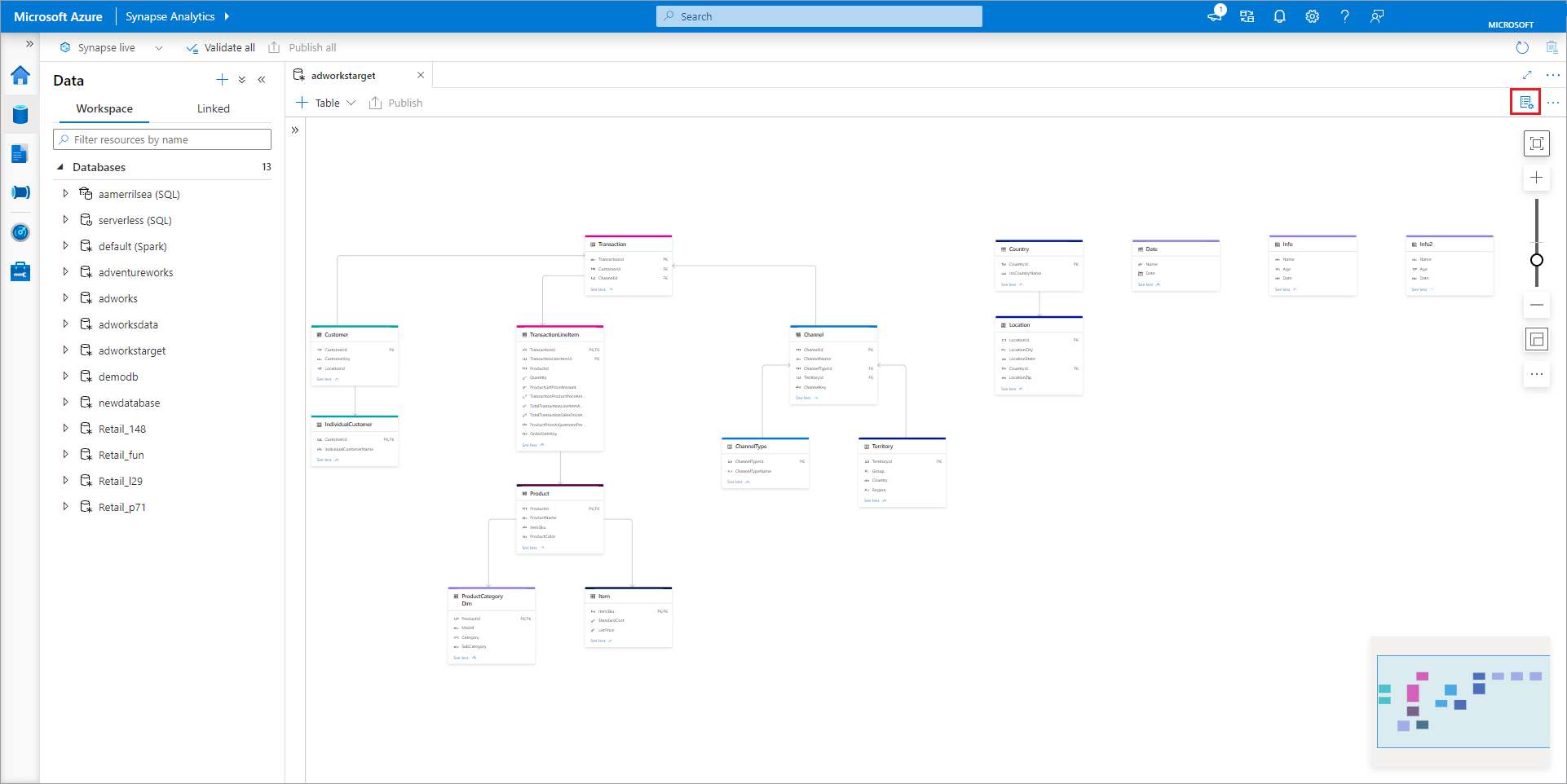
- Noms Les noms ne pouvant pas être modifiés après la publication de la base de données, veillez à choisir le nom correct.
