Vue d’ensemble de Stockage Azure dans HDInsight
Stockage Azure est une solution de stockage à la fois robuste et polyvalente qui s’intègre en toute transparence à HDInsight. HDInsight peut utiliser un conteneur d’objets blob dans le stockage Azure comme système de fichiers par défaut pour le cluster. Grâce à une interface HDFS, l’ensemble des composants de HDInsight peut opérer directement sur les données structurées ou non structurées stockées en tant qu’objets blob.
Nous vous recommandons d’utiliser des conteneurs de stockage distincts pour votre stockage de clusters par défaut et vos données d’entreprise. La séparation consiste à isoler les journaux HDInsight et les fichiers temporaires de vos propres données d’entreprise. Nous recommandons également de supprimer le conteneur d’objets blob par défaut, qui contient les journaux des applications et système, après chaque utilisation pour réduire le coût de stockage. Assurez-vous de récupérer les journaux d’activité avant de supprimer le conteneur.
Si vous choisissez de sécuriser votre compte de stockage à l’aide des restrictions de pare-feu et réseaux virtuels paramétrées sur Réseaux sélectionnés, veillez à activer l’exception Autoriser les services approuvés de Microsoft… L’exception vise à permettre à HDInsight d’accéder à votre compte de stockage.
Architecture de stockage HDInsight
Le schéma suivant résume l’architecture HDInsight de Stockage Azure :
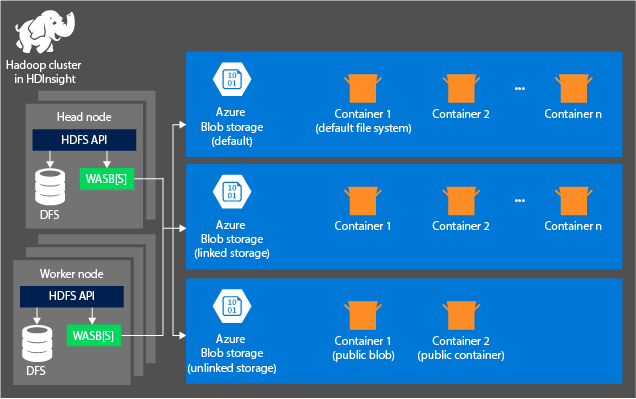
HDInsight permet d'accéder au système de fichiers distribués (DFS) connecté localement aux nœuds de calcul. Vous pouvez accéder à ce système de fichiers en utilisant l'URI complet, par exemple :
hdfs://<namenodehost>/<path>
Grâce à HDInsight, vous pouvez également accéder aux données dans Stockage Azure. La syntaxe est la suivante :
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
Pour les comptes qui ont un espace de noms hiérarchique (Azure Data Lake Storage Gen2), la syntaxe est la suivante :
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
Voici quelques points à prendre en compte quand vous utilisez un compte Stockage Azure avec des clusters HDInsight :
Conteneurs dans les comptes de stockage connectés à un cluster : Comme le nom et la clé du compte sont associés au cluster durant la création, vous disposez d’un accès complet aux blobs de ces conteneurs.
Conteneurs publics ou blobs publics dans les comptes de stockage qui ne sont pas connectés à un cluster : vous avez l’autorisation d’accès en lecture seule aux blobs dans les conteneurs.
Notes
Les conteneurs publics vous permettent d’obtenir une liste de tous les objets blob disponibles dans ce conteneur, ainsi que ses métadonnées. Vous pouvez accéder aux objets blob d'un objet blob public uniquement si vous connaissez leur URL exacte. Pour plus d’informations, consultez Gestion de l’accès en lecture anonyme aux conteneurs et aux objets blob.
Conteneurs privés dans des comptes de stockage qui ne sont pas connectés à un cluster : vous ne pouvez pas accéder aux blobs se trouvant dans les conteneurs, sauf si vous définissez le compte de stockage quand vous envoyez des travaux WebHCat.
