Présentation d’Apache Spark Structured Streaming
Apache Spark Structured Streaming vous permet d’implémenter des applications évolutives, à haut débit et à tolérance de panne pour le traitement des flux de données. Structured Streaming repose sur le moteur Spark SQL et offre des améliorations par rapport aux constructions des trames de données et jeux de données Spark SQL afin de vous permettre d’écrire des requêtes de diffusion en continu selon la même procédure que pour les requêtes par lot.
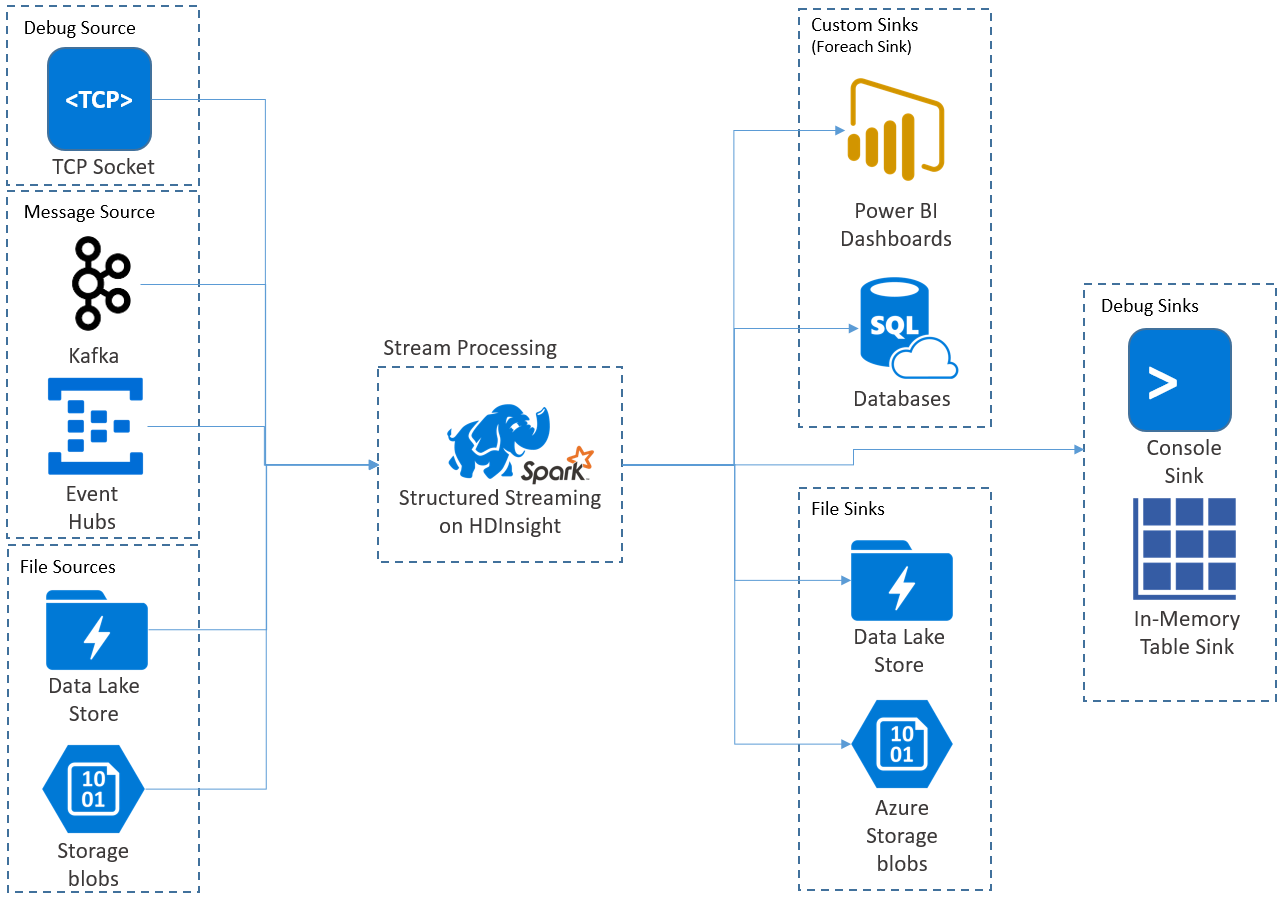
Les applications Structured Streaming s’exécutent sur les clusters HDInsight Spark et se connectent aux données de streaming provenant d’Apache Kafka, d’un socket TCP (pour le débogage), du stockage Azure ou d’Azure Data Lake Storage. Les deux dernières options, qui reposent sur des services de stockage externes, permettent de surveiller les nouveaux fichiers qui ont été ajoutés dans le stockage et de traiter leur contenu comme s’ils avaient été diffusés en continu.
