Niveau de compatibilité pour les travaux Azure Stream Analytics
Cet article décrit l’option de niveau de compatibilité d’Azure Stream Analytics.
Stream Analytics est un service géré régulièrement enrichi de nouvelles fonctionnalités et d’améliorations des performances constantes. La plupart des mises à jour de runtime du service sont automatiquement accessibles aux utilisateurs finaux, indépendamment du niveau de compatibilité. Toutefois, lorsqu’une nouvelle fonctionnalité introduit un changement de comportement des tâches existantes, ou un changement dans la manière dont les données sont consommées dans les tâches en cours d’exécution, nous présentons ce changement sous un nouveau niveau de compatibilité. Si vous souhaitez que vos travaux Stream Analytics existants continuent de s’exécuter sans changement majeur, laissez le paramètre de niveau de compatibilité défini sur une valeur faible. Lorsque vous êtes prêt à intégrer les derniers comportements de runtime, vous pouvez les accepter en augmentant le niveau de compatibilité.
Choisir un niveau de compatibilité
Le niveau de compatibilité contrôle le comportement d’exécution d’un travail Stream Analytics.
Azure Stream Analytics prend actuellement en charge trois niveaux de compatibilité :
- 1.2 : comportement le plus récent avec les améliorations les plus récentes
- 1.1 : comportement précédent
- 1.0 : le niveau de compatibilité d’origine a été introduit dans la version en disponibilité générale d’Azure Stream Analytics voici quelques années.
Lorsque vous créez un travail Stream Analytics, il est recommandé de le créer à l’aide du dernier niveau de compatibilité. Démarrez votre conception de travail en vous basant sur les derniers comportements afin d’éviter un ajout de complexité et de modifications par la suite.
Définition du niveau de compatibilité
Vous pouvez définir le niveau de compatibilité d’un travail Stream Analytics dans le Portail Azure ou en appelant l’API REST de création d’un travail.
Pour mettre à jour le niveau de compatibilité du travail dans le Portail Azure :
- Utilisez le Portail Azure pour accéder à votre travail Stream Analytics.
- Interrompez le travail à l’aide de la commande Arrêter avant de mettre à jour le niveau de compatibilité. Si votre travail est en cours d’exécution, vous ne pouvez pas mettre à jour le niveau de compatibilité.
- Sous le titre Configurer, sélectionnez Niveau de compatibilité.
- Choisissez la valeur de niveau de compatibilité souhaitée.
- Sélectionnez Enregistrer au bas de la page.
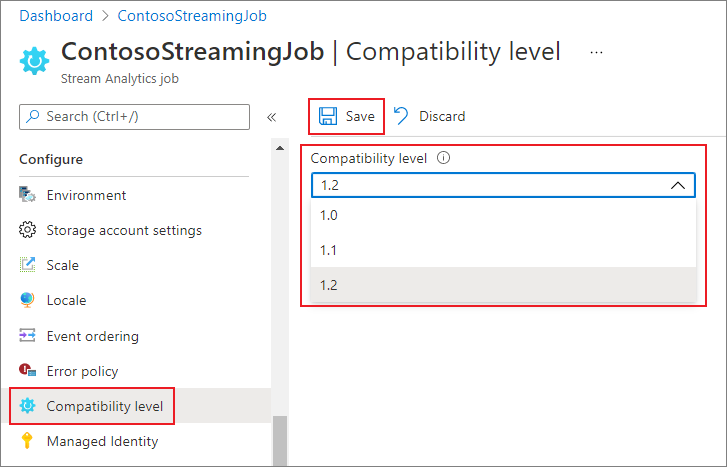
Quand vous mettez à jour le niveau de compatibilité, le compilateur T valide le travail avec la syntaxe correspondant au niveau de compatibilité sélectionné.
Niveau de compatibilité 1.2
Les principales modifications introduites dans le niveau de compatibilité 1.2 sont les suivantes :
Protocole de messagerie AMQP
Niveau 1.2 : Azure Stream Analytics utilise le protocole de messagerie AMQP (Advanced Message Queueing Protocol) pour écrire dans les files d’attente et les rubriques Service Bus. Le protocole AMQP vous permet de développer des applications hybrides interplateforme à l’aide d’un protocole open standard.