- Description L’attribution d’une description à votre base de données est facultative, mais elle permet aux utilisateurs de comprendre l’objectif de la base de données.
- Paramètres de stockage pour la base de données Cette section contient les informations de stockage par défaut pour les tables de la base de données. Les paramètres par défaut sont appliqués à chaque table de la base de données, sauf s’ils sont remplacés par la table elle-même.
- Service lié Service lié par défaut utilisé pour stocker vos données dans Azure Data Lake Storage. Le service lié par défaut associé à l’espace de travail Synapse s’affiche, mais vous pouvez le remplacer par n’importe quel compte de stockage ADLS de votre choix.
- Le dossier d’entrée utilisé pour définir le chemin d’accès du conteneur et du dossier par défaut au sein de ce service lié à l’aide du navigateur de fichiers ou modifiant manuellement le chemin avec l’icône de crayon.
- Format de données Les bases de données de lac dans Azure Synapse prennent en charge les formats de fichier Parquet et de texte délimité comme formats de stockage pour les données.
Pour ajouter une table à la base de données, cliquez sur le bouton + Table.
- Personnalisée Ajoute une nouvelle table au canevas.
- À partir d’un modèle Ouvre la galerie et vous permet de sélectionner un modèle de base de données à utiliser lors de l’ajout d’une nouvelle table. Pour plus d’informations, consultez Créer une base de données de lac à partir d’un modèle de base de données.
- À partir d’un lac de données Vous permet d’importer un schéma de table en utilisant des données figurant déjà dans votre lac.
Sélectionnez Personnalisé. Une nouvelle table s’affiche sur le canevas, nommée Table_1.
Vous pouvez ensuite personnaliser la table Table_1 en modifiant son nom, sa description, ses paramètres de stockage, ses colonnes et ses relations. Consultez la section Personnaliser des tables dans une base de données ci-dessous.
Ajoutez une nouvelle table à partir du lac de données en sélectionnant + Table, puis À partir d’un lac de données.
Le volet Créer une table externe à partir d’un lac de données s’affiche. Remplissez le volet avec les détails ci-dessous, puis sélectionnez Continuer.
- Nom de la table externe Nom que vous voulez attribuer à la table que vous êtes en train de créer.
- Service lié Service lié contenant l’emplacement Azure Data Lake Storage dans lequel se trouve votre fichier de données.
-
Fichier ou dossier d’entrée Utilisez l’explorateur de fichiers pour accéder à un fichier de votre lac à l’aide duquel vous souhaitez créer une table, et le sélectionner.
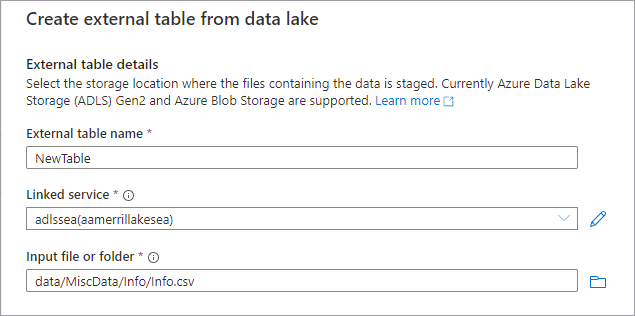
- Dans l’écran suivant, Azure Synapse affiche un aperçu du fichier et détecte le schéma.
- Vous êtes dirigé vers la page Nouvelle table externe dans laquelle vous pouvez mettre à jour tous les paramètres liés au format de données et afficher un Aperçu des données pour vérifier si Azure Synapse a identifié le fichier correctement.
- Lorsque vous êtes satisfait des paramètres, sélectionnez Créer.
- Une nouvelle table portant le nom que vous avez sélectionné est ajoutée au canevas, et la section Paramètres de stockage pour la table affiche le fichier que vous avez spécifié.
Avec la base de données personnalisée, il est maintenant temps de le publier. Si vous utilisez une intégration Git avec votre espace de travail Synapse, vous devez valider vos modifications et les fusionner dans la branche Collaboration. En savoir plus sur le contrôle de code source dans Azure Synapse. Si vous utilisez le mode dynamique Synapse, vous pouvez sélectionner « publier ».