Structured Streaming crée une longue requête au cours de laquelle vous appliquez des opérations sur les données d’entrée, par exemple des opérations de sélection, de projection, d’agrégation, de fenêtrage et de jointure de la trame de données de diffusion en continu avec les trames de données de référence. Les résultats sont ensuite transférés au stockage de fichiers (objets Blob du stockage Azure ou instance de Data Lake Storage), ou à n’importe quel magasin de données par le biais d’un code personnalisé (par exemple, SQL Database ou Power BI). Structured Streaming transmet également des données de sortie à la console à des fins de débogage en local, ainsi qu’à une table en mémoire afin que vous puissiez afficher les données générées pour le débogage dans HDInsight.
Remarque
Spark Structured Streaming remplace Spark Streaming (DStreams). Structured Streaming bénéficiera d’améliorations et fera l’objet d’une maintenance, contrairement à DStreams qui sera proposé uniquement en mode maintenance. Structured Streaming n’intègre pas pour le moment autant de fonctionnalités que DStreams pour les sources et les récepteurs immédiatement pris en charge. Veillez donc à bien évaluer vos besoins pour choisir l’option de traitement de flux de données Spark qui vous convient le mieux.
Flux de données sous forme de tables
Spark Structured Streaming représente un flux de données sous la forme d’une table non limitée en profondeur, autrement dit, la table ne cesse de croître à mesure que de nouvelles données arrivent. Cette table d’entrée est traitée en continu par une longue requête, et les résultats sont écrits dans une table de sortie :

Dans Structured Streaming, les données arrivent au système et sont ingérées immédiatement dans une table d’entrée. Vous écrivez des requêtes (à l’aide des API DataFrame et DataSet)qui effectuent des opérations sur cette table d’entrée. La sortie de la requête génère une autre table : la table de résultats. La table de résultats contient les résultats de votre requête, à partir desquels vous récupérez des données destinées à un magasin de données externe tel qu’une base de données relationnelle. Le moment où les données de la table d’entrée sont traitées est contrôlé par l’intervalle de déclenchement. Par défaut, l’intervalle de déclencheur est défini sur zéro, ce qui signifie que Structured Streaming tente de traiter les données dès qu’elles arrivent. Concrètement, dès que Structured Streaming a fini l’exécution de la requête précédente, il démarre un autre flux de traitement sur toutes les nouvelles données reçues. Vous pouvez configurer le déclencheur pour qu’il s’exécute à un intervalle défini, afin que les données de diffusion en continu soient traitées dans des lots basés sur le temps.
Les données des tables de résultats peuvent contenir uniquement les nouvelles données reçues depuis le traitement de la requête (mode Append), ou la table peut être actualisée chaque fois qu’il existe de nouvelles données, afin que la table contienne toutes les données de sortie depuis le début de la requête de streaming (mode Complet).
Mode Append
En mode Append, seules les lignes ajoutées à la table de résultats depuis la dernière exécution de la requête sont présentes dans la table de résultats et écrites dans un stockage externe. Par exemple, la requête la plus simple copie simplement toutes les données de la table d’entrée dans la table de résultats non modifiée. Chaque fois qu’un intervalle de déclencheur est écoulé, les nouvelles données sont traitées et les lignes qui représentent des nouvelles données apparaissent dans la table de résultats.
