Configurer les paramètres de l’Agent MQTT pour la haute disponibilité, la mise à l’échelle et l’utilisation de la mémoire
La ressource Broker est la ressource principale qui définit les paramètres globaux pour un Agent MQTT. Elle détermine également le nombre et le type de pods qui exécutent la configuration Broker, comme les serveurs frontaux et principaux. Vous pouvez également utiliser la ressource Broker pour configurer son profil de mémoire. Les mécanismes self-healing sont intégrés au répartiteur et peuvent souvent se remettre automatiquement de défaillances des composants. Par exemple, cela pourrait être un nœud qui échoue dans un cluster Kubernetes configuré pour la haute disponibilité.
Vous pouvez mettre à l’échelle horizontalement l’Agent MQTT en ajoutant d’autres réplicas front-end et d’autres partitions back-end. Les réplicas front-end sont responsables de l’acceptation des connexions MQTT à partir de clients et de leur transfert vers les partitions back-end. Les partitions back-end sont responsables du stockage et de la remise des messages aux clients. Les pods de front-end distribuent le trafic de messages entre tous les pods principaux. Le facteur de redondance des principaux détermine le nombre de copies de données nécessaires pour fournir une résilience contre les défaillances de nœuds dans le cluster.
Pour obtenir la liste des paramètres disponibles, consultez les informations de référence sur l’API de broker.
Configurer les paramètres de mise à l’échelle
Important
Ce paramètre nécessite la modification de la ressource Broker. Il est configuré uniquement lors du déploiement initial à l’aide d’Azure CLI ou du portail Azure. S’il est nécessaire de modifier la configuration Broker, un nouveau déploiement est requis. Pour en savoir plus, consultez Personnaliser l’Agent par défaut.