Les erreurs sont validées dans votre base de données avant sa publication. Toutes les erreurs détectées s’affichent sous l’onglet Notifications, avec des instructions sur la façon de les corriger.
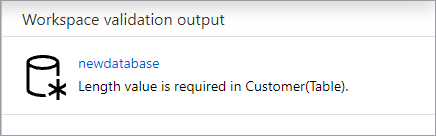
La publication a pour effet de créer votre schéma de base de données dans le metastore Azure Synapse. Après la publication, les objets de base de données et de table sont visibles par les autres services Azure, et autorisent la circulation des métadonnées de votre base de données dans des applications comme Power BI ou Microsoft Purview.
Personnaliser des tables dans une base de données
Le concepteur de bases de données vous permet de personnaliser entièrement toutes les tables de votre base de données. Lorsque vous sélectionnez une table, trois onglets sont disponibles, contenant chacun des paramètres liés au schéma ou aux métadonnées de la table.
Généralités
L’onglet Général contient des informations spécifiques de la table proprement dite.
Nom Nom de la table. Vous pouvez personnaliser le nom de la table en lui attribuant n’importe quelle valeur unique figurant dans la base de données. Les tables du même nom ne sont pas autorisées.
Héritée de (facultatif) Cette valeur s’affiche si la table a été créée à partir d’un modèle de base de données. Elle ne peut pas être modifiée et indique à l’utilisateur la table de modèle dont elle est dérivée.
Description Description de la table. Si la table a été créée à partir d’un modèle de base de données, description du concept que cette table représente. Vous pouvez modifier ce champ pour le faire correspondre à la description de vos besoins métier.
Dossier d’affichage Fournit le nom du dossier de secteur d’activité sous lequel cette table a été regroupée au sein du modèle de base de données. Pour les tables personnalisées, cette valeur sera « Autre ».
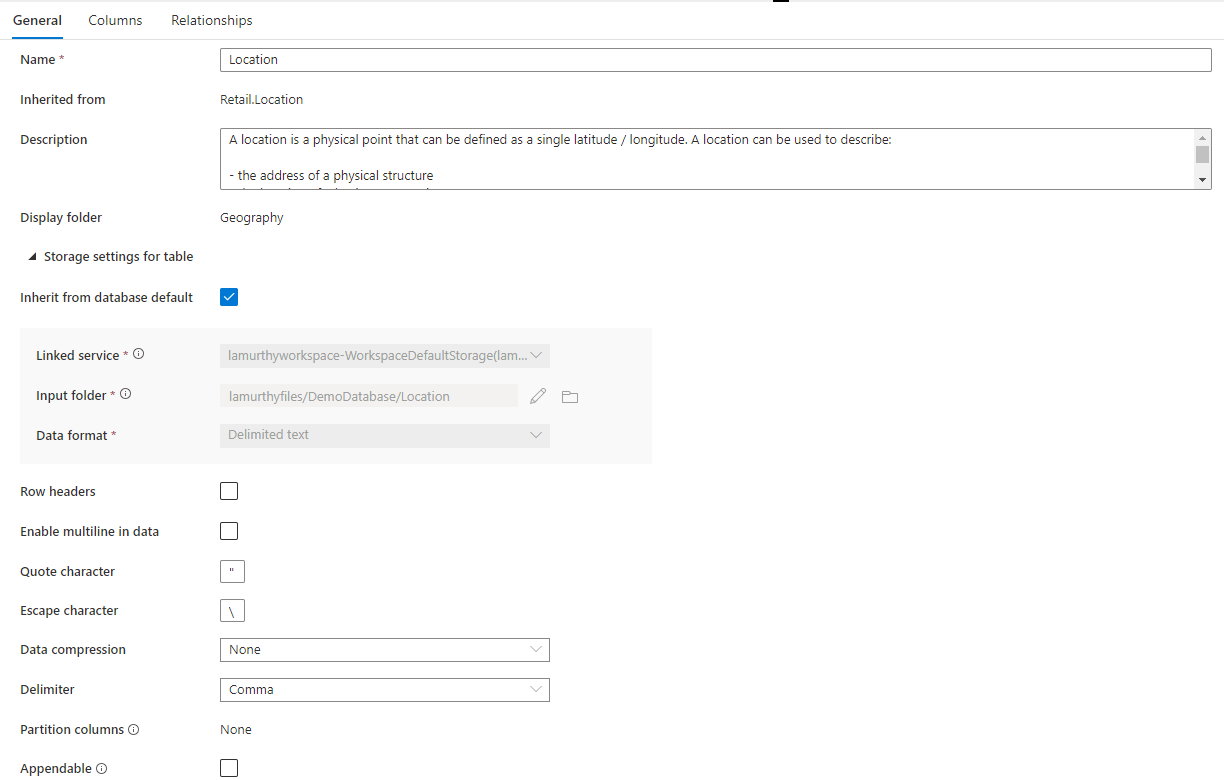
En outre, il existe une section réductible appelée Paramètres de Stockage pour la table, qui fournit des paramètres pour les informations de stockage sous-jacentes que la table utilise.