Imaginez un scénario où vous traitez des données de télémétrie provenant de capteurs de température, par exemple un thermostat. Supposons que le premier déclencheur ait traité un événement à 00:01 pour l’appareil 1 affichant une température de 95 degrés. Dans le premier déclencheur de la requête, seule la ligne associée à l’heure 00:01 apparaît dans la table de résultats. À l’heure 00:02, lorsqu’un autre événement arrive, la seule nouvelle ligne est la ligne associée à l’heure 00:02 et, par conséquent, la table de résultats contiendra uniquement cette ligne.
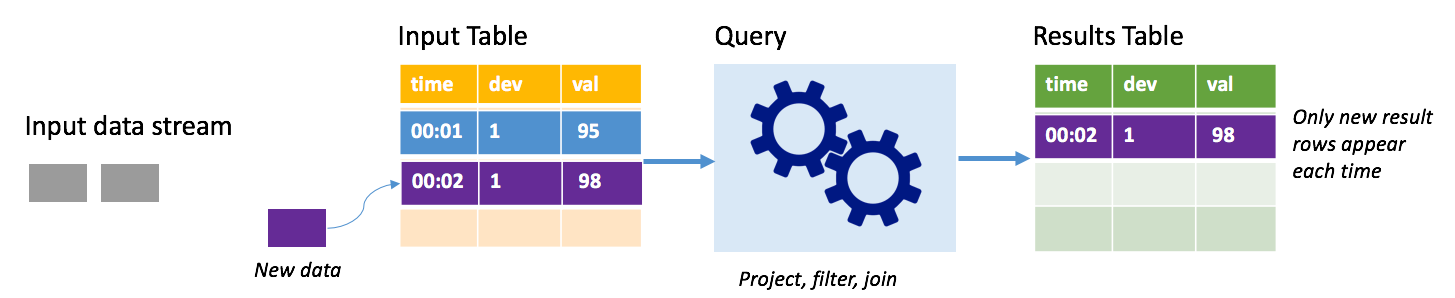
Lorsque vous utilisez le mode Append, votre requête applique des projections (en sélectionnant les colonnes qui l’intéressent), un filtrage (en choisissant uniquement les lignes répondant à certaines conditions) ou une jointure (en enrichissant les données avec les données d’une table de recherche statique). Le mode Append permet de transmettre facilement les nouveaux points de données pertinents vers un stockage externe.
Mode Complet
Considérez le même scénario, cette fois en utilisant le mode Complet. En mode Complet, l’intégralité de la table de sortie est actualisée à chaque déclencheur. Autrement dit, la table inclut non seulement les données issues de l’exécution du dernier déclencheur, mais également les données de toutes les autres exécutions. Vous pouvez utiliser le mode Complet pour copier les données non modifiées de la table d’entrée vers la table de résultats. À chaque exécution déclenchée, les nouvelles lignes de résultats s’affichent en même temps que toutes les lignes précédentes. Le tableau de résultats finit par stocker toutes les données collectées depuis le début de la requête, au risque de manquer de mémoire. Le mode Complet est destiné à des requêtes d’agrégation qui, d’une certaine façon, synthétisent les données entrantes. À chaque déclencheur, la table de résultats est donc mise à jour avec un nouveau résumé.