Pour configurer les paramètres de mise à l’échelle de l’Agent MQTT, spécifiez les champs de cardinalité dans la spécification de la ressource Broker pendant le déploiement d’Opérations Azure IoT.
Cardinalité de déploiement automatique
Pour déterminer automatiquement la cardinalité initiale pendant le déploiement, omettez le champ de cardinalité dans la ressource Broker.
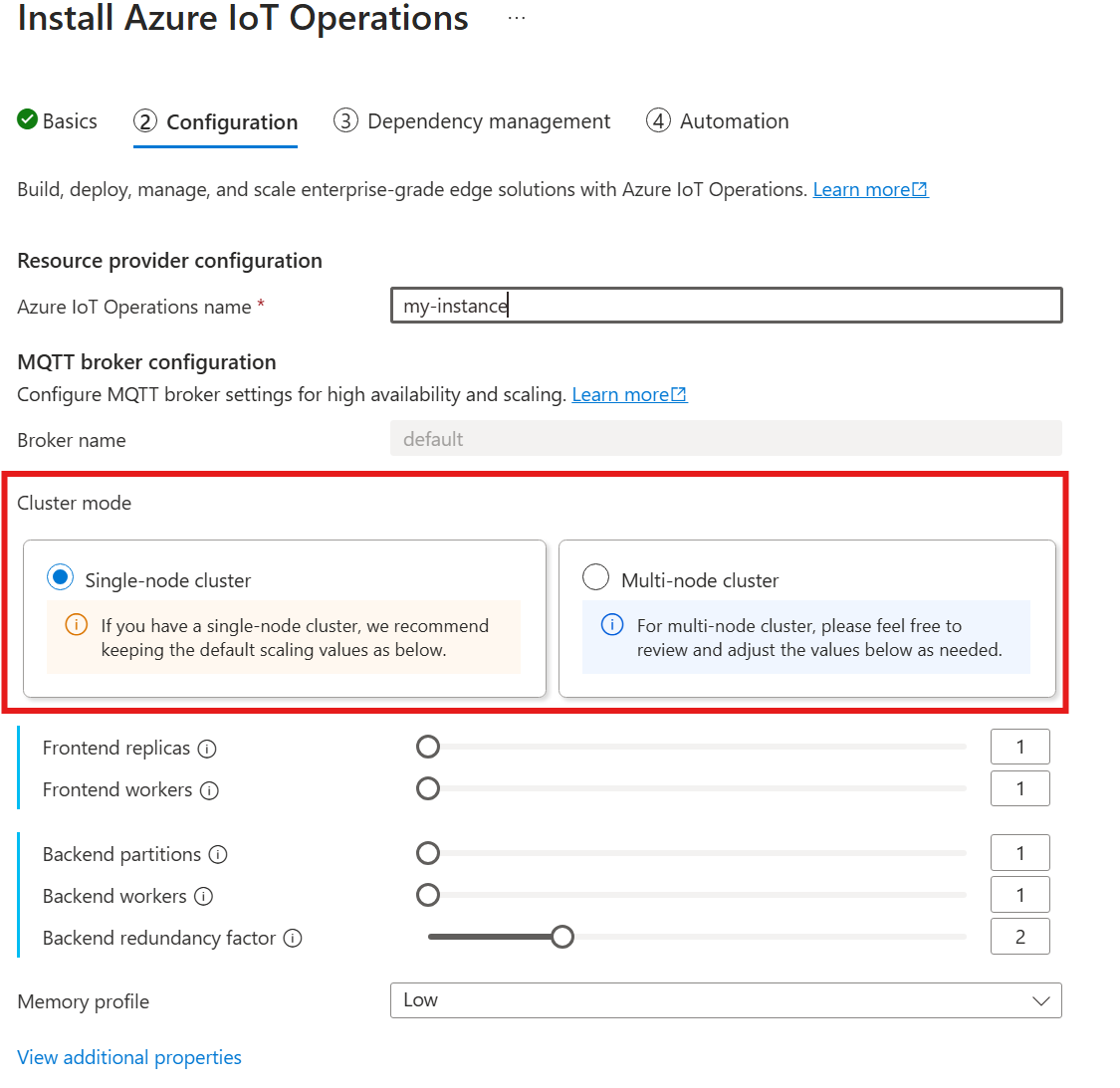
La cardinalité automatique n’est pas encore prise en charge lors du déploiement d’Opérations IoT via le Portail Azure. Vous pouvez spécifier manuellement le mode de déploiement du cluster en tant que Nœud unique ou Multinœuds. Pour en savoir plus, veuillez consulter la section Déployer des opérations Azure IoT.
L’opérateur MQTT broker déploie automatiquement le nombre approprié de pods en fonction du nombre de nœuds disponibles au moment du déploiement. Cette fonctionnalité est utile pour les scénarios hors production où vous n’avez pas besoin de mise à l’échelle ou de haute disponibilité.
Cette fonctionnalité ne se met pas automatiquement à l’échelle. L’opérateur ne met pas automatiquement à l’échelle le nombre de pods en fonction de la charge. L’opérateur détermine le nombre initial de pods à déployer uniquement en fonction du matériel du cluster. Comme indiqué précédemment, la cardinalité est définie uniquement au moment du déploiement initial. Un nouveau déploiement est nécessaire si les paramètres de cardinalité doivent être modifiés.
Configurer directement la cardinalité
Pour configurer directement les paramètres de cardinalité, spécifiez chacun des champs de cardinalité.