Hériter de la base de données par défaut Case à cocher déterminant si les paramètres de stockage ci-dessous sont hérités des valeurs définies sous l’onglet Propriétés de la base de données, ou définis individuellement. Si vous souhaitez personnaliser les valeurs de stockage, désactivez cette case.
- Service lié Service lié par défaut utilisé pour stocker vos données dans Azure Data Lake Storage. Modifiez cette valeur pour choisir un autre compte ADLS.
- Dossier d’entrée Dossier dans ADLS où résident les données chargées dans cette table. Vous pouvez parcourir l’emplacement du dossier ou le modifier manuellement à l’aide de l’icône de crayon.
- Format de données Format des données figurant dans le Dossier d’entrée. Les bases de données de lac dans Azure Synapse prennent en charge les formats de fichier Parquet et de texte délimité comme formats de stockage pour les données. Si le format de données ne correspond pas aux données figurant dans le dossier, les requêtes sur la table échouent.
Pour un format de données de texte délimité, il existe d’autres paramètres :
- En-têtes de lignes Activez cette case si les données comprennent des en-têtes de lignes.
- Activez la case à cocher multiligne dans les données si les données ont plusieurs lignes dans une colonne de chaîne.
- Le caractère de guillemet spécifie le caractère de guillemet personnalisé pour un fichier texte délimité.
- Caractère d’échappement spécifiant le caractère d’échappement personnalisé pour un fichier texte délimité.
- Compression des données Type de compression utilisé sur les données.
- Délimiteur Délimiteur de champ utilisé dans les fichiers de données. Les valeurs prises en charge sont les suivantes : virgule (,), tabulation (\t) et barre verticale (|).
- Colonnes de partition, la liste des colonnes de partition s’affiche ici.
- Ajout possible cochez cette case si vous interrogez des données Dataverse à partir de SQL Serverless.
Pour des données Parquet, il y a le paramètre suivant :
- Compression des données Type de compression utilisé sur les données.
Colonnes
L’onglet Colonnes est l’endroit où les colonnes de la table sont répertoriées et peuvent être modifiées. Sous cet onglet figurent deux listes de colonnes : Colonnes standard et Colonnes de partition. Les Colonnes standard incluent toute colonne qui stocke des données, est une clé primaire et n’est pas utilisée pour le partitionnement des données. Les Colonnes de partition stockent également des données, mais sont utilisées pour partitionner les données sous-jacentes dans des dossiers en fonction des valeurs contenues dans la colonne. Chaque colonne a les propriétés suivantes.