Supposons que nous avons déjà traité l’équivalent de cinq secondes de données, et qu’il nous faille maintenant traiter les données correspondant à la sixième seconde. La table d’entrée contient des événements pour l’heure 00:01 et l’heure 00:03. L’objectif de cet exemple de requête est de donner la température moyenne de l’appareil toutes les cinq secondes. L’implémentation de cette requête applique un agrégat qui accepte toutes les valeurs qui se trouvent dans chaque fenêtre de 5 secondes, calcule la moyenne de la température et génère une ligne correspondant à la température moyenne sur cet intervalle. À la fin de la première fenêtre de 5 secondes, il existe deux tuples : (00:01, 1, 95) et (00:03, 1, 98). Pour la fenêtre 00:00-00:05, l’agrégation génère donc un tuple avec la température moyenne de 96,5 degrés. Dans la fenêtre de 5 secondes suivante, on obtient uniquement un point de données à l’heure 00:06, ce qui donne une température moyenne de 98 degrés. À l’heure 00:10, à l’aide du mode Complet, la table de résultats intègre les lignes correspondant aux deux fenêtres (00:00-00:05 et 00:05:00:10), car la requête renvoie toutes les lignes agrégées, et pas seulement les nouvelles. Par conséquent, la table des résultats continue de croître à mesure que de nouvelles fenêtres sont ajoutées.
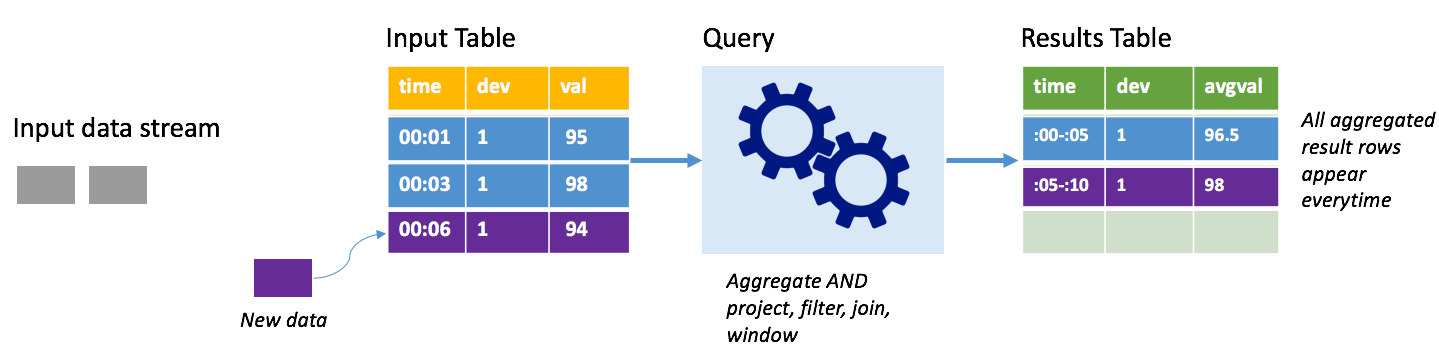
Toutes les requêtes qui utilisent le mode Complet n’entraînent pas une croissance illimitée de la table. Imaginez, en reprenant l’exemple précédent, qu’au lieu de calculer la moyenne de température par fenêtre de temps, la requête calcule la moyenne par ID d’appareil. La table de résultats contient un nombre fixe de lignes (une par appareil) avec la température moyenne obtenue pour l’appareil sur tous les points de données reçus à partir de cet appareil. À mesure que de nouvelles températures sont reçues, la table de résultats est mise à jour de sorte que les moyennes de la table soient toujours actualisées.
Composants d’une application Spark Structured Streaming
Un exemple de simple requête peut synthétiser les relevés de température sur des fenêtres d’une heure. Dans ce cas, les données sont stockées dans des fichiers JSON à l’intérieur du stockage Azure (attaché en tant que stockage par défaut pour le cluster HDInsight) :
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Ces fichiers JSON sont stockés dans le sous-dossier temps, sous le conteneur du cluster HDInsight.