Fonctions géospatiales
Niveaux précédents : Azure Stream Analytics utilisait des calculs de type Géographie.
Niveau 1.2 : Azure Stream Analytics vous permet de calculer des coordonnées géographiques projetées de type Géométrique. Il n’existe aucune modification au niveau de la signature des fonctions géospatiales. Toutefois, leur sémantique a légèrement changé et améliore la précision des calculs.
Azure Stream Analytics prend en charge l’indexation des données de référence géospatiales. Les données de référence contenant des éléments géospatiaux peuvent être indexés afin d’accélérer les calculs.
Les fonctions géospatiales mises à jour offrent l’expressivité totale du format géospatial WKT (Well Known Text). Vous pouvez spécifier d’autres composants géospatiaux qui n’étaient précédemment pas pris en charge avec GeoJson.
Pour plus d’informations, consultez le billet de blog Updates to geospatial features in Azure Stream Analytics – Cloud and IoT Edge (Mises à jour des fonctionnalités géospatiales dans Azure Stream Analytics - Cloud et IoT Edge).
Exécution de requêtes en parallèle pour les sources d’entrée avec plusieurs partitions
Niveaux précédents : les requêtes Azure Stream Analytics nécessitaient l’utilisation de la clause PARTITION BY pour paralléliser le traitement des requêtes dans l’ensemble des partitions de source d’entrée.
Niveau 1.2 : si la logique de requête peut être parallélisée sur toutes les partitions de source d’entrée, Azure Stream Analytics crée des instances de requête distinctes et exécute les calculs en parallèle.
Intégration de l’API en bloc en mode natif à la sortie Azure Cosmos DB
Niveaux précédents : le comportement de l’opération upsert était insert or merge (insérer ou fusionner).
Niveau 1.2 : L’intégration de l’API en bloc en mode natif à la sortie Azure Cosmos DB optimise le débit et gère efficacement les requêtes de limitation. Pour plus d’informations, consultez l’article Azure Stream Analytics output to Azure Cosmos DB (Sortie Azure Stream Analytics dans Azure Cosmos DB).
Le comportement de l’opération upsert est insert or replace (insérer ou remplacer).
Utilisation de DateTimeOffset lors de l’écriture dans une sortie SQL
Niveaux précédents : Les types DateTimeOffset étaient ajustés au format temps universel coordonné (UTC).
Niveau 1.2 : DateTimeOffset n’est plus ajusté.
Long lors de l’écriture dans une sortie SQL
Niveaux précédents : Les valeurs ont été tronquées en fonction du type cible.
Niveau 1.2 : Les valeurs qui ne tiennent pas dans le type cible sont traitées en fonction de la stratégie d’erreur de sortie.
Sérialisation des enregistrements et des tableaux lors de l’écriture dans la sortie SQL
Niveaux précédents : Les enregistrements étaient écrits en tant que « Record » (Enregistrement) et les tableaux l’étaient en tant que « Array » (Tableau).
Niveau 1.2 : Les enregistrements et les tableaux sont sérialisés au format JSON.
Validation stricte des préfixes de fonction
Niveaux précédents : il n’existait aucune validation stricte des préfixes de fonction.
Niveau 1.2 : Azure Stream Analytics applique une validation stricte des préfixes de fonction. L’ajout d’un préfixe à une fonction intégrée entraîne une erreur. Par exemple, myprefix.ABS(…) n’est pas pris en charge.
L’ajout d’un préfixe à des agrégats intégrés engendre également une erreur. Par exemple, myprefix.SUM(…) n’est pas pris en charge.
L’utilisation du préfixe "system" pour des fonctions définies par l’utilisateur entraîne une erreur.
Interdiction des types Array et Object en tant que propriétés de clé dans l’adaptateur de sortie Azure Cosmos DB
Niveaux précédents : les types Array et Object étaient pris en charge comme propriétés de clé.