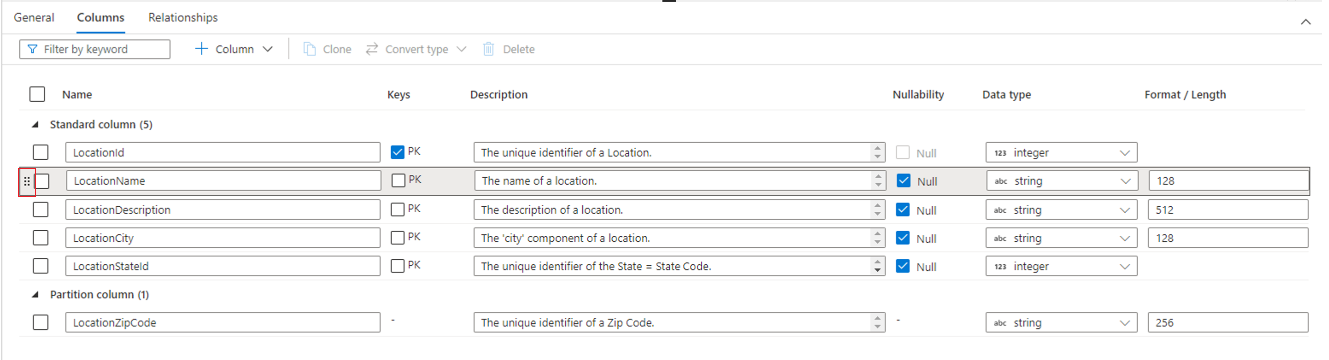
- Nom Nom de la colonne. Doit être unique dans la table.
- Les clés indiquent si la colonne est une clé primaire (PK) et/ou une clé étrangère (FK) pour la table. Non applicable aux colonnes de partition.
- Description Description de la colonne. Si la colonne a été créée à partir d’un modèle de base de données, la description du concept que cette colonne représente est visible. Vous pouvez modifier ce champ pour le faire correspondre à la description de vos besoins métier.
- Possibilité de valeur Null Indique cette colonne peut contenir des valeurs Null. Non applicable aux colonnes de partition.
- Type de données Définit le type de données de la colonne en fonction de la liste des types de données Spark disponibles.
- Format / Longueur Permet de personnaliser le format ou la longueur maximale de la colonne, en fonction du type de données. Les types de données date et horodatage comportent des listes déroulantes de formats, et d’autres types tels que chaîne ont un champ de longueur maximale. Certains types de données n’ont pas une valeur, car ils sont de longueur fixe. En haut de l’onglet Colonnes figure une barre de commandes permettant d’interagir avec les colonnes.
- Filtrer par mot clé Filtre la liste des colonnes sur les éléments correspondant au mot clé spécifié.
-
+ Colonne Permet d’ajouter une nouvelle colonne. Il existe trois options possibles.
- Nouvelle colonne Crée une colonne standard personnalisée.
- À partir d’un modèle Ouvre le volet exploration qui vous permet d’identifier les colonnes d’un modèle de base de données à inclure dans votre table. Si votre base de données n’a pas été créée à l’aide d’un modèle de base de données, cette option n’apparaît pas.
- Colonne de partition Ajoute une nouvelle colonne de partition personnalisée.
- Cloner Duplique la colonne sélectionnée. Les colonnes clonées sont toujours du même type que la colonne sélectionnée.
- Convertir le type Option utilisée pour modifier la colonne standard sélectionnée en colonne de partition et inversement. Cette option est grisée si vous avez sélectionné plusieurs colonnes de types différents, ou si la colonne sélectionnée n’est pas éligible pour une conversion en raison de la présence d’un indicateur PK ou Possibilité de valeur Null défini sur la colonne.
- Supprimer Supprime les colonnes sélectionnées de la table. Cette action est irréversible.
Vous pouvez également réorganiser l’ordre des colonnes en faisant glisser-déplacer à l’aide des points de suspension verticaux doubles qui s’affichent à gauche du nom de colonne lorsque vous pointez ou cliquez sur la colonne comme indiqué dans l’image ci-dessus.