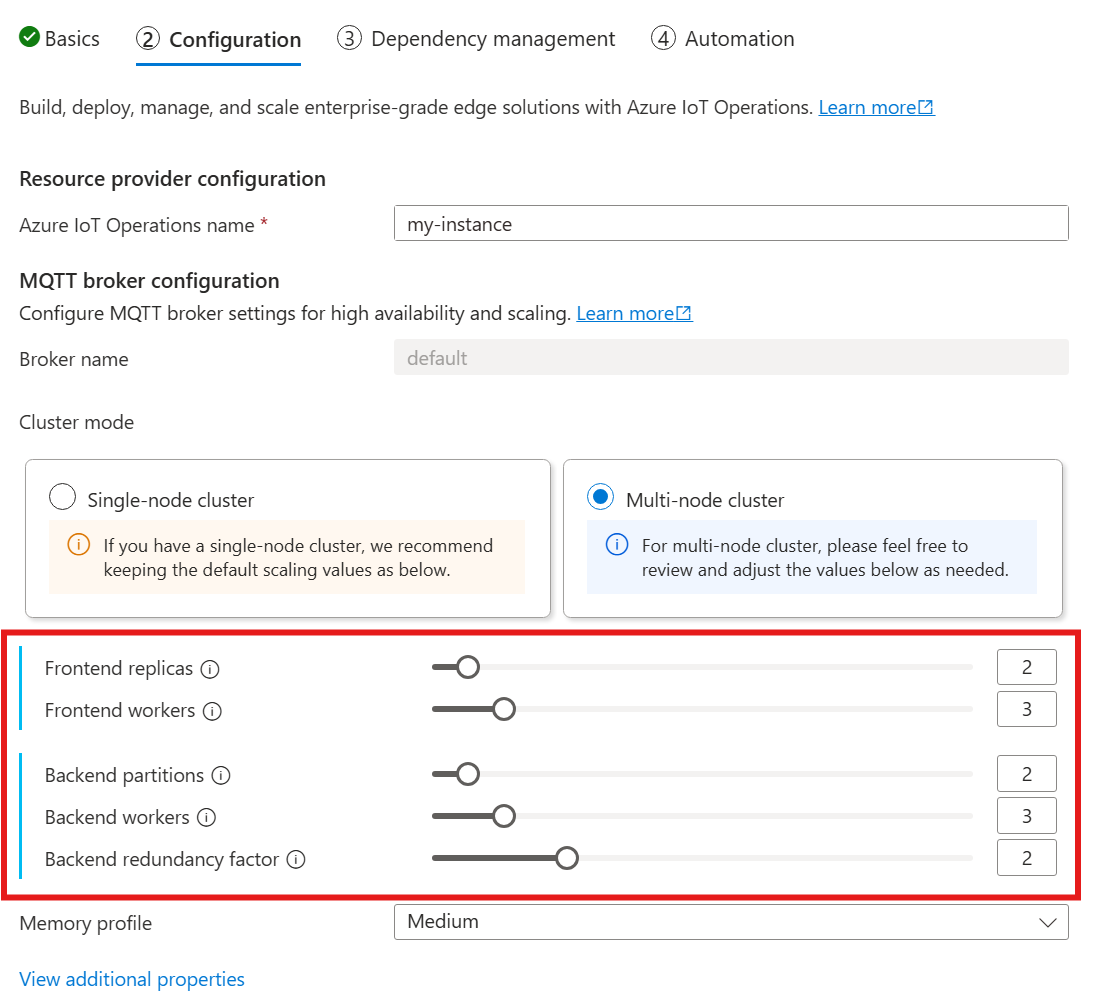
Lorsque vous suivez le guide pour déployer les opérations IoT, dans la section Configuration, regardez sous Configuration du courtier MQTT. Ici, vous pouvez spécifier le nombre de réplicas front-end, de partitions back-end et de Workers back-end.
Comprendre la cardinalité
La cardinalité est le nombre d’instances d’une entité particulière dans un jeu. Dans le contexte de l’Agent MQTT, la cardinalité fait référence au nombre de réplicas front-end, de partitions back-end et de Workers back-end à déployer. Les paramètres de cardinalité sont utilisés pour mettre à l’échelle le répartiteur horizontalement et améliorer la haute disponibilité en cas de défaillance de pod ou de nœud.
Le champ de cardinalité est un champ imbriqué doté de sous-champs pour les chaînes front-end et principale. Chacun de ces sous-champs a ses propres paramètres.
Serveur frontal
Le sous-champ frontend définit les paramètres des pods front-end. Les deux paramètres principaux sont les suivants :
- Réplicas : nombre de réplicas front-end (pods) à déployer. L’augmentation du nombre de réplicas front-end offre une haute disponibilité en cas de défaillance de l’un des pods front-end.
- Workers : nombre de Workers front-end logiques par réplica. Chaque Worker peut consommer jusqu’à un cœur de processeur au maximum.