Niveau 1.2 : les types Array et Object ne sont plus pris en charge comme propriétés de clé.
Désérialisation du type booléen dans JSON, AVRO et PARQUET
Niveaux précédents : Azure Stream Analytics désérialise la valeur booléenne en un type BIGINT (false map en 0 et true map en 1). La sortie ne crée que des valeurs booléennes dans JSON, AVRO et PARQUET, si vous convertissez explicitement les événements en BIT.
Par exemple, une requête directe telle que la SELECT value INTO output1 FROM input1lecture d’un JSON{ "value": true } depuis entrée1 écrit dans sortie1 une valeur JSON { "value": 1 }.
Niveau 1.2 : Azure Stream Analytics désérialise la valeur booléenne en un type BIT. False map en 0 et true map en 1. Une requête directe telle que la SELECT value INTO output1 FROM input1lecture d’un JSON{ "value": true } depuis entrée1 écrit dans sortie1 une valeur JSON { "value": true }. Vous pouvez caster la valeur en un type BIT dans la requête pour vous assurer qu’elles apparaissent comme true et false dans la sortie pour les formats prenant en charge le type booléen.
Niveau de compatibilité 1.1
Voici les principales modifications introduites dans le niveau de compatibilité 1.1 :
Format XML de Service Bus
Niveau 1.0 : Azure Stream Analytics utilisait DataContractSerializer, c’est pourquoi le contenu des messages incluait des balises XML. Par exemple :
@\u0006string\b3http://schemas.microsoft.com/2003/10/Serialization/\u0001{ "SensorId":"1", "Temperature":64\}\u0001
Niveau 1.1 : le contenu du message renferme directement le flux sans aucune balise supplémentaire. Par exemple : { "SensorId":"1", "Temperature":64}
Conservation de la casse des noms de champ
Niveau 1.0 : les noms de champs passaient en minuscules au moment du traitement par le moteur Azure Stream Analytics.
Niveau 1.1 : la casse des noms de champ est préservée lorsque ces derniers sont traités par le moteur Azure Stream Analytics.
Notes
La conservation de la casse n’est pas encore disponible pour les tâches Stream Analytics hébergés à l’aide de l’environnement Edge. Par conséquent, tous les noms de champs sont convertis en minuscules si votre tâche est hébergée sur Edge.
FloatNaNDeserializationDisabled
Niveau 1.0 : la commande CREATE TABLE n’a pas filtré les événements avec NaN (N’est pas un nombre. Par exemple, Infini, -Infini) dans un type de colonne FLOAT, car ils sont en dehors de la plage documentée pour ces nombres.
Niveau 1.1 : la commande CREATE TABLE vous permet de spécifier un schéma fort. Le moteur Stream Analytics vérifie que les données sont conformes à ce schéma. Avec ce modèle, la commande peut filtrer des événements avec des valeurs NaN.
Désactiver la conversion automatique des chaînes datetime en type DateTime à l’entrée pour JSON
Niveau 1.0 : L’analyseur JSON convertit automatiquement les valeurs de chaîne contenant des informations de date/heure/zone en type DATETIME à l’entrée, de sorte que la valeur perd immédiatement ses informations de mise en forme d’origine et de fuseau horaire. Dans la mesure où cette opération est effectuée à l’entrée, même si ce champ n’a pas été utilisé dans la requête, il est converti en DateTime UTC.
Niveau 1.1 : Il n’y a pas de conversion automatique des valeurs de chaîne contenant des informations de date/heure/zone en type DATETIME. Par conséquent, les informations de fuseau horaire et la mise en forme d’origine sont conservées. Toutefois, si le champ NVARCHAR(MAX) est utilisé dans la requête dans le cadre d’une expression DATETIME (fonction DATEADD, par exemple), il est converti en type DATETIME pour effectuer le calcul et il perd sa forme d’origine.
Étapes suivantes
- Résoudre les problèmes liés aux entrées Azure Stream Analytics
- Stream Analytics Resource health (Intégrité des ressources Stream Analytics)