Colonnes de partition
Des colonnes de partition sont utilisées pour partitionner les données physiques dans votre base de données en fonction des valeurs figurant dans ces colonnes. Les colonnes de partition offrent un moyen simple de distribuer les données sur le disque dans des blocs plus performants. Les colonnes de partition dans Azure Synapse sont toujours à la fin du schéma de table. En outre, elles sont utilisés de haut en bas lors de la création des dossiers de partition. Par exemple, si vos colonnes de partition sont Année et Mois, vous obtenez dans ADLS une structure telle que la suivante :
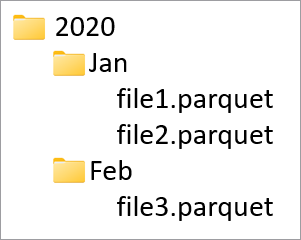
Où fichier1 et fichier2 contenaient toutes les lignes dans lesquelles les valeurs d’Année et de Mois étaient respectivement 2020 et Jan. À mesure que des colonnes de partition sont ajoutées à une table, des fichiers sont ajoutés à cette hiérarchie, ce qui a pour effet de réduire la taille de fichier globale des partitions.
Azure Synapse n’applique pas ou ne crée pas cette hiérarchie en ajoutant des colonnes de partition à une table. Les données doivent être chargées dans la table à l’aide de pipelines Synapse ou d’un bloc-notes Spark dans l’ordre de création de la structure de partition.
Relations
L’onglet Relations vous permet de spécifier les relations entre les tables de la base de données. Les relations dans le concepteur de base de données sont informatives. Elles n’appliquent pas de contraintes aux données sous-jacentes. Elles sont lues par d’autres applications Microsoft, et peuvent être utilisées pour accélérer des transformations ou fournir aux utilisateurs des informations sur la manière dont les tables sont reliées. Le volet Relations contient les informations suivantes.
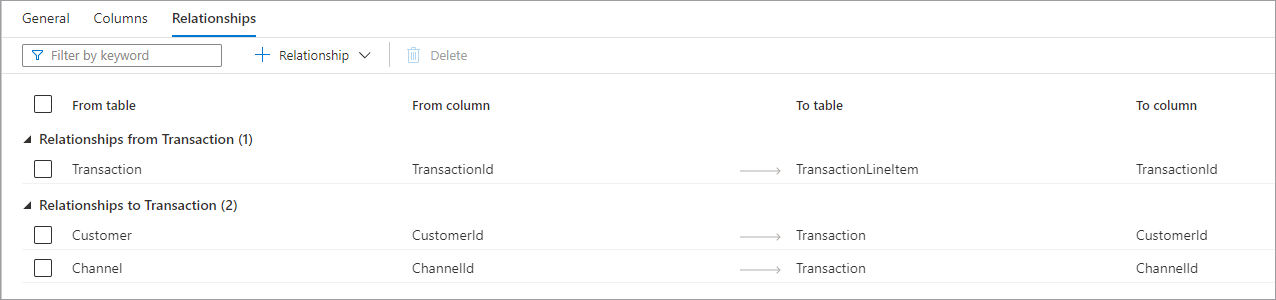
- Relations à partir de (table) S’affichent quand une ou plusieurs tables ont des clés étrangères connectées à cette table. C’est ce qu’on appelle parfois une relation parent.
- Relations à (table) S’affichent quand une table a une clé étrangère et est connectée à une autre table. C’est ce qu’on appelle parfois une relation enfant.
- Les deux types de relations ont les propriétés suivantes.
- À partir de la table Table parent dans la relation, ou côté « un ».
- À partir de la colonne Colonne dans la table parent sur laquelle la relation est basée.
- À la table Table enfant dans la relation, ou côté « plusieurs ».
- À la colonne Colonne dans la table enfant sur laquelle la relation est basée. En haut de l’onglet Relations figure la barre de commandes permettant d’interagir avec les relations.
- Filtrer par mot clé Filtre la liste des colonnes sur les éléments correspondant au mot clé spécifié.
-
+ Relation Permet d’ajouter une nouvelle relation. Il existe deux options.
- À partir de la table Crée une relation à partir de la table sur laquelle vous travaillez vers une autre table.
- À la table Crée une relation à partir d’une autre table vers celle sur laquelle vous travaillez.
- À partir d’un modèle Ouvre le volet d’exploration qui vous permet de choisir dans le modèle de base de données les relations à inclure dans votre base de données. Si votre base de données n’a pas été créée à l’aide d’un modèle de base de données, cette option n’apparaît pas.
Étapes suivantes
Continuez à explorer les fonctionnalités du concepteur de base de données en suivant les liens ci-dessous.