Chaîne back-end
Le sous-champ de chaîne back-end définit les paramètres des partitions back-end. Les trois principaux paramètres sont les suivants :
- Partitions : nombre de partitions à déployer. Grâce à un processus appelé partitionnement, chaque partition est responsable d’une partie des messages, divisés par ID de sujet et ID de session. Les pods front-end distribuent le trafic de messages sur toutes les partitions. L’augmentation du nombre de partitions augmente le nombre de messages que le Broker peut traiter.
- Facteur de redondance : le nombre de réplicas principaux (pods) à déployer par partition. L’augmentation du facteur de redondance augmente le nombre de copies de données pour fournir une résilience contre les défaillances de nœud dans le cluster.
- Workers : nombre de Workers à déployer par réplica back-end. Il se peut que l’augmentation du nombre de Workers par réplica principal augmente le nombre de messages que le pod principal est capable de traiter. Chaque Worker peut consommer jusqu’à deux cœurs d’UC. Ainsi, lorsque vous augmentez le nombre de Workers par réplica, faites attention à ne pas dépasser le nombre de cœurs d’UC dans le cluster.
À propos de l’installation
Lorsque vous augmentez les valeurs de cardinalité, la capacité du Broker à traiter davantage de connexions et de messages s’améliore généralement, et cela optimise la haute disponibilité en cas de défaillance de nœud ou de pod. Cette capacité accrue provoque également une consommation de ressources plus élevée. Par conséquent, lorsque vous ajustez les valeurs de cardinalité, tenez compte des paramètres du profil de mémoire et des demandes de ressources d’UC de l’agent. L’augmentation du nombre de Workers par réplica front-end peut aider à augmenter l’utilisation du cœur de processeur si vous découvrez que l’utilisation du processeur front-end est un goulot d’étranglement. L’augmentation du nombre de Workers principaux peut aider à améliorer le débit des messages si l’utilisation de l’UC principale est un goulot d’étranglement.
Par exemple, si votre cluster a trois nœuds, chacun doté de huit cœurs d’UC, définissez le nombre de réplicas front-end de façon à ce qu’il corresponde au nombre de nœuds (3) et définissez le nombre de Workers sur 1. Définissez le nombre de partitions principales de façon à ce qu’il corresponde au nombre de nœuds (3) et définissez le nombre de Workers principaux sur 1. Définissez le facteur de redondance comme vous le souhaitez (2 ou 3). Augmentez le nombre de Workers front-end si vous découvrez que l’utilisation de l’UC front-end est un goulot d’étranglement. N’oubliez pas que les Workers principaux et front-end peuvent entrer en concurrence entre eux et avec d’autres pods pour les ressources d’UC.
Configurer le profil de mémoire
Important
Ce paramètre vous oblige à modifier la ressource Broker. Il est configuré uniquement lors du déploiement initial à l’aide d’Azure CLI ou du portail Azure. S’il est nécessaire de modifier la configuration Broker, un nouveau déploiement est requis. Pour en savoir plus, consultez Personnaliser l’Agent par défaut.
Pour configurer les paramètres de profil de mémoire de l’Agent MQTT, spécifiez les champs de profil de mémoire dans la spécification de la ressource Broker pendant le déploiement d’Opérations IoT.
Lorsque vous utilisez le guide suivant pour déployer des Opérations IoT, dans la section Configuration, consultez Configuration de l’Agent MQTT et recherchez le paramètre Profil de mémoire. Ici, vous pouvez sélectionner parmi les profils de mémoire disponibles dans une liste déroulante.