Définir la source d’entrée
Commencez par configurer une trame de données qui décrit la source des données et tous les paramètres dont a besoin cette source. Cet exemple extrait des données à partir des fichiers JSON dans le stockage Azure et leur applique un schéma au moment de la lecture.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
Appliquer la requête
Appliquez ensuite une requête qui contient les opérations souhaitées sur la trame de données de diffusion en continu. Dans ce cas, une agrégation regroupe toutes les lignes dans des fenêtres de 1 heure, puis calcule les températures minimales, maximales et moyennes dans cette fenêtre de 1 heure.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
Définir le récepteur de sortie
Définissez ensuite la destination des lignes qui sont ajoutées à la table de résultats dans chaque intervalle de déclencheur. Cet exemple envoie simplement toutes les lignes à une table en mémoire temps que vous pourrez interroger plus tard avec SparkSQL. Avec le mode de sortie Complet, vous avez la garantie que toutes les lignes de toutes les fenêtres seront générées à chaque fois.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
Démarrer la requête
Démarrez la requête de diffusion en continu et exécutez-la jusqu’à la réception d’un signal d’arrêt.
val query = streamingOutDF.start()
Afficher les résultats
Pendant l’exécution de la requête, dans la même session Spark, vous pouvez exécuter une requête SparkSQL sur la table temps où sont stockés les résultats de la requête.
select * from temps
Cette requête génère des résultats similaires à ce qui suit :
| window | min(temp) | avg(temp) | max(temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
Pour plus d’informations sur l’API Spark Structured Stream, ainsi que les sources de données d’entrée, les opérations et les récepteurs de sortie qu’elle prend en charge, consultez le Guide de programmation d’Apache Spark Structured Streaming.
Points de contrôle et journaux d’activité WAL
Pour la résilience et la tolérance de panne, Structured Streaming s’appuie sur les points de contrôle pour s’assurer que le traitement de flux de données s’effectue sans interruption, même en cas de défaillances de nœud. Dans HDInsight, Spark crée des points de contrôle pour un stockage durable (Data Lake Storage ou le stockage Azure). Ces derniers stockent les informations de progression concernant la requête de diffusion en continu. Structured Streaming utilise également un journal WAL (write-ahead log). Le journal WAL capture les données ingérées qui ont été reçues, mais qui n’ont pas encore été traitées par une requête. En cas de défaillance et de redémarrage du traitement à partir du journal WAL, aucun des événements reçus de la source ne sera perdu.
Déploiement d’applications Spark Streaming
Vous générez généralement une application Spark Streaming localement dans un fichier JAR, puis vous la déployez dans Spark sur HDInsight en copiant le fichier JAR dans le stockage par défaut attaché à votre cluster HDInsight. Vous pouvez démarrer votre application à l’aide des API REST Apache Livy disponibles dans votre cluster à l’aide de l’opération POST. Le corps du POST inclut un document JSON qui fournit le chemin d’accès à votre fichier JAR, le nom de la classe dont la méthode principale définit et exécute l’application de diffusion en continu et éventuellement les ressources requises par la tâche (telles que le nombre d’exécuteurs, la mémoire et les cœurs), ainsi que tout paramètre de configuration requis par votre code d’application.
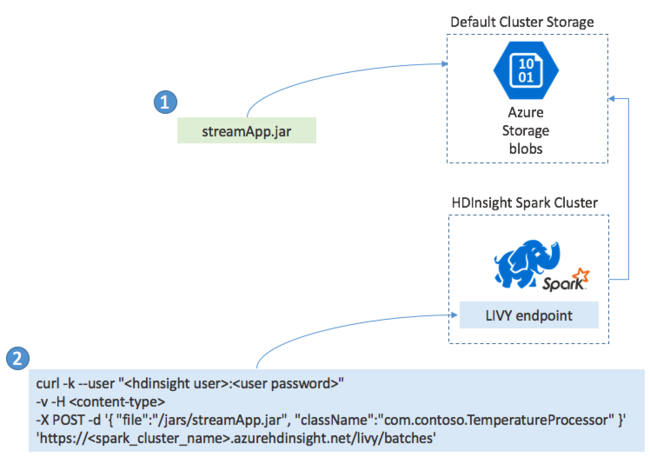
L’état de toutes les applications peut également être vérifié à l’aide d’une requête GET sur un point de terminaison LIVY. Enfin, vous pouvez terminer l’exécution d’une application en émettant une requête DELETE sur le point de terminaison LIVY. Pour plus d’informations sur l’API LIVY, consultez Travaux à distance avec Apache LIVY