Les comptes de stockage définis durant la création et leurs clés sont stockés dans %HADOOP_HOME%/conf/core-site.xml sur les nœuds du cluster. Par défaut, HDInsight utilise les comptes de stockage définis dans le fichier core-site.Xml. Vous pouvez modifier ce paramètre avec Apache Ambari. Pour plus d’informations sur les paramètres du compte de stockage qui peuvent être modifiés ou placés dans le fichier core-site.xml, consultez les articles suivants :
- Support Azure Hadoop : Stockage d’objets Blob azure
- Support Azure Hadoop : ABFS – Azure Data Lake Storage Gen2
Plusieurs travaux WebHCat, notamment Apache Hive, MapReduce, le streaming Apache Hadoop et Apache Pig, véhiculent une description des comptes de stockage et des métadonnées. (Cet aspect est actuellement valable pour Pig avec les comptes de stockage, mais pas pour les métadonnées.) Pour plus d’informations, consultez Utilisation d’un cluster HDInsight avec des comptes de stockage et des metastores secondaires.
Les objets blob peuvent être utilisés pour les données structurées et non structurées. Les conteneurs d’objets blob stockent des données en tant que paires clé/valeur et ils n’ont pas de hiérarchie de répertoires. Cependant, le nom de la clé peut inclure une barre oblique (« / ») pour faire comme si un fichier était stocké dans une structure de répertoires. Par exemple, une clé d’objet blob peut être input/log1.txt. Il n’existe aucun répertoire input réel, mais en raison de la présence de la barre oblique dans le nom de la clé, celle-ci apparaît comme un chemin de fichier.
Avantages de Stockage Azure
Les clusters de calcul et les ressources de stockage qui ne sont pas colocalisés ont des coûts implicites en termes de performances. Ces coûts sont atténués par la façon dont les clusters de calcul sont créés à proximité des ressources de compte de stockage à l’intérieur de la région Azure. Dans cette région, les nœuds de calcul peuvent accéder efficacement aux données par le biais du réseau à haut débit à l’intérieur de Stockage Azure.
Quand vous stockez les données dans Stockage Azure plutôt qu’HDFS, vous obtenez plusieurs avantages :
Réutilisation et partage des données : les données du système HDFS sont situées dans le cluster de calcul. Seules les applications pouvant accéder au cluster de calcul peuvent utiliser les données avec l'API HDFS. Les données dans Stockage Azure, quant à elles, sont accessibles par le biais des API HDFS ou des API REST de Stockage Blob. Vous pouvez ainsi utiliser un plus grand nombre d’applications (notamment d’autres clusters HDInsight) et d’outils pour produire et consommer des données.
Archivage des données : quand les données sont stockées dans Stockage Azure, les clusters HDInsight utilisés pour les calculs peuvent être supprimés sans perte de données utilisateur.
Coût de stockage des données : le stockage à long terme de données dans DFS est plus coûteux que le stockage des données dans Stockage Azure, car le coût d’un cluster de calcul est supérieur à celui de Stockage Azure. De plus, comme vous n’avez pas à recharger les données pour chaque génération de cluster de calcul, vous faites également des économies sur les chargements de données.
Scale-out élastique : même si le système HDFS offre un système de fichiers scale-out, l’échelle est déterminée par le nombre de nœuds que vous créez pour votre cluster. Plutôt que de modifier l’échelle, il est parfois plus simple de profiter des capacités de mise à l’échelle élastique que vous obtenez automatiquement dans Stockage Azure.
Géoréplication : vous pouvez géorépliquer votre Stockage Azure. Si la géoréplication permet la récupération à partir d’autres régions géographiques et la redondance des données, un basculement vers un emplacement géorépliqué affecte sérieusement les performances et peut entraîner des frais supplémentaires. Par conséquent, choisissez la géoréplication avec précaution et uniquement si la valeur des données justifie le coût supplémentaire.
Certains packages et travaux MapReduce peuvent créer des résultats intermédiaires qu’il est préférable de ne pas stocker dans Stockage Azure. Dans ce cas, vous pouvez choisir de stocker les données dans un système HDFS local. HDInsight utilise DFS pour plusieurs de ces résultats intermédiaires dans les tâches Hive et d’autres processus.
Notes
La plupart des commandes HDFS (par exemple, ls, copyFromLocal et mkdir) fonctionnent comme prévu dans Stockage Azure. Seules les commandes propres à l’implémentation HDFS native (ou DFS), comme fschk et dfsadmin, se comportent différemment dans Stockage Azure.