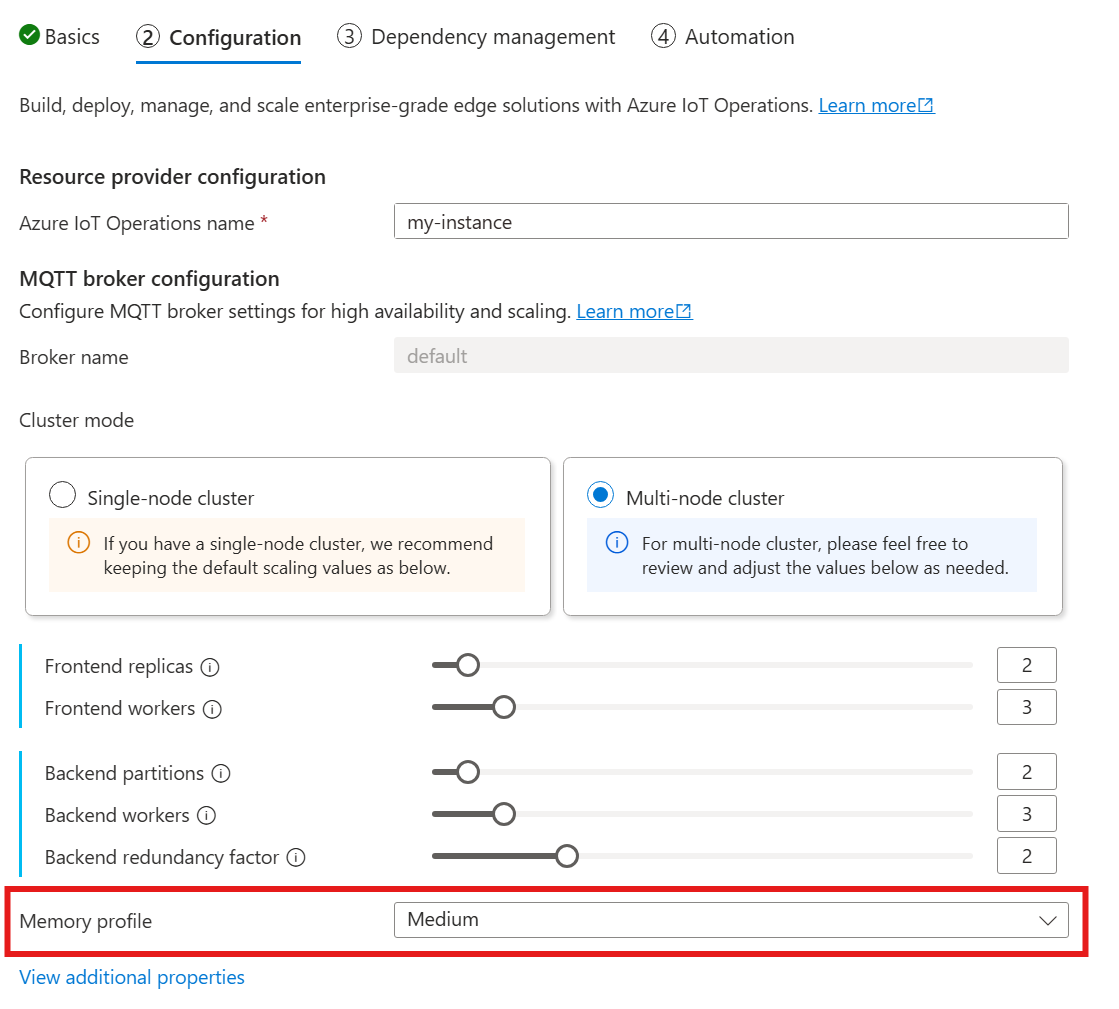
Vous avez le choix entre quelques profils de mémoire, chacun présentant des caractéristiques d’utilisation de la mémoire différentes.
Petit
Lorsque vous utilisez ce profil :
- L’utilisation maximale de la mémoire de chaque réplica front-end est d’environ 99 Mio, mais l’utilisation maximale réelle de la mémoire pourrait être plus élevée.
- L’utilisation maximale de la mémoire de chaque réplica back-end est d’environ 102 Mio multipliée par le nombre de Workers back-end, mais l’utilisation maximale réelle de la mémoire peut être plus élevée.
Recommandations lorsque vous utilisez ce profil :
- Un seul serveur front-end doit être utilisé.
- Les clients ne doivent pas envoyer de paquets volumineux. Vous devez uniquement envoyer des paquets inférieurs à 4 Mio.
Faible
Lorsque vous utilisez ce profil :
- L’utilisation maximale de la mémoire de chaque réplica front-end est d’environ 387 Mio, mais l’utilisation maximale réelle de la mémoire pourrait être plus élevée.
- L’utilisation maximale de la mémoire de chaque réplica back-end est d’environ 390 Mio multipliée par le nombre de workers back-end, mais l’utilisation maximale réelle de la mémoire peut être plus élevée.
Recommandations lorsque vous utilisez ce profil :
- Uniquement un ou deux serveurs front-end doivent être utilisés.
- Les clients ne doivent pas envoyer de paquets volumineux. Vous devez uniquement envoyer des paquets inférieurs à 10 Mio.
Moyenne
Média est le profil par défaut.
- L’utilisation maximale de la mémoire de chaque réplica front-end est d’environ 1,9 Gio, mais l’utilisation maximale réelle de la mémoire pourrait être plus élevée.
- L’utilisation maximale de la mémoire de chaque réplica back-end est d’environ 1,5 Gio multipliée par le nombre de workers back-end, mais l’utilisation maximale réelle de la mémoire peut être plus élevée.
Élevé
- L’utilisation maximale de la mémoire de chaque réplica front-end est d’environ 4,9 Gio, mais l’utilisation maximale réelle de la mémoire pourrait être plus élevée.
- L’utilisation maximale de la mémoire de chaque réplica back-end est d’environ 5,8 Gio multipliée par le nombre de workers back-end, mais l’utilisation maximale réelle de la mémoire peut être plus élevée.
Cardinalité et limites de ressources Kubernetes
Pour éviter la pénurie de ressources dans le cluster, le Broker est configuré par défaut pour demander les limites de ressources de processeur Kubernetes. La mise à l’échelle du nombre de réplicas ou de Workers augmente proportionnellement les ressources de processeur requises. Une erreur de déploiement est émise si les ressources de processeur disponibles dans le cluster sont insuffisantes. Cette notification vous permet d’éviter les situations où la cardinalité demandée de l’agent ne dispose pas des ressources suffisantes pour s’exécuter de manière optimale. Cela permet également d’éviter la contention potentielle de processeur et les évictions de pod.
L’Agent MQTT demande actuellement une (1,0) unité d’UC par Worker front-end et deux (2,0) unités d’UC par Worker principal. Pour plus d’informations, consultez Unités de ressources d’UC Kubernetes.
Par exemple, la cardinalité suivante demanderait les ressources d’UC suivantes :
- Pour les front-ends : 2 unités d’UC par pod front-end, soit 6 unités d’UC au total.
- Pour les principaux : 4 unités d’UC par pod principal (pour deux Workers principaux), multiplié par 2 (facteur de redondance), multiplié par 3 (nombre de partitions), soit au total 24 unités d’UC.
{
"cardinality": {
"frontend": {
"replicas": 3,
"workers": 2
},
"backendChain": {
"partitions": 3,
"redundancyFactor": 2,
"workers": 2
}
}
}
Pour désactiver ce paramètre, affectez la valeur Disabled au champ generateResourceLimits.cpu dans la ressource Broker.
La modification du champ generateResourceLimits n’est pas prise en charge dans le portail Azure. Pour désactiver ce paramètre, utilisez Azure CLI.
Déploiement multi-nœud
Pour garantir la haute disponibilité et la résilience des déploiements multinœuds, l’Agent MQTT des Opérations IoT définit automatiquement des règles anti-affinité pour les pods principaux.
Ces règles sont prédéfinies et ne peuvent pas être modifiées.
Objectif des règles d’anti-affinité
Les règles d’anti-affinité garantissent que les pods back-end de la même partition ne s’exécutent pas sur le même nœud. Cette fonctionnalité permet de distribuer la charge et fournit une résilience contre les défaillances de nœud. Plus précisément, les pods back-end de la même partition ont une anti-affinité les uns avec les autres.
Vérifier les paramètres anti-affinité
Pour vérifier les paramètres d’anti-affinité pour un pod back-end, utilisez la commande suivante :
kubectl get pod aio-broker-backend-1-0 -n azure-iot-operations -o yaml | grep affinity -A 15
La sortie affiche la configuration anti-affinité, comme dans l’exemple suivant :
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: chain-number
operator: In
values:
- "1"
topologyKey: kubernetes.io/hostname
weight: 100
Ces règles sont les seules règles anti-affinité définies pour l